Entity FrameWork 与 NHibernate
1 Nhibernate

展示了NHibernate在数据库和用程序之间提供了一个持久层。
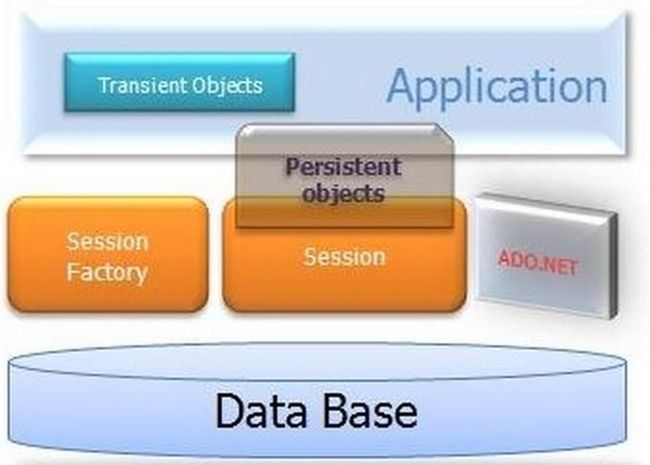
应用程序自己提供ADO.NET连接,并且自行管理事务.NHibernate体系结构如图1-51所示。它体现了NHibernate如何使用数据库和配置文件数据来为应用程序提NHibernate 供持久化服务(和持久化的对象)。
SessionFactory(NHibernate.IsessionFactory):它是Session的工厂,是ConnectionProvider的客户。可以持有一个可选的(第二级)数据缓存,可以在进程级别或集群级别保存的可以在事物中重用的数据。
会话(NHibernate.ISession):单线程,生命期较短的对象,代表应用程序和持久化层之间的一次对话。封装了一个ADO.NET连接,也是Transaction的工厂。保存有必需的(第一级)持久化对象的缓存,用于遍历对象图,或者通过标识符查找对象。
持久化对象(Persistent)及其集合(Collections):生命期较短的单线程的对象,包含了持久化状态和商业功能。这些可能是普通的对象,唯一特别的是现在从属于且仅从属于一个Session。一旦Session被关闭,它们都将从Session中取消联系,可以在任何程序层自由使用(比如,直接作为传送到表现层的DTO,数据传输对象)。
临时对象(Transient Object)及其集合(Collection):目前没有从属于一个Session的持久化类的实例。这些可能是刚刚被程序实例化,还没有来得及被持久化,或者是被一个已经关闭的Session实例化。
事务Transaction (NHibernate.ITransaction):(可选)单线程,生命期较短的对象,应用程序用其来表示一批工作的原子操作,它是底层的ADO.NET事务的抽象。一个Session在某些情况下可能跨越多个Transaction事务。
ConnectionProvider(NHibernate.Connection.ConnectionProvider):(可选)ADO.NET连接的工厂。从底层的IDbConnection抽象而来。对应用程序不可见,但可以被开发者扩展/实现。
TransactionFactory(net.sf.hibernate.TransactionFactory):(可选)事务实例的工厂。对应用程序不可见,但可以被开发者扩展/实现。

重量级体系:所有的底层ADO.NET API都被抽象了。
持久化类是应用程序用来解决商业问题的类(比如,在电子交易程序中的Customer和Order)。持久化类NHibernate是暂时存在的,实例会被持久性保存于数据库中。
如果这些类符合简单的规则,NHibernate能够工作得最好,这些规则就是Plain Old CLR Object(POCO,简单传统CLR对象)编程模型
2 Entity Framework
Entity Framework的全称是ADO.NET Entity Framework,是微软开发的基于ADO.NET的ORM(Object/Relational Mapping)框架。

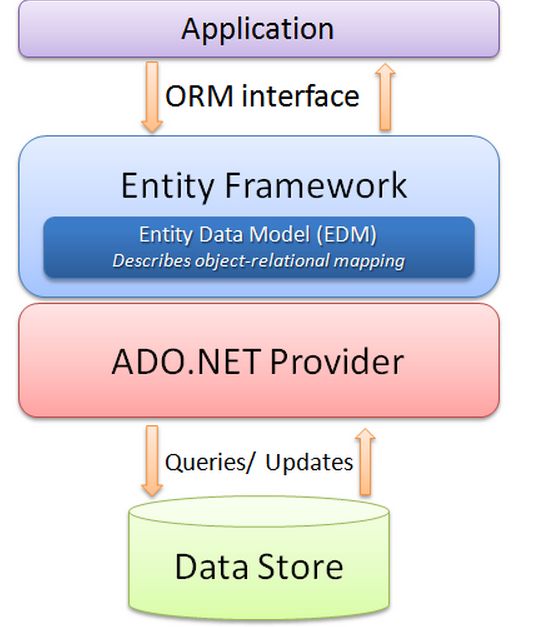

概念层结构定义了对象模型 (Object Model),让上层的应用程序码可以如面向对象的方式般访问数据,概念层结构是由 CSDL (Conceptual Schema Definition Language) 所撰写。
概念层结构定义如下所示:
<?xml version="1.0" encoding="utf-8"?> <Schema Namespace="Employees" Alias="Self" xmlns="http://schemas.microsoft.com/ado/2006/04/edm"> <EntityContainer Name="EmployeesContext"> <EntitySet Name="Employees" EntityType="Employees.Employees" /> </EntityContainer> <EntityType Name="Employees"> <Key> <PropertyRef Name="EmployeeId" /> </Key> <Property Name="EmployeeId" Type="Guid" Nullable="false" /> <Property Name="LastName" Type="String" Nullable="false" /> <Property Name="FirstName" Type="String" Nullable="false" /> <Property Name="Email" Type="String" Nullable="false" /> </EntityType> </Schema>
对应层结构负责将上层的概念层结构以及下层的储存体结构中的成员结合在一起,以确认数据的来源与流向。对应层结构是由 MSL (Mapping Specification Language) 所撰写2。
对应层结构定义如下所示:
<?xml version="1.0" encoding="utf-8"?> <Mapping Space="C-S" xmlns="urn:schemas-microsoft-com:windows:storage:mapping:CS"> <EntityContainerMapping StorageEntityContainer="dbo" CdmEntityContainer="EmployeesContext"> <EntitySetMapping Name="Employees" StoreEntitySet="Employees" TypeName="Employees.Employees"> <ScalarProperty Name="EmployeeId" ColumnName="EmployeeId" /> <ScalarProperty Name="LastName" ColumnName="LastName" /> <ScalarProperty Name="FirstName" ColumnName="FirstName" /> <ScalarProperty Name="Email" ColumnName="Email" /> </EntitySetMapping> </EntityContainerMapping> </Mapping>
储存层结构是负责与数据库管理系统 (DBMS) 中的数据表做实体对应 (Physical Mapping),让数据可以输入正确的数据来源中,或者由正确的数据来源取出。它是由 SSDL (Storage Schema Definition Language) 所撰写3。
一份储存层结构定义如下所示:
<?xml version="1.0" encoding="utf-8"?> <Schema Namespace="Employees.Store" Alias="Self" Provider="System.Data.SqlClient" ProviderManifestToken="2005" xmlns="http://schemas.microsoft.com/ado/2006/04/edm/ssdl"> <EntityContainer Name="dbo"> <EntitySet Name="Employees" EntityType="Employees.Store.Employees" /> </EntityContainer> <EntityType Name="Employees"> <Key> <PropertyRef Name="EmployeeId" /> </Key> <Property Name="EmployeeId" Type="uniqueidentifier" Nullable="false" /> <Property Name="LastName" Type="nvarchar" Nullable="false" MaxLength="50" /> <Property Name="FirstName" Type="nvarchar" Nullable="false" /> <Property Name="Email" Type="nvarchar" Nullable="false" /> </EntityType> </Schema>
定义好 Entity Data Model 的 CS/MS/SS 之后,即可以利用 ADO.NET Entity Framework 的用户端来访问 EDM,EDM 中的数据提供者会向数据来源访问数据,再传回用户端。
目前 ADO.NET Entity Framework 有三种用户端
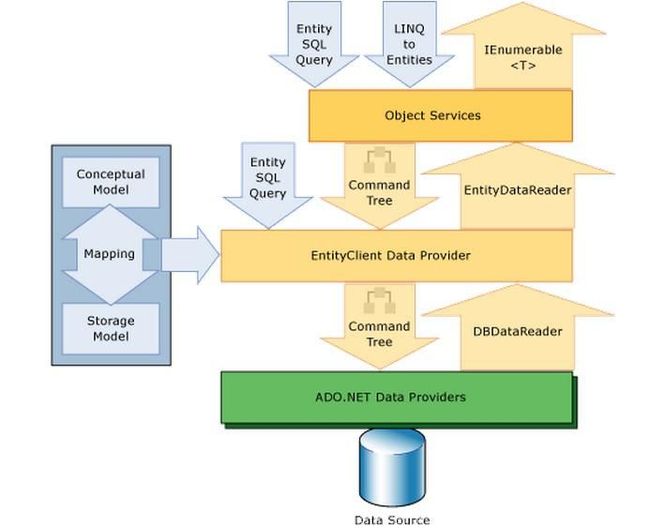
Entity Client
Entity Client 是 ADO.NET Entity Framework 中的本地用户端 (Native Client),它的对象模型和 ADO.NET 的其他用户端非常相似,一样有 Connection, Command, DataReader 等对象,但最大的差异就是,它有自己的 SQL 指令 (Entity SQL),可以用 SQL 的方式访问 EDM,简单的说,就是把 EDM 当成一个实体数据库。
// Initialize the EntityConnectionStringBuilder. EntityConnectionStringBuilder entityBuilder = new EntityConnectionStringBuilder(); //Set the provider name. entityBuilder.Provider = providerName; // Set the provider-specific connection string. entityBuilder.ProviderConnectionString = providerString; // Set the Metadata location. entityBuilder.Metadata = @"res://*/AdventureWorksModel.csdl| res://*/AdventureWorksModel.ssdl| res://*/AdventureWorksModel.msl"; Console.WriteLine(entityBuilder.ToString()); using (EntityConnection conn = new EntityConnection(entityBuilder.ToString())) { conn.Open(); Console.WriteLine("Just testing the connection."); conn.Close(); } Object Context
由于 Entity Client 太过于制式,而且也不太符合 ORM 的精神,因此微软在 Entity Client 的上层加上了一个供编程语言直接访问的界面,它可以把 EDM 当成对象般的访问,此界面即为 Object Context (Object Service)。
在 Object Context 中对 EDM 的任何动作,都会被自动转换成 Entity SQL 送到 EDM 中执行。
// Get the contacts with the specified name. ObjectQuery<Contact> contactQuery = context.Contact .Where("it.LastName = @ln AND it.FirstName = @fn", new ObjectParameter("ln", lastName), new ObjectParameter("fn", firstName)); LINQ to Entities
Object Context 将 EDM 的访问改变为一种对对象集合的访问方式,这也就让 LINQ 有了发挥的空间,因此 LINQ to Entities 也就由此而生,简单的说,就是利用 LINQ 来访问 EDM,让 LINQ 的功能可以在数据库中发挥。
using (AdventureWorksEntities AWEntities = new AdventureWorksEntities()) { ObjectQuery<Product> products = AWEntities.Product; IQueryable<Product> productNames = from p in products select p;
Entity Framework的主要特点:
1. 支持多种数据库(Microsoft SQL Server, Oracle, and DB2);
2. 强劲的映射引擎,能很好地支持存储过程;
3. 提供Visual Studio集成工具,进行可视化操作;
4. 能够与ASP.NET, WPF, WCF, WCF Data Services进行很好的集成。
5.Entity Framework 已发布版本 6.1.3,框架开源,可从nuget 官网上下载 http://www.nuget.org/packages/EntityFramework.SqlServerCompact
Entity Framework 与 Nhibernate 的区别
1.架构方面
Nhibernate 使用 ISessionFactory 创建 ISession 对象, 并用 ISession 对象来负责 工作单元 (Unit of Work)和持久化映射,ISession 对象很容易创建和销毁。Entity Framework遵循的是更加传统的.NET设计,其中所有一切都封装在单独的ObjectContext或者DbContext中。这让使用对象更加简单,但是缺点在于“类并没有因此是轻量级的,因为它有与NHibernate类似的内容,并且一般不会看到这样的例子:实例可以缓存在字段中。
2. 映射方面
EF(code first) 和 NHibernate 都支持使用 POCO 来代表实体,不需要基 类( 甚至在 NHibernate中)对于映射.
NHibernate 支持三种类型的映射方式:
a. 基本 XML文件的映射,它的优势是,不需要将实体类转换成普通的 orm ,
xml 文件可以作为文件或 嵌入式资源在文件系统上单独部署
2. 基于属性的映射,为了保持实体和数据间的一致性,将实体类和
NHibernate 的特有属性关联起来。
3. 基于强类型的映射,将 model 动态创建,并进行强制转换,这样一来,如
果一相属性的名字改变了,那映射也将会被更新 。
Entity Framework 使用的映射:
1 基于属性的映射,(尽管如此,但是属性不能表示所有可能的 属性,例如 级联)
2. 强类型 代码映射,与 NHibernate 相同
在理论上,这让你可以针对不同的数据库schema使用相同的对象模型,而不需要重新编译应用程序。 但在实践中很少这么使用。
在很多方面古老一些的NHibernate要优于Entity Framework。 Ricardo提供了更多细节,并简要地总结如下:
- 关联:都支持一对一、一对多、多对多,但是NHibernate还支持各种排序、未排序和索引的选项。它甚至还有不变的(immutable)、索引的(indexed)列表。
- 缓存:NHibernate提供了带有大量实现的二级缓存。Entity Framework没有任何对此内建的支持,但是有些增加二级缓存的例子。
- 延迟加载: Nhibernate 支持: 关联的实体(一对一,多对一);集合(一对多,多对多); 标量属性(例如 BLOB,二进制大对象 CLOB 字符串大对象), EF 支持: 关联实体、集合
- 批量写入——我们可以配置NHibernate,使其对数据库进行批量写入,从而在你需要向数据库中写入多个指令的时候,NHibernate只需要与其进行一次交互,而不需要在每个指令的执行过程中都要访问数据库。批量读/多重查询特性——NHibernate使你可以在与数据库的一次交互过程中批量执行多个查询,而不需要在独立的交互过程中执行每个查询。批量的集合加载——当你延迟加载集合的时候,NHibernate能够找到其它相同类型而没有载入的集合,然后只对数据库进行一次访问,就把它们全部载入。这种方法很好,因为这样就可以避免处理SELECT N+1的问题。
- ID生成:NHibernate提供了大概十二种策略,这取决于你如何计算。Entity Framework只为SQL Server提供了主要的三种:标识符列、GUID、和手动赋值。
- 事件:Entity Framework只有两种基于事件的扩展点:ObjectMaterialized和SavingChanges。“NHibernate拥有非常丰富的事件模型,暴露了超过20种事件,有些针对同步前执行(synchronous pre-execution),有些针对异步后执行(asynchronous post-execution)”。
- 级联:两种框架都支持集合和关联的级联:当实体被删除的时候,相关的子实体也会被删除。NHibernate还提供了一种特性,可以把子实体上的外键设置为NULL,而不删除它们。
- 清理变更:NHibernate提供了一种自动模式,其中在必要的时候会保存变更,像“如果有一种实体类型的脏实例,而查询是针对这种实体类型执行”。FlushMode.Auto实际上是默认值,但偶尔会看到由于自动清除而导致性能问题。
但在下列领域中,Entity Framework比较好:
- 跟踪变更:尽管两种框架在工作单元级别默认都能够跟踪变化,而Entity Framework还提供了自我跟踪实体(self-tracking entities)。
- 整合:Entity Framework当然会与Visual Studio和各种ASP.NET以及WCF类库有很好的绑定。
- 文档:“这是另一种Entity Framework表现非常好的地方:NHibernate缺少针对初学者的文档,并且也没有与其最新版本同步的最新API参考。”
- 查询:Craig写到:“NHibernate有更丰富的特性,但有一个领域除外,那就是对Linq的支持。因为对于很多用户来说,Linq或者其它查询语言都是ORM中最可见的部分,它会让人对功能产生错误印象。”
总结
EF 和 NHibernate 都是优秀的很受欢迎的 ORM 框架,但在某些领域,两种框架都可以做出改进,像批处理功能。当需要真正支持SQL的高级特性——像通用表表达式——的时候,两种ORM框架都无法支持SQL Alchemy。
我们应该发现两个ORM框架都很活跃,经常会有定期的改进。所以,如果二者都能够满足你的最小需求,那么考虑就更多集中在程序库的设计模式和哲学上,而不是在特性列表上。
参考文档: http://weblogs.asp.net/ricardoperes/differences-between-nhibernate-and-entity-framework
https://www.devbridge.com/articles/entity-framework-6-vs-nhibernate-4/
注释:
POCO是指Plain Old Class Object,也就是最基本的CLR Class,即原始的对象, 在原先的EF中,实体类通常是从一个基类继承下来的,而且带有大量的属性描述。而POCO则是指最原始的Class,换句话说这个实体的Class仅仅需要从Object继承即可,不需要从某一个特定的基类继承。主要是配合Code First使用。Cost Frist则是指我们先定义POCO这样的实体class,然后生成数据库。实际上现在也可以使用Entity Framework Power tools将已经存在的数据库反向生成POCO的class(不通过edmx文件)。
Unit Of Work 在理解这个模式之前有必要回顾下我们耳熟能详的Data Access Object(DAO)模式,即数据访问对象。DAO是一种简单的模式,我们构建应用的时候经常会使用到它,它的功能就是将DAL元素从应用程序中分离出来,在经典的三层架构中,我们会将数据持久化工作单独分离出来,封装成DAL层。但是,DAO并没有隐藏它面对是一张张数据表,而且通常情况我们会为数据库中的每一张表创建一个DAO类,想必大家对这种方式的极度的不爽了,。
由于DAO模式与数据表是一对一匹配的关系,因此DAO模式很好的配合了Active Record和Transaction Script业务模式,尤其是Table Module。正因为这种与数据表一对一匹配关系,使我对DAO模式深恶痛绝。
Unit Of Work模式,即工作单元,它是一种数据访问模式。它是用来维护一个由已经被业务修改(如增加、删除和更新等)的业务对象组成的列表。它负责协调这些业务对象的持久化工作及并发问题。那它是怎么来维护的一系列业务对象组成的列表持久化工作的呢?通过事务。Unit Of Work模式会记录所有对象模型修改过的信息,在提交的时候,一次性修改,并把结果同步到数据库。 这个过程通常被封装在事务中。所以在DAL中采用Unit Of Work模式好处就在于能够确保数据的完整性,如果在持有一系列业务对象(同属于一个事务)的过程中出现问题,就可以将所有的修改回滚,以确保数据始终处于有效状态,不会出现脏数据。
SQLAlchemy 是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。SQLAlchemy的理念是,SQL数据库的量级和性能重要于对象集合;而对象集合的抽象又重要于表和行。因此,SQLAlchmey采用了类似于Java里Hibernate的数据映射模型,而不是其他ORM框架采用的Active Record模型。不过,Elixir和declarative等可选插件可以让用户使用声明语法。
Transaction Script
这个我就不费过多的口舌了。完全是面向过程式的写法。所以是最容易理解,掌握和运用的模式。通常的做法是为每隔业务事务创建一个单独的方法,并将它们组合起来放入某种静态管理程序或服务类。每个过程都包含了完成业务事务所需要的所有的业务逻辑,包括工作流,业务规则和数据库持久化验证检查。
其优势是容易理解并上手。
其劣势是一旦程序变大或者业务逻辑变得复杂时,方法的数目变多,从而形成一个充斥着功能交叠的细粒度方法的无用API。代码将会很快变得笨重且不可维护。
由于这种方式比较简单,我们无须给出示例。
Active Record
Active Record模式是一种流行的模式,尤其在底层数据库模型匹配业务模型时,它特别有效。通常,数据库中的每张表都对应一个业务对象。业务对象表示表中的一行,并且包含数据、行为以及持久化该对象的工具,此外还有添加新实例和查找对象集合所需的方法。
在Active Record模式中,每隔业务对象均负责自己的持久化和相关的业务逻辑。
Active Record模式非常适用于在数据模型和业务模型之间具有一对一映射关系的简单应用程序,如博客或论坛引擎。如果已经有数据库模型或者希望采用“数据优先”的方法来构建应用程序,这也是一个可用的好模式。因为业务对象与数据库中的表具有一对一映射关系,而且均具有相同的创建,读取,更新和删除方法,所以可以使用代码生成工具自动生成业务模型。与Transaction Script模式一样,Active Record模式也非常简单并且易于掌握。
Active Record模式随着基于数据库的Web应用程序而流行,其中一个典型就是结合了MVC模式和Active Record ORM的Ruby on Rails框架。在.net领域,构建在NHibernate之上的Castle ActiveRecord项目是最流行的开放源代码Active Record框架之一。以下将通过构建一个简单的博客网站(博客网站只包含少量的业务逻辑,因此在业务对象和数据模型之间存在较好的相关性),来展示其具体用法。
ActiveRecord也属于ORM层,由Rails最早提出,遵循标准的ORM模型:表映射到记录,记录映射到对象,字段映射到对象属性。配合遵循的命名和配置惯例,能够很大程度的快速实现模型的操作,而且简洁易懂。
ActiveRecord的主要思想是:
1. 每一个数据库表对应创建一个类,类的每一个对象实例对应于数据库中表的一行记录;通常表的每个字段在类中都有相应的Field;
2. ActiveRecord同时负责把自己持久化,在ActiveRecord中封装了对数据库的访问,即CURD;;
3. ActiveRecord是一种领域模型(Domain Model),封装了部分业务逻辑;
ActiveRecord比较适用于:
1. 业务逻辑比较简单,当你的类基本上和数据库中的表一一对应时, ActiveRecord是非常方便的,即你的业务逻辑大多数是对单表操作;
2. 当发生跨表的操作时, 往往会配合使用事务脚本(Transaction Script),把跨表事务提升到事务脚本中;
3. ActiveRecord最大优点是简单, 直观。 一个类就包括了数据访问和业务逻辑. 如果配合代码生成器使用就更方便了;
这些优点使ActiveRecord特别适合WEB快速开发。
ActiveRecord不适合于:
1. ActiveRecord虽然有业务逻辑, 但基本上都是基于单表的. 跨表逻辑一般会放到当发生跨表的操作时, 往往会配合使用事务脚本(Transaction Script)中. 如果对象间的关联越来越多, 你的事务脚本越来越庞大, 重复的代码越来越多, 你就要考虑Domain Model + O/R Mapper了;
2. ActiveRecord保存了数据, 使它有时候看上去像数据传输对象(DTO). 但是ActiveRecord有数据库访问能力, 不要把它当DTO用. 尤其在跨越进程边界调用的时候, 不能传递ActiveRecord对象。