【黑马-python进阶】---学习笔记(8)---MySQL
8 MySQL数据库基本操作
8.1 数据库基础
8.1.1 数据概念、作用、分类及特点
- 1、数据库概念
- 数据库就是以一定格式进行组织的数据的集合,通俗来看,数据库就是用户计算机上一些具有特殊格式的数据文件的集合;
 * 2、数据库的作用
* 2、数据库的作用
- 数据库就是用来存储数据的!
问题:
数据库本身就是一种文件,用户可以不使用数据而使用普通文件来进行数据的存储吗?从理论上可以,但是相比于普通文件,数据有以下特点:
- 持久化存储;
- 读写速度极高;
- 保证数据的有效性;
- 对程序支持性非常好,容易拓展;
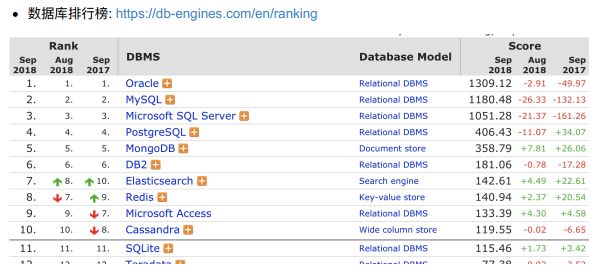
- 3、数据库分类及特点
- 1)关系型数据库;
- 2)非关系型数据库;
- 4、关系数据库
- 关系型数据库管理系统-RDBMS(Relational Database Management System);
- 关系型数据库RDBMS,是建立在关系模型基础上的数据库,借助于几何代数等数学概念和方法来处理数据库中的数据,本质上使用一张二维表来表示关系;

-
5、非关系型数据库
- 非关系型数据库,又称为NoSQL(Not Only SQL),不仅仅是SQL,对NoSQL最普遍的定义是非关联型,强调Key-Value存储和文档数据库的优点;

- 非关系型数据库,又称为NoSQL(Not Only SQL),不仅仅是SQL,对NoSQL最普遍的定义是非关联型,强调Key-Value存储和文档数据库的优点;
-
小结
- **关系型数据库:**基于关系模型建立,用二维表进行数据存储的数据库;
- **非关系型数据库:**不是基于二维表,基于Key-Value方式存储;
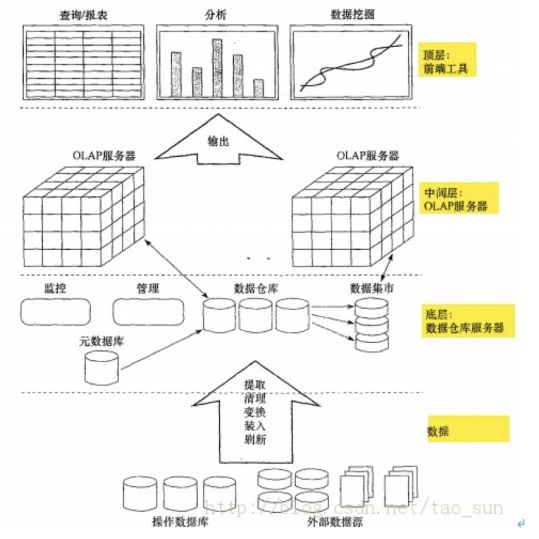
8.1.2 数据库管理系统—DBMS
- 1、数据库管理系统介绍—DBMS
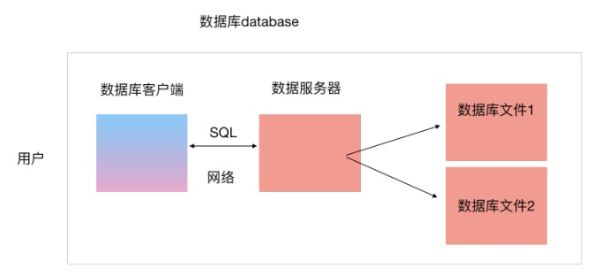
- 数据库管理系统(Database Management System,简称DBMS)是为了管理数据库而设计的软件系统,包括三大部分:
- 1)数据库文件集合:主要是一系列数据文件,作用是存储数据;
- 2)数据库服务端:主要负责对数据文件以及文件中的数据进行管理;
- **3)数据库客户端:**主要负责和服务端通信,向服务端传输数据或者从服务端获取数据;
- 数据库管理系统(Database Management System,简称DBMS)是为了管理数据库而设计的软件系统,包括三大部分:
-
数据库三部分之间的关系
- 1)数据库客户端通过SQL语句告诉服务端,客户端想要做什么;
- 2)服务端和数据文件一般都在同一个台机器上,直接可以读写数据文件;
-
2、SQL语句
-
SQL语句的作用是实现数据库客户端和服务端之间的通信;
其表现形式为:带有一定格式的字符串;
-
SQL(Structured Query Language)是结构化查询语言—是对于RDBMS(关系型)
- **SQL是一种用来操作RDBMS的数据语言,**当前几乎所有关系型数据库都支持SQL语言进行操作,可以通过SQL操作oracle、sql server、mysql、sqilte等所有的关系型数据库;
-
SQL语句主要分为:
- 1)DQL:数据查询语言,用于对数据进行查询,如select;
- 2)DML:数据操作语言,对数据进行增加、修改、删除,如insert、update、delete;
- **3)TPL:事务处理语言,**对事物进行处理,包括begin transaction、commit、rollback;
- **4)DCL:数据控制语言,**进行授权与权限回收,如grant、revoke;
- 5)DDL:数据定义语言,进行数据库、表的管理等,如create、drop;
-
对于web程序员,最重要的就是crud(增删查改),必须熟练编写DQL、 DML, 能够编写DDL完成数据库、 表的操作, 其它语⾔如TPL、 DCL、 CCL了解即可;
-
-
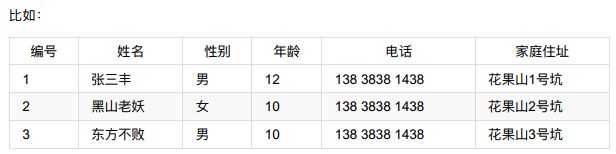
3、关系型数据库中核心元素
- 数据行(记录);
- 数据列(字段);
- 数据表(数据行的集合);
- 数据库(数据表的集合);
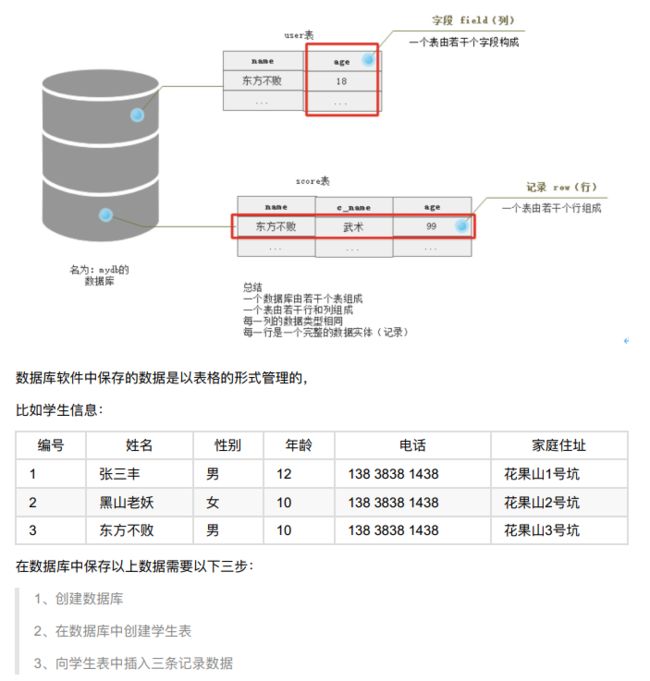
-
小结

8.1.3 MySQL环境搭建
- 1、服务端安装
- 2、MySQL配置文件
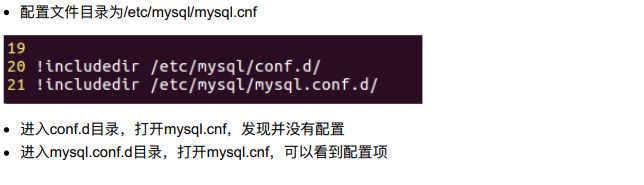
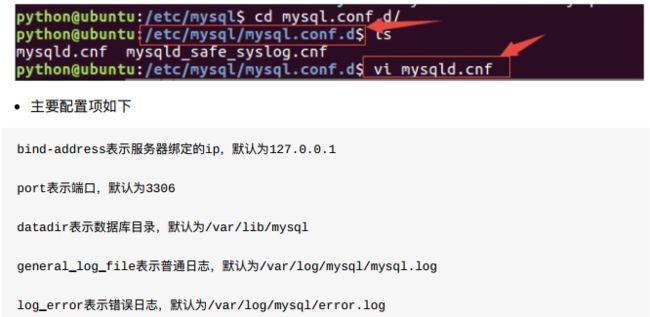
- 3、客户端安装
- 客户端为开发人员与dba使用,通过socket方式与服务端通信,常用的有nacicat、命令行mysql;
- 图形化界面客户端navicat
- 4、命令行客户端
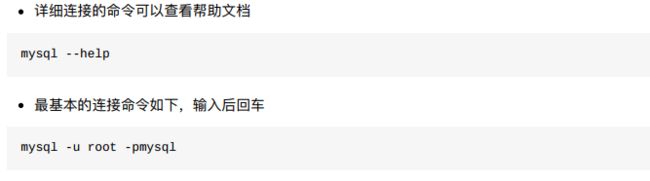

- 小结

8.1.4 数据完整性
-
1、数据库分类
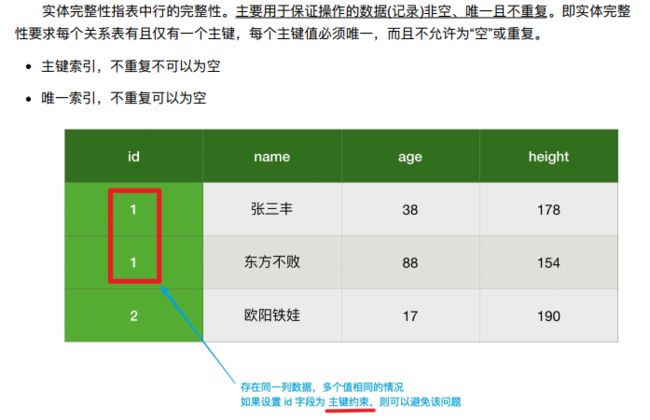
- **数据库完整性约束用于保证数据正确性。**系统在更新、插入或删除等操作时都要检查数据完整性,核实其约束条件,即关系模型的完整性规则。
- 关系模型中有四类完整性约束:
- 实体完整性;
- 域完整性;
- 参照完整性;
- 用户定义完整性;
- 其中实体完整性和参照完整性约束条件,称为关系的两个不变性;
-
2、实体完整性
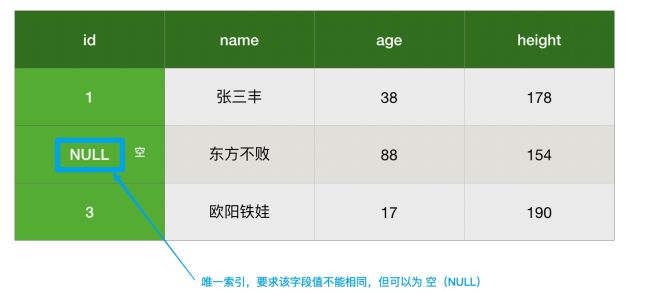
-
3、域完整性—一列保持一致

-
4、参照完整性—父类删除,子类也要跟着删除
- 参照完整性属于表间规则。 对于永久关系的相关表, 在更新、 插⼊或者删除记录时, 如果只改其⼀, 就会影响数据的完整性。 如删除⽗表的某记录后, ⼦表的相应记录未删除, 致使这些记录称为孤⽴记录。 对于更新、 插⼊、 删除表间数据的完整性, 统称为参照完整性。
-
5、用户定义完整性(在用户定义的取值范围内,男/女)
- ⽤户定义完整性是对数据表中字段属性的约束, ⽤户定义完整性规则也称域完整性规则。 包括字段的值域、 字段类型和字段的有效规则等约束, 是由确定关系结构时所定义的字段属性决定的。
-
6、常见约束介绍
-
小结

8.2 客户端Navicat使用
- 目标
- 使用Navicat创建数据库;
- 使用Navicat在数据库中创建数据库表;
- 使用Navicat在数据库中添加数据;
- MySQL 数据库本身⾃带有命令⾏⼯具, 也有图形管理⼯具 MySQL Workbench. 但⾃带的⼯具在功能上和易⽤性上总⽐不上第三⽅开发的⼯具, ⽐如 Navicat, 使⽤它你⼏乎能完成任何针对 MySQL 的管理任务.
- Navicat 是⼀套快速、 可靠并价格适宜的数据库管理⼯具, 适⽤于三种平台, Microsoft Windows、Mac OS X 及 Linux. 可以⽤来对本机或远程的 MySQL、 SQL Server、 SQLite、 Oracle 及PostgreSQL 数据库进⾏管理及开发. 专为简化数据库的管理及降低系统管理成本⽽设. 它的设计符合数据库管理员、 开发⼈员及中⼩企业的需. Navicat 是以直觉化的图形⽤户界⾯⽽建的, 让你可以以安全并且简单的⽅式对数据库进⾏操作.
- 数据库客户端工具使用三个方面:
- 1)数据库操作;
- 2)数据表的操作;
- 3)数据库表中数据的操作;
-
1、数据库操作–创建、编辑、删除
-
2、数据表的操作
-
小结

-
3、数据库表中数据的操作
- 1)查看数据;
- 2)增加数据;—自动增长的主键列不需要填写值;
- 3)修改数据;
- 4)删除数据;
-
小结

8.3 MySQL数据类型
-
1、数据类型简述
- MySQL中定义数据字段的类型对你数据库的优化是非常重要的,
- MySQL支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
-
2、数值
-
2.1 整型类型
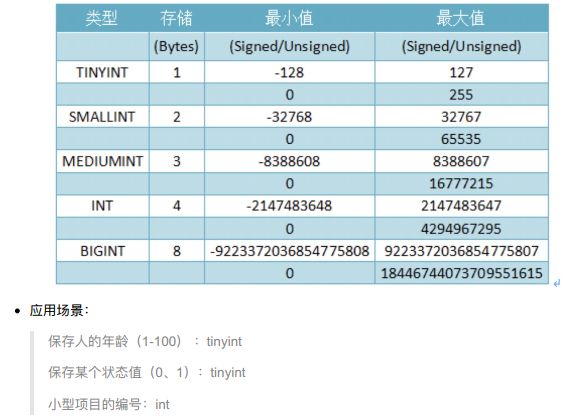
-
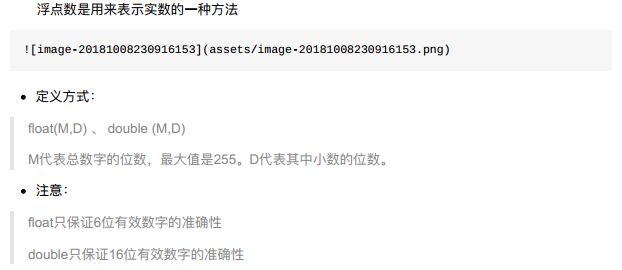
2.2 浮点型
-
2.3 定点数
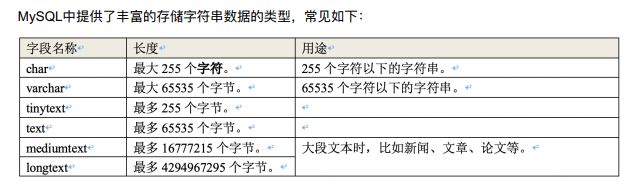
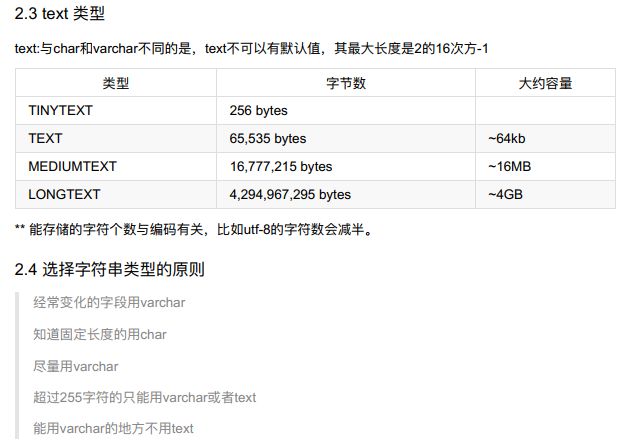
 * 3、字符串
* 3、字符串

-
4、枚举类型

-
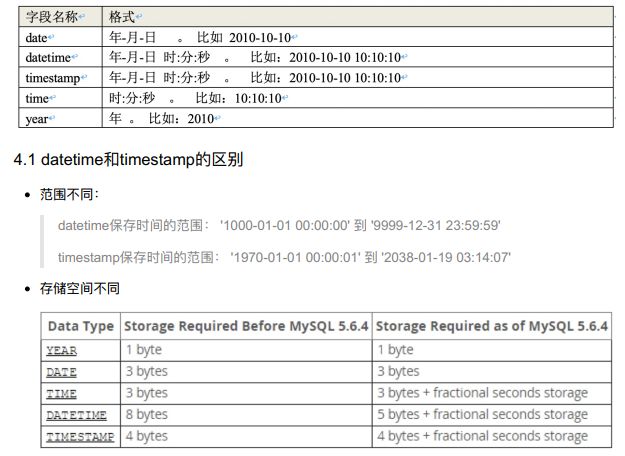
5、时间类型
-
小结

8.4 SQL命令
8.4.1 登录和退出数据库

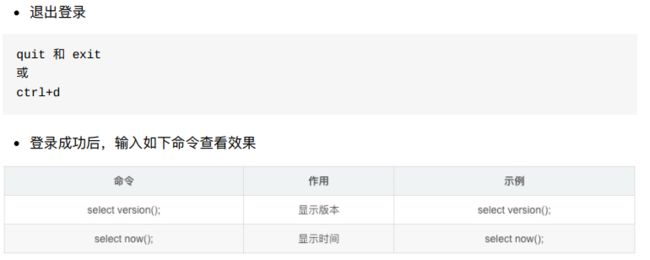
8.4.2 数据库操作

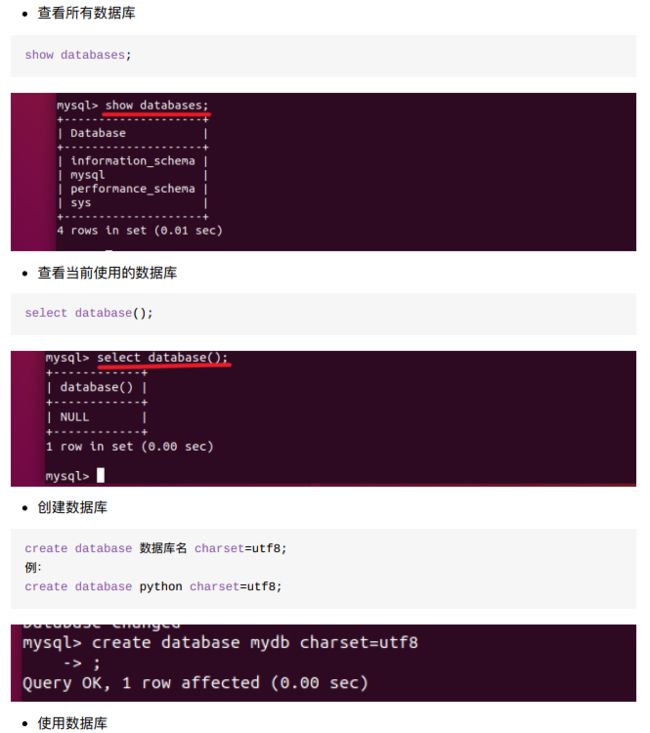
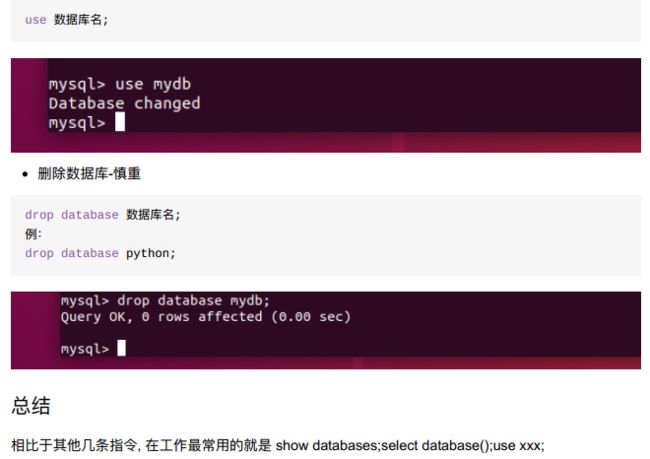
8.4.3 表结构的创建
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-f36pbesL-1654428641579)(https://raw.githubusercontent.com/caterpillar-0/picture/main/image-20220528152037284.png)]

- 小结

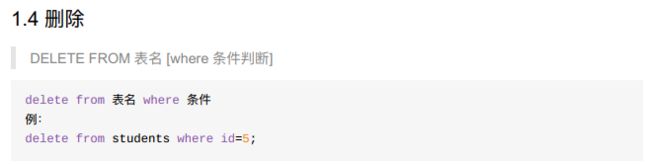
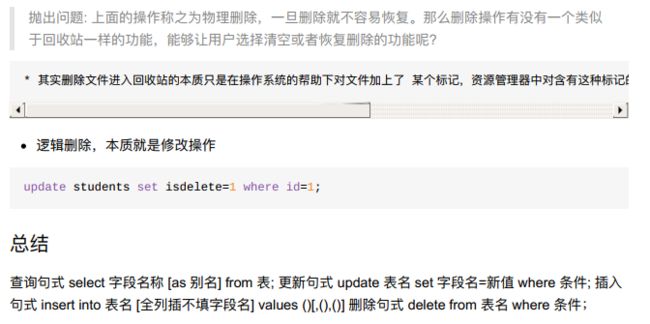
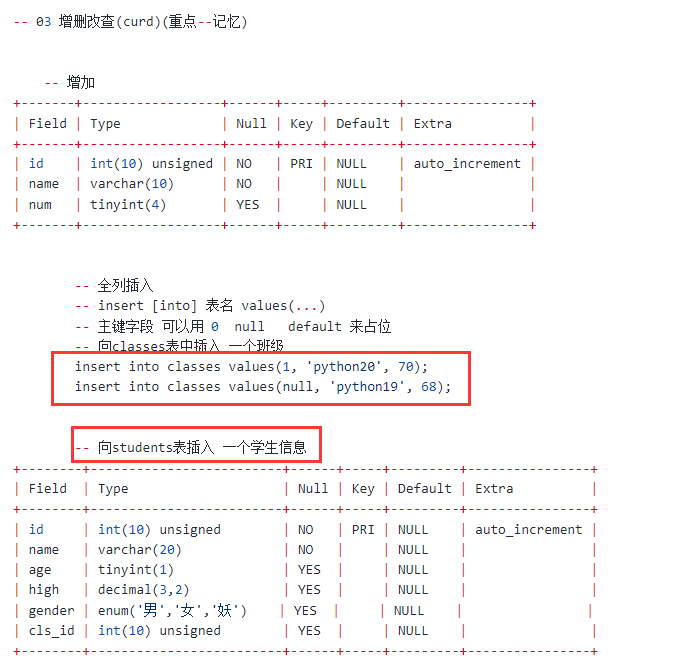
8.4.5 表数据操作-增删查改(curd)
- 创建create;
- 更新update;
- 读取retrieve/read;
- 删除delete;


- 小结


9 MySQL数据库进阶操作
9.1 练习强化
- 学习目标
- 说出as的作用;
- 说出distinct的作用;
- 1、查询强化


-
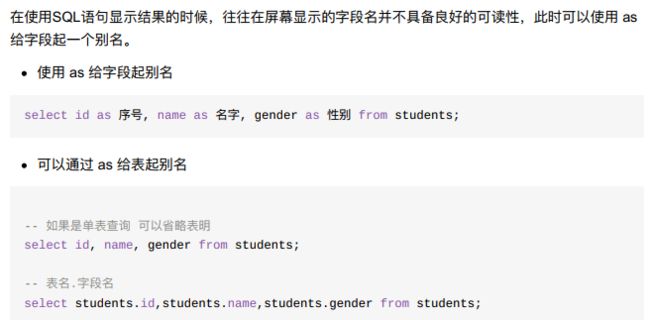
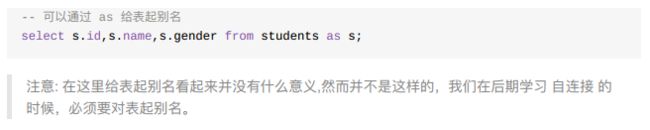
2、as关键字
-
注意,起了别名,在后面as s,前面就不可以在用students.id了
-
3、消除重复行

-
小结
- 1)as关键字可以给表中字段或者表名起别名;
- 2)distinct关键字可以把数据去重;

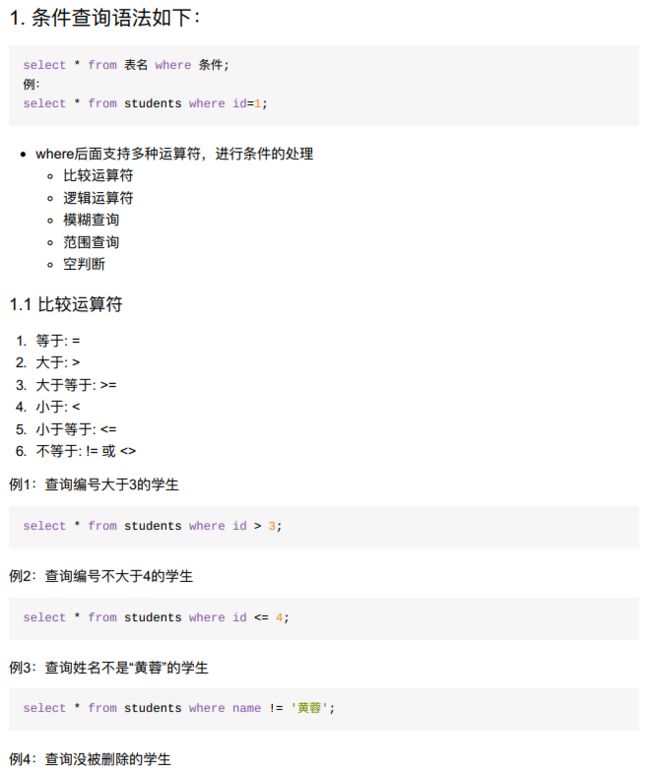
9.2 where条件查询
9.2.1 where之比较运算=,<,>,!=,<>
- 能够说出常见的比较运算符;
- where语句作用:使用where子句对表中的数据筛选,结果为true的行会出现在结果集中。

- 小结

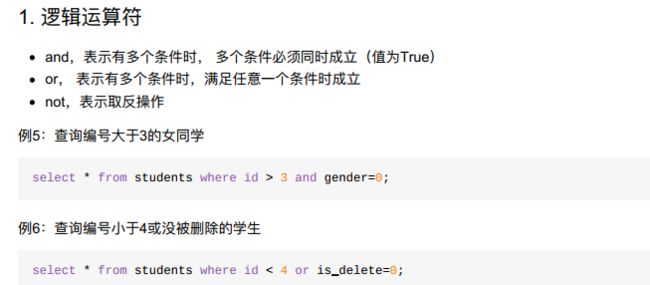
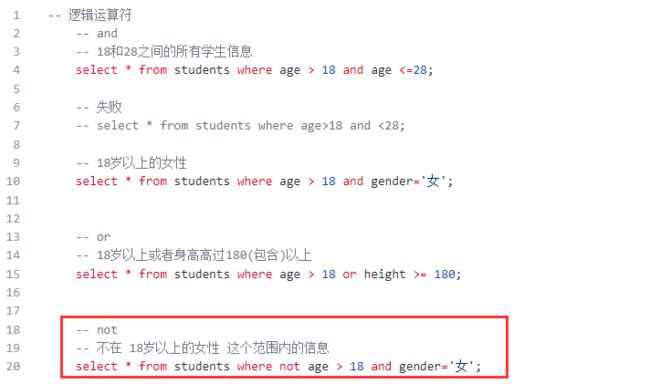
9.2.2 where之逻辑运算and、or、not
- 目标
- 逻辑运算符and、or、not作用
- 小结
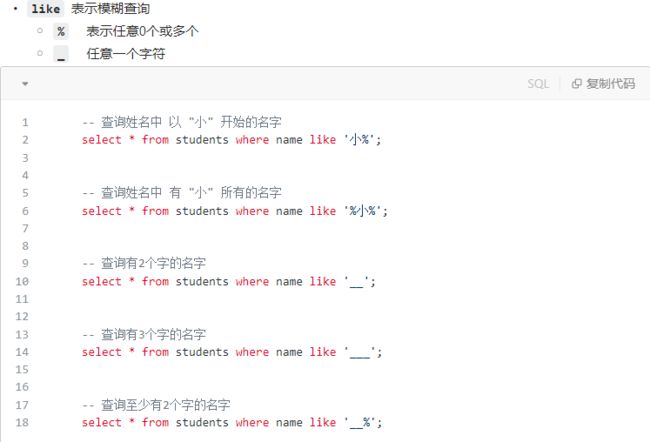
9.2.3 where之模糊查询like

- 小结
9.2.4 where之范围查询
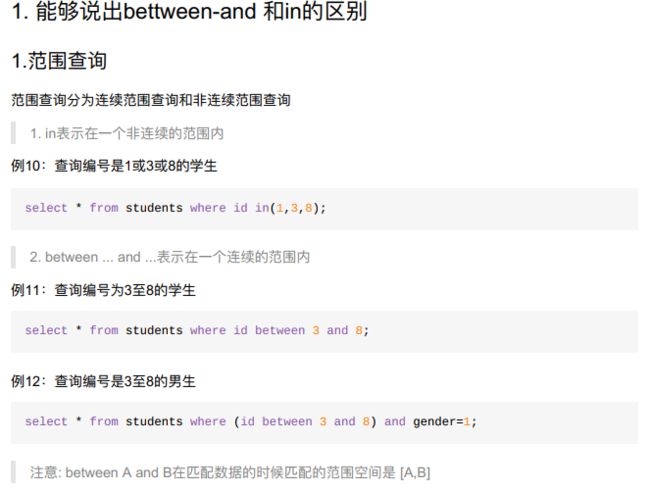
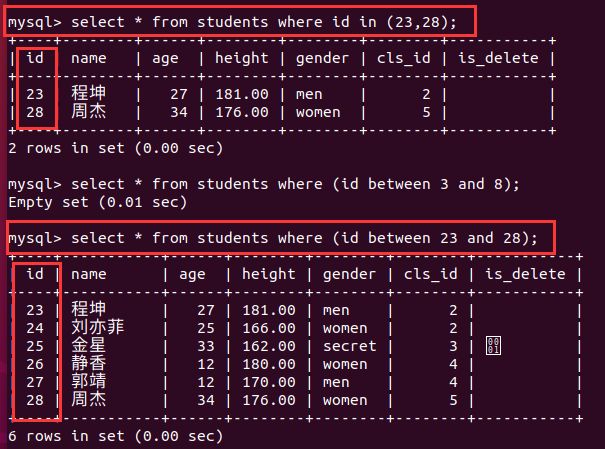
- 小结
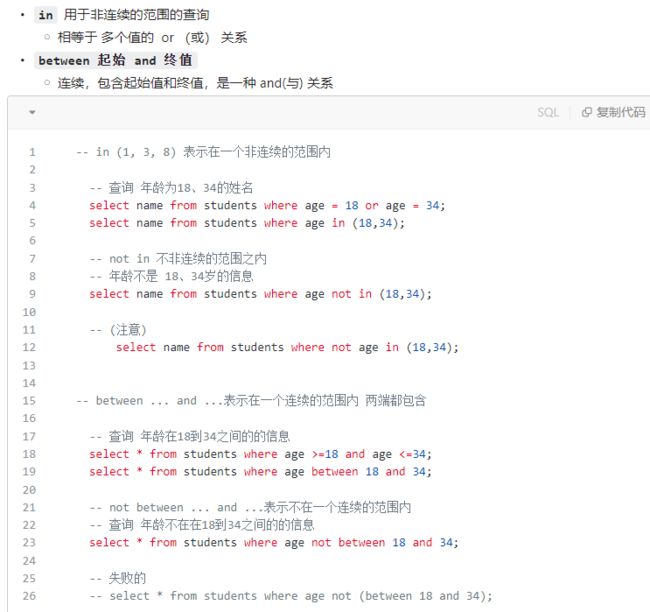
9.2.5 where之空值判断



9.3 查询语句进阶-order,聚合,group,limit,分页
9.3.1 order排序
- 目标
- 说出排序使用的关键字;
- 说出升序和降序分别使用的关键字
- 1、排序的作用
- 程序中的排序:
- 以⼤家搜索百度为例。 ⽤户在百度上搜索 MySQL的特点, 作为⼀个⽹站往往需要把和⽤户最为需要的⽹⻚和数据发送给客户, 那么如何才能认定这个数据是⽤户最需要的呢? 百度就会把⽤户搜索的关键字和数据库中已经存在的⽹⻚进⾏关联性的分析, 将关联度⾼的⽹⻚准备发送给⽤户浏览, 但是问题来了 有很多关联性⼏乎⼀致的⽹⻚到底应该给⽤户优先推送哪个⽹⻚呢, 谁在前⾯谁在后⾯呢?
- 答案就是排序。 先将所有的数据的关联程度进⾏排序, 然后将关联程度⼀样的数据 根据 ⽐如⽤户的点击量等属性进⾏排序。
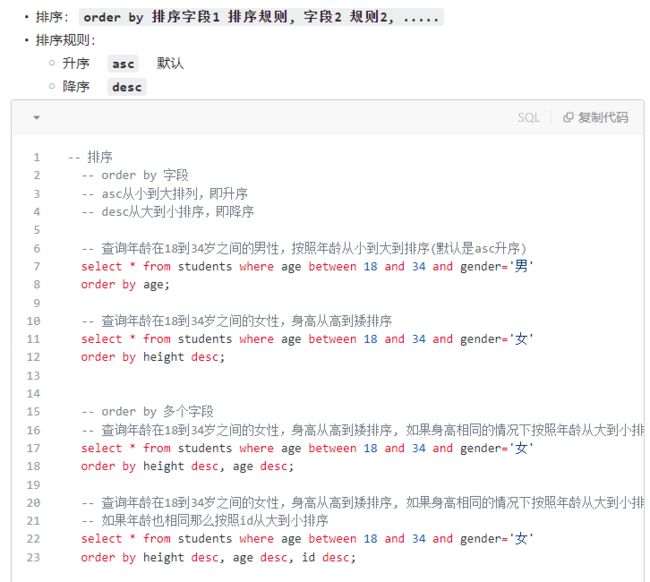
- 2、排序查询语法

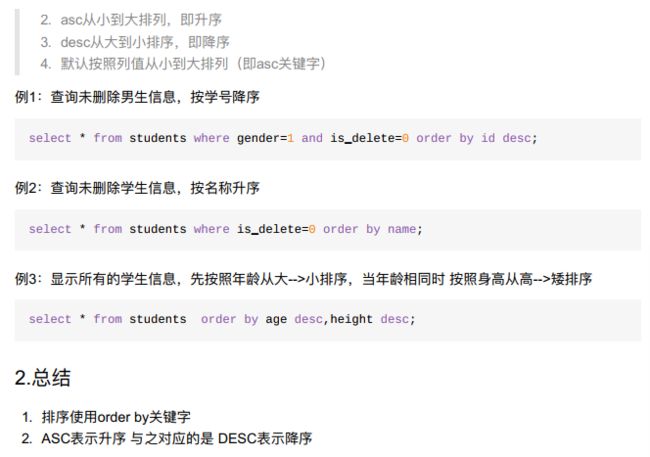
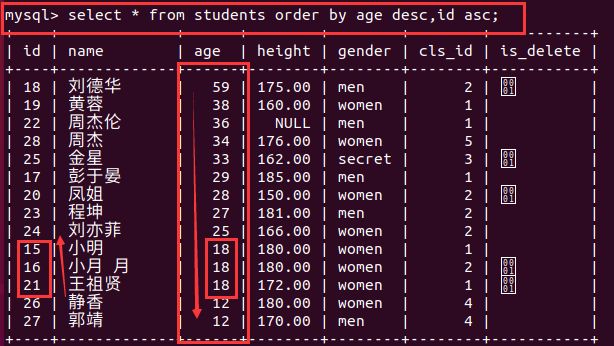
- 小结
9.3.2 聚合函数
- 目标
- 求出集合中的数据的最大值/最小值;
- 求出集合中的数据的数量;
- 求出集合中数据的和;
- 求出集合中数据的平均值;
- 1、聚合函数的作用
- 1)聚合函数aggregation function又称为组函数;
- 默认情况下,聚合函数会对当前所在表当做一个组进行统计;
- 2)聚合函数有以下几个特定:
- 每个组函数接收一个参数(字段名或者表达式);
- 统计结果中默认忽略字段为NULL的记录,要想列值为NULL的行也参与组函数计算,必须使用IFNULL函数对NULL值进行转换;
- 3)不允许出现嵌套,比如sum(max(xx));


- round不是聚合函数,四舍五入,保留小数位数,
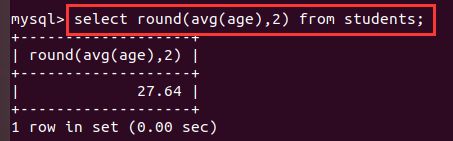
- 小结



9.3.3 group分组查询
- 学习目标
- 分组的目的;
- 使用group by完成对数据的分组;
- 说出group_concat函数的作用;
- 使用聚合函数完成对分组结果的统计;
- 使用having完成对分组结果的条件过滤;
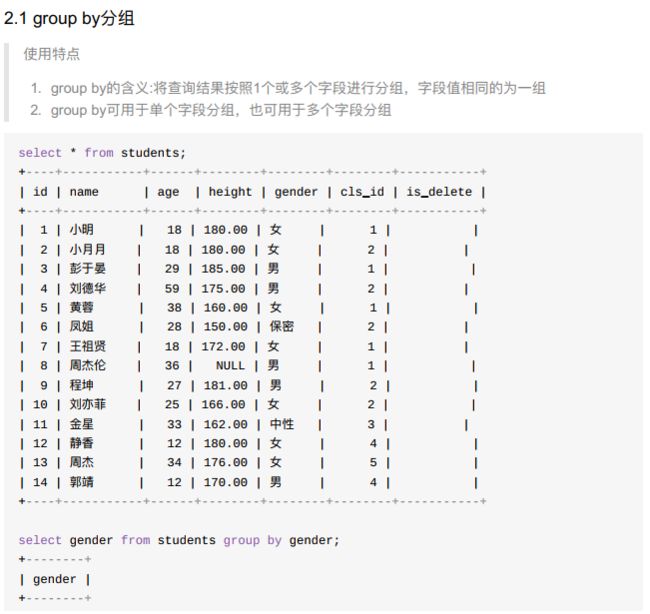
- 1、分组用法
所谓分组就是将一个“数据集”划分为若干个“小区域”,然后针对若干个“小区域”进行数据处理;
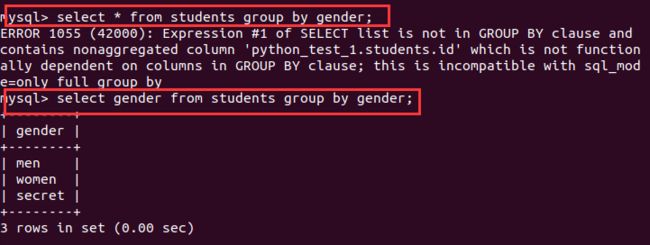
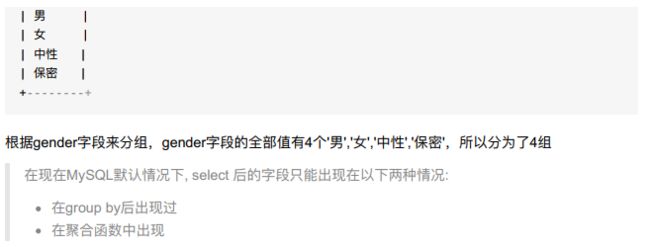


- having是分组之后进行条件过滤。where是在分组之前(抓取数据的时候)就开始条件过滤选了!!
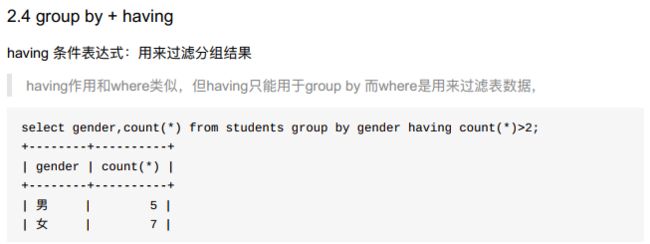
- 可以给avg(age)其别名。在having时可以使用
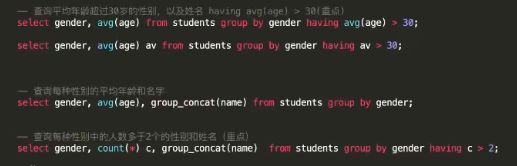

- 小结

9.3.4 limit限制记录
- 学习目标
- 知道limit关键字的作用;
- 知道limit后面两个参数的作用;

- 小结
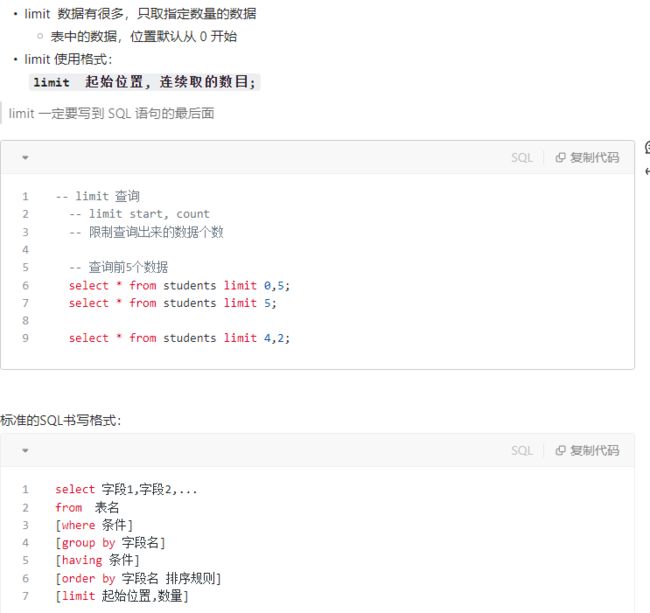
9.3.5 分页查询
- 1、分页的使用
当排序经过数据分析之后, 根据关联度和点击量等属性排序后, 所有的数据的⼤⼩对于⽤户来讲是个天⽂数字并且⽤户也不⼀定需要这么⼤量的数据, 所以这个时候就有⼀个想法能不能把这么多数据分成⼀⻚⼀⻚的数据, ⽽ 根据⽤户的需要将数据分为⼀⻚⼀⻚地传输给⽤户的技术就是分⻚。

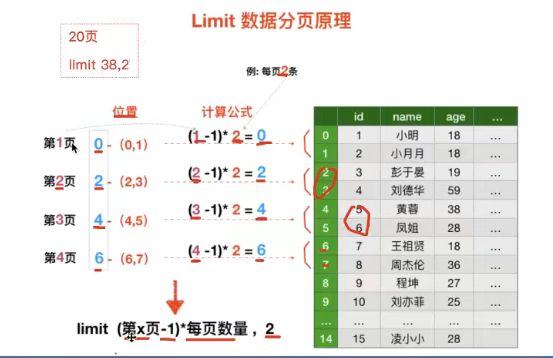
9.4 查询高级-连接,自连接,子连接
9.4.1 连接查询
- 学习目标
- 1)说出连接的作用;
- 2)说出笛卡尔积,内连接,外连接;
- 3)inner join关键字完成对多张表的内连接查询(重点);
- 4)使用left join关键字完成对多张表的左连接查询;
- 5)使用right join关键字完成对多张表的右连接查询;
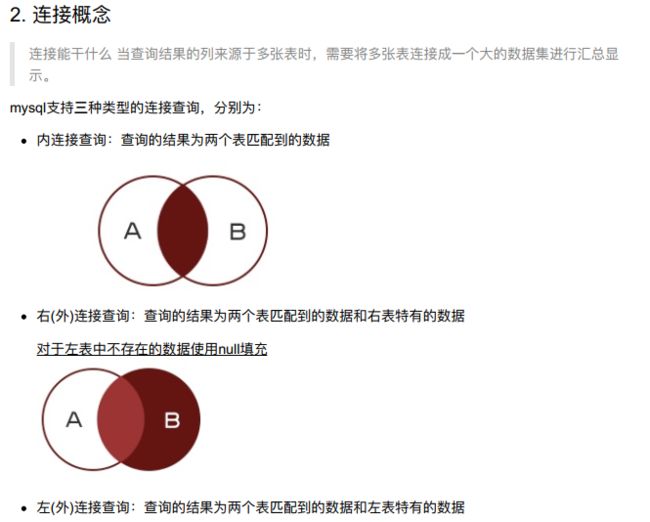


- 1、内连接的方式,笛卡尔积
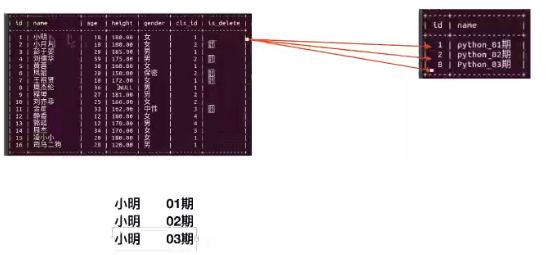
- 内连接—练习:
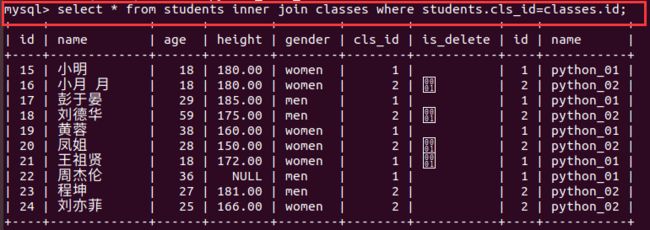
- on替换where
- 2、外连接
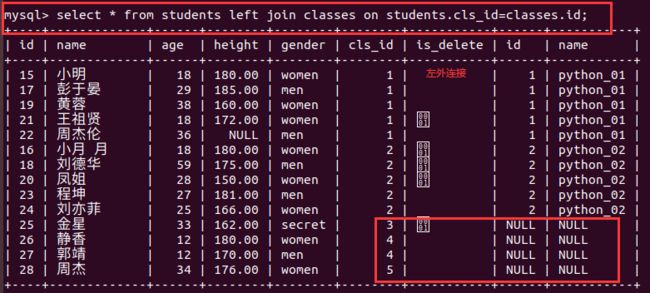
- (1)左连接,左边是主表,优先保留左边的,如果左边有一个cls_id=4,右表即使没有对应也保留为NULL;总字段是两者之和

- (2)右连接,右边为主表,

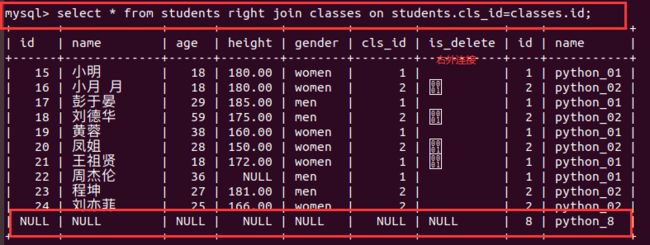
- 小结

-- 连接查询(重点)
-- inner join ... on
-- select ... from 表A inner join 表B;
select * from students inner join classes;
-- 查询 有能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id = classes.id;
-- 按照要求显示姓名、班级
select students.name, classes.name
from students inner join classes on students.cls_id = classes.id;
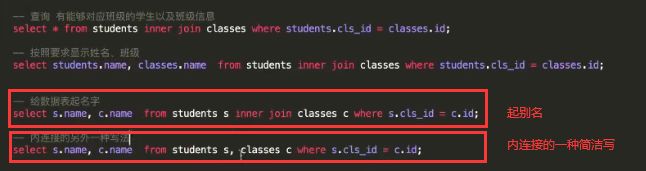
-- 给数据表起名字
select s.name, c.name from students s inner join classes c on s.cls_id = c.id;
-- 92写法
select s.name, c.name from students s, classes c where s.cls_id = c.id;
-- 查询学生以及对应班级信息,显示学生的所有信息students.*,只显示班级名称classes.name
select students.*, classes.name
from students inner join classes on students.cls_id = classes.id;
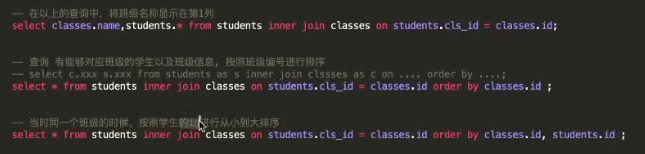
-- 在以上的查询中,将班级名称显示在第1列
select classes.name,students.*
from students inner join classes on students.cls_id = classes.id;
-- 查询 有能够对应班级的学生以及班级信息, 按照班级编号进行排序
-- select c.xxx s.xxx from students as s inner join clssses as c on .... order by ....;
select * from students s inner join classes c on s.cls_id = c.id order by c.id;
-- 当时同一个班级的时候,按照学生的id进行从小到大排序
select * from students s inner join classes c on s.cls_id = c.id order by c.id, s.id;
-- left/right join ....on
-- 查询每位学生对应的班级信息
select * from students left join classes on students.cls_id = classes.id;
-- 查询每班级对应的学生信息
select * from students right join classes on students.cls_id = classes.id;
-- 查询没有对应班级信息的学生
-- select ... from xxx as s left join xxx as c on..... where .....
-- select ... from xxx as s left join xxx as c on..... having ..... 不要使用
select students.*
from students left join classes on students.cls_id = classes.id
where classes.id is null;
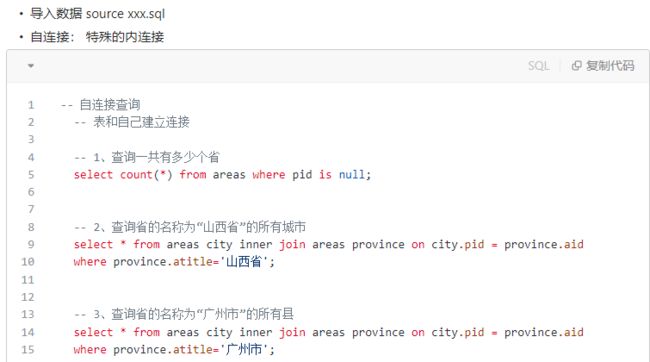
9.4.2 自连接查询
- 学习目标
- 说出自连接作用;
- 说出自连接和普通连接上使用的区别;
- 1、自连接概述



- 小结
- 1)当需要将多张“表”的相关数据汇总一个结果集中,并且多张“表”的数据来自于同一张表;
- 2)自连接就是一种特殊的连接方式;
- 3)需要对表起多个不同的别名才能进行自连接查询;
 #### 9.4.3 子查询
#### 9.4.3 子查询
- 学习目标
- 标量子查询;行子查询;列子查询;


- 小结

-- 子查询
-- 标量子查询: 子查询返回的结果是一个数据(一行一列)
-- 列子查询: 返回的结果是一列(一列多行)
-- 行子查询: 返回的结果是一行(一行多列)
-- 查询出高于平均身高的信息(height)
-- 1 查出平均身高
select avg(height) from students;
-- 2 查出高于平均身高的信息
select * from students where height > (select avg(height) from students);
-- 查询学生的学号和班级编号对应的学生信息
-- select name from students where cls_id in (select id from classes);
-- 1 查出所有的班级id
select id from classes;
-- 2 查出能够对应上班级号的学生信息
select * from students where id in (select id from classes);
10 MySQL数据库编程
10.1 MySQL使用基本语法-外键、视图
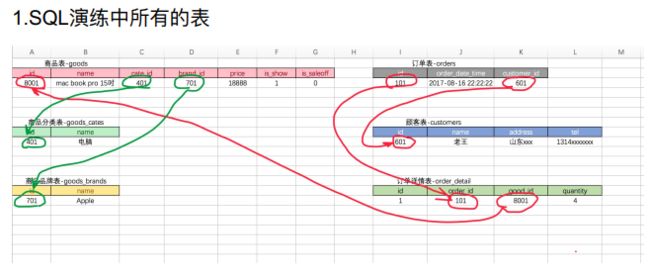
10.1.1 SQL演练(复习)
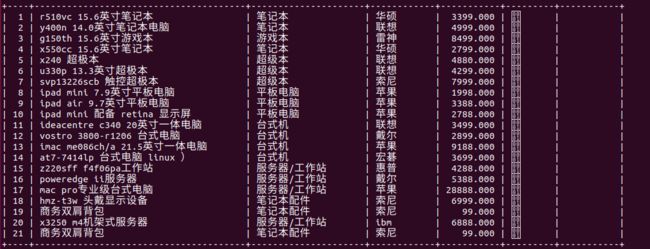
- 1、创建数据表

- 2、插入数据

- 小结
-- sql强化演练( goods 表练习)
-- 查询类型 cate_name 为 '超级本' 的商品名称 name 、价格 price ( where )
select name, price from goods where cate_name = '超级本';
-- 显示商品的种类
-- 1)分组的方式( group by )
select cate_name from goods group by cate_name;
-- 2)去重的方法( distinct )
select distinct cate_name from goods;
-- 求所有电脑产品的平均价格 avg ,并且保留两位小数( round )
select round(avg(price), 2) from goods;
-- 显示 每种类型 cate_name (由此可知需要分组)的 平均价格
select cate_name, avg(price) from goods group by cate_name;
-- 查询 每种类型 的商品中 最贵 max 、最便宜 min 、平均价 avg 、数量 count
select cate_name, max(price), min(price), avg(price), count(*) from goods group by cate_name;
-- 查询所有价格大于 平均价格 的商品,并且按 价格降序 排序 order desc
-- 1)查询平均价格 avg(price)
select avg(price) from goods;
-- 2)使用子查询
select * from goods where price > (select avg(price) from goods) order by price desc;
-- 查询每种类型中最贵的电脑的所有信息(难)
select * from goods where price in (select max(price) from goods group by cate_name);
-- 1 查找 每种类型 中 最贵的 max_price 价格
select cate_name, max(price), group_concat(name) from goods group by cate_name;
-- 2 关联查询 inner join 每种类型 中最贵的物品信息
select * from goods
inner join
(select cate_name, max(price) as max_price from goods group by cate_name) as max_price_goods
on goods.cate_name = max_price_goods.cate_name and goods.price = max_price_goods.max_price;
- 3、SQL语句强化

10.2.2 SQL操作实战
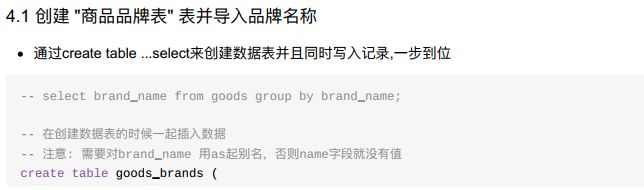
- 1、根据商品表中分类信息创建分类表

- 2、根据商品表中品牌信息创建品牌表
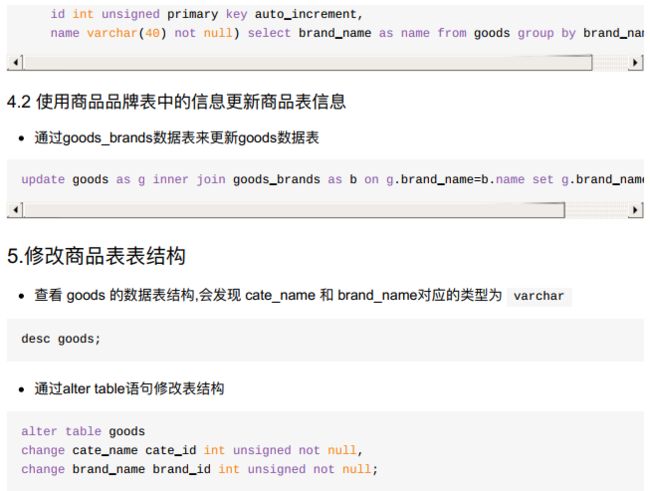
- 小结
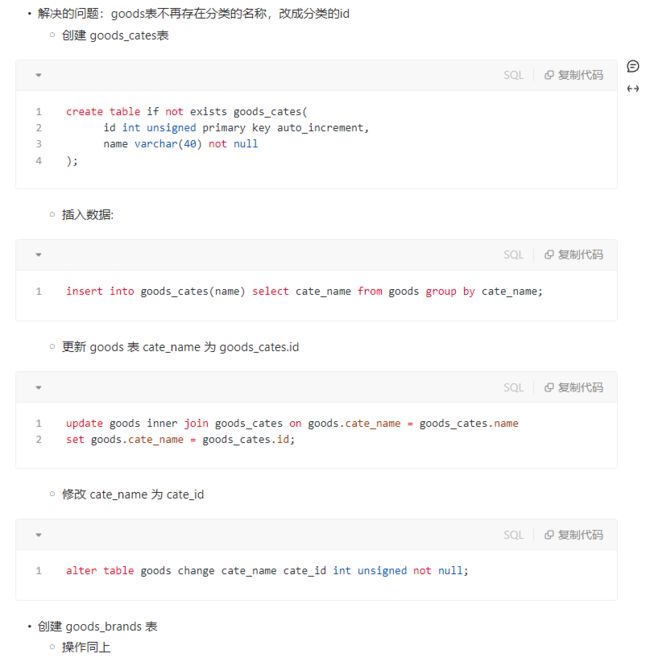
10.2.3 外键使用
- 1、外键
- 外键foreign key约束指定某一个列或一组列作为外部键,其中包含外部键的表称为子表,包含外键所引用的键的表称为父表;

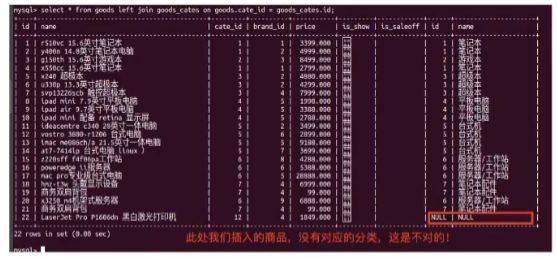
- 为了防止无效信息的插入,需要在插入前判断类型或者品牌名称是否存在,可以使用外键解决:
- 1、外键约束:对外键字段的值,在更新和插入时进行和引用的表中的字段数据进行对比;
- 2、关键字:foreign key,只有innodb数据库引擎支持外键约束;


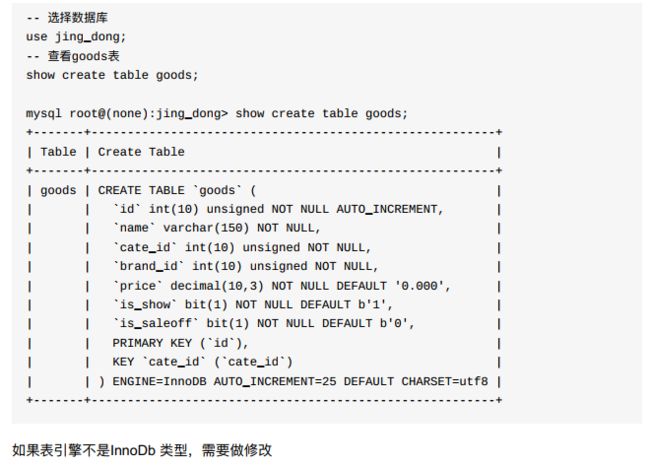
- 2、对于已经存在的字段添加外键约束
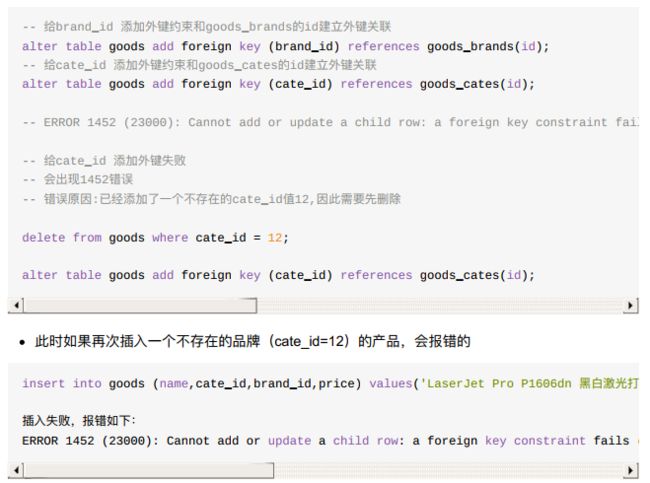
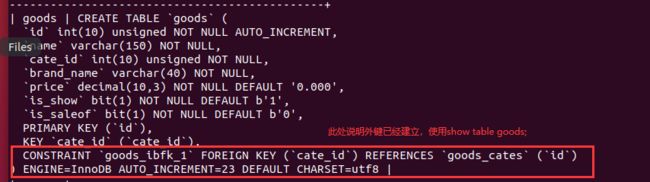
show create table goods;
- 外键约束后,重新插入就会报错;

- 3、在创建数据表的时候设置外键约束

- 4、删除外键约束
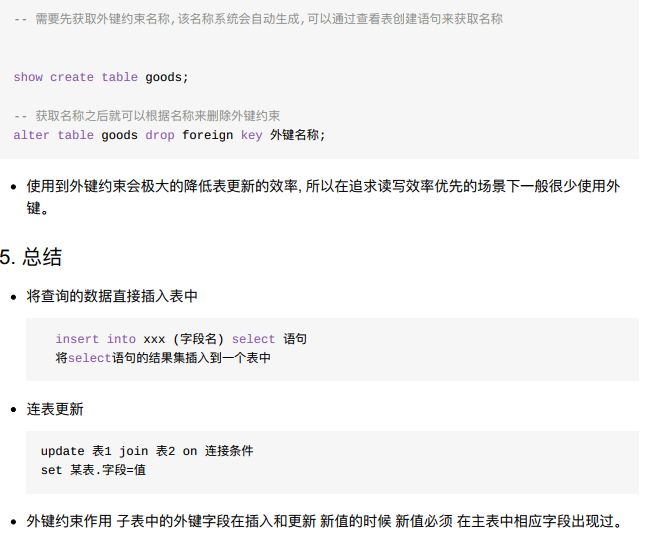
- 小结

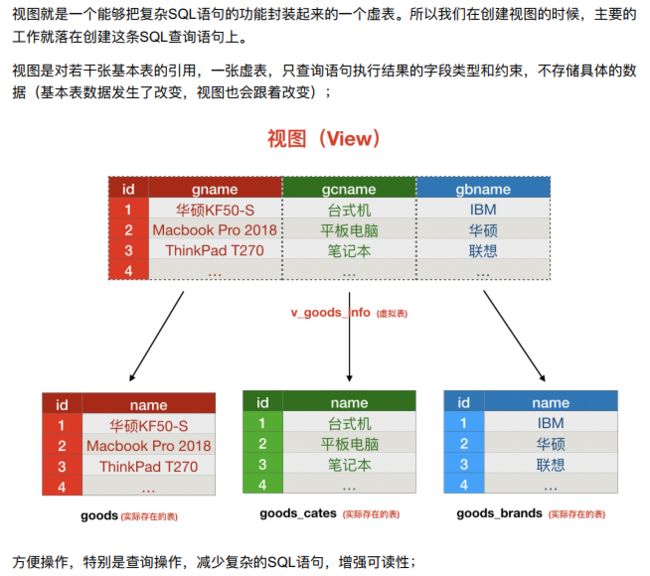
10.1.4 视图–是一个虚拟表
- 1、视图的作用
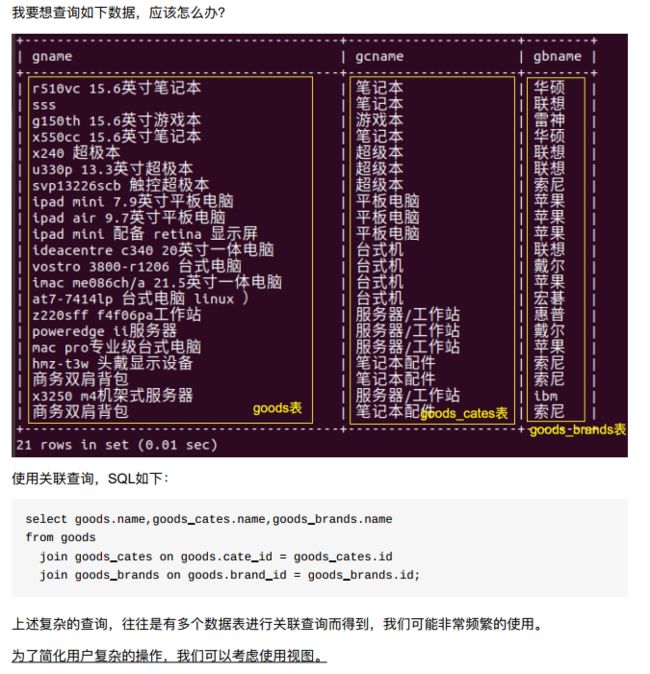
- 2、视图简介
- 3、视图的使用
- !!需要起别名!!

- 视图是一个虚拟表,真实数据还在原来的表中,当原来表数据发生改变,视图会自动更新改变!!!



- 小结

-- 视图的定义方式
-- crete view 视图名 as select ....
-- 查出产品表中产品名称、分类名称以及对应品牌
-- 创建上述结果的视图( v_goods_info)
create view v_goods_info as
select goods.name gname,goods_cates.name gcname,goods_brands.name gbname
from goods
inner join goods_cates on goods.cate_id = goods_cates.id
inner join goods_brands on goods.brand_id = goods_brands.id;
-- 查看所有表和视图
show tables; # v_goods_info;
-- 当原表产品名称改变后,会影响视图(视图是虚拟表)
update goods set name = 'xxx' where id = 24;
-- 删除视图
-- drop view 视图名;
drop view v_goods_info;
-- 注意
-- 视图只能进行搜索
-- 视图作用总结
-- 1 提高了重用性,就像一个函数
-- 2 对数据库重构,却不影响已经编写好的程序运行
-- 3 提高了安全性能,可以对不同的用户
-- 4 让数据更加清
-- 视图最主要解决的问题
-- 程序对数据库操作,一旦数据库发生变化,程序需要修改,这时如果使用视图就可以解决这个问题
10.2 事务—为了解决一件事一次性完成
10.2.1 事务简介及特性
- 学习目标
- 说出事务的使用场景;
- 事务的四个特性以及分别含义;
- 1、事务简介
- 事务Transaction,是指作为一个基本工作单元执行的一系列SQL语句的操作,要么完全的执行,要么完全的都不执行


- 2、事务四大特性ACID
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)


- 小结

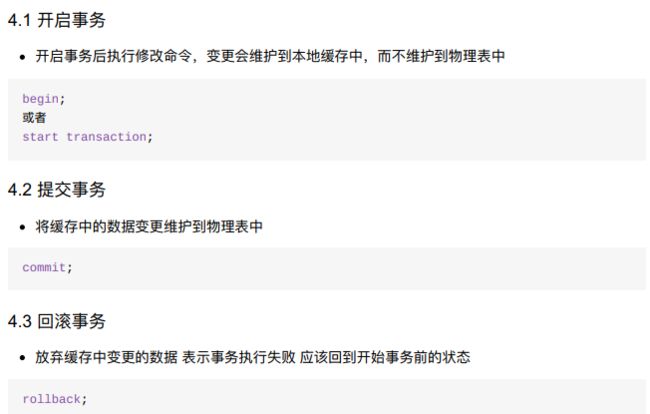
10.2.2 事务使用
- 学习目标
- 说出commit对事务的作用;
- 说出rollback对事务的作用;
- 1、查看表引擎
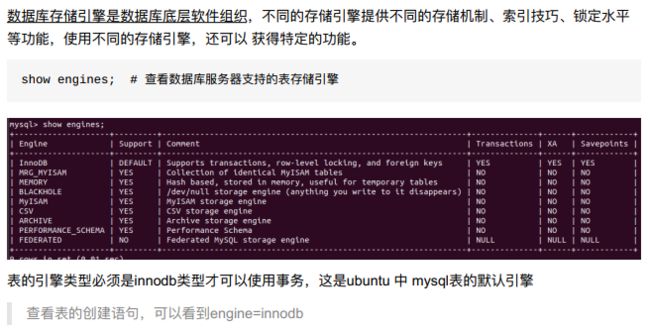
10.2.3 验证事务的ACID特性


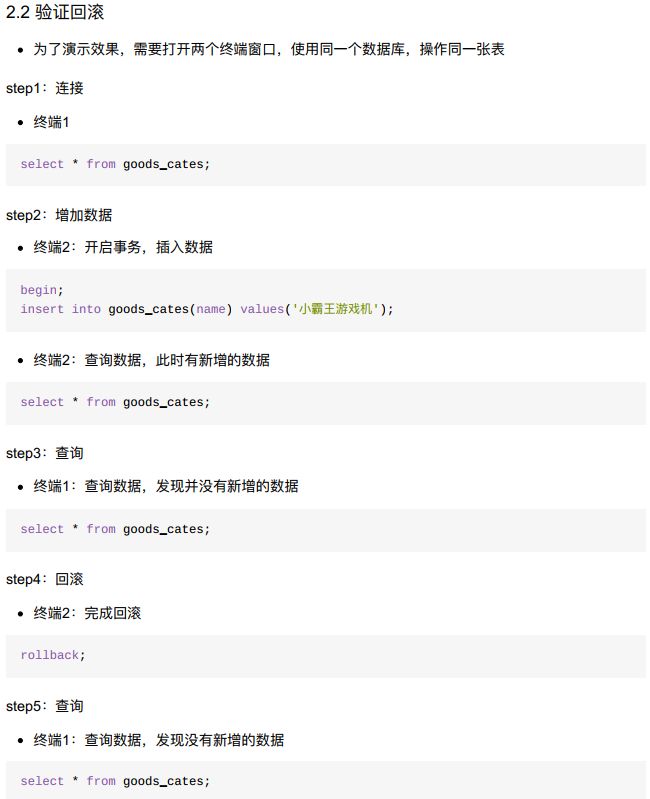
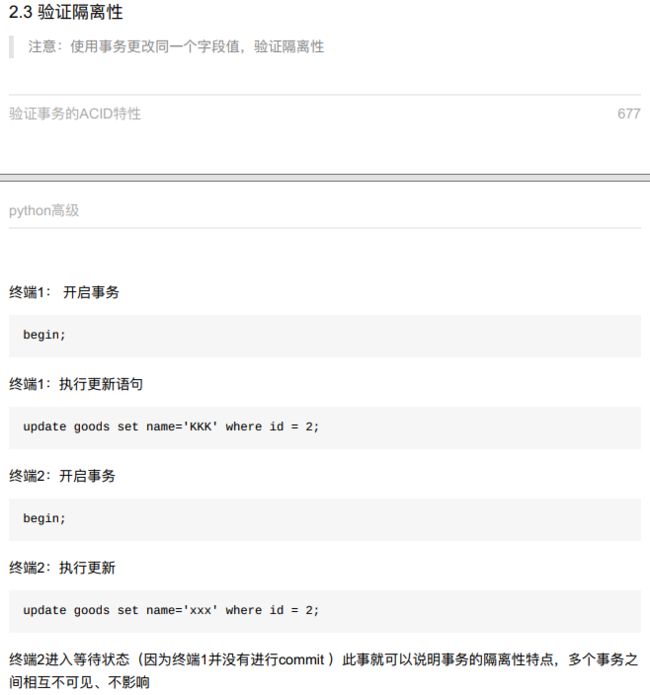
- 不可以同一时间修改同一字段—隔离性


- 小结

10.3 数据库设计-三范式,E-R模型
10.3.1 数据库三范式
- 学习目标
- 一个表结构设计是否满足范式的要求;
- 1、数据库设计三范式
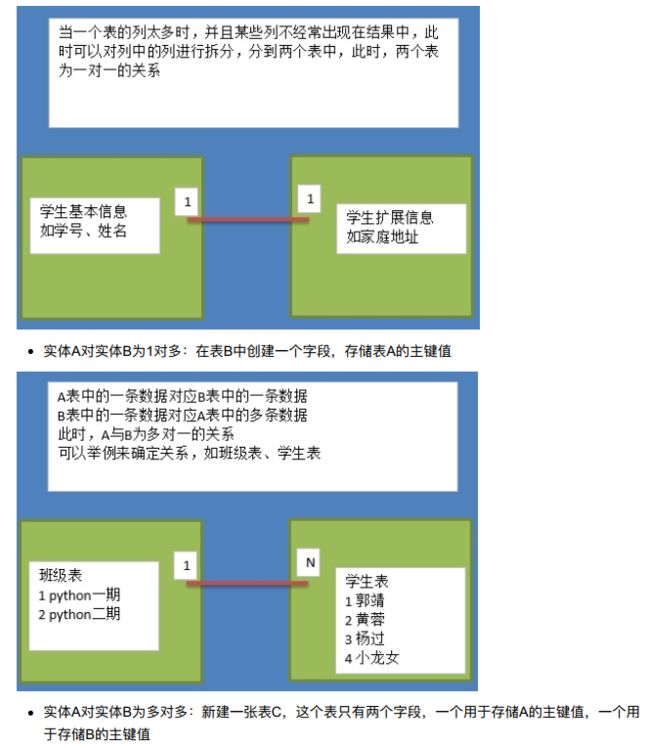
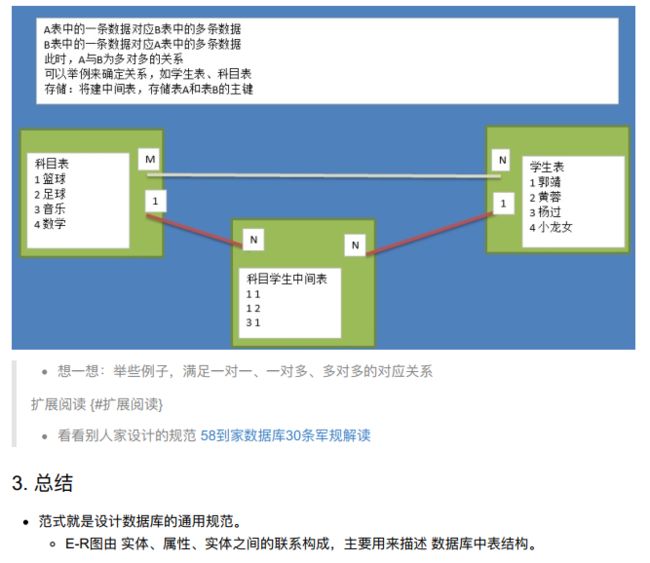
- 经过研究和对使用的问题总结,对于设计数据库提出了一些规范,这些规范称为范式(Normal Form);
- 目前有迹可循的共有8种范式,一般需要遵守3范式即可;
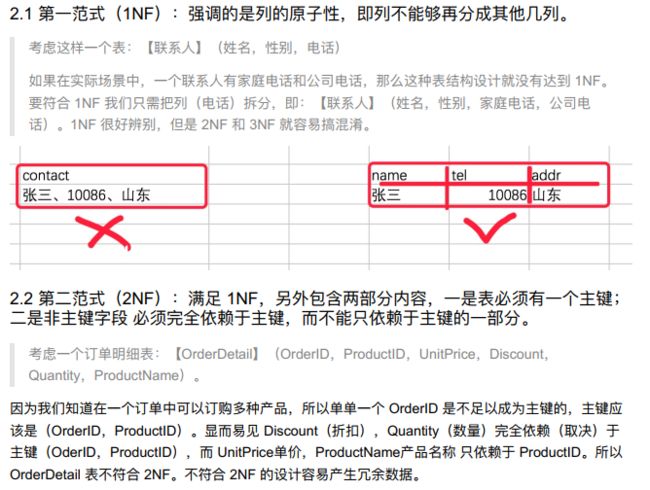
- 一个主键可以有两个字段,形成组合主键,下面就是orderid(订单号)和productid(商品号)组合主键,unitprice是属于商品的,discount折扣是属于订单的,字段依赖于不同的主键,因此设计不合理
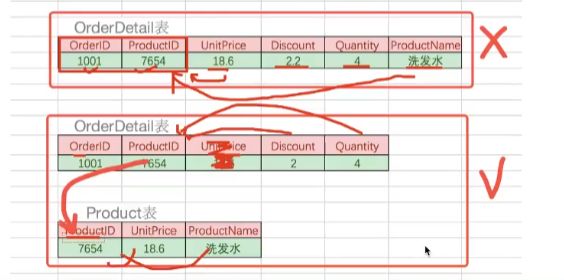

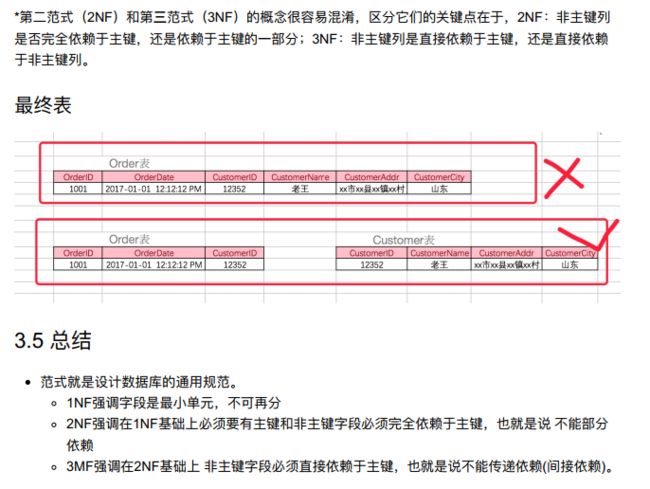
10.3.2 数据库的设计


- 注意:
- 1)创建外键关联之前,要引用的表必须先存在;
- 2)满足数据库设计三范式;
- 字段原子;
- 必须完全依赖主键,不能部分依赖;
- 不能传递依赖;
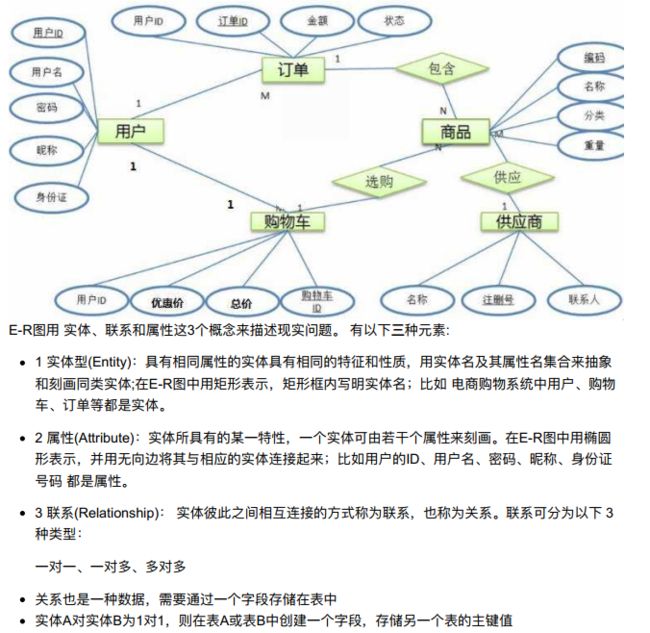
10.3.3 E-R模型及其表间关系
- 学习目标
- 了解E-R模型组成部分;
- 1、E-R模型


10.4 数据库编程-curd,防注入
10.4.1 python连接mysql
- 学习目标
- 说出python操作数据库的步骤;
- 能够connect方法创建连接对象;
- 使用连接对象的cursor()方法创建游标对象;
- 使用游标对象的execute()方法执行SQL语句;
- 使用游标对象的close()方法关闭游标对象;
- 使用连接对象的close()方法关闭连接对象;
- 1、数据库编程

- 2、python中操作mysql步骤
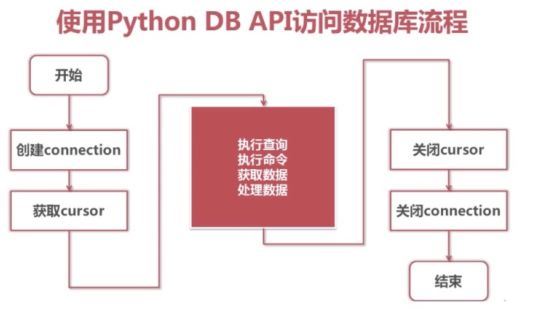

- 3、pymysql的使用
- 查询不需要建立连接,但是增删查改需要建立连接


- 小结
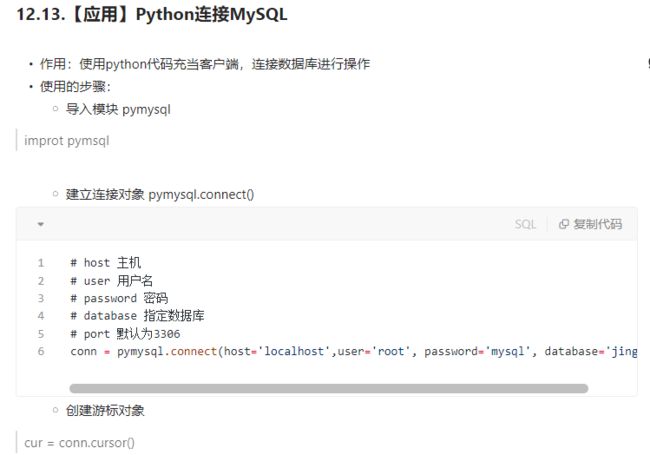

# 1、导入模块 pymysql
import pymysql
# 2、建立连接对象 pymysql.connect(),默认为3306
conn = pymysql.connect(host='localhost', port=3306, user='root', password='123123', database='jing_dong')
# 3、创建游标对象
cur = conn.cursor()
# 4、使用游标对象执行SQL语句
result = cur.execute("select * from goods order by id desc")
print("查询到:%s条数据" % result)
# 5、获取执行的结果
# cur.fetchone() 从查询的结果中取出一条数据
# result_list = cur.fetchone()
# print(result_list)
result_list = cur.fetchall()
for line in result_list:
# line 一行 是一个元组
print(line)
cur.close()
conn.close()
- ctrl+?可以实现多行注释
10.4.2 python操作数据库CURD(增删查改)
- 学习目标
- 使用游标对象的fetchall()方法取出所有数据;
- 使用游标对象的fetchone()方法取出一条数据;
- !!注意:要commit()才可以!!
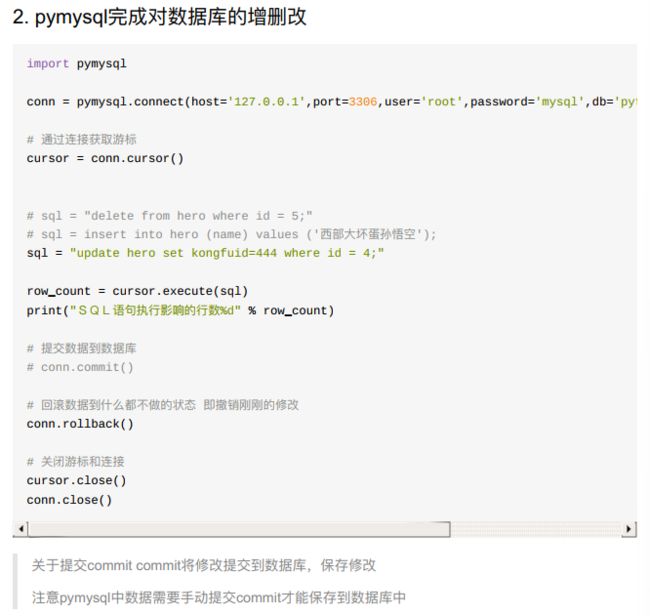
10.4.3 SQL防注入
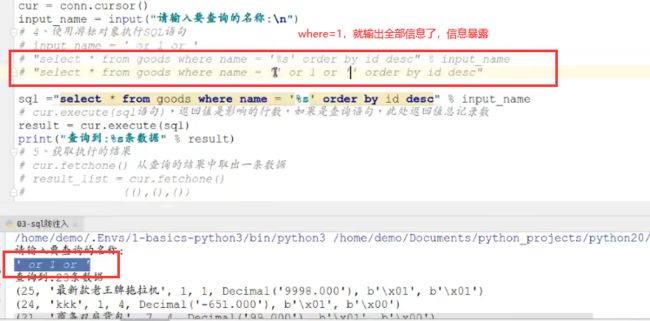

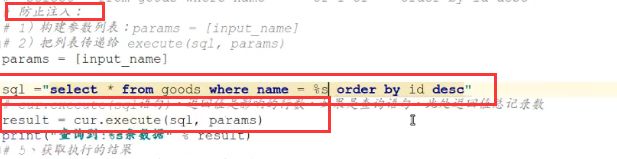
- 小结

11 MySQL高级&装饰器基础
11.1 索引
- 1、索引的作用
- 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),包含着对数据表里所有记录的位置信息;
- 通俗来说,数据库索引好比一本书的目录,能加快数据库的查询速度;
- 2、索引原理(B+树)

- 3、索引的使用


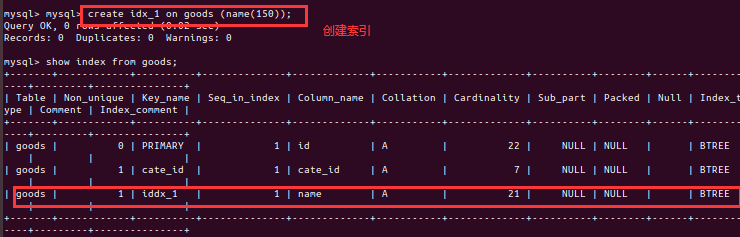

- 4、验证索引是否能够提升查询性能
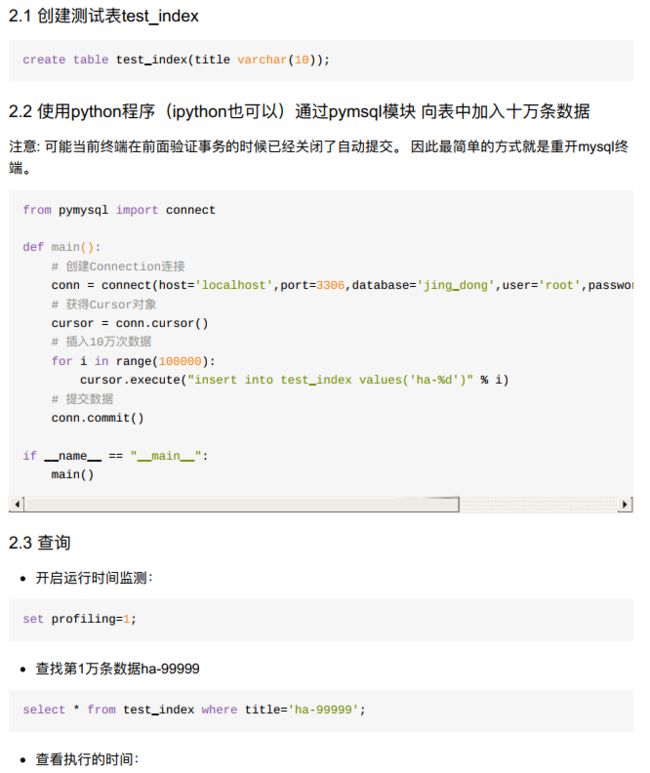

- 小结

11.2 用户管理
11.2.1 创建用户并授权
- 学习目标
- 能够使用grant创建一个用户并且授权;
-
1、MySQL账户管理

-
2、授权权限
- 需要使用实例级账号登录后操作,以root为例;
- 查看所有用户;
- 修改密码;
- 删除用户;
- 需要使用实例级账号登录后操作,以root为例;
-
3、查看所有用户
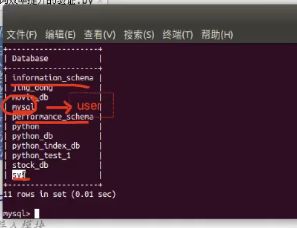

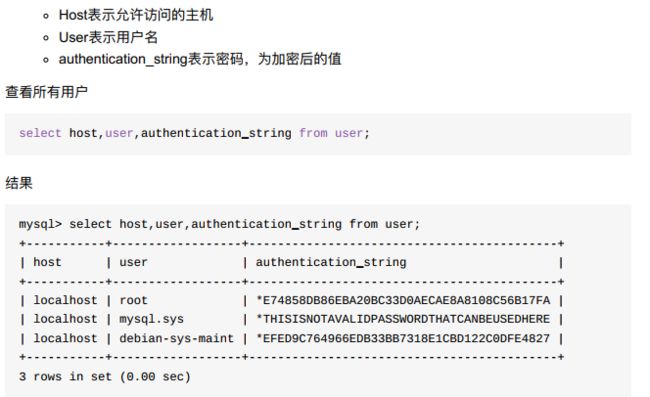
-
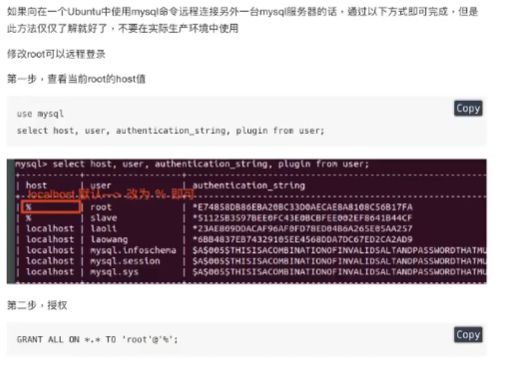
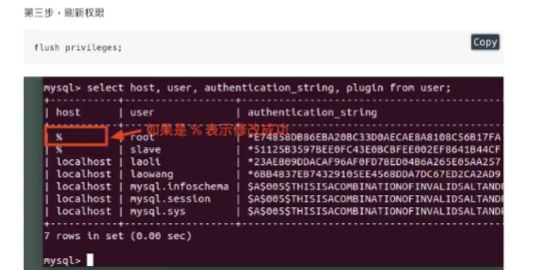
host如果为%。,表示可以使用本地或者任何IP地址登录数据库
authentication_string是存储用户密码的,加密之后的;
-
4、创建账户、授权
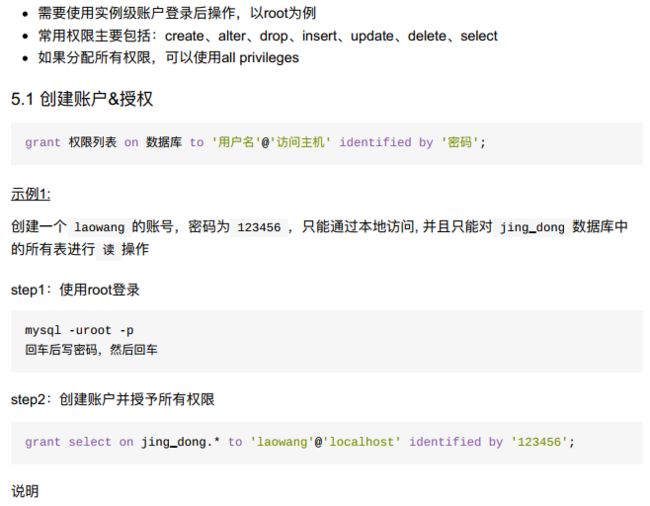
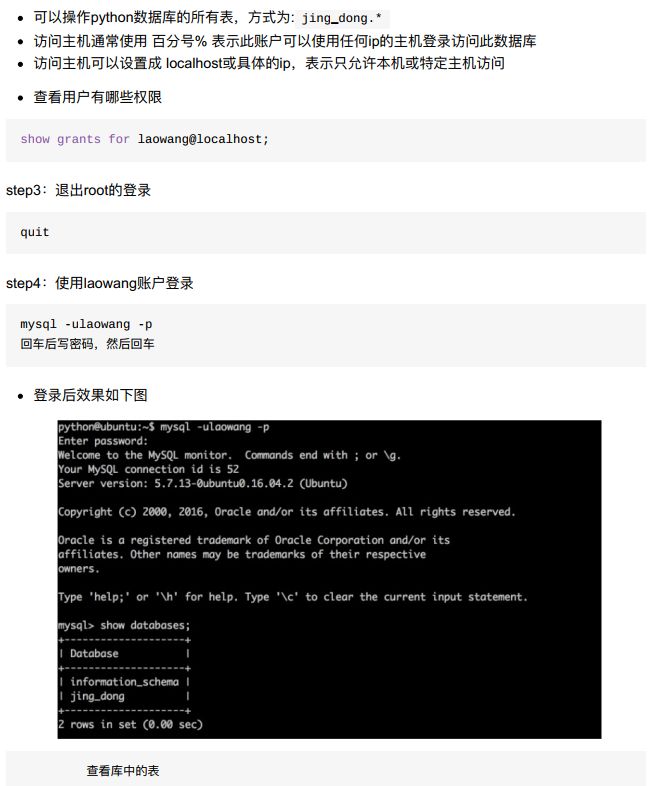
- 小结

11.2.2 账户管理
- 学习目标
- 修改一个用户的密码;
- 修改一个用户的权限;
-
2、修改权限



-
3、修改密码
- 使用root登录,修改mysql数据库的user表;
- 使用password()函数进行密码加密;

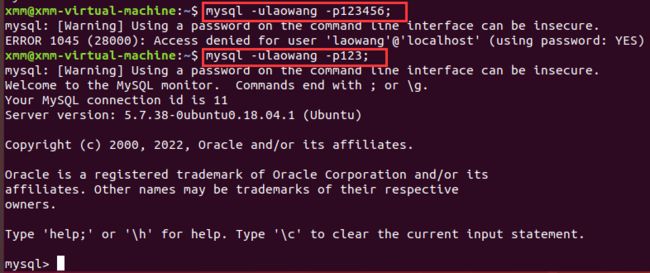
-
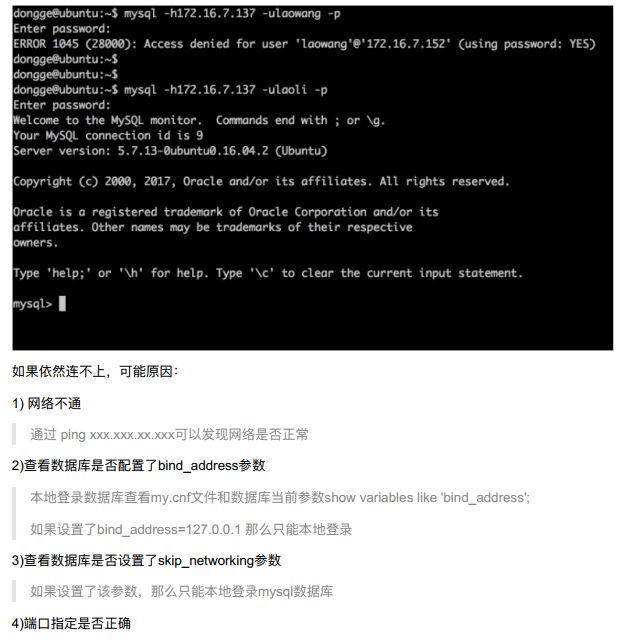
4、远程登录
-
5、删除账户
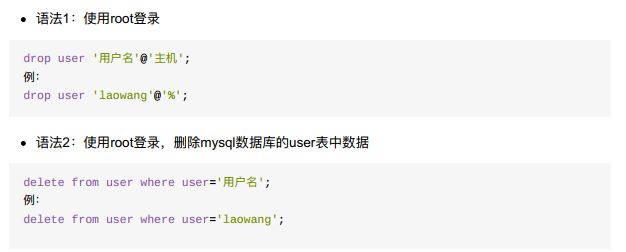

-
小结
![(img-AEcwNS4g-1654433062694)(https://raw.githubusercontent.com/caterpillar-0/picture/main/image-20220605153339643.png)]](http://img.e-com-net.com/image/info8/1278248f292c4be0a460ff454ccc330e.jpg)
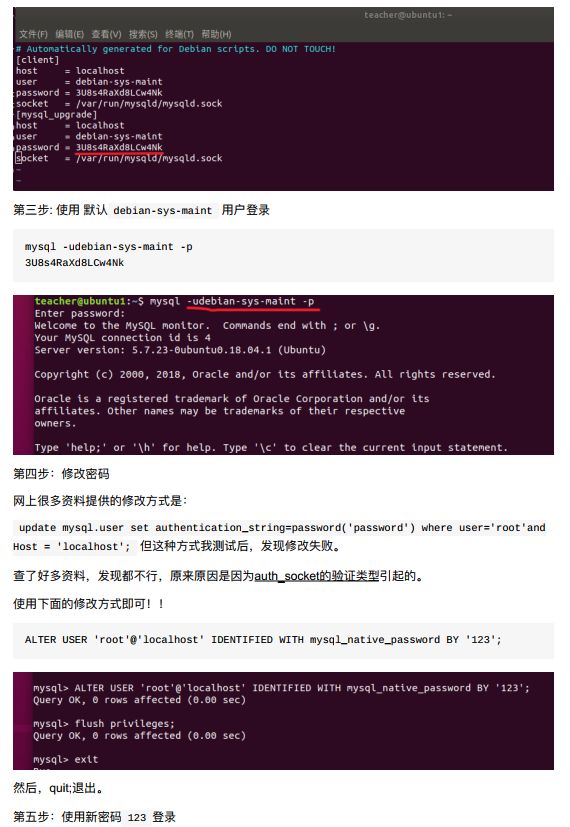
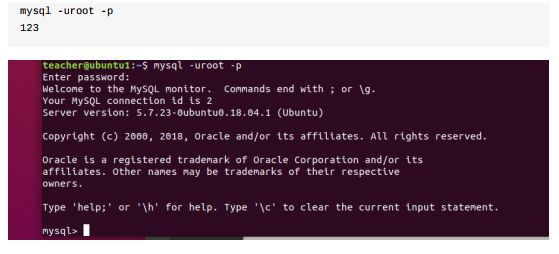
11.2.3 修改mysql默认密码

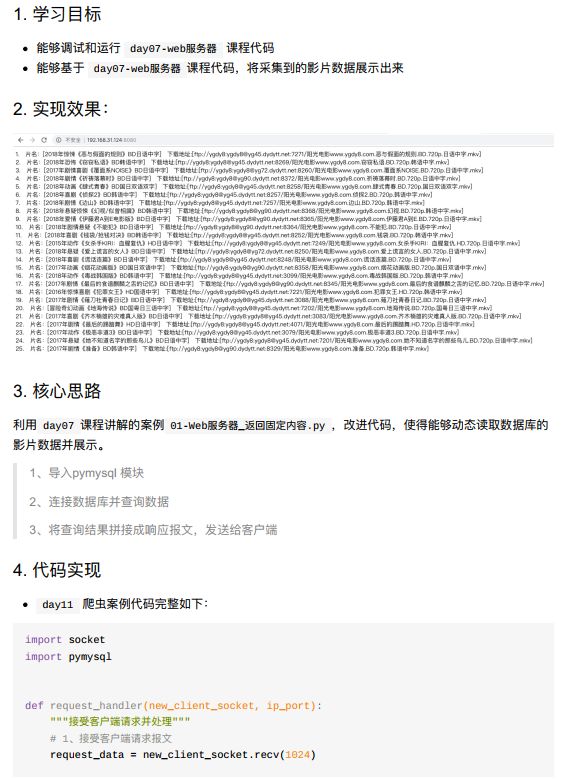
11.3 爬虫实战
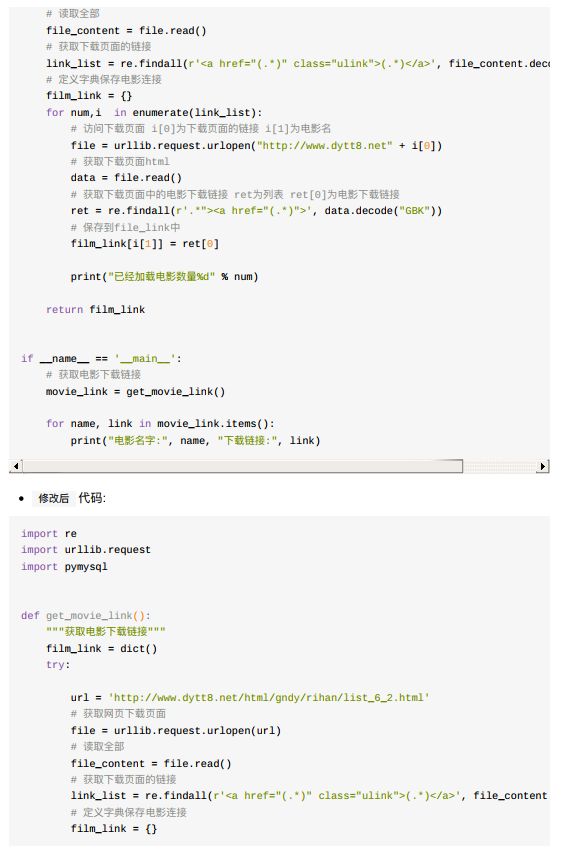
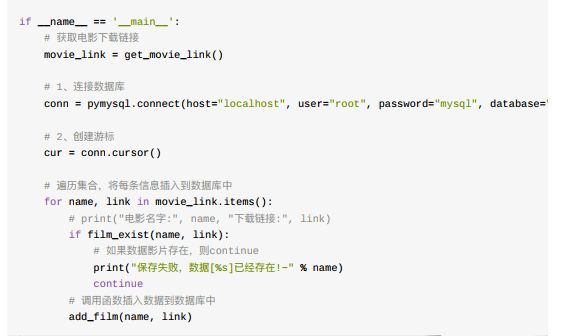
11.3.1 爬取数据并保存到数据库中
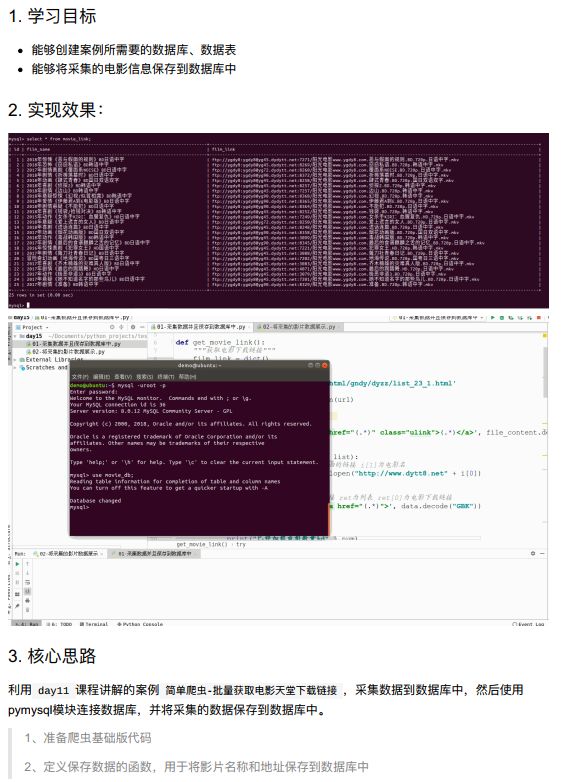


11.3.2 展示电影数据到网页上