JAVA正则解析Pattern.compile(regex)出现java.util.regex.PatternSyntaxException
问题
最近线上项目出现了java.util.regex.PatternSyntaxException,项目也没什么改动,除了特殊
字符表的字符集由于原来是utf8编码的字符集,不支持4个字节的字符,修改成了utf8mb4字节,其余
的也没什么改动.异常原因如下
异常贴图

解析
private void everyMsgInDB(List<MessageSampleMsg> msgs,String speCharRegex,Map<String, String> varWordMap){
...省略
content = DataFormat.removeSpeChar(content, speCharRegex); //问题在这
...省略
}
public static String removeSpeChar(String content, String regex) {
Pattern p = Pattern.compile(regex); //最终问题确定在这里
Matcher matcher = p.matcher(content);
return matcher.replaceAll("");
}
到这发现原来问题出现在组装的regex,看下面regex的组装
public static String getSpeCharRegex(Connection conn) {
SpecialCharDao specialCharDao = DaoFactory.getSpecialCharDao();
List<String> spchars = null;
try {
spchars = specialCharDao.getAll(conn);//这是获取所有的特殊字符
} catch (SQLException e) {
log.error("特殊字符查询失败", e);
}
StringBuffer sbf = new StringBuffer();
//将每个特殊字符用或和转义字符去拼接
for (String spchar : spchars) {
sbf.append("\\").append(spchar).append("|");
}
return sbf.substring(0, sbf.length() - 1);
}
}
拼接好的regex如图一所示,那么为什么\ying这里会出现异常呢?接下来分析下
Pattern.conpile(String regex)源码,下面的源码是JDK1.8
//1.
public static Pattern compile(String regex) {
return new Pattern(regex, 0);
}
//2.
private Pattern(String p, int f) {
pattern = p;
flags = f; //这里flags == 0
//0 & 任何数都 == 0,这里可忽略
if ((flags & UNICODE_CHARACTER_CLASS) != 0)
flags |= UNICODE_CASE;
//可忽略
capturingGroupCount = 1;
localCount = 0;
//这个pattern就是前面传进来的字符串【\ying】
if (pattern.length() > 0) {
//然后到这里面
compile();
} else {
root = new Start(lastAccept);
matchRoot = lastAccept;
}
}
//3.
private void compile() {
...省略
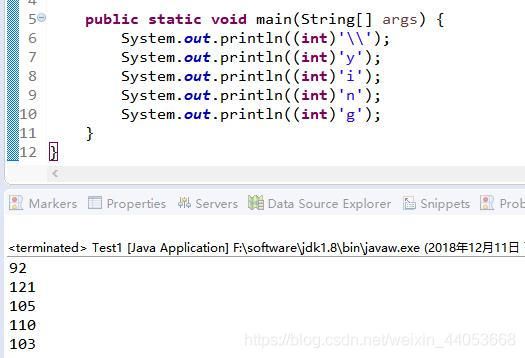
temp = new int[patternLength + 2];//这里temp是字符的ASCII码对应的十进制数
// 这里是组装temp数组,见下面的temp数组贴图
for (int x = 0; x < patternLength; x += Character.charCount(c)) {
c = normalizedPattern.codePointAt(x);
if (isSupplementary(c)) {
hasSupplementary = true;
}
temp[count++] = c;
}
...省略
if (has(LITERAL)) {
matchRoot = newSlice(temp, patternLength, hasSupplementary);
matchRoot.next = lastAccept;
} else {
// 来到递归下降解析
matchRoot = expr(lastAccept);
}
...省略
}
//4.
private Node expr(Node end) {
...省略
for (;;) {
//会到这里
Node node = sequence(end);
Node nodeTail = root; // double return
...省略
}
...省略
}
//5.
private Node sequence(Node end) {
...省略
LOOP: for (;;) {
//前面的temp为{92,121,105,110,103},这里会拿到ch == 92
//对应的ASCII为\\
int ch = peek();
switch (ch) {
...省略
//所以匹配到了这里
case '\\':
//到这里看一下下一个是不是还要跳过
//下一个为121,对应的ASCII为y
ch = nextEscaped();
if (ch == 'p' || ch == 'P') {
boolean oneLetter = true;
boolean comp = (ch == 'P');
ch = next(); // Consume { if present
if (ch != '{') {
unread();
} else {
oneLetter = false;
}
node = family(oneLetter, comp);
//所以来到这里
} else {
//这一步是让指针往前回退一会
//即这时,指针来到了92的位置
unread();
//然后来到这里
node = atom();
}
break;
...省略
}
}
//6.继续下来
private Node atom() {
int first = 0;
...省略
int ch = peek();
for (;;) {
switch (ch) {
...省略
//因为前面指针回退,所以匹配到了这里
case '\\':
ch = nextEscaped();
if (ch == 'p' || ch == 'P') {
if (first > 0) {
unread();
break;
} else {
boolean comp = (ch == 'P');
boolean oneLetter = true;
ch = next();
if (ch != '{')
unread();
else
oneLetter = false;
return family(oneLetter, comp);
}
}
unread();
prev = cursor;
//然后来到这里
//这里进去的参数为false,true,false
ch = escape(false, first == 0, false);
...省略
}
private int escape(boolean inclass, boolean create, boolean isrange) {
//这里是让指针指向y,还记得前面指针已经回退到\了吗
int ch = skip();
//下面的switch如果是return就没问题
//如果是break就要抛出异常了,程序就中断了
switch (ch) {
case '0':
return o();
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
if (inclass)
break;
if (create) {
root = ref((ch - '0'));
}
return -1;
...省略
case 'l':
//这里也有问题
case 'm':
break;
case 'n':
return '\n';
//看这里,如果是o,p,q会被break,就会到最一行抛出异常
case 'o':
case 'p':
case 'q':
break;
...省略
case 'w':
if (create)
root = has(UNICODE_CHARACTER_CLASS) ? new Utype(UnicodeProp.WORD) : new Ctype(ASCII.WORD);
return -1;
case 'x':
return x();
//还记得我是的\ying,这里匹配的是y所以抛出异常
//到这里算是找到问题的根源了
case 'y':
break;
case 'z':
if (inclass)
break;
if (create)
root = new End();
return -1;
default:
return ch;
}
throw error("Illegal/unsupported escape sequence");
}
下图是 int[] temp 对应的数组
结论
如果要通过以下方式进行正则匹配一定要注意,加转移字符的时候一定要注意,注意字符后面一定不要跟a-zA-Z0-9否则有可能造成异常的出现。
public static String removeSpeChar(String content, String regex) {
Pattern p = Pattern.compile(regex);
Matcher matcher = p.matcher(content);
return matcher.replaceAll("");
}
所以代码修改了一下。
public static String getSpeCharRegex(Connection conn) {
SpecialCharDao specialCharDao = DaoFactory.getSpecialCharDao();
List<String> spchars = null;
try {
spchars = specialCharDao.getAll(conn);
} catch (SQLException e) {
log.error("特殊字符查询失败", e);
}
StringBuffer sbf = new StringBuffer();
for (String spchar : spchars) {
//添加了这么一句
//如果字符不是以A-Za-z0-9之间的需要添加转移字符
if(!spchar.matches("[A-Za-z0-9]*")){
sbf.append("\\");
}
sbf.append(spchar).append("|");
}
return sbf.substring(0, sbf.length() - 1);
}