docker系列
时间一晃三个月过去了,本来不想再写csdn的,但是思来想去,最初发表的第一篇文章是csdn平台,而且领悟到了许多大佬经常说的不忘初心,牢记使命,我给自己目前的定位是运维开发内容,每个IT人员都有一个全栈的梦想,继续启航吧

文章目录
-
-
-
-
- 1.docker(centos)快速安装
- 2.docker(ubuntu)极速安装
- 3.docker-compose安装
- 4.docker安装Elasticsearch
- 5.docker安装vscode
- 6.docker部署100台nginx服务
- 7.docker安装EFK分布式日志平台
- 8.docker 可视化管理容器
- 9.docker redis分布式集群
-
- 9.2基于哈希槽分区的三主三从
- 9.3docker redis 三主三从部署
- 9.4Redis主从切换迁移案例
- 9.5主从扩容案例
- 9.6主从缩容案例
- 10.docker 容器监控-CAdvisor+InfluxDB+Granfana
-
-
-
1.docker(centos)快速安装
_docker_centos(){
#安装工具
yum install -y yum-utils
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
#安装docker
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
}
_docker_centos
2.docker(ubuntu)极速安装
_docker_install(){
#卸载旧的docker版本
sudo apt-get remove docker docker-engine docker.io containerd runc
#apt存储库更新,确保https和ca证书模块被安装
sudo apt-get update
sudo apt-get install \
ca-certificates \
apt-transport-https \
curl \
gnupg \
lsb-release \
vim
#添加 Docker 的官方 GPG 密钥
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
#设置稳定存储库。要添加 nightly或test存储库
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
#安装docker
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
sudo systemctl enable docker.service
sudo systemctl start docker.service
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn/"]
}
EOF
systemctl daemon-reload
systemctl restart docker
}
_docker_install
3.docker-compose安装
docker-compose_install(){
curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.4/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
}
docker-compose_install
4.docker安装Elasticsearch
Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎,可以说 Lucene 是当今最先进,最高效的全功能开源搜索引擎框架。
由Shay Banon开发并于2010年发布。现在是由Elasticsearch BV负责维护。其最新版本是:5.2.0。
Elasticsearch是一个实时分布式和开源的全文搜索和分析引擎。 它可以从RESTful Web服务接口访问,并使用模式少JSON(JavaScript对象符号)文档来存储数据。它是基于Java编程语言,这使Elasticsearch能够在不同的平台上运行。使用户能够以非常快的速度来搜索非常大的数据量。
ElasticSearch优点:
Elasticsearch是基于Java开发的,这使得它在几乎每个平台上都兼容。
Elasticsearch是实时的,换句话说,一秒钟后,添加的文档可以在这个引擎中搜索得到。
Elasticsearch是分布式的,这使得它易于在任何大型组织中扩展和集成。
通过使用Elasticsearch中的网关概念,创建完整备份很容易。
与Apache Solr相比,在Elasticsearch中处理多租户非常容易。
Elasticsearch使用JSON对象作为响应,这使得可以使用不同的编程语言调用Elasticsearch服务器。
Elasticsearch支持几乎大部分文档类型,但不支持文本呈现的文档类型
ES跑起来需要至少1.2GIB内存,所以如果内存不够的话可以通过-e配置修改实现,一下ES_JAVA_OPTS参数选择性添加
Xms #分配的内存
Xmx #最大限度内存
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx1000m" elasticsearch:7.6.2
百度访问:http://ip地址:9200
{
"name" : "8fecaad4e721",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "qUtP0qneSiqbn2SS69VQ6A",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
访问:http://ip地址:9200/_cat/
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates
5.docker安装vscode
# DOMAIN 强烈推荐设置,设置域名或IP, 设置后将支持 Draw.io 等插件
# PASSWORD 引号内可设置登录密码
__run_vscode() {
docker rm -f vscode
rm -rf /data/docker-data/vscode/.local/share/code-server
docker pull registry.cn-hangzhou.aliyuncs.com/lwmacct/code-server:v3.12.0-shell
docker run -itd --name=vscode \
--hostname=code \
--restart=always \
--privileged=true \
--net=host \
-v /proc:/host \
-v /docker/vscode:/root/ \
-e DOMAIN='' \
-e PASSWORD="123456" \
registry.cn-hangzhou.aliyuncs.com/lwmacct/code-server:v3.12.0-shell
}
__run_vscode
6.docker部署100台nginx服务
循环启动100个nginx服务
for i in $(seq 0 99);do docker run -itd -p 80$i:80 --name=nginx$i --privileged nginx:latest ;done

查看一百台nginx容器服务IP地址
for i in $(docker ps|grep -aiE nginx|awk '{print $1}');do docker inspect $i |grep -aiE ipaddr|tail -1|grep -aiowE "([0-9]{1,3}\.){3}[0-9]{1,3}";done
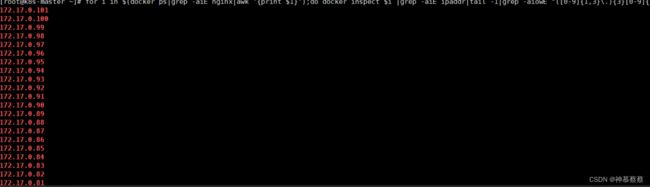
取出IP地址,容器id,cpu内存,磁盘信息取出打印
for i in $(docker ps|grep -aiE nginx|awk '{print $1}');do echo $i; docker inspect $i |grep -aiE ipaddr|tail -1|grep -aiowE "([0-9]{1,3}\.){3}[0-9]{1,3}";done|sed 'N;s/\n/ /g'|awk '{print $NR,$0" 2C 2G 40GB Nginx"}'
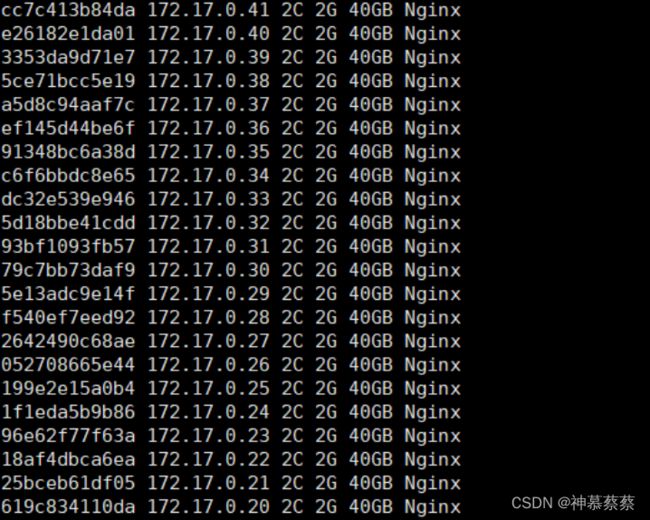
7.docker安装EFK分布式日志平台

通常我们会使用到ELK分布式日志管理系统(Elasticsearch,Logstash,Kibana,均是开源软件)
- Elasticsearch 是分布式搜索引擎,提供收集,存储数据,自动搜索负载等功能
- Logstash 是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
- Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志
而现在要用到的是EFK,F是Filebeats,搜索文件数据
Filebeats对比Logstash
Logstash是java写的,插件是jrub写的,消耗资源会多
Filebeats是go语言写的,非常轻量级占用的系统资源更少,但是Beats相对于LogStash的插件更少
docker部署EFK
#拉取镜像,最好7版本以上
#EFK版本保持一致
拉取三个镜像
#拉取三个镜像
docker pull elasticsearch:7.6.2
docker pull kibana:7.6.2
docker pull elastic/filebeat:7.6.2
Elasticsearch配置
#启动ES
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms64m -Xmx1000m" elasticsearch:7.6.2
#解决跨域问题,容器内文件追加俩行内容
docker exec -it elasticsearch bash -c "echo -e 'http.cors.enabled: true\nhttp.cors.allow-origin: \"*\"' >> config/elasticsearch.yml"
#重启
docker exec -it elasticsearch
kibana配置
#启动kibana
#elasticsearch是ES容器名,--link参数是将将两个容器关联到一起可以互相通信,kibana到时候需要从ElasticSearch中拿数据
docker run --link elasticsearch:elasticsearch -p 5601:5601 -d --name kibana kibana:7.6.2
#配置kibana的yml文件,让其找到ES,并且汉化一下
docker exec -it kibana /bin/bash
vim config/kibana.yml
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: "zh-CN"
#重启kibana
docker restart kibana
Filebeat配置
Filebeat配置帮助
#Filebeat配置字段介绍(yml格式)
- type #输入的文件类型,本例中输入为log文件
- enabled #是否启用当前输入,一般为true
- paths #文件路径,可以配置多个,没有对配置目录做递归处理,比如配置的如果是:/var/log/ /.log,则只会去/var/log目-录的所有子目录中寻找以".log"结尾的文件,而不会寻找/var/log目录下以".log"结尾的文件。
- multiline #多行合并配置,例如日志为堆栈异常,应将多行日志合并为一条消息。
- setup.template #模板配置,filebeat会加载默认的模板,当我们想指定自己的索引名称时在此指定name和匹配规则pattern
- setup.ilm.enabled #当配置模板名称后不生效,需要关闭此开关
- output.elasticsearch.hosts #输出到ES的地址
- output.elasticsearch.index #输出到ES的索引名称,这个配置和上面setup.template.name setup.template.pattern需要一- 起使用
- setup.kibana.host #配置kibana的地址,一般来说filebeat直接发送数据给ES,kibana只做展示可以不用配置,但要使用- - kibana的dashboard等功能的话需要作出此配置
本人配置文件
>#编写filebeat.docker.yml文件
cd /usr/src/
vim filebeat.docker.yml
filebeat.inputs:
# 多个后端服务,每个后端服务日志目录不同,给不同的日志目录设置不同的tag
- type: log
# 更改为true以启用此输入配置
enabled: true
#解决中文乱码问题
encoding: GB2312
#过滤日志字段
#您可以添加可用于过滤日志数据的字段。字段可以是标量值,数组,字典或它们的任何嵌套组合。默认情况下,
#您在此处指定的字段将被分组fields到输出文档中的子词典下。要将自定义字段存储为顶级字段,
#请将fields_under_root选项设置为true。如果在常规配置中声明了重复字段,则其值将被此处声明的值覆盖。
fields:
type: s1
paths:
#- /var/log/*.logs
#- c:\programdata\elasticsearch\logs\*
- G:\\s1.log
- type: log
# 更改为true以启用此输入配置
enabled: true
#解决中文乱码问题
encoding: GB2312
#过滤日志字段
#您可以添加可用于过滤日志数据的字段。字段可以是标量值,数组,字典或它们的任何嵌套组合。默认情况下,
#您在此处指定的字段将被分组fields到输出文档中的子词典下。要将自定义字段存储为顶级字段,
#请将fields_under_root选项设置为true。如果在常规配置中声明了重复字段,则其值将被此处声明的值覆盖。
fields:
type: s2
# Paths that should be crawled and fetched. Glob based paths.
#paths也是数组(下面也有-这个符号),path用于指定日志路径。
paths:
#- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*
- G:\s2.log
#pattern:多行日志开始的那一行匹配的pattern
#negate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为false
#match:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.pattern: ^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}|^\[|^[[:space:]]+(at|\.{3})\b|^Caused by:'
multiline.negate: false
multiline.match: after
# ============================== Filebeat modules ==============================
filebeat.config.modules:
# Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
reload.enabled: true
# ======================= Elasticsearch template setting =======================
setup.template.settings:
index.number_of_shards: 1 #指定索引的分片
output.elasticsearch: #输出到elasticsearch集群,没用集群就写本机或者一个就行了
hosts: ["127.0.0.1:9300"]
##输出到console
#filebeat断电异常关闭,会自动修改yml文件的 enabled: true属性为false,请注意查看
#Filebeat Console(标准输出):Filebeat将收集到等数据,输出到console里,一般用于开发环境中,用于调试。
#output.console:
# pretty: true
# enable: true
#index.codec: best_compression
#_source.enabled: false
# =================================== Kibana ===================================
setup.kibana:
host: "127.0.0.1:5601"
# ================================== Outputs ==================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["127.0.0.1:9200"]
indices:
# 注意!!! 对应es 创建索引名称 。 统一前缀或者后缀 。多服务想一起查询某个数据,以便于以后在kibana创建索引模型可以同时匹配)
- index: "s_1_%{+yyyy.MM.dd}"
when.equals:
#对应filebeat.inputs: type字段
fields.type: "s1"
- index: "s_2_%{+yyyy.MM.dd}"
when.equals:
fields.type: "s2"
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
#indices:
processors:
#需要删除的标签
- drop_fields:
fields: ["input_type", "log.offset", "host.name", "input.type", "agent.hostname", "agent.type", "ecs.version", "agent.ephemeral_id", "agent.id", "agent.version", "fields.ics", "log.file.path", "log.flags", "host.os.version", "host.os.platform","host.os.family", "host.os.name", "host.os.kernel", "host.os.codename", "host.id", "host.containerized", "host.hostname", "host.architecture"]
#启动filebeat
docker run -d -v /usr/src/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml -v /var/log/es/:/var/log/es/ --link elasticsearch:kibana --name filebeat elastic/filebeat:7.6.2
8.docker 可视化管理容器
portainer是一个可视化的Docker操作界面,提供状态显示面板、应用模板快速部署、容器镜像网络数据卷的基本操作(包括上传下载镜像,创建容器等操作)、事件日志显示、容器控制台操作、Swarm集群和服务等集中管理和操作、登录用户管理和控制等功能。功能十分全面,基本能满足中小型单位对容器管理的全部需求
Rancher是一个开源软件平台,使组织能够在生产中运行和管理Docker和Kubernetes。使用Rancher,组织不再需要使用一套独特的开源技术从头开始构建容器服务平台。Rancher提供了管理生产中的容器所需的整个软件堆栈
#--privileged=true #特权授予此容器扩展权限
#--restart=always #容器自动启动
docker run -d -p 9000:9000 \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
--privileged=true \
--name prtainer \
docker.io/portainer/portainer
设置完密码
点击本地连接接口看到首页界面
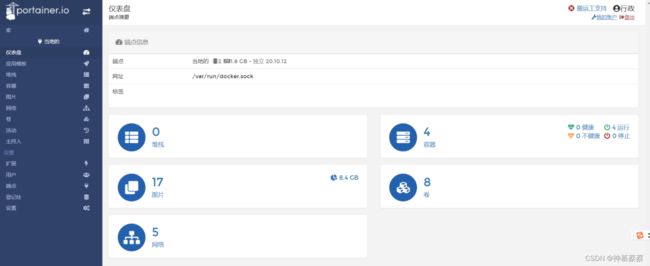
web平台的操作会在之后时间加上去
9.docker redis分布式集群
9.2基于哈希槽分区的三主三从
哈希槽介绍:
哈希槽实质是一个数组,[0,2^14-1]形成hash slot空间
为什么产生?
解决均匀分配的问题,在数据何节点之间又加入一层,称之为哈希槽(slot),用于管理数据和节点之间的关系
哈希解决的是映射问题,使用key的哈希值计算所在的槽,便于数据移动
槽的数量
一个集群只有0-2^14-1=0-16384个槽,槽会根据编号分配到主节点,集群会记录节点和槽的对应关系,
key求哈希值,对16384取余,slot=crc16(key)%16384来决定放置哪个槽
为什么是16384个槽,而不是65536呢?
1.如果是65536,发送心跳信息头达8k,过于庞大,会导致浪费带宽
2.redis集群主节点基本不可能超过1000个,不然会导致网络堵塞,16384已经足够使用
3.槽位越少,节点少的情况下,压缩比高,容易传输
9.3docker redis 三主三从部署
环境基于一台服务器上,利用docker容器化秒级部署
IP地址:192.168.142.128

redis集群配置
#关闭防火墙
systemctl disable --now firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#docker秒级启动六个redis服务
#-cluster-enabled是否开启集群,appendonly持久化数据
for i in $(seq 1 6);do docker run -d --name redis-node-$i --net host --privileged=true -v /mydata/redis/redis-node$i:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 637$i;done
#查看容器状态
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c9b8b822a86a redis:6.0.8 "docker-entrypoint.s…" 41 seconds ago Up 41 seconds redis-node-6
4a6f36a1c8b7 redis:6.0.8 "docker-entrypoint.s…" 41 seconds ago Up 41 seconds redis-node-5
98390020eaa3 redis:6.0.8 "docker-entrypoint.s…" 42 seconds ago Up 41 seconds redis-node-4
4f9436b43bc6 redis:6.0.8 "docker-entrypoint.s…" 42 seconds ago Up 41 seconds redis-node-3
4aeb79c8dd54 redis:6.0.8 "docker-entrypoint.s…" 42 seconds ago Up 42 seconds redis-node-2
568e4c387b0a redis:6.0.8 "docker-entrypoint.s…" 42 seconds ago Up 42 seconds redis-node-1
#配置集群关系
docker exec -it redis-node-1 /bin/bash
#--cluster-replicas 1表示为每一个master创建一个slave节点
redis-cli --cluster create 192.168.142.128:6371 192.168.142.128:6372 192.168.142.128:6373 192.168.142.128:6374 192.168.142.128:6375 192.168.142.128:6376 --cluster-replicas 1
#接下来会显示如下信息
>>>正在6个节点上执行哈希槽分配。。。
主[0]>插槽0-5460
主机[1]>插槽5461-10922
主机[2]>插槽10923-16383
将副本192.168.142.128:6375添加到192.168.142.128:6371
将副本192.168.142.128:6376添加到192.168.142.128:6372
将副本192.168.142.128:6374添加到192.168.142.128:6373
>>>尝试为反亲和力优化从属分配
[警告]一些奴隶与其主人在同一主机中
M: e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371
插槽:[0-5460](5461插槽)主
M: e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372
插槽:[5461-10922](5462插槽)主
M: 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373
插槽:[10923-16383](5461插槽)主
S: 267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374
复制84bcd2ee94cc91edcb1b4298b2a280b4f1588a52
S: 6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375
复制e6a761497e0fe78c066db91e32449ff5b71e29ae
S: 551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376
复制e7fd3352b9999ba0e75c9972971652e3d694eca3
我可以设置上述配置吗?(键入“yes”接受):yes #输入yes即可
M: 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered. #全部覆盖并且完成
进入6371主节点查看集群状态
redis-cli -p 6371
#查看集群信息
127.0.0.1:6371> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384 #总共槽位16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #节点数量6个
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:104
cluster_stats_messages_pong_sent:108
cluster_stats_messages_sent:212
cluster_stats_messages_ping_received:108
cluster_stats_messages_pong_received:104
cluster_stats_messages_received:212
#查看master节点与slave节点的分配情况
127.0.0.1:6371> cluster nodes
267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374@16374 slave 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 0 1658891898700 3 connected
551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376@16376 slave e7fd3352b9999ba0e75c9972971652e3d694eca3 0 1658891898000 2 connected
6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375@16375 slave e6a761497e0fe78c066db91e32449ff5b71e29ae 0 1658891897000 1 connected
e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371@16371 myself,master - 0 1658891898000 1 connected 0-5460
e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372@16372 master - 0 1658891899708 2 connected 5461-10922
84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373@16373 master - 0 1658891897693 3 connected 10923-16383
Redis主与从一一对应

Master Slave
1 ----> 5
2 ----> 6
3 ----> 4
9.4Redis主从切换迁移案例
#正确插入数据的方式,(以集群cluster的方式连接redis-node-1机器)
redis-cli -p 6371 -c
127.0.0.1:6371> FLUSHALL #清空数据(可输可不输)
OK
127.0.0.1:6371> set k1 v1 #插入一条数据
-> Redirected to slot [12706] located at 192.168.142.128:6373
OK
192.168.142.128:6373> #由于槽位是12706属于是6373机器的槽位,直接跳到6373机器上
#增加10条数据内容
redis-cli -p 6371 -c
127.0.0.1:6371> set k1 v1 #所有的数据均只会在三台主机上操作,三台从主机只能查看
-> Redirected to slot [12706] located at 192.168.142.128:6373
OK
192.168.142.128:6373> set k2 v2
-> Redirected to slot [449] located at 192.168.142.128:6371
OK
192.168.142.128:6371> set k3 v3
OK
192.168.142.128:6371> set k4 v4
-> Redirected to slot [8455] located at 192.168.142.128:6372
OK
192.168.142.128:6372> set k5 v5
-> Redirected to slot [12582] located at 192.168.142.128:6373
OK
192.168.142.128:6373> set k6 v6
-> Redirected to slot [325] located at 192.168.142.128:6371
OK
192.168.142.128:6371> set k7 v7
OK
192.168.142.128:6371> set k8 v8
-> Redirected to slot [8331] located at 192.168.142.128:6372
OK
192.168.142.128:6372> set k9 v9
-> Redirected to slot [12458] located at 192.168.142.128:6373
OK
192.168.142.128:6373> set k10 v10
#主master 6371机器上查看数据
root@k8s-master:/data# redis-cli -p 6371 -c
127.0.0.1:6371> keys *
1) "k7"
2) "k6"
3) "k3"
4) "k2"
#从slave 6375机器上查看是否同步数据
root@k8s-master:/data# redis-cli -p 6375 -c
127.0.0.1:6375> keys *
1) "k6"
2) "k3"
3) "k2"
4) "k7"
Redis主从切换
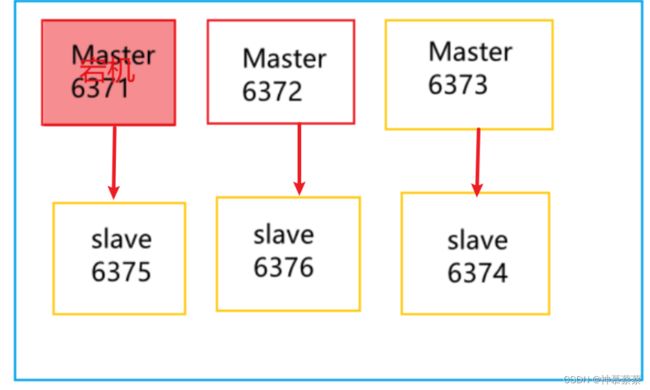
#模拟6371机器挂了
docker stop redis-node-1
#连接主slave 6375机器
root@k8s-master:/data# redis-cli -p 6375 -c
127.0.0.1:6375> cluster nodes
6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375@16375 master - 0 1658898284597 7 connected 0-5460 #6375切换为了master状态
551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376@16376 slave e7fd3352b9999ba0e75c9972971652e3d694eca3 0 1658898283587 2 connected
e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372@16372 myself,master - 0 1658898282000 2 connected 5461-10922
84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373@16373 master - 0 1658898282579 3 connected 10923-16383
267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374@16374 slave 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 0 1658898284000 3 connected
e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371@16371 master,fail - 1658897948468 1658897944000 1 disconnected #6371已经master,fail掉了
#可以看到,6375机器已经具备操作数据的能力
127.0.0.1:6375> set k12 v12
OK
从以上可以看出,6371机器宕机后,6375机器从slave变成了master
思考一个问题,如果6371恢复了会立即变成master,6375会立即变成slave吗?显示不会
#恢复6371机器
docker start redis-node-1
#进去查看集群状态,很明显6371集群是处于myself,slave状态
docker exec -it redis-node-1 /bin/bash
root@k8s-master:/data# cat nodes.conf
84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373@16373 master - 0 1658898881521 3 connected 10923-16383
e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372@16372 master - 0 1658898881521 2 connected 5461-10922
267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374@16374 slave 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 0 1658898881521 3 connected
6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375@16375 master - 0 1658898881521 7 connected 0-5460
551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376@16376 slave e7fd3352b9999ba0e75c9972971652e3d694eca3 1658898881521 1658898881520 2 connected
e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371@16371 myself,slave 6f09a00eb85e485ba2da608bc106a8b8641647e4 0 1658898881520 7 connected
通常我们还是希望6371是主master,6375是从slave,因此只需要先暂停6375,再恢复即可
#暂停并启动6375集群
docker stop redis-node-5
sleep 10
docker start redis-node-5
#进入6371机器查看集群状态
docker exec -it redis-node-1 /bin/bash
root@k8s-master:/data# redis-cli -p 6371 -c
127.0.0.1:6371> cluster nodes
e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372@16372 master - 0 1658900310064 2 connected 5461-10922
6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375@16375 slave e6a761497e0fe78c066db91e32449ff5b71e29ae 0 1658900309054 8 connected
84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373@16373 master - 0 1658900311073 3 connected 10923-16383
267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374@16374 slave 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 0 1658900308045 3 connected
e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371@16371 myself,master - 0 1658900309000 8 connected 0-5460
551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376@16376 slave e7fd3352b9999ba0e75c9972971652e3d694eca3 0 1658900309000 2 connected
很明显6371机器变成了myself,master状态,6375机器恢复到了slave状态
9.5主从扩容案例
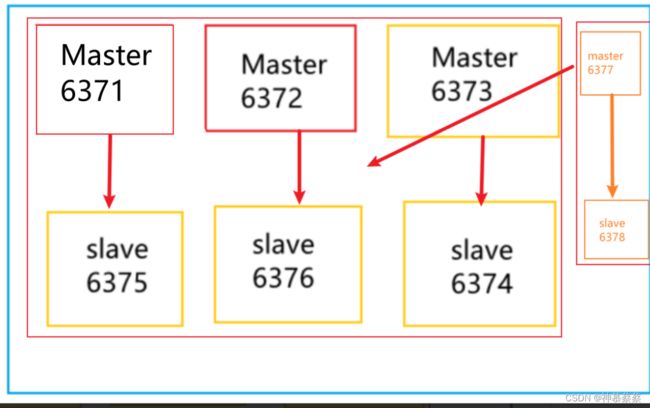
需求:一级系统,高并发流量全部进来了,三主三从扛不住了怎么办?
在三主三从的基础上,再增加一对一主一从来承担流量
三主三从变成四主四从的主要步骤:
1.新增节点
2.槽位分配
新增俩台节点(也就是俩个redis服务)
for i in $(seq 7 8);do docker run -d --name redis-node-$i --net host --privileged=true -v /mydata/redis/redis-node$i:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 637$i ;done
[root@k8s-master ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
88ce7c01b591 redis:6.0.8 "docker-entrypoint.s…" 6 minutes ago Up 6 minutes redis-node-8
7adb00fc0187 redis:6.0.8 "docker-entrypoint.s…" 6 minutes ago Up 6 minutes redis-node-7
c9b8b822a86a redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 3 hours redis-node-6
4a6f36a1c8b7 redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 27 minutes redis-node-5
98390020eaa3 redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 3 hours redis-node-4
4f9436b43bc6 redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 3 hours redis-node-3
4aeb79c8dd54 redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 3 hours redis-node-2
568e4c387b0a redis:6.0.8 "docker-entrypoint.s…" 26 hours ago Up 34 minutes redis-node-1
6377机器(空槽位)作为master加入原集群(新增master节点)
#进入6377容器
docker exec -it redis-node-7 /bin/bash
#add-node是添加节点,6371作为6377的领路人成为新的master节点
redis-cli --cluster add-node 192.168.142.128:6377 192.168.142.128:6371
....
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.142.128:6377 to make it join the cluster.
[OK] New node added correctly. #新的节点已加入
#查看6377端口集群状态
root@k8s-master:/data# redis-cli --cluster check 192.168.142.128:6377
192.168.142.128:6377 (2d932fa6...) -> 0 keys | 0 slots | 0 slaves.
192.168.142.128:6373 (84bcd2ee...) -> 5 keys | 5461 slots | 1 slaves.
192.168.142.128:6371 (e6a76149...) -> 5 keys | 5461 slots | 1 slaves.
192.168.142.128:6372 (e7fd3352...) -> 3 keys | 5462 slots | 1 slaves.
[OK] 13 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.142.128:6377)
M: 2d932fa60af3b3658e7dd5cf74cfaac66e068cef 192.168.142.128:6377
slots: (0 slots) master #已经是master状态,槽位为0
M: 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52 192.168.142.128:6373
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: e6a761497e0fe78c066db91e32449ff5b71e29ae 192.168.142.128:6371
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 267df70ab24d26946ef0b9ddde5dc34f6a4eb83b 192.168.142.128:6374
slots: (0 slots) slave
replicates 84bcd2ee94cc91edcb1b4298b2a280b4f1588a52
S: 6f09a00eb85e485ba2da608bc106a8b8641647e4 192.168.142.128:6375
slots: (0 slots) slave
replicates e6a761497e0fe78c066db91e32449ff5b71e29ae
S: 551c2fa30f0c0b72843cd51097c74539981c8e93 192.168.142.128:6376
slots: (0 slots) slave
replicates e7fd3352b9999ba0e75c9972971652e3d694eca3
M: e7fd3352b9999ba0e75c9972971652e3d694eca3 192.168.142.128:6372
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
重新分派槽位
reshard #重新哈希算法分配
新的节点加入后,必须重新规划槽位,16383/主master节点数量=平均分配的槽位
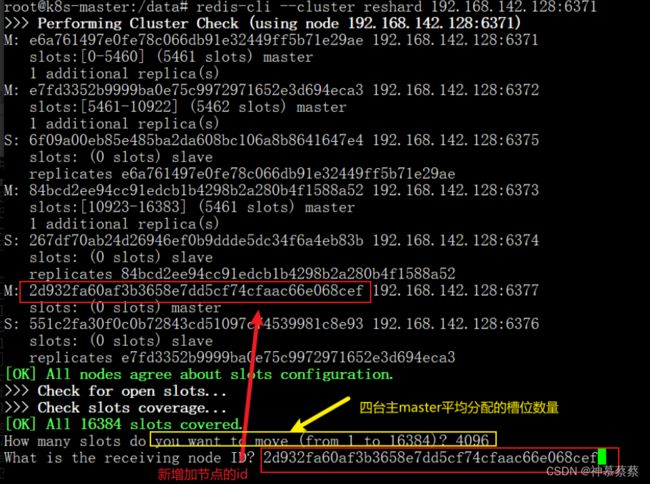


查看集群信息
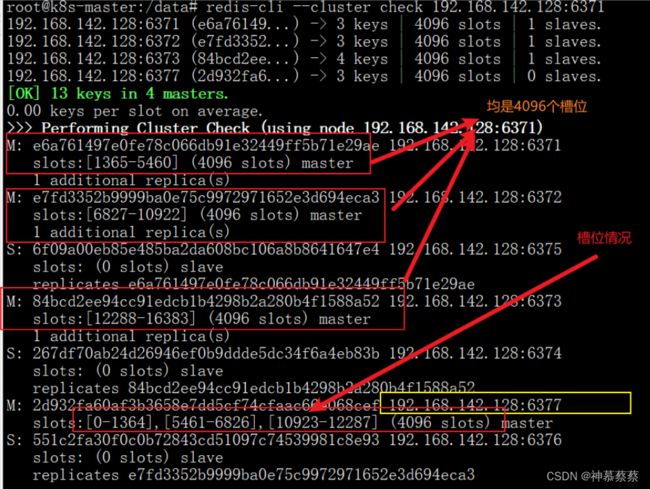
从上图可知,6377端口机器的槽位是另外3个主master机器分别划分给它的槽位
为主6377机器增加从节点6378机器
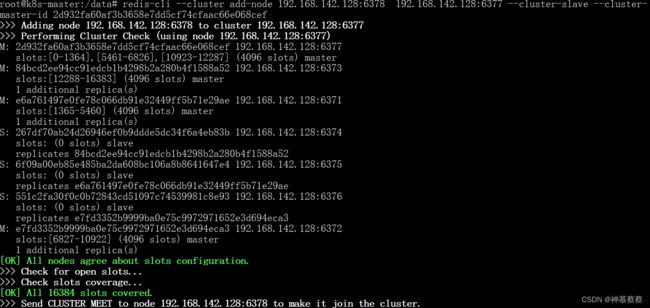
再次查看集群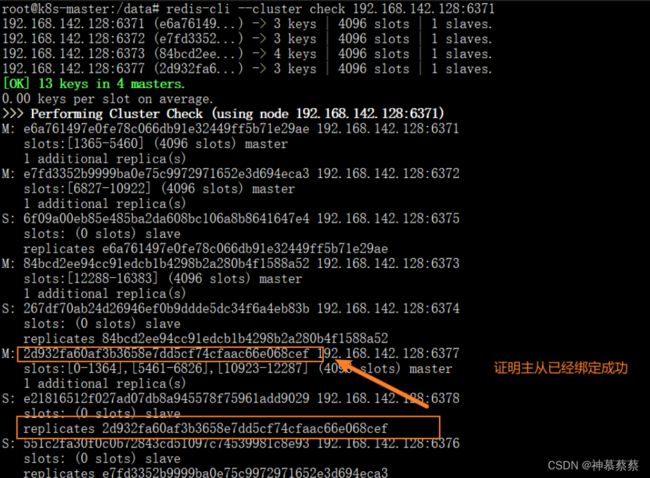
至此扩容四主四从完成!
9.6主从缩容案例
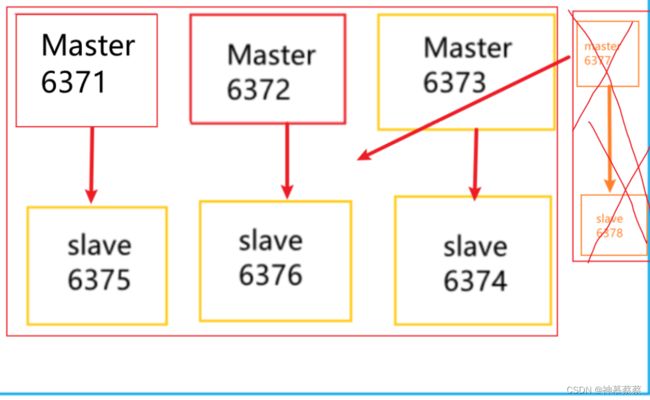
亿级的流量长时间已经不会再出现了,如何从四主四从恢复到三主三从?
第一步:将6378机器从redis集群中删除
#获得6378的节点ID
root@k8s-master:/data# redis-cli --cluster check 192.168.142.128:6378
S: e21816512f027ad07db8a945578f75961add9029 192.168.142.128:6378
slots: (0 slots) slave
#删除该节点
redis-cli --cluster del-node 192.168.142.128:6378 e21816512f027ad07db8a945578f75961add9029
>>> Removing node e21816512f027ad07db8a945578f75961add9029 from cluster 192.168.142.128:6378
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
第二步:将6377机器的槽位清空,重新分配
redis-cli --cluster reshard 192.168.142.128:6371
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? e6a761497e0fe78c066db91e32449ff5b71e29ae #被接收的槽位ID,此ID为6371机器
Source node #1: 2d932fa60af3b3658e7dd5cf74cfaac66e068cef #6377机器的ID,槽位全部交给6371
Source node #2: done
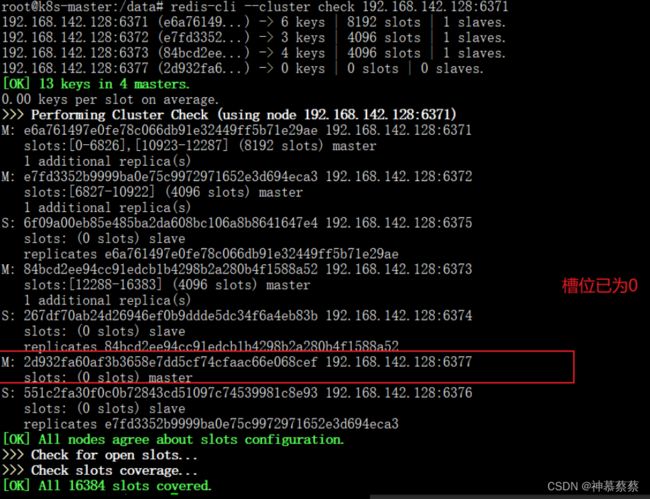
第三步:将6377机器从redis集群中删除
#获得6377的节点ID
redis-cli --cluster check 192.168.142.128:6371
M: 2d932fa60af3b3658e7dd5cf74cfaac66e068cef 192.168.142.128:6377
#删除该节点
redis-cli --cluster del-node 192.168.142.128:6377 2d932fa60af3b3658e7dd5cf74cfaac66e068cef
>>> Removing node 2d932fa60af3b3658e7dd5cf74cfaac66e068cef from cluster 192.168.142.128:6377
>>> Sending CLUSTER FORGET messages to the cluster...
>>> Sending CLUSTER RESET SOFT to the deleted node.
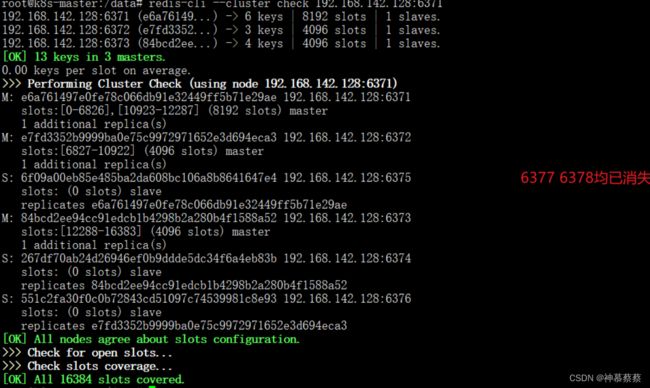
至此缩容完成!
10.docker 容器监控-CAdvisor+InfluxDB+Granfana
···等时间写