SphereEx苗立尧:云原生架构下的Database Mesh研发实践
嘉宾 | 苗立尧
2022年7月27日,在由开放原子开源基金会主办的“2022开放原子全球开源峰会”上,SphereEx Mesh实验室负责人、云原生技术专家苗立垚带来了《云原生架构下的Database Mesh的研发实践》的主题演讲。

![]()
从云原生架构到Service Mesh
从单体到微服务,应用部署的基础设施规模越来越大,服务之间调用关系越来越复杂,对微服务的治理行为集中在流量控制、可观测性、安全访问、配置管理和高可用等方面。
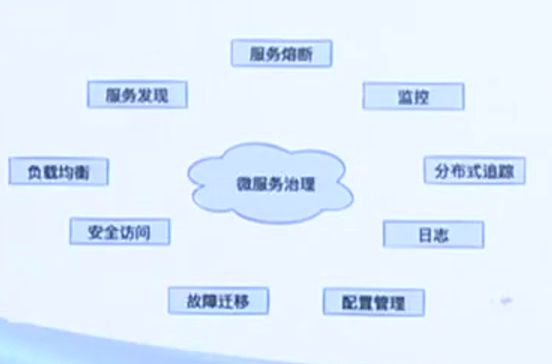
服务网格通过透明代理层作为数据面接管应用流量,并通过控制面管理和下发服务发现、限流熔断、访问控制、安全证书等各种配置,为云原生环境中的微服务实现治理能力。
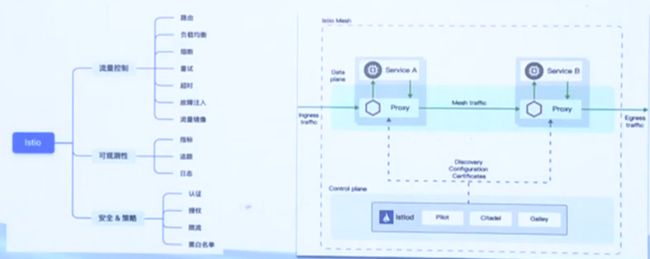
服务网格最典型的应用场景是Istio,Istio可以解决开发人员和运营商在分布式或微服务架构方面面临的挑战。无论是从零开始构建应用程序,还是将现有应用程序迁移到原生云,Istio都能提供帮助。
![]()
当服务治理遇到数据库治理
当服务治理遇到数据库治理,我们可不可以使用Service Mesh治理数据库的流量?
如果把数据库看作是微服务中的一个节点,那么可以通过Service Mesh对数据库访问进行治理。

数据库拥有一些特殊治理属性,比如通信协议、资源管理、基于数据请求的负载均衡、分库分表,还有可观测性、访问控制等。
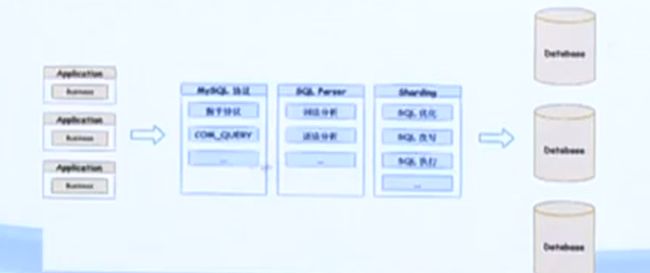
2018年,SphereEx创始人张亮提出了Database Mesh概念,至今四年的时间,已经有很多厂商与企业客户对Database Mesh做了实践。
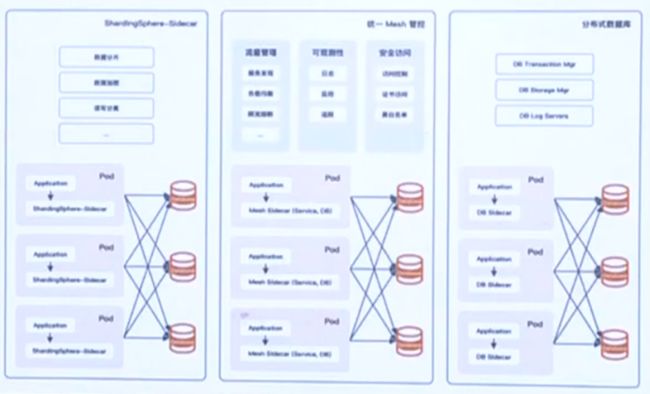
上图是三种典型的Database Mesh实现方式,以Sidecar方式实现数据库分片,将数据库流量管理纳入统一的管控,实现一个分布式数据库。
将ShardingSphere当作Sidecar进行部署,不论是ShardingSphere-JDBC或是ShardingSphere-Proxy,都可以实现数据库流量治理与计算能力的增强。
-
以Sidecar方式实现数据库分片
-
将数据库流量管理纳入统一的管控
中等或大规模厂商往往会采用统一的Mesh管控,一般由专门的团队负责所有关于服务方面的治理,数据库也会被列入到治理范畴之中。其中,两套Sidecar受控于同一个服务网格,流量治理、访问控制、可观测性都通过统一的Mesh管控完成。
-
实现一个分布式数据库
利用Sidecar做接入,将计算、事务、存储管理都放在单独的节点中,构成分布式数据库。
以上三种实现都聚焦在数据库流量治理的部分,如果将其称为Database Mesh 1.0,那么2.0阶段又应该有哪些特征呢?除了流量之外,数据库治理还应该包括哪些方面?如何通过一个标准框架,提升开发人员的体验?如何减少SRE、DBA的工作负担,还可以为各种场景提供扩展性支持?
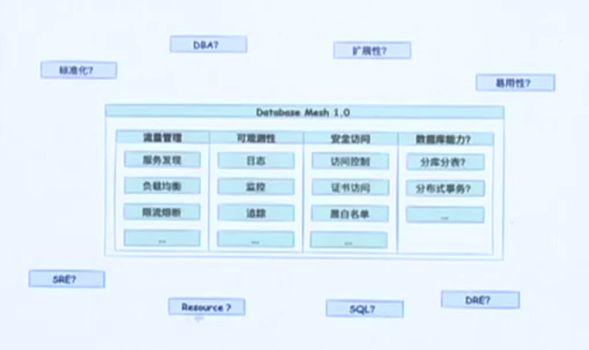
基于上述问题的思考,我们构建了Database Mesh 2.0的概念,希望构建高效可编程的数据库治理体验:
-
进一步减轻开发人员的心智负担,提高开发效率,提供透明和无感的数据库基础设施使用体验;
-
以可配置、可插拔、可编程的方式,实现一个覆盖数据库流量、运行时资源和稳定性保障等方面的治理框架;
-
以异构数据源、云原生数据库、分布式数据库等多个数据库领域的典型场景提供标准的使用界面。
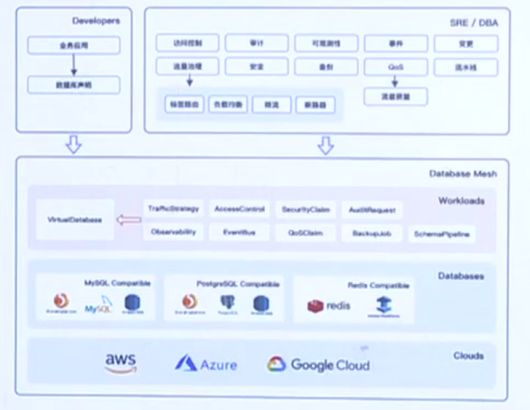
Database Mesh 2.0希望提供一种以数据库为中心的治理框架:
-
数据库是一等公民:一切抽象围绕数据库治理行为进行,比如控制访问、流量治理、可观测性等;
-
面向工程师体验:对于开发人员,通过便捷易用的数据库声明和定义即可进行开发,无需关心数据库的位置;对于运维和DBA,提供多种数据库治理行为抽象,实现自动化的数据库可靠性治理;
-
云原生:以开放的生态和实现机制适配不同的云环境,面向云原生构建和实现,而无需担心厂商锁定。
![]()
设计一个面向数据库的治理框架
前面已经提到了Database Mesh的概念以及我们想做的事情,那么该如何把它从理论变成实际项目呢?
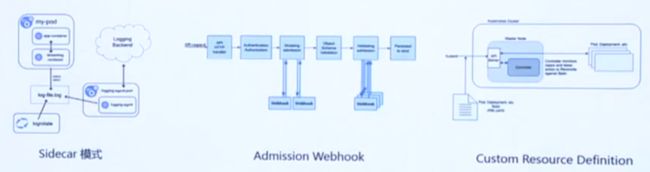
Kubernetes利用自身强大的扩展能力,如Sidecar模式、Admission Webhook、Custom Resource Definition等,为构建平台上的平台提供了便利。
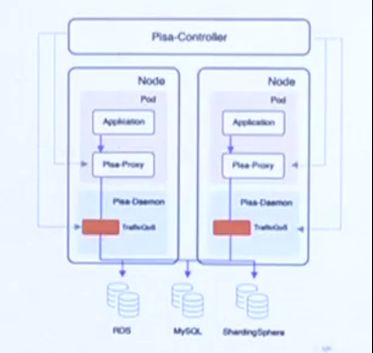
Pisanix是面向Database Mesh的解决方案,由Go、Rust编写,适配Kubernetes环境,目前支持MySQL协议,有三个主要功能:
-
SQL感知的流量治理:借助SQL解析能力,提供对流量的负载均衡、审计、访问控制、可观测性等功能;
-
面向运行时的资源可编程:通过多种Linux内核能力,实现流量治理运行时的资源可配置和可编程;
-
数据库可靠性工程:以工程师为中心、以数据库可靠性为原则设计产品形态,建立数据库上云统一界面。
主要组件有:
-
Pisa-Controller:Pisanix的控制面,Go语言实现,负责配置转换和下发等;
-
Pisa-Proxy:Pisanix的数据面,Rust语言实现,负责流量治理相关能力,以Sidecar形式部署;
-
Pisa-Daemo:Pisanix的数据面,Rust语言实现,负责资源治理相关能力,以Daemon形式部署。
Pisa-Proxy的整体流程
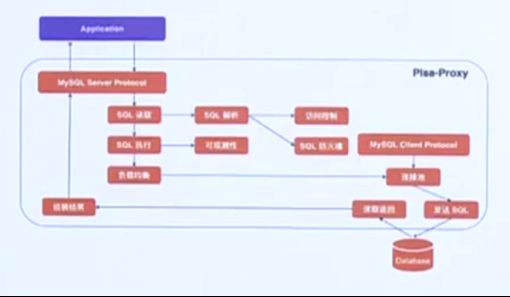
Pisa-Proxy可以看作是面向数据库流量的负载均衡器,主要工作流程如下:
-
目前Pisa-Proxy支持MySQL协议,将自己伪装成数据库服务器,应用连接配置只需要修改访问地址即可建连;
-
Pisa-Proxy通过读取应用发来的握手请求和数据包,得到应用希望执行的SQL;
-
对该SQL进行词法和语法解析后得到对应AST;
-
基于AST实现高级访问控制和SQL防火墙能力;
-
访问控制和防火墙通过后,SQL提交执行;
-
SQL执行阶段的指标将采集Prometheus Metrics;
-
根据负载均衡策略获取执行该语句的后端数据库连接;
-
如果连接池为空,将根据配置建立和后端数据库的连接;
-
SQL将从该链接发往后端数据库,并读取相应返回结果;
-
SQL执行结果进行组装后返回给业务应用。
MySQL Protocol
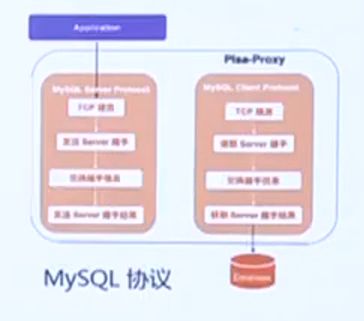
Pisa-Proxy作为服务端监听数据库连接请求的流程为:
-
接收客户端发来的TCP请求并建连;
-
向客户端发送握手请求,设置服务端标志位;
-
读取客户端发来的握手响应,验证密码等配置;
-
向客户端发送握手结果。
Pisa-Proxy作为客户端连接后端数据库的流程为:
-
和后端数据库建立TCP连接;
-
接收后端数据库发来的握手请求;
-
根据收到的握手请求中的标志位组装客户端握手请求,如SSL、AuthSwitch、密码加密等;
-
与后端数据库交换握手信息;
-
接受后端数据库发来的握手结果。
SQL Parser
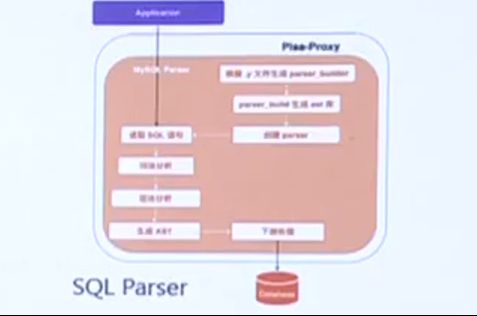
Pisa-Proxy使用Grmtools根据MySQL yacc构建Parser:
-
Parser中通过Scanner读取SQL Token,经过词法分析、语法分析后生成抽象语法树AST;
-
抽象语法树中可以得到SQL要操作的列和表信息;
-
基于列、表信息等可以实现细粒度的访问控制、分库分表、加解密等能力。
负载均衡
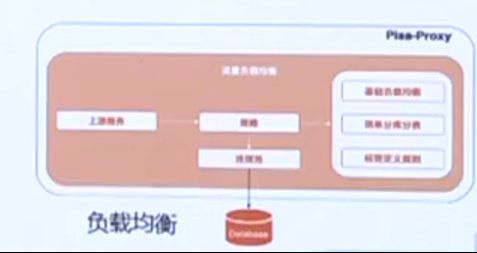
Pisa-Proxy支持多种负载均衡策略,现已支持:
-
基础负载均衡(随机、轮询);
-
读写分离(静态规划和主从感知)。
下一步将支持:
-
简单分库分表:支持一定计算规模内的分库分表规则;
-
标签定义规则:通过标签匹配的方式,指定SQL路由到不同的数据源;
-
未来将提供策略框架,用户可以自定义策略,注入框架后即可使用。
可观测性
Pisa-Proxy支持多种可观测性指标,现有指标为:
-
SQL_PROCESSED_TOTAL;
-
SQL_PROCESSED_DURATION;
-
SQL_UNDER_PROCESSING。
下一步将支持:
-
Latency、Throughput、Error Rate;
-
TopN Queries by Total Time、TopN Queries by Count;
-
SQL Runtime Memory。