里里外外详解URL编码(zt)
RFC 1738中对URL有明确规定,URL必须由英文字母、数字、和某些标点符号组成,不能使用其他文字,因此所有包含中文的URL都应当是非法的!其实,浏 览器自作聪明的为我们做了很多人性化的hack.
URL全称Uniform Resource Locator,直译为“统一资源定位符”,也就是网页地址,是互联网上任意角落都可以访问到的,言外之意是说,URL不受国 别、种族、语言、编码差异的约束,是编码无关的。然而我们常常在浏览器中敲入诸如“http://url/中文”的url,也能正确访问,既然url中包 含中文,那么如何让其他国家那些没有中文编码的计算机上也能访问到相同的网址呢?
RFC 1738中对URL有明确规定,URL必须由 英文字母、数字、和某些标点符号组成,不能使用其他文字,因此所有包含中文的URL都应当是非法的!其实,浏览器自作聪明的为我们做了很多人性化的 hack,比如,浏览器会对地址栏中填入的url进行先编码再使用,因此,不论怎样,一个正确封装的http包中的URI字段一定不会出现中文字符。也就 是说,实际发生作用的url也一定如RFC 1738中所言,非ascII码要先转换成ascII码序列,但RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)和web程序作者自己决定。这导致“URL编码”成为了一个混乱的领域。也会导致一些奇怪的 现象发生。
我们分别在firefox和ie用baidu和google搜索“淘宝”。
在firefox中百度“淘宝”, 出现: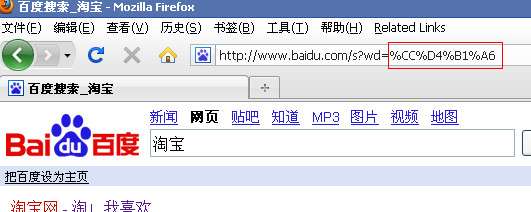
实际发生请求的url为: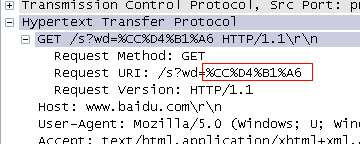
同地址栏中显示是一致的,搜索结果也正确。在地址栏中直接输入“http://www.baidu.com /s?wd=淘宝”也是如此,在firefox中google“淘宝”:
实际发生请求的url为:
可以看到,实际发生请求的url和地址栏显示的url不一致,搜索结果正确。这时,重新请求地址栏的“url” (不是刷新),地址栏显示为:
实际发生的请求为:
这时,地址栏和实际发生的请求是一致的,搜索结果正确。进一步分析之前,先看看js里的两个运算
我们知道escape()是计算unicode编码,传说中正统的URL编码encodeURI()则是进行 utf-8编码,(简单讲,unicode编码是纯粹的编码方式,utf-8是unicode编码的一种实现,即将二进制unicode编码再编码,以一 种比较节约空间的方式对unicode全集进行二次编码)。escape()的结果是将每个unicode字符以%u分割,encodeURI是每个字节 以%分割,也就是说,“淘”和“宝”的unicode编码分别是“6DD8”和“5B9D”,他们的utf-8编码分别是“E6 B7 98”和“E5 AE 9D”,此外,他们的gbk编码分别为“CC D4”和“B1 A6”。
初步得到结论一:在firefox中的百度搜索,通过 form提交的中文转换为gbk编码,参与http包的封装。在ff中google搜索,通过form提交的中文转换为utf-8编码,但显示在地址栏中 的url是其中文映像(如果这时将地址栏复制下来,复制的实际是转码后的url,无法复制url中的中文字符)。如果直接在ff地址栏中输入中文url, 这时,url里的中文字符一律进行gbk编码,不管百度还是google都是如此。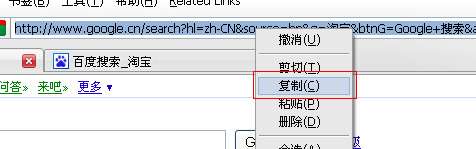
复制不了里面的中文
如此看来,firefox默认处理url里的中文,都是通过gbk编码进行编码的,这 里和网页编码无关(浏览器无法检测将要被访问的网页编码)。
那么,百度和google对unicode编码和utf-8编码的支持情况如 何呢?
“淘宝”的unicode编码为“%6D%D8%5B%9D”,在ff中访问“http://www.baidu.com /s?wd=%6D%D8%5B%9D”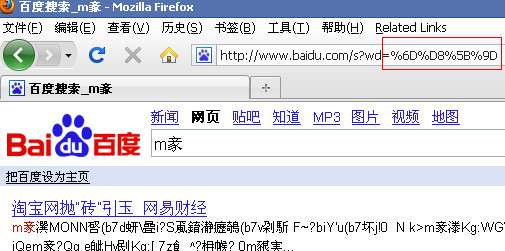
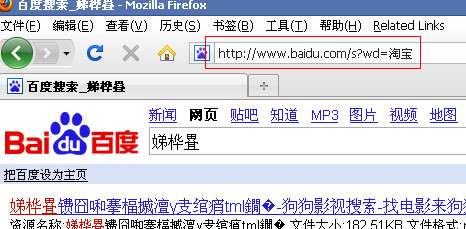
也是乱码。
再来看google能否解析utf-8编码,在ff中访问 “http://www.google.cn/search?q=%E6%B7%98%E5%AE%9D”,得到,

结果正确,google可以正确解析utf-8编码。再看google能否解析unicode编码,在ff中访问 “http://www.google.cn/search?q=%6D%D8%5B%9D”,得到:
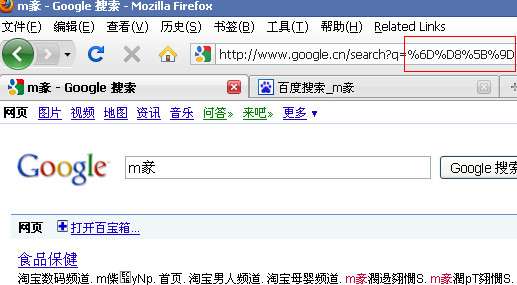
是乱码。
初步得到结论二,所谓正统的URL编码encodeURI并不是万能的,要看每个网站的 实现,百度搜索就不支持这个所谓正统,而是一律采用gbk系的编码作为自己的URL编码。google支持“正统URL编码”,也支持gbk系的编码,更 健壮一些。
再来看IE中的情况,在ie中在百度和google中通过form搜索“淘宝”结果和ff中一致,但直接在地址栏中输 入中文url就有些奇怪了,在ie中访问“http://www.baidu.com/s?wd=淘宝”,得到,
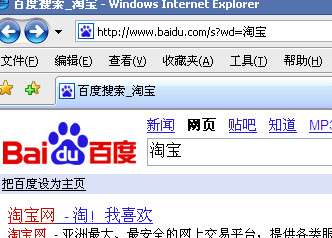
结果当然正确,实际发生的请求为
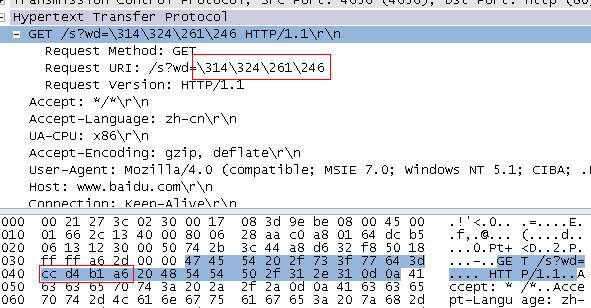
这里可以看到,ie发起的http请求甚至没有经过任何编码,硬生生的将“淘宝”当作原始gbk字符,这样,其他 语言编码的操作系统就无法识别这个url,这里的“\314\324\261\246”是一种我也不知道是什么东西的编码,甚至连wireshark都不 知道,因为“http://www.baidu.com/s?wd=\314\324\261\246”明显是一个错误的请求。
此 外,unicode编码和utf-8编码后的url在ie下的表现和ff中一致。
由此,可得到结论:
1,RFC 1738文档很粗糙,导致了url编码标准缺失。实际url编码标准和操作系统、浏览器以及web应用有关;
2,ff对非ascII码的url进 行编码,编码方式和操作系统默认编码一致
3,google支持“正统的URL编码”(即utf-8 URL编码:utf-8字节中间加上%),百度不支持
4,IE不对非ascII码的url进行编码,直接根据操作系统默认编码发送url请求,换 句话说,ie甚至不遵循RFC 1738,或者说ie对URL的转码实现有bug。
5,ff在地址栏显示的url进行了hack,但hack的有 bug,开发时要注意。
基于此,我们在web开发过程中要做到:
1,要单独处理编码问题,建议采用统一的URL编码,不 论是gbk还是unicode还是URI(utf-8),必须要统一,鉴于大多数人稀里糊涂的认为URI是正宗的URL编码,因此建议还是在前后端都做 URI编码和解码。
2,明智选择web app的编码,utf-8为最佳,gbk为最次。
3,编码问题要调试浏览器兼容性。