Shell编程之正则表达式与文本处理器
目录
一:正则表达式
1.1基础正则表达式
1.2扩展正则表达式
二:网上三剑客之——grep查找
2.1grep命令和正则表达式运用
三:文本小工具cut、sort、uniq、tr
3.1cut列截取工具
3.2sort排序
3.3uniq去重
3.4tr修改
四:网上三剑客之——sed 工具
4.1sed命令格式
4.2用法示例行演示
4.2.1输出符合条件的文本(p表示正常输出)
4.2.2 删除符合条件的文本(d)
4.2.3替换符合条件的文本
4.2.4迁移符合条件的文本
五:网上三剑客之——awk打印
5.1awk概述
5.2awk工作原理
5.3awk命令格式和参数
5.3.1awk常用内置变量:$1、$2、NF、NR、$0
5.3.2BEGIN和END的用法与区别
5.3.3模糊匹配,用~表示包含;!~表示不包含
5.3.4关于数值与字符串的比较
5.3.5awk高级用法
六:总结
引言:在生产环境中我们必不可少的使用网上三剑客:grep、sed、awk,我们需要了解其功能以及结合正则表达式和四种小工具cut、sort、uniq、tr来满足我们在工作时的各种需要。
一:正则表达式
正则表达式定义:
正则表达式,又称正规表达式,常规表达式
使用字符串来描述,匹配一系列符合某个规则的字符串
正则表达式通常用于判断语句棕,用来检查某一字符串是否满足某一格式
正则表达式组成
普通字符:大小写字母,数字,标点符号及一些其他符号 普通字符需要转义符
元字符:在正则表达式中具有特殊意义的专用字符 元字符不需要转义符
网上三剑客:grep(查找);set(修改);awk(打印)
1.1基础正则表达式
基础正则表达式是常用的正则表达式部分
除了普通字符外,常见到以下元字符
\:转义字符,\!、\n等
^:匹配字符串开始的位置
例:^a、^the、^#
$:匹配字符串结束的位置
例:word$
.:匹配除\n之外的任意的一个字符
例:go.d、g..d
*:匹配前面子表达式0次或者多次
例:goo*d、go.*d
[list]:匹配list列表中的一个字符
例:go[old]d、[abc]、[a-z]、[a-z0-9]
[^list]:匹配任意不在list列表中的一个字符
例:[^a-z]、[^0-9]、[^A-Z0-9]
\{n,m\}:匹配前面的子表达式n到m次,有\{n\}、\{n,\}、\{n,m\}三种格式
例:go\{2\}d、go\{2,3\}d、go\{2,\}d1.2扩展正则表达式
扩展正则表达式是对基础正则表达式的扩充
扩展元字符
+:匹配前面子表达式1次以上
例:go+d,将匹配至少一个o
?:匹配前面子表达式0次或者1次
例:go?d,将匹配gd或god
():将括号中的字符串作为一个整体
例:(xyz)+,将匹配xyz整体1次以上,如xyzxyz
|:以或的方式匹配字条串
例:good|food,将匹配good或者food
例:g(oo|la)d,将匹配good或者glad
二:网上三剑客之——grep查找
grep [选项] ... 查找条件 目标文件
| -E | 开启扩展(Extend)的正则表达式 |
| -c | 计算找到 ‘搜寻字符串’ 的次数 |
| -i | 忽略大小写的不同,所以大小写视为相同 |
| -o | 只显示被模式匹配到的字符串 |
| -v | 反向选择,亦即显示出没有 ‘搜寻字符串’ 内容的那一行!(反向查找,输出与条件不相符的行) |
| --color=auto |
可以将找到的关键词部分加上颜色的显示 |
| -n | 输出行号 |
egrep是grep的升级版
案例:
统计root字符行总行数

案例:
不区分大小写查找the所有的行

案例:
将/etc/passwd下查找不显示root的行
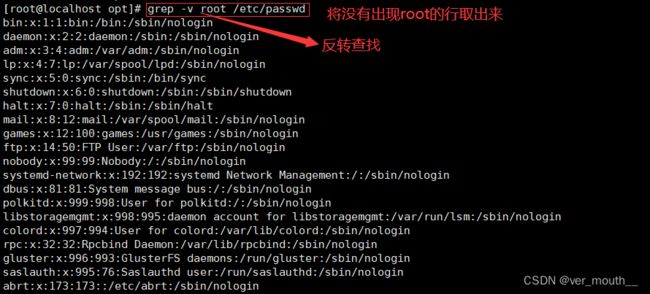
案例:
将非空行写入到test.txt文件

案例:
过滤出ip

 2.1grep命令和正则表达式运用
2.1grep命令和正则表达式运用
案例:查找特定字符

案例:利用中括号查找特定字符集
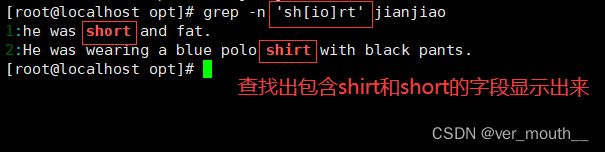
案例:查找含有oo的字符集

案例:[^]在正则表达式中是取反的意思
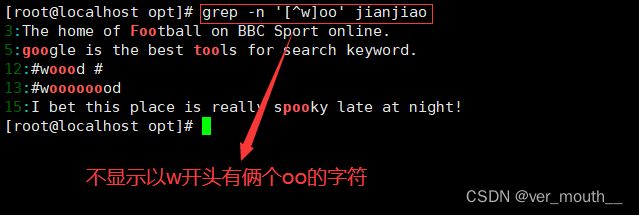
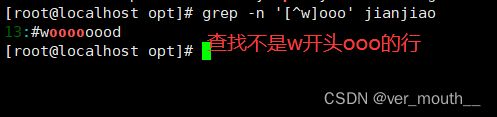

案例:查找行首和行尾

案例:以数字和字符开头
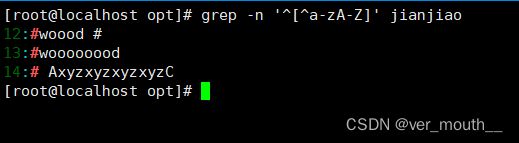
案例:查找以.号结尾的行

案例:查找空行
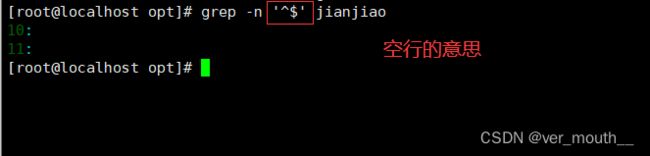
案例:
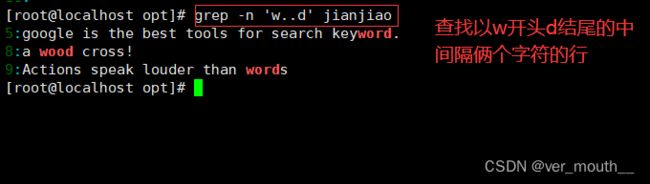
案例:

案例:
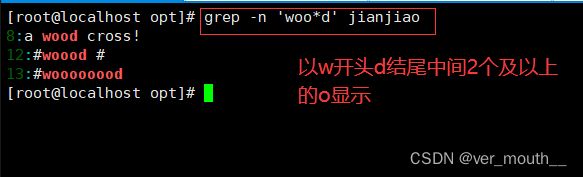
案例:
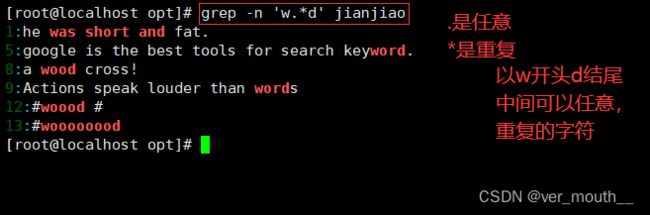
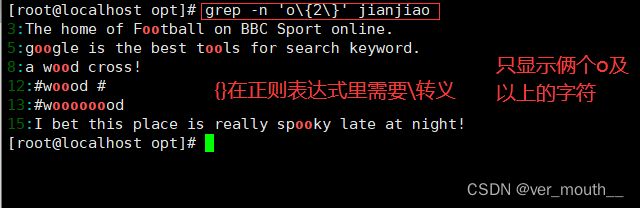
案例:只显示俩个o及以上的字符
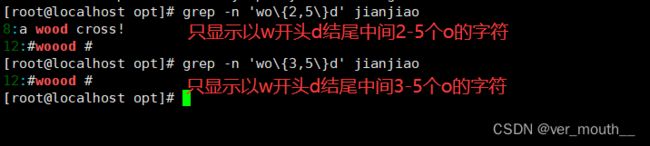
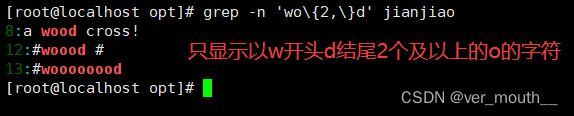
案例:只显示2到5个o以w开头d结尾的字符
三:文本小工具cut、sort、uniq、tr
3.1cut列截取工具
cut命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定file参数,cut命令将读取标准输入。必须指定 -b、-c或-f标志之一
| -b | 按字节截取 |
| -c | 按字节截取,常用于中文 |
| -d | 指定以什么为分隔符截取,默认为制表符 |
| -f | 通常和-d一起 |
案例:
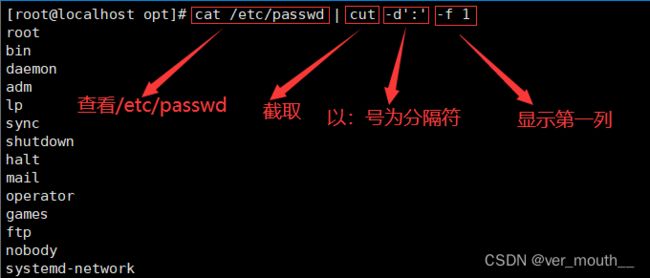
或
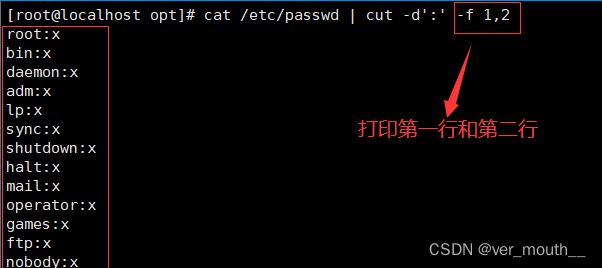
同时打印俩列
案例:按字节截取

编辑一个文档


3.2sort排序
sort是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。例如数据和字符的排序就不一样
语法:sort [选项] 参数
| -t | 指定分隔符,默认使用[Tab]键或空格分隔 |
| -k | 指定排序区域,哪个区间排序 |
| -n | 按照数字进行排序,默认是以文字形式排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行,注意:如果行尾有空格去重就不成功 |
| -r | 反向排序,默认是升序,-r就是降序 |
| -o | 将排序后的结果转存至指定文件 |
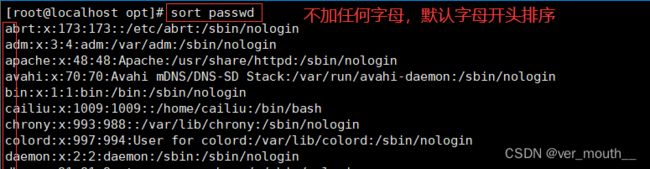
案例:sort后面不加任何字母,默认字母开头排序
案例:
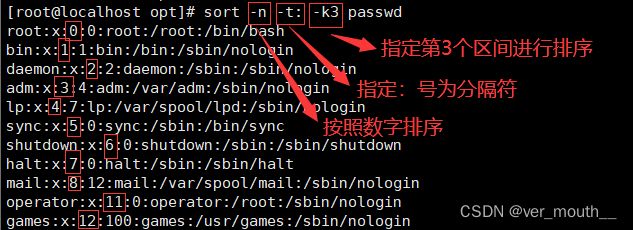
案例:

案例:

3.3uniq去重
uniq主要用于去除连续的重复行
注意:是连续的行,所以通常和sort结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行它不能去重
语法:uniq [选项] 参数
| -c | 对重复的行进行计算 |
| -d | 仅显示重复行 |
| -u | 仅显示出现一次的行 |
创建一个水果类型的文件

案例:

案例:

案例:
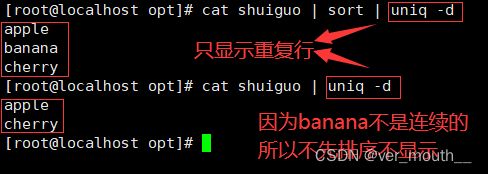
案例:
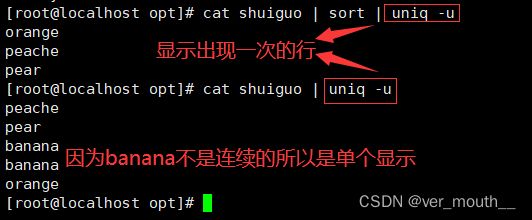
案例:
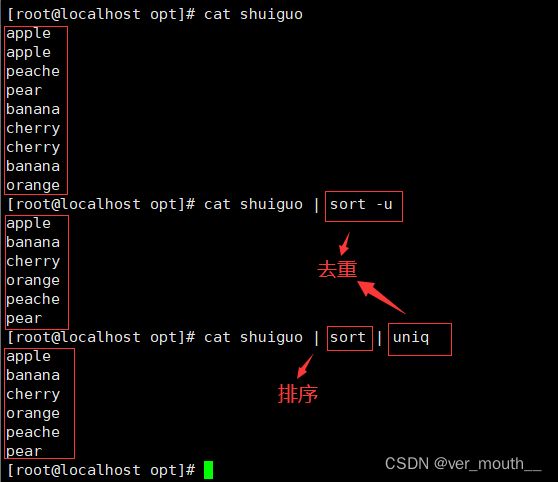
案例:
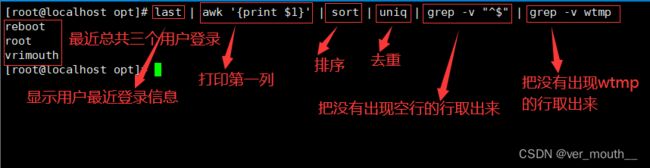
3.4tr修改
tr可以用一个字符来替换另一个字符,或者可以完全除去一些字符,也可以用它来除去重复字符
语法:tr [选项] ...SET1 [SET2]
从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出
| -d | 删除字符 |
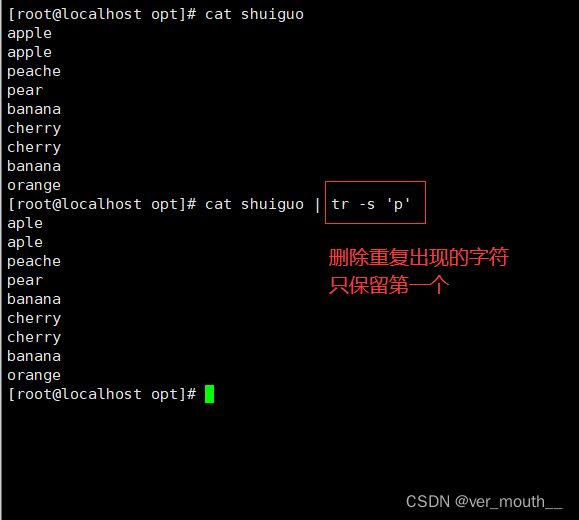
| -s | 删除所有重复出现的字符,只保留第一个 |
案例:
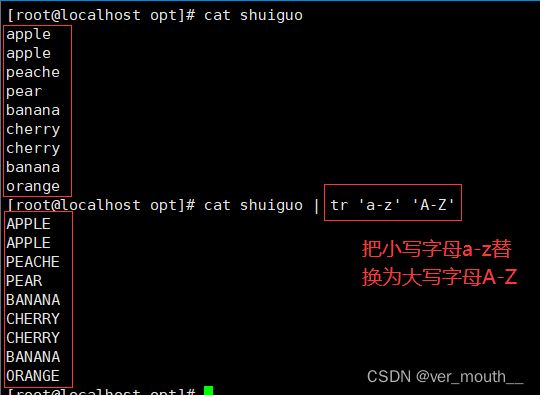
案例:
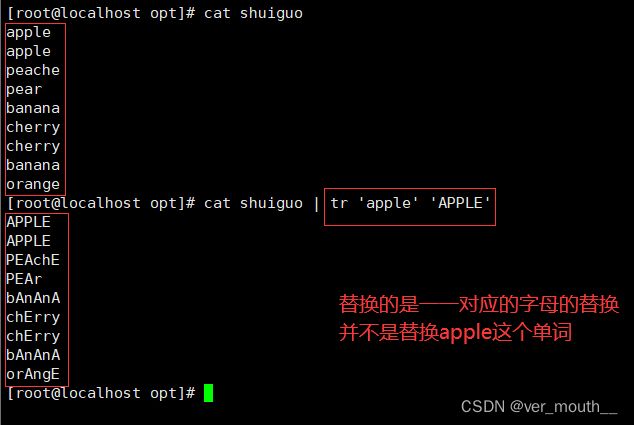
案例:

案例:

案例:

案例:
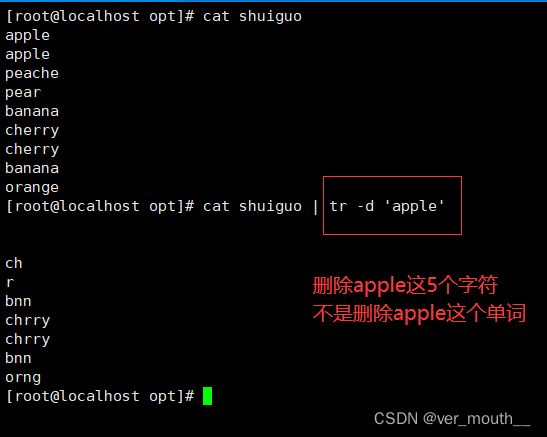
案例:

案例:
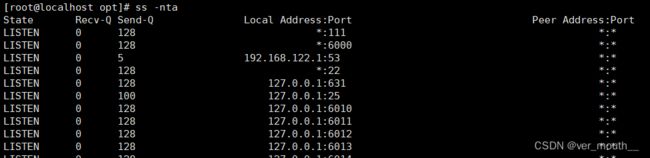
案例:查看系统当前主机的连接状态

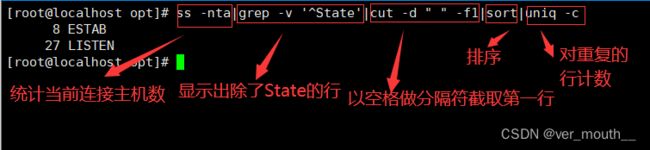
案例:
四:网上三剑客之——sed 工具
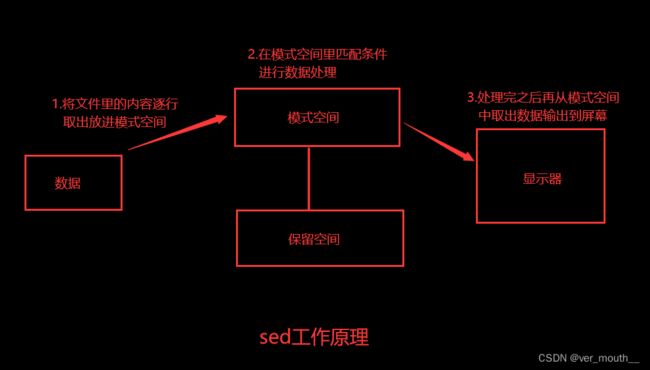
sed是一个强大而简单的文本解析转换工具,可以读取文本,并根据指定的条件对文本内容进行编辑(删除、替换、添加、移动等)
sed也可以在无交互的情况下实现相当复杂的文本处理操作,被广泛应用于Shell脚本中,
用以完成各种自动化处理任务
sed的工作流程主要包括读取、执行和显示三个过程
4.1sed命令格式
sed -e '编辑指令' 文件1 文件2 ...
sed -n -e '编辑指令' 文件1 文件2 ...
sed -i -e '编辑指令' 文件1 文件2 ...常用选项
| -e | 指定命令或者脚本来处理输入的文本文件 |
| -n | 只输出处理后的行,读入时不显示 |
| -i | 直接编辑文件,而不输出结果 |
| -f | 用指定的脚本文件来处理输入的文本文件 |
| -h | 显示帮助 |
| -r | 使用扩展正则表达式 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
编辑命令格式
[地址1] [,地址2] 操作 [参数]
地址:可数字、正则表达式、$,没有地址代表是所有行
操作:用于指定对文件操作的动作行为,也就是 sed 的命令。通常情况下是采用的“[n1[,n2]]”操作参数的格式。n1、n2 是可选的,
代表选择进行操作的行数,如操作需要在 5~ 20 行之间进行,则表示为“5,20 动作行为”。常见的操作包括以下几种
| a | 增加,在当前行下面增加一行指定内容 |
| c | 替换,将选定行替换为指定内容 |
| d | 删除,删除选定的行 |
| i | 插入,在选定行上面插入一行指定内容 |
| p | 打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以 ASCII 码输出,通常与“-n”选项一起使用 |
| s | 替换,替换指定字符 |
| y | 字符转换 |
4.2用法示例行演示
4.2.1输出符合条件的文本(p表示正常输出)
案例:输出所有内容
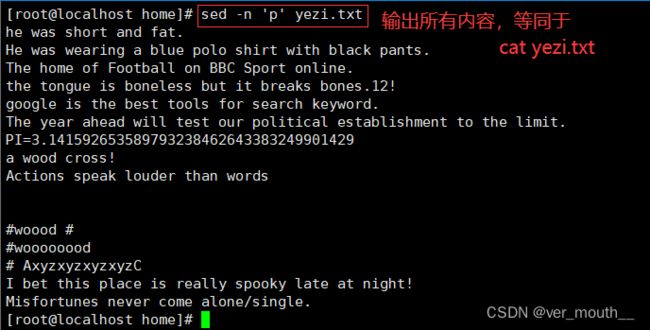
案例:输出第三行
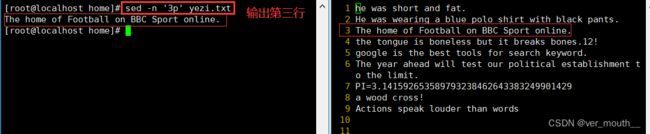
案例:输出3-5行
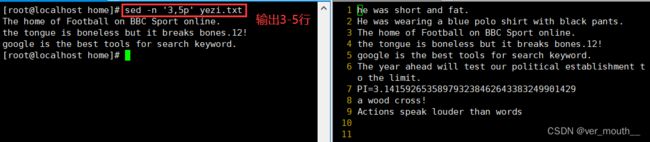
案例:sed -n 'p;n' yezi.txt 输出所有奇数行,n表示读入下一行资料
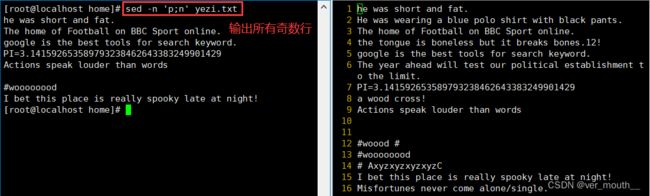
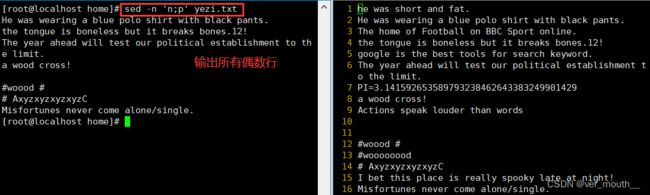
案例:sed -n 'n;p' yezi.txt 输出所有偶数行,n表示读入下一行资料
案例:sed -n '12,${n;p}' yezi.txt 输出12行之后的偶数行

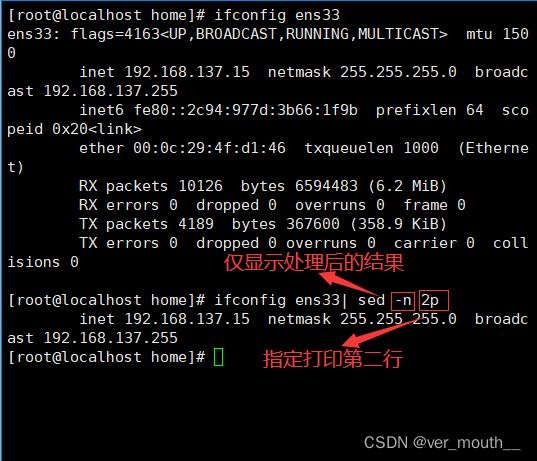
案例:打印ifconfig ens33第二行的所有内容
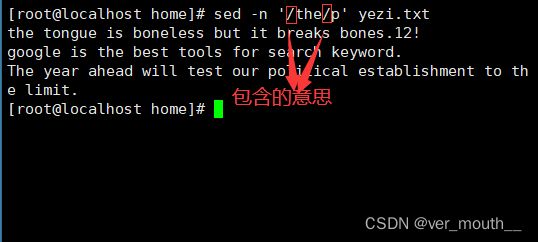
案例:将含有the字符的行都打印出来 // 是包含的意思
案例:从第四行开始显示有the的行

案例:显示含有the的行的行号 =是输出行号的意思

案例:显示以什么什么开头的行

案例:显示以什么什么结尾的行
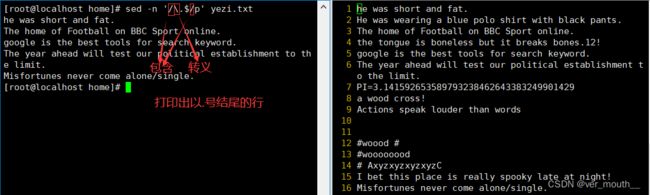
案例:以数字0-9作为结尾

案例:输出包含单词wood的行,\< \>代表单词边界
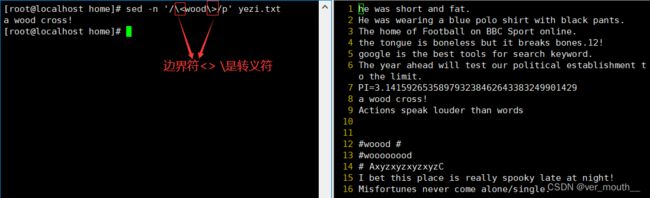
案例:nl打印出计算机文件的行数 空格不算

4.2.2 删除符合条件的文本(d)
案例:删除第四行

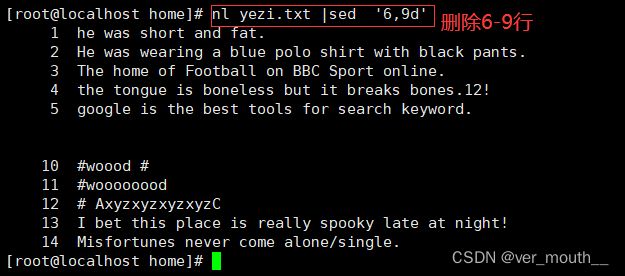
案例:删除6-9行
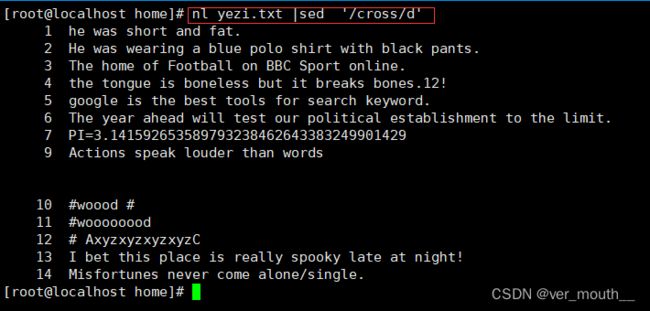
案例:删除包含cross的行
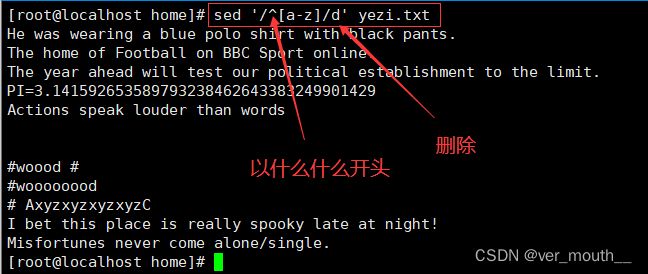
案例:删除不包含cross的行

案例:删除以a-z开头的行
案例:删除以.结尾的行

案例:删除空行:若是删除重复的空行,即连续的空行只保留一个,cat -s yezi.txt


4.2.3替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y
(字符转换)、g是全局的意思命令选项,常见的用法如下所示
案例:将每行中的第一个the替换为THE

案例: 将每行中的第2个l替换为L

案例: 将文件中的所有the替换为THE
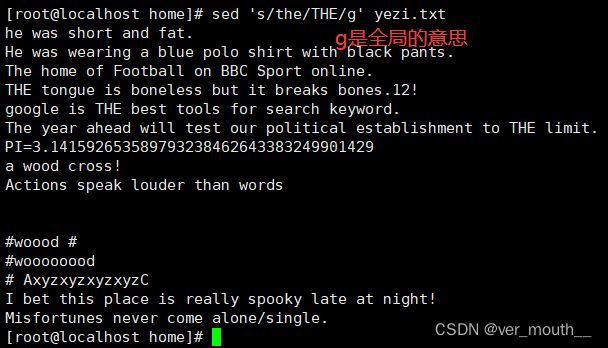
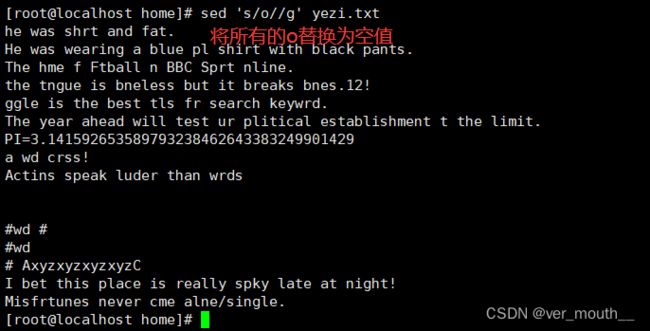
案例:将文件中的所有o删除(替换为空串)
案例: 在每行行首插入#号

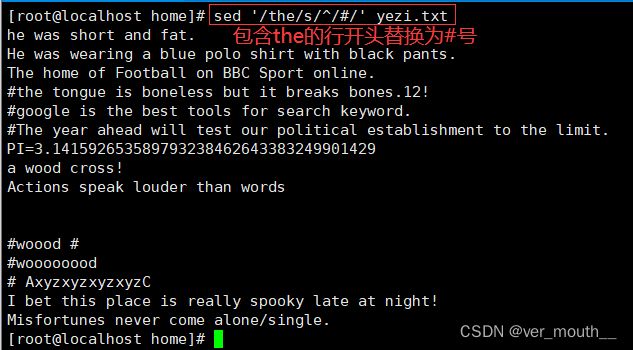
案例:在包含the的每行行首插入#号
案例:在每行行尾插入EOF字符串

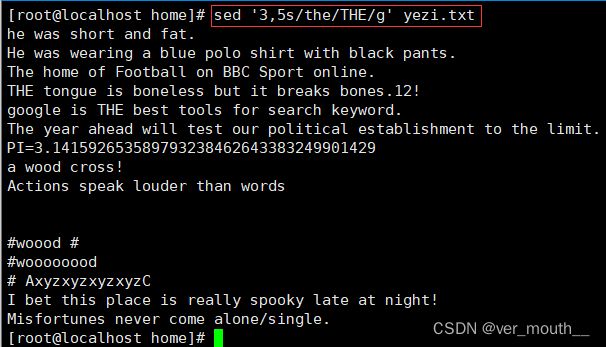
案例:将第3-5行中的所有the替换为THE
案例:将包含the的所有行中的o都替换为O

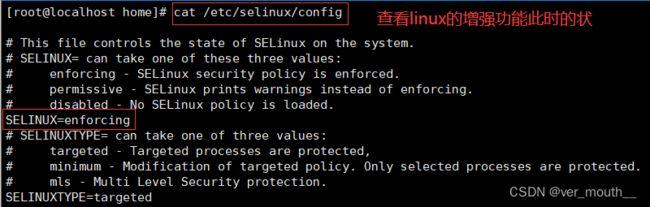
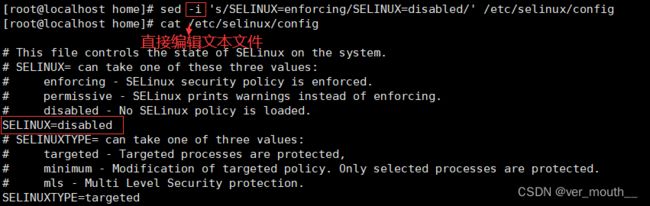
案例:关闭增强功能
4.2.4迁移符合条件的文本
在使用sed命令迁移符合条件的文本时,常用到以下参数
| H | 复制到剪贴板 |
| g、G | 将剪贴板中的数据覆盖/追加至指定行 |
| w | 保存为文件 |
| r | 读取指定文件 |
| a | 追加指定内容 |
| I、i | 忽略大小写 |
案例:将包含the 的行迁移至文件末尾,{;}用于多个操作

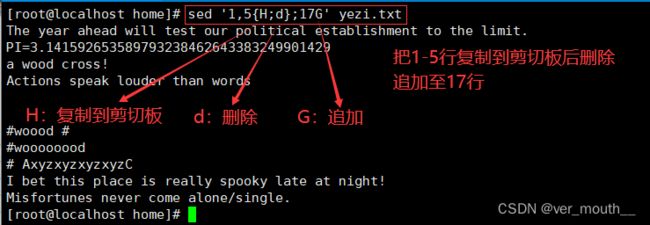
案例:将第1-5行内容转移至17行后
案例:将包含the的行另存为文件out.file

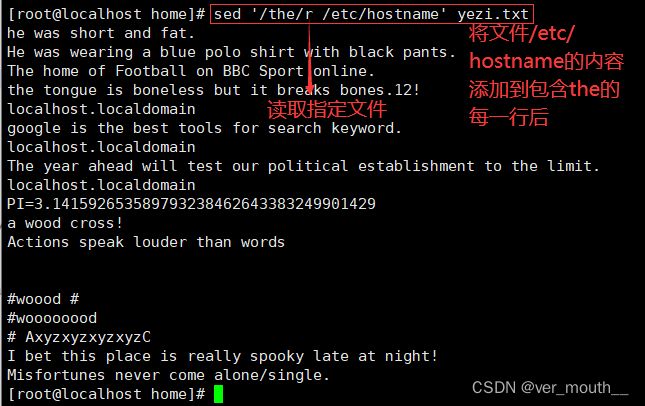
案例:将文件/etc/hostname的内容添加到包含the的每行以后
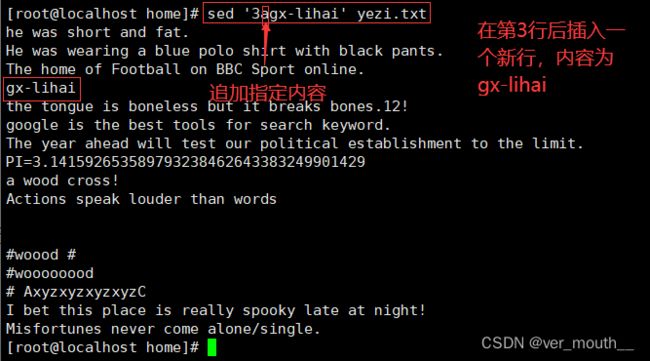
案例:在第3行后插入一个新行,内容为gx-lihai
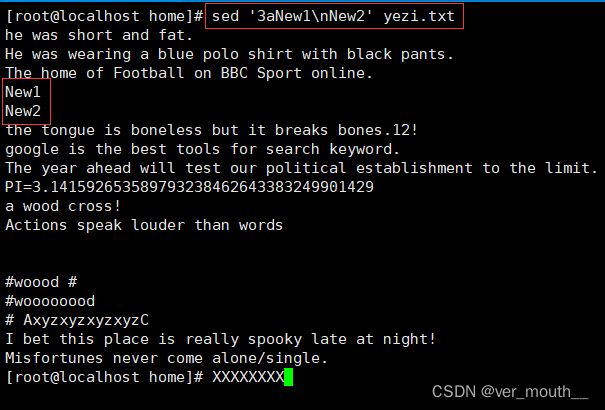
案例:在第3行后插入多行内容,中间的\n表示换行
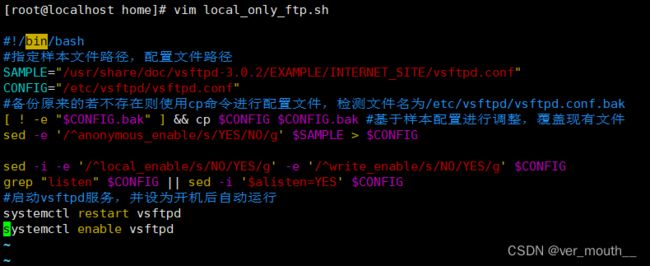
扩展:调整vsftpd服务配置,禁止匿名用户,但运行本地用户(也允许写入)
五:网上三剑客之——awk打印
5.1awk概述
awk是一种处理文本文件的语言,是一个强大的文本分析工具
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作
数据可以来自标准输入也可以是管道或文件
5.2awk工作原理
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
逐行读取文木,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
sed和awk的区别
sed命令常用于一整行的处理,而awk比较、倾向于将一行分成多个""字段"然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符"
&& 表示 "与"、|| 表示 "或"、! 表示 "非";还可以进行简单的数学运算,如+、-"、*、/、%、^分别表示加、减、乘、除、取余和乘方
5.3awk命令格式和参数
命令格式:awk关键字 选项 命令部分 '{xxxx}' 文件名
| FS |
指定每行文本的字段分隔符,默认为空格或制表位 |
| NF | 当前处理的行的字段个数 |
| NR | 当前处理的行的行号(序数) |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME | 被处理的文件名 |
| RS | 行分隔符 |
案例:
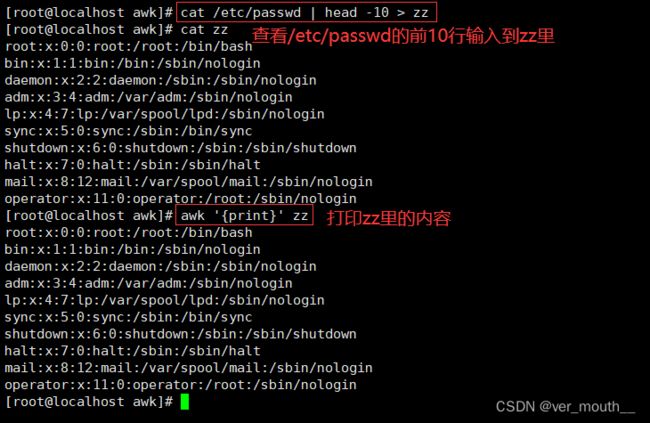
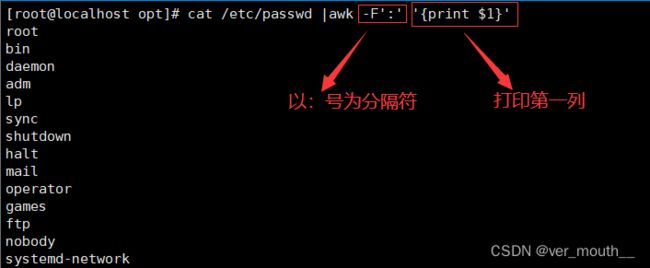
案例:以冒号做分隔符显示分隔后的第五列

案例:以冒号做分隔符显示分隔后的第一列和第二列

案例:用制表符作为分隔符输出

案例:定义多个分隔符,只要看到其中一个都算作分隔符
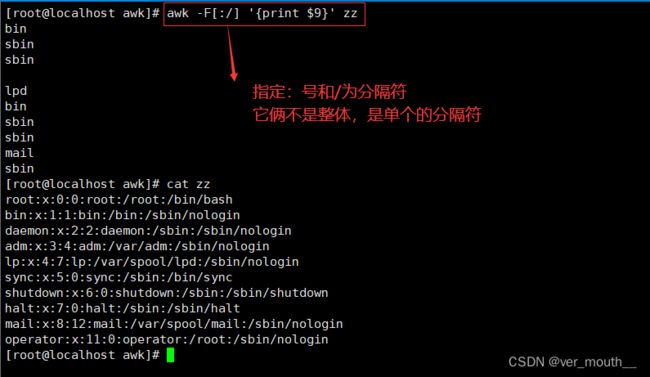
5.3.1awk常用内置变量:$1、$2、NF、NR、$0
$1:代表第一列
$2:代表第二列
$0:代表整行
NF:一行的列数
NR:行数
案例:打印包含root的整行内容

案例:打印每一行的列数,显示行号

案例:显示处理行的行号和整行内容

案例:打印第二行,不加print也一样,默认就是打印

案例:打印第二行的第一列
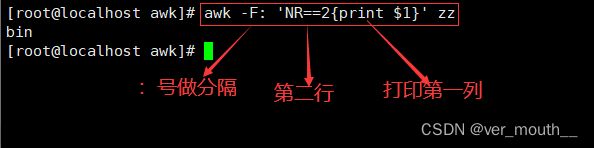
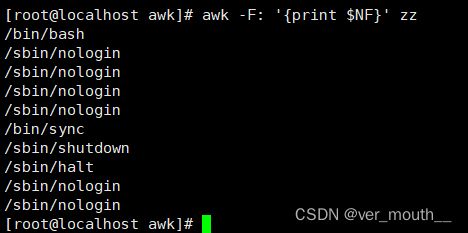
案例:打印最后一行
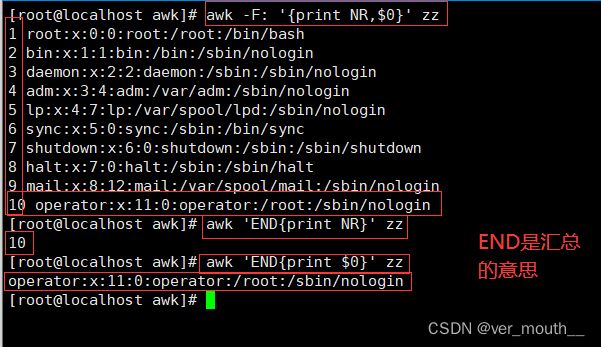
案例:打印总行数以及打印文件的最后一行,END是汇总的意思
案例:可以输入中文

扩展案例:网卡的ip、流量
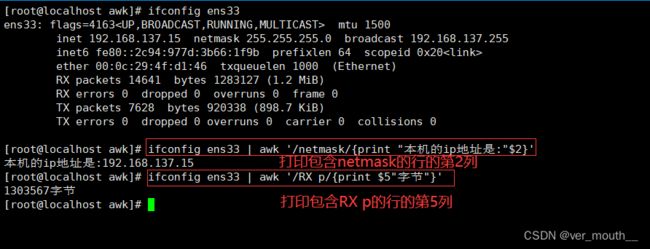
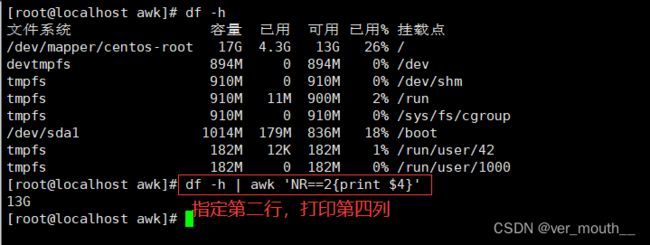
扩展案例:根分区的可用量
5.3.2BEGIN和END的用法与区别
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
BEGIN:一般用来做初始化操作,仅在读取数据记录之前执行一次
END:一般用来做汇总操作,仅在读取完数据记录之后再执行一次

awk的运算案例:

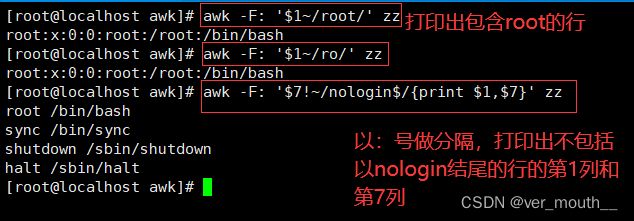
5.3.3模糊匹配,用~表示包含;!~表示不包含
5.3.4关于数值与字符串的比较
比较符号:== != <= >= < >
案例:打印行号为第5行的内容
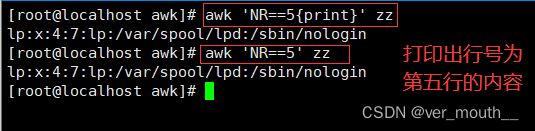
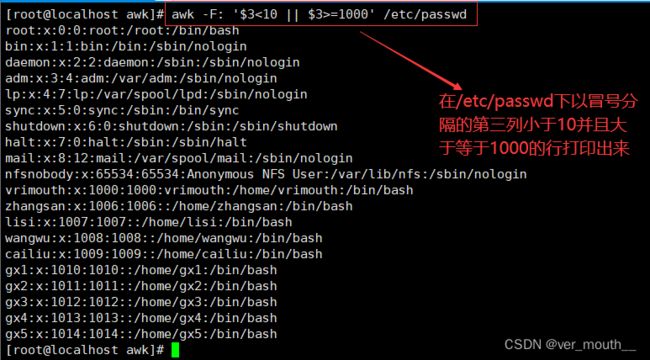
案例: 打印行号小于5行的内容;以冒号做分隔第三列的值为0的行

案例:精确匹配

案例:数字与字符串比较和逻辑运算结合

| NF | 字段个数(读取的列数) |
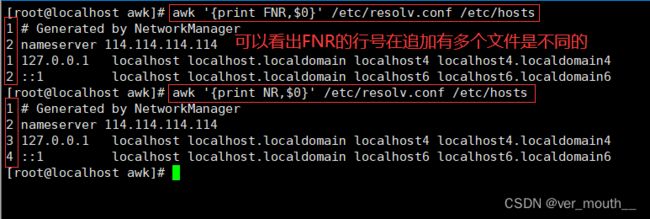
| NR | 记录数(行号)从1开始,新的文件延续上面的技术,新文件不从1开始 |
| FNR | 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数 |
| FS | 输入字段分隔符,默认是空格 |
| OFS | 输出字段分隔符,默认是空格 |
| RS | 输入行分隔符,默认为换行符 |
| ORS | 输出行分隔符,默认为换行符 |
案例:在打印之前定义字段分隔符为冒号


案例:FNR和NR的区别
案例:RS和ORS的区别


5.3.5awk高级用法
定义引用变量
案例:

案例:

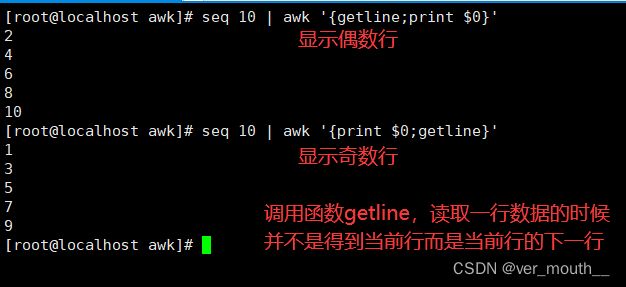
调用函数getline:读取一行数据的时候并不是得到当前行而是当前行的下一行

案例:显示偶数行;显示奇数行
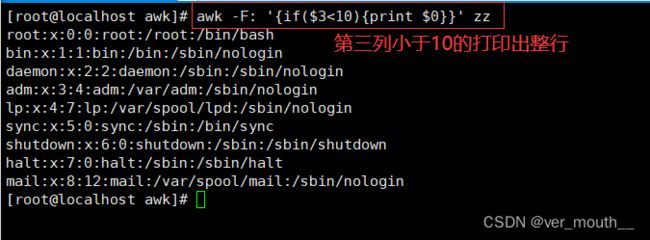
awk中使用if语句
awk的if语句也分为单分支、双分支和多分支
单分支为if () {}
双分支为if() {}else{}
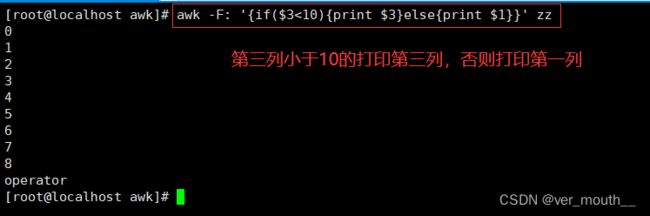
多分支为if() {}else if () {}else{}
案例:
案例:
六:总结
本篇我们学习了正则表达式中基础正则表达式和扩展正则表达式元字符的用法,以及网上三剑客grep、sed、awk的使用方法和结合正则表达式的用法案例以及文本小工具cut、sort、uniq、tr的使用方法案例,掌握其用法,可以使我们在生产环境中更方便的进行工作。