1.前言
数据展示,即数据可视化,是数据分析的第五个步骤,大部分人对图形敏感度高于数字,好的数据展示方式能让人快速发现问题或规律,找到数据背后隐藏的价值。
2.Matplotlib概念
Matplotlib 是 Python 中常用的 2D 绘图库,它能轻松地将数据进行可视化,作出精美的图表。Matplotlib 模块很庞大,其中最常用的一个子模块是 pyplot,通常以一下方式将其导入:
import matplotlib.pyplot as plt
因为在程序中经常使用,所以给 matplotlib.pyplot 起了个别名plt,以减少大量重复代码
3.Matplotlib.pyplot基本使用
pyplot 中最基础的作图方式是以点作图,即给出每个点的坐标,pyplot 会将这些点在坐标系中画出,并用线将这些点连起来。以正弦函数为例,用 pyplot 画出图像:
代码段1:
import numpy as np import matplotlib.pyplot as plt x = np.arange(0,2*np.pi,0.1) #生成一个0到2pi、步长为0.1的数组x y = np.sin(x) #将x的值传入正弦函数,得到对应的值存入数组y plt.plot(x,y) #传入plt.plot(),将x,y转换成对应坐标。 plt.show() #显示图像
上面程序画出了以下图像:
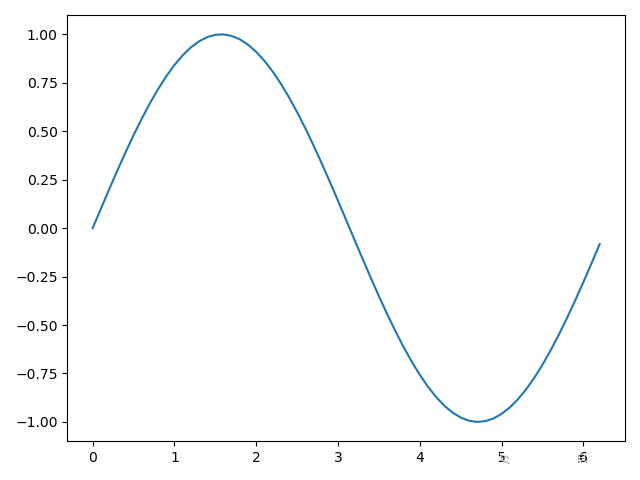
注:选择x的步长为0.1是为了让每个点间隔较小,让图像更加接近真实情况,否则如果步长过大,则会变成折线,若步长为1则会变成以下情况:
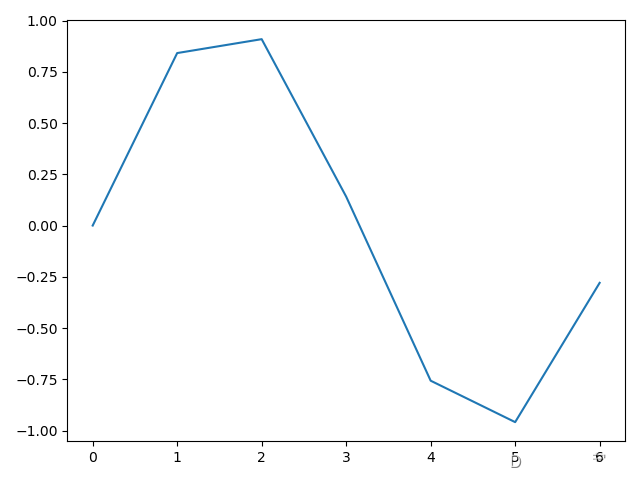
除了 np.sin()方法外,numpy 中也有 np.cos()、np.tan()等计算三角函数的方法。上面这些方法,最重要的是 plt.plot()方法,plt.plot()方法可以接收任意对数的 x 和 y ,它会将这些图像在一张图上都画出来,例如在原来的正弦图像上增加余弦图像,可以这样写:
import numpy as np import matplotlib.pyplot as plt x = np.arange(0,2*np.pi,0.1) #生成一个0到2pi,步长为0.1的数组x y1 = np.sin(x) #将x的值传入正弦函数,得到对应的值存入数组y1 y2 = np.cos(x) #将x的值传入余弦函数,得到对应的值存入数组y1 plt.plot(x,y1,x,y2) #传入plt.plot(),将(x,y1)、(x,y2)转换成对应坐标。 plt.show() #显示图像
以上程序公用了同一个x,当然也可以重新定义一个新的 x,最终得到的图像如下:
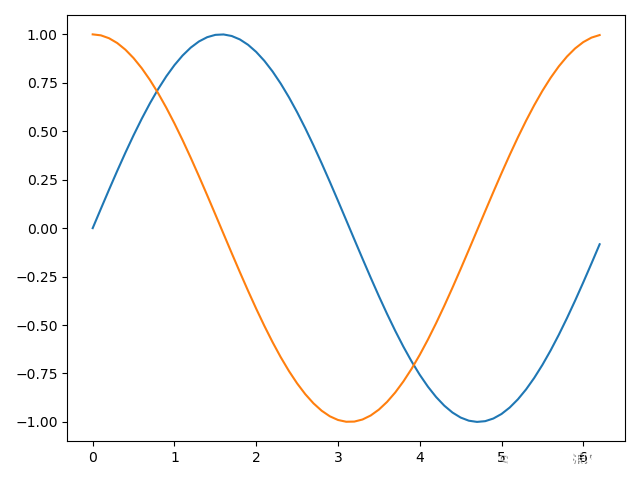
代码段2使用一次 plt.plot()方法直接将两个数字转换 成对应坐标,当然也可以调用两次,以下两行代码和上面第7行代码是等价的。
plt.plot(x,y1) plt.plot(x,y2)
对每一对 x 和 y,有一个可选格式化参数,进行指定线条的颜色、点标记和线条的类型。
代码段3:
import numpy as np import matplotlib.pyplot as plt x = np.arange(0,2*np.pi,0.1) #生成一个0到2pi,步长为0.1的数组x y1 = np.sin(x) #将x的值传入正弦函数,得到对应的值存入数组y1 y2 = np.cos(x) #将x的值传入余弦函数,得到对应的值存入数组y1 plt.plot(x,y1,'ro--',x,y2,'b*-.') #将(x,y1)、(x,y2)转换成对应坐标,并选用格式化参数 plt.show() #显示图像
将代码段2传入了格式化参数后,最终图像如下所示:
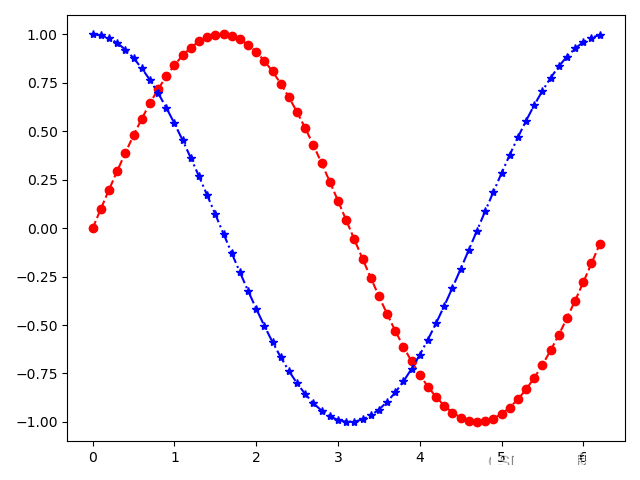
以其中的参数'ro--'为例,它分为三部分:r 代表红色(red),o 代表在坐标点采用圆点标记,-- 代表虚线。'ro--'整体来说就是线条为虚线、坐标点标记为圆点。格式化参数这三部分都是可选的,即传入一部分也是可以的,并且没有顺序要求,
格式化参数常用的选型及含义如下表所示:

3.数据展示
3.1如何选择展示方式
我们通过数据分析来进行决策,那么使用合适的图表来准确地展示数据是至关重要的。实际使用中,我们会用到各种各样地几十种图表,按照数据展示的目标可以把它们分为五种,分别是:趋势、比较、构成、分布和联系。

- 趋势:最常见的一种时间序列关系,关心数据如何随时间变化,趋势里的图标能直观反映出每年、每月、每天的变化趋势,增长、减少、上下波动还是基本不变,最常见的是折线图,它能很好地表现指标随时间呈现的趋势。
- 构成:主要关注每个部分整体的占比,如果逆向分析的目标如“份额”、“百分比”等。展示构成关系的图表类型,最常见的是饼图。
- 比较:可以展示某个维度上的排列顺序,分析某维度之间的对比是差不多,还是“大于”、“小于”,比如分析男生和女生的身高差别。
- 分布:当你关心数据集中,频率、分布时,比如根据地理位置数据,通过地图来展示不同分布特征。比较常用的图表有地图、直方图、散点图。
- 联系:主要查看两个变量之间是否表达出我们所要证明的相关关系,比如预期销售额可能随着优惠折扣的增长而增长,常用于表打“与......有关”、“随......而增长”、“随......而不同”等维度的关系。
在进行数据可视化时,要先明确分析的目标,再来选择五种合适的分类,最后选择某个分类里合适的图表类型。
3.2绘制折线图
其实在前面已经用过折线图了,就是使用 plot.plot() 方法。之前我们传入的时x和y坐标点,而折线图的 x 和 y 分别是时间点和对应的数据,下面以两个商品的销量走势为例:
import numpy as np
import matplotlib.pyplot as plt
x = ['周一','周二','周三','周四','周五','周六','周日']
y1 = [61,42,52,72,86,91,73]
y2 = [23,26,67,38,46,55,33]
#传入label参数
plt.rcParams['font.family'] = ['SimHei'] #设置字体防止乱码
plt.plot(x, y1, label='商品A') #增加折线图例“商品A”
plt.plot(x, y2, label='商品B') #增加折线图例“商品B”
#设置x轴标签
plt.xlabel('时间')
plt.ylabel('销量')
#设置图表标题
plt.title('商品销量对比图')
#显示图例、图像
plt.legend(loc='best') #显示图例,并设置在“最佳位置”
plt.show()
得到的图像如下图所示:

因为上图中有中文,所以通过 plt.rcParams['font.family'] = ['SimHei'] 来设置中文字体来防止乱码,如果想设置其他字体只需将 SimHei(黑体)替换成相应的名称即可。通过一下代码获得,自己编译器所在环境安装的字体:
import matplotlib.font_manager as fm
for font in fm.fontManager.ttflist:
print(font.name)
图例位置是一个可选参数,默认 matplotlib 会自动选择合适位置,也可以指定其他位置。
具体的如下表所示:
plt.legend() 方法的 loc 参数选择 参数含义参数含义best最佳位置center居中upper right右上角center right靠右居中upper left左上角center left靠左居中lower left左下角lower center靠下居中lower right右下角upper center靠上居中
3.3绘制柱状图
柱状图描述的是分类数据,展示的是每一类的数量。柱状图分为很多种,有普通柱状图、堆叠柱状图、分组柱状图等。
3.3.1普通柱状图
普通柱状图调用 plt.bar() 方式实现。我们至少需要传入两个参数,第一个参数是 x 轴上刻度的标签序列(列表、元组、数组等),第二个参数用于指定每个柱子的高度,也就是具体的数据。下面以一个班级体育课选课的情况为例:
import matplotlib.font_manager as fm
for font in fm.fontManager.ttflist:
print(font.name)
得到如下图像:

plt.bar() 前两个参数是必选的,当然还有一些可选参数,常用的有 width 和 color ,分别是用于设置柱子的宽度(默认0.8)和颜色。比如我们将柱子宽度改成0.6,将柱子的颜色设成好看的天蓝色只需将 plt.bar() 改为 plt.bar(names, nums, width=0.6, color='skyblue') 即可。之前在折线图部分用到的 plt.xlabel() 、plt.ylabel() 、plt.title() 和 plt.legend() 方法都是通用方法,并不局限于一种图表,所有的图表都适用。
3.3.2堆叠柱状图
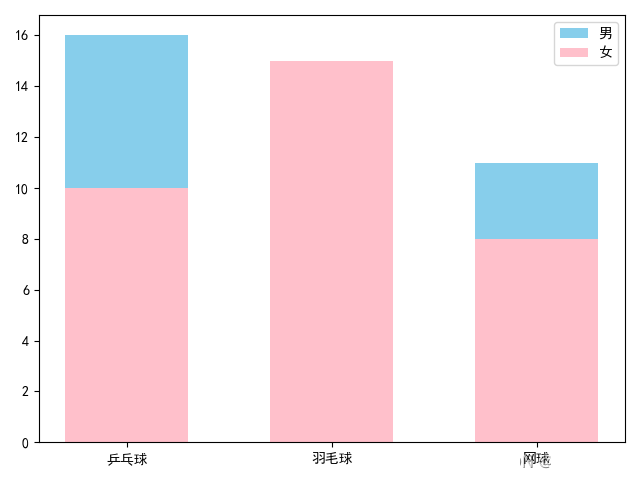
柱状图能直观地展现出不同数据上的差异,但有时候我们需要进一步分析数据的分布,比如每门选修课的男女比例,这时就需要用到堆叠柱状图。
下面就是进一步分析每一门选修课中男女比例为例编写程序:
import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.family'] = ['SimHei'] #设置字体防止乱码 name = ['乒乓球','羽毛球','网球'] nums_boy = [16,5,11] nums_girl = [10,15,8] plt.bar(name, nums_boy, width=0.6, color='skyblue', label='男') plt.bar(name, nums_girl, bottom=nums_boy, width=0.6, color='pink', label='女') plt.legend() plt.show()
最终得到图像:

上面的代码和普通柱状图相比,多调用了一次,plt.bar() 方法,并传入了 bottom 参数,每调用一次 plt.bar() 方法都会画出对应的柱状图,而 bottom 参数作用就是控制柱状图低端的位置。我们将前一个柱状图的高度传进去,这样就形成了堆叠柱状图。而如果没有 bottom 参数,后面的图形会盖在原来的图形之上,
就像下面这样:
3.3.3分组柱状图
分组柱状图经常用于不同组间数据的比较,这些组都包含了相同分类的数据。
先来看一下效果图:

绘制上图的代码如下:
import numpy as np import matplotlib.pyplot as plt x = np.arange(3) width = 0.3 names = ['篮球', '羽毛球', '乒乓球'] nums_boy = [16, 5, 11] nums_girl = [10, 15, 8] plt.rcParams['font.family'] = ['SimHei'] #设置字体防止乱码 plt.bar(x - width / 2, nums_boy, width=width, color='skyblue', label='男') plt.bar(x + width / 2, nums_girl, width=width, color='pink', label='女') plt.xticks(x, names) plt.legend() plt.show()
这次的方法和之前有些不同,首先使用 np.arange(3) 方法创建了一个数组 x ,值为[0,1,2]。并定义了一个变量 width 用于指定柱子的宽度。在调用 plt.bar() 时,第一个参数不再是刻度线上的标签,而是对应的刻度。以[0,1,2]为基准,分别加上或减去柱子的宽度得到[-0.15,0.85,1,85]和[0.15,1.15,2.15],这些刻度将分别作为两组柱子的中点,并且柱子的宽度为0.3。

因为传入的是刻度,而不是刻度的标签。所以调用 plt.xticks() 方法来将 x 轴上刻度改为对应的标签,该方法第一个参数时要改的刻度序列,第二个参数时与之对于的标签序列。同理,使用plt.yticks() 方法来更改y轴上刻度的标签。
3.3.4饼图
饼图广泛地应用在各个领域,用于表示不同分类的占比情况,通过弧度大小来对比各种分类。饼图通过将一个圆饼按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块(圆弧)表示该分类占总体的比例大小,所有区块(圆弧)的加和等于100%。
饼图的绘制很简单,只需要传入数据和对于的标签给 plt.pie() 方法即可。以2018年国内生产总值(GDP)三大产业的占比为例,可以画出这样的饼图:

绘制上图的代码如下:
import matplotlib.pyplot as plt plt.rcParams['font.family'] = ['SimHei'] #设置字体防止乱码 data = [64745.2, 364835.2, 489700.8] labels = ['第一产业', '第二产业', '第三产业'] explode = (0.1, 0, 0) plt.pie(data, explode=explode, labels=labels,autopct='%0.1f%%') plt.show()
plt.pie() 方法的第一个参数是绘图需要的数据;参数 explode 是可选参数,用于突出显示某一区块,默认数值都是0,数值越大,区块抽离越明显;参数 lables 是数据对应的标签;参数 autopct 则给饼图自动添加百分比显示。
参数 autopct 的格式用到了字符串格式化输出的知识,代码中 '%0.1f%%' 可以分成两部分。一部分是 %0.1f 表示保留一位小数,同理 %0.2f 表示保留两位小数;另一部分是 %% ,它表示输出一个 %,因为% 在字符串格式化输出中有特殊的含义,所以想要输出 % 就得写成 %% 。所以,'%0.1f%%' 的含义是保留一位小数的百分数,例如:66.6%。
4.绘制子图
Matplotlib 提供了子图的概念,通过使用子图,可以在一张图里绘制多个图表。在 matplotlib 中,调用 plt.subplot() 方法来添加子图。plt.subplot() 方法的前两个参数分别是子图的行数和列数,第三个参数是子图的序号(从1开始)。
ax1 = plt.subplot(2, 2, 1) ax2 = plt.subplot(2, 2, 2) ax3 = plt.subplot(2, 2, 3) ax4 = plt.subplot(2, 2, 4)
plt.subplot(2,2,1) 的作用是生成一个两行两列的子图,并选择其中序号为1的子图,所以上面四行代码将一张图分成了4个子图,并用1、2、3、4来选择对应的子图。

我们也可以绘制不规则的子图,比如上面两张子图,下面一张子图。
方法如下:
ax1 = plt.subplot(2, 2, 1) ax2 = plt.subplot(2, 2, 2) ax3 = plt.subplot(2, 1, 2)
之所以第三行代码是 plt.subplot(2, 1, 2) ,因为子图序号是独立的,与之前创建的子图没有关系。plt.subplot(2, 2, 1) 选择并展示了2*2的子图中的第一个。plt.subplot(2, 2, 2) 选择并展示了2*2的子图中的第二个,它们两个合起来占了2*2子图的第一行。而 plt.subplot(2, 1, 2) 则是生成了两行一列的子图,并选择了第二行。即占满第二行的子图,正好填补了之前2*2子图第二行剩下的空间,因此生成的图表是这样的:

图表的框架画好了,就可以往里面填充图像了,之前调用的是 plt 上的方法绘图,只要将其改成 plt.subplot() 方法的返回值上调用相应的方法绘图即可。
举个栗子,下面是在一张图上绘制了 sin、cos 和 tan 三个函数的图像的代码:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei'] #设置字体防止乱码
x = np.arange(0, 2 * np.pi, 0.1)
plt.suptitle('三角函数可视化')
ax1 = plt.subplot(2,2,1)
ax1.set_title('sin函数')
y1 = np.sin(x)
ax1.plot(x,y1)
ax2 = plt.subplot(2,2,2)
ax2.set_title('cos函数')
y2 = np.cos(x)
ax2.plot(x,y2)
ax3 = plt.subplot(2,1,2)
ax3.set_title('tan函数')
y3 = np.tan(x)
ax3.plot(x,y3)
plt.show()
得到的图像是:
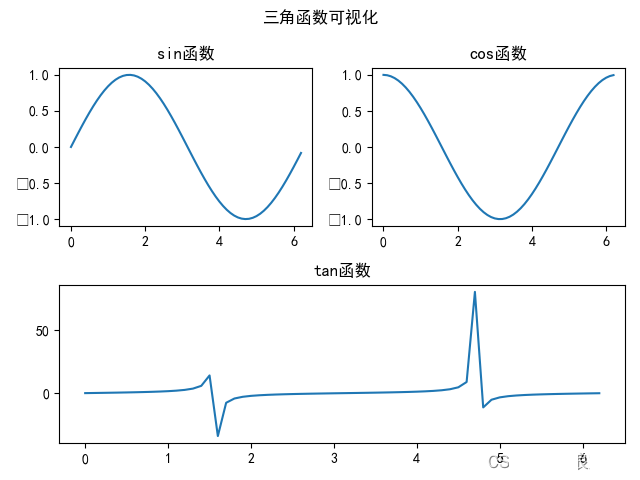
上面程序中,使用 set_title() 方法为每个子图设置单独的标题。需要注意的是,如果想要给带有子图的图表设置总的标题的话,不是使用的 plt.titie() 方法,而是通过 plt.suptitile() 方法来设置带有子图的图表标题。
到此这篇关于Python数据分析之Matplotlib数据可视化的文章就介绍到这了,更多相关Python Matplotlib数据可视化内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!