图像分类(pytorch实现)
目录
一、问题
1、问题描述
2、问题分析
二、网络结构
1、VGG
2、VGG网络结构
三、数据集
四、实验步骤
1、数据集
(1)数据集的获取
(2)数据集的处理
(3)数据集的读取
2、模型读取
3、测试
五、实验结果
六、代码
一、问题
1、问题描述
1) 对Cifar-10图像数据集,用卷积神经网络进行分类,统计正确率。
2) 选用Caffe, Tensorflow, Pytorch等开源深度学习框架之一,学会安装这些框架并调用它们的接口。
3) 直接采用这些深度学习框架针对Cifar-10数据集已训练好的网络模型,只做测试。
2、问题分析
首先在官网上下载cifar-10数据集,因为是用python作为开发环境,所以选择python version版本下载,然后对其进行相应的图片格式转换。
最后在网上下载他人训练好的网络模型,进行测试,计算出正确率即可。
二、网络结构
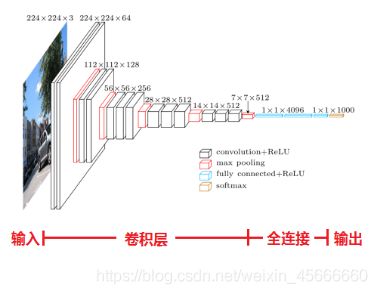
1、VGG
VGG 网络是由conv、pool、fc、softmax层组成。VGG网络的卷积层,没有缩小图片,每层pad都是有值的,图片缩小都是由pool来实现的。
2、VGG网络结构

三、数据集
该数据集共有60000张彩色图像,这些图像是32*32,分为10个类,每类6000张图。这里面有50000张用于训练,构成了5个训练批,每一批10000张图;另外10000用于测试,单独构成一批。测试批的数据里,取自10类中的每一类,每一类随机取1000张。抽剩下的就随机排列组成了训练批。注意一个训练批中的各类图像并不一定数量相同,总的来看训练批,每一类都有5000张图。
下面这幅图就随机列举了10类,每类各10幅图片。

四、实验步骤
1、数据集
(1)数据集的获取
在http://www.cs.toronto.edu/~kriz/cifar.html官网上下载cifar-10数据集,因为是用python作为开发环境,所以选择python version版本下载。
![]()
下载解压之后,出现5个数据集和1个测试集:

(2)数据集的处理
因为我们只需要对数据集进行测试并统计正确率,所以仅需对测试集进行处理。
先对图像进行归一化,我们使用torchvision中的正则化函数Normalize()传入的参数为[0.485,0.456,0.406],[0.229,0.224,0.225]
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])(3)数据集的读取
使用torch中的DataLoader构建这些数据集对象的迭代器。
testset = torchvision.datasets.CIFAR10(root='E:/dataset', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=0)2、模型读取
state = torch.load('./checkpoint/ckpt.t7')3、测试
Total为测试的个数,accuracy为测试正确的个数;
total += labels.size(0)
accuracy += (predicted == labels).sum()统计正确率。(正确率=正确个数/测试个数*100%)
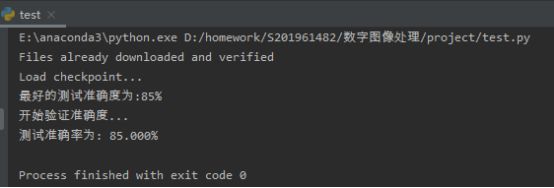
print('测试准确率为: %.3f%%' % (100 * accuracy / total))五、实验结果
六、代码
1、 nn_module_sample.py
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 2
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 3
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 4
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 5
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 6
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 7
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 8
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 9
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 10
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 11
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 12
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 13
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.AvgPool2d(kernel_size=1, stride=1),
)
self.classifier = nn.Sequential(
# 14
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(),
# 15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
# 16
nn.Linear(4096, num_classes),
)
# self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
if __name__ == '__main__':
import torch
# 使用gpu
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
net = VGG16().to(device)
print(net)2、test.py
import torch
import torchvision
import torchvision.transforms as transforms
from nn_module_sample import VGG16
import os
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
testset = torchvision.datasets.CIFAR10(root='E:/dataset', train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False, num_workers=0)
# 使用gpu
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
# 模型定义 VGG16
net = VGG16().to(device)
def test():
print("Load checkpoint...")
assert os.path.isdir('checkpoint'), 'Error: no checkpoint directory found'
state = torch.load('./checkpoint/ckpt.t7')
net.load_state_dict(state['state_dict'])
best_test_acc = state['acc']
# pre_epoch = state['epoch']
print("最好的测试准确度为:{}%".format(best_test_acc.item()))
print("开始验证准确度...")
with torch.no_grad():
accuracy = 0
total = 0
for data in testloader:
# 开始测试
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 返回每一行中最大值的那个元素,且返回其索引(得分高的那一类)
total += labels.size(0)
accuracy += (predicted == labels).sum()
# 输出测试准确率
print('测试准确率为: %.3f%%' % (100 * accuracy / total))
if __name__ == '__main__':
test()