利用mlxtend进行数据关联分析
guan
大数据挖掘最深入人心的一个故事应该是“啤酒与尿布”,这个规律就是用关联分析发现的。今天我们就来点关联分析,刚刚学到的,现学现分享?。下面假设是某超市的交易记录(我编造的)

基本概念
我们在关联分析之前先了解几个基本概念。
找出频繁一起出现的物品集的集合,我们称之为频繁项集。比如一个超市的频繁项集可能有{{啤酒,尿布},{鸡蛋,牛奶},{香蕉,苹果}}

mlxtend安装
mlxtend是python的机器学习扩展库,在数据科学中也会经常遇到。在本文主要是使用其中的关联分析一些方法
!pip3 install mlxtend编码
这块跟sklearn文本分析的contvertorizer和tfidfvectorizer差不多,都是从数据中学到 空间
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
#测试数据
records = [['牛奶', '洋葱', '猪肉', '鸡蛋', '洋葱', '酸奶'],
['洋葱', '豆角', '酸奶', '鸡蛋', '苹果'],
['牛奶', '苹果', '豆角', '鸡蛋'],
['牛奶', '玉米', '胡萝卜', '豆角', '酸奶'],
['玉米', '洋葱', '豆角', '冰激凌', '鸡蛋']]
Encoder = TransactionEncoder()
encoded_data = Encoder.fit_transform(records)
df = pd.DataFrame(encoded_data, columns=Encoder.columns_)
df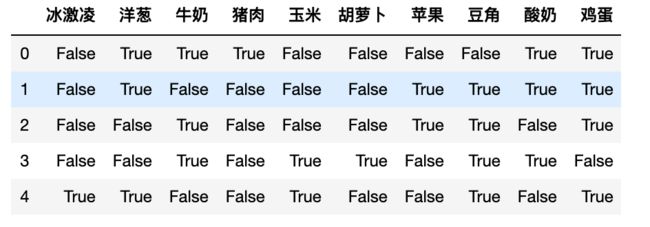
频繁项
找出频繁项,这里会用到 mlxtend.frequent_patterns 中的 apriori 函数
apriori(df, minsupport=0.5, usecolnames=False, max_len=None)
df:编码后的dataframe,如上图
min_support:给定的最小支持度
use_colnames:默认False,则返回的物品组会用编号显示,为True的话直接显示物品名称。
max_len=None:最大物品组合数,默认是None,不做限制。
我们设置minsupport=0.05, usecolnames=True, 需要计算最多四个物品组合的话,便将max_len这个值设置为4。
from mlxtend.frequent_patterns import apriori
frequent_items = apriori(df, min_support=0.05, use_colnames=True, max_len=4).sort_values(by='support', ascending=False)
frequent_items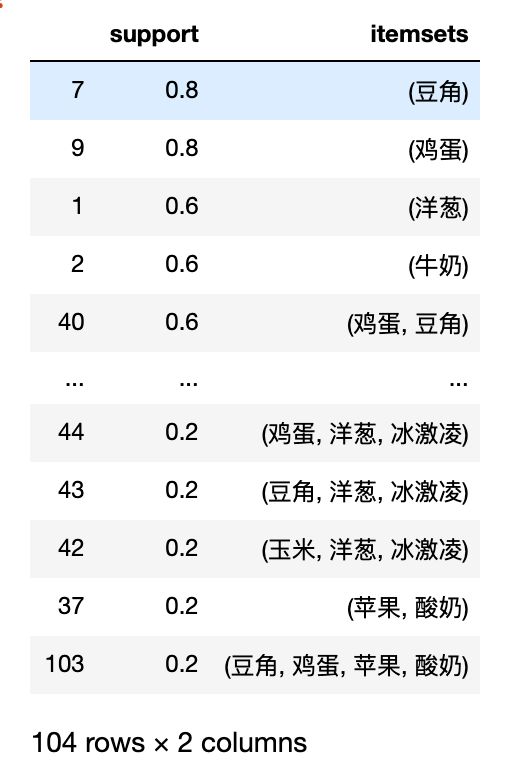
求关联规则
mlxtend.frequent_patterns里封装有关联规则函数 association_rules ,我们可以直接使用该函数帮助我们找到关联规则
associationrules(df, metric='confidence', minthreshold=0.8)
df: 频繁项dataframe
metric:默认是confidence
min_threshold:给选定的metric设定最低阈值
from mlxtend.frequent_patterns import association_rules
ass_rule = association_rules(frequent_items, metric='confidence', min_threshold=0.8)
ass_rule.sort_values(by='leverage', ascending=False, inplace=True)
ass_rule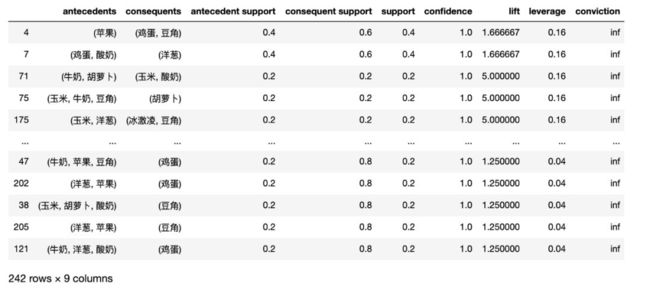
从上面看,买了苹果的人,会再买鸡蛋和豆角。可能这人爱吃苹果,主食会来来豆角炒鸡蛋?
编的数据,所以解读就当笑话吧~
近期文章
课件获取方式,请在公众号后台回复关键词“20191015”