Python算法入门day5——常见列表算法分析5 希尔排序,桶排序,计数排序,基数排序
1、希尔排序
【简单描述】
由插入排序变形而来
1.希尔排序(Shell Sort)是一种分组插入排序算法
2.首先取一个整数d1=n//2,将元素分为d1个组,每组相邻量元素之间的距离为d1,在各组内进行直接插入排序;
3.接着取第二个整数d2=d1/2,重复上述分组排序过程,直到d=1,即所有元素在同一组内进行直接插入排序。
4.希尔排序每趟并不使某些元素有序,而是使整体数据越来越接近有序;最后一趟排序使得所有数据有序。
希尔排序图解
1.首先输入一个长度为9的列表,d1为4

2.将整体列表分为四组,间隔为四的分为一组
第一组(5,3,8)第二组(7,1)第三组(4,2)第四组(6,9)
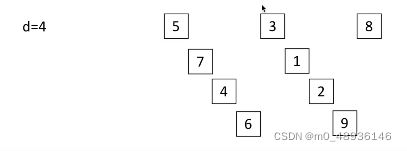
3.每组进行插入排序,完成第一次,排完序回来

4.接着进行第二次排序,取d2=d1/2,间隔为二的成一组
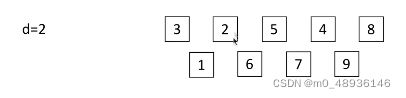
5.然后在进行插入排序,再放回

6.最后d=1,直接进行插入排序,结束

【代码解析】
因为希尔排序是基于插入排序的,所以只需要在插入排序中进行修改,将所有的1改为整数d即可(不了解插入排序的,可以看看这一篇)
Python算法入门day2——常见列表算法分析1 冒泡、选择、插入_m0_48936146的博客-CSDN博客冒泡排序、选择排序、插入排序https://blog.csdn.net/m0_48936146/article/details/123551869?spm=1001.2014.3001.5501这只是一行列表的插入排序
def insert_sort_gap(li,gap):#列表,分的组
for i in range(gap,len(li)):
tmp=li[i] #储存当前的数
j=i-gap #目前已经加入的数
while j>=0 and li[j]>tmp:
li[j+gap]=li[j]
j-=gap
li[j+gap]=tmp接下来就是实现希尔排序的代码
#实现希尔排序
def shell_sort(li):
d=len(li)//2 #第一次分割的列表数
while d>=1:
insert_sort_gap(li,d)
d=d//2
【完整代码】
def insert_sort_gap(li,gap):#列表,分的组
for i in range(gap,len(li)):
tmp=li[i] #储存当前的数
j=i-gap #目前已经加入的数
while j>=0 and li[j]>tmp:
li[j+gap]=li[j]
j-=gap
li[j+gap]=tmp
#实现希尔排序
def shell_sort(li):
d=len(li)//2 #第一次分割的列表数
while d>=1:
insert_sort_gap(li,d)
d=d//2
li=list(range(10))
import random
random.shuffle(li)#打乱
print(li)
shell_sort(li)
print(li)【实验结果】
[4, 8, 1, 5, 2, 3, 0, 9, 7, 6]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
2、计数排序
【题目要求】
对列表进行排序,已知列表中对数对范围都在0到100之间。设计时间复杂度为O(n)的算法。
【计数排序思路】
计数排序相比前面几个排序是相对简单的
1、只需要创建一个n个数下标的列表
2、全部覆0
3、依次将列表中的数挨个计数的方式加入到列表中
1 3 2 3 4 5 2 3 #列表1 长度为8
[0,0,0,0,0,0] #创建一个长度为列表1中最大的值(5)+1的列表
[1,2,3,1,1] #挨个计数
[1,2,2,3,3,3,4,5] #根据数量挨个输出下标
时间复杂度为O(n)
【代码运算】
def count_sort(li,max_count=100):#列表,列表最大值默认100
li_1=[0 for i in range(max_count+1)]#创建一个100长度的全0列表
for i in li: #将li中的数作为下标
li_1[i]+=1#统计,在i处+1
li.clear()#清空列表 重新写回li
#将下标和值挨个输出,表示有val个ind
for ind,val in enumerate(li_1):
for i in range(val):#将ind下标输出val个
li.append(ind)
import random
#输入10个1~100随机整数,
li=[random.randint(1,100) for i in range(10)]
print(li)
count_sort(li)
print(li)不了解enumerate()函数的可以看看这个
Python enumerate() 函数 | 菜鸟教程Python enumerate() 函数 Python 内置函数 描述 enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 Python 2.3. 以上版本可用,2.6 添加 start 参数。 语法 以下是 enumerate() 方法的语法: enumerate(sequence, [start=0]) 参数 se..https://www.runoob.com/python/python-func-enumerate.html
【运行结果】
[4, 33, 12, 57, 38, 42, 92, 91, 67, 46]
[4, 12, 33, 38, 42, 46, 57, 67, 91, 92]
【缺点/限制】
不能是小数并且有范围,得找最大值,如果数是1到1亿,就五个数,还是需要创建一个一亿的列表,还是有点浪费的,需要更加完善。
3、桶排序
(不常用,了解)
1.在计数排序中,如果元素的范围比较大(比如在1到一亿之间),那么该如何改造算法呢?
2.桶排序(Bucket Sort): 首先将元素分在不同的桶中,再对桶中的元素进行排序。
eg:
如图,最大值是50,所以可以分为5个阶段表示桶,然后依次将列表中的元素放入桶中,当放入的元素比桶中的元素大时,交换位置 。
【代码实现】
def Bucket_sort(li,n=100,max_num=10000):#列表,默认100个桶,默认1w个数
buckets=[[] for i in range(n)]#创建桶,二维数组[][]
for var in li:
i=min(var//(max_num//n),n-1)
'''
max_num//n 表示每个桶的范围
i代表var到哪个桶里去
(当var为89,89//100-》0 代表第一个桶)
var=4k 4k//100->40 代表第40个桶
n-1代表最后一个桶
当桶只有99个,var=10w,代表第100个桶
但是没有第100个桶,所以要加入到第99个桶,所以要使用min函数
'''
buckets[i].append(var)#将var加入到桶里
#保持桶内顺序
for j in range(len(buckets[i])-1,0,-1):
if buckets[i][j]【桶排序——讨论】
1.桶排序的表现取决于数据的分布。也就是需要对不同的数据排序时采取不同对分桶策略。
2.平均情况时间复杂度:O(n+k)
3.最坏情况时间复杂度:O(n^2k)
4、基数排序
类似桶排序
【了解多关键字排序】
假如现在有一个员工表,要求按照薪资排序,年龄相同的按照年龄排序。
首先按照年龄进行排序,其次再按照薪资进行稳定排序。
那么对于32,13,94,52,17,54,93排序,是否可以看做多关键词排序?
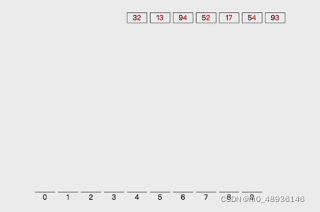
1.首先需要创建一个0~9的列表
2.然后先比较个位上的数,依次填入列表中,再依次返回原来列表

![]()
3.接着再判断十位上的数,再依次输出就拍完序了。


【代码思路】
1.首先找到列表中最大的数(用来判断是几位数的数)
2.遍历while循环(直到遍历完最大数的位数推出循环)
3.依次将个位,十位,百位...的数进行排序放入桶操作,再放回原来列表即可。
def radix_sort(li):
Max_num=max(li) #最大值 9->1,99->2,1000->4
pf=0 #平方
while 10**pf<=Max_num:
Buckets=[[] for i in range(10)]#创建十个桶
for i in li:
var=i//(10**pf)%10 #依次取个位,十位。。。
Buckets[var].append(i)#暂存
li.clear()#将一开始的列表清空
for j in Buckets: #将刚拍完序的数重新加入到li
li.extend(j)
pf+=1 #位数加1
import random
li=[random.randint(1,100) for i in range(10)]
print(li)
radix_sort(li)
print(li)【实验结果】
[53, 47, 59, 79, 24, 63, 75, 27, 61, 23]
[23, 24, 27, 47, 53, 59, 61, 63, 75, 79]