一文看尽 6篇 CVPR2021 2D 异常检测论文
本文首发于极市平台,作者:刘冰一,转载须经授权并注明来源
6月25日,CVPR 2021 大会圆满结束,随着 CVPR 2021 最佳论文的出炉,本次大会所接收的论文也全部放出。CVPR2021 共接收了 7039 篇有效投稿,其中进入 Decision Making 阶段的共有约 5900 篇,最终有 1366 篇被接收为 poster,295 篇被接收为 oral,其中录用率大致为 23.6%,略高于去年的 22.1%。
CVPR 2021 全部接收论文列表:
https://openaccess.thecvf.com/CVPR2021?day=all
从 CVPR2021 公布结果开始,极市就一直对最新的 CVPR2021 进行分类汇总,共分为33个大类,包含检测、分割、估计、跟踪、医学影像、文本、人脸、图像视频检索、三维视觉、图像处理等多个方向。所有关于CVPR的论文整理都汇总在了我们的Github项目中,该项目目前已收获7200 Star。
Github项目地址(点击阅读原文即可跳转):
https://github.com/extreme-assistant/CVPR2021-Paper-Code-Interpretation
在之前极市平台曾对 CVPR 2021中 “2D目标检测” 领域的论文进行了盘点,今天我们继续盘点 CVPR 2021 检测大类中的 “异常检测领域” 领域的论文,将依次阐述每篇论文的方法思路和亮点。接下来还会继续进行其他领域的 CVPR2021 论文盘点。如有遗漏或错误,欢迎大家在评论区补充指正。
论文一
Anomaly Detection in Video via Self-Supervised and Multi-Task Learning
标题:通过自我监督和多任务学习进行视频异常检测
论文:https://arxiv.org/abs/2011.07491
视频中的异常检测是一个具有挑战性的计算机视觉问题。由于训练时缺乏异常事件,异常检测需要设计没有完全监督的学习方法。这篇论文主要是通过object-level的自监督多任务学习解决视频中的异常检测问题,是第一个在这个问题上提出使用多任务学习方法的工作。
本文通过对象级别的自监督和多任务学习来处理视频中的异常事件检测。首先利用预训练的检测器来检测物体。然后,训练一个 3D 卷积神经网络,通过联合学习多个代理任务来产生有区别的异常特定信息:三个自监督任务和一项消融研究。
自监督任务是:1.区分向前/向后移动的物体(时间箭头);2.连续/间歇帧中物体的区分(运动不规则);3.物体特定外观信息的重建。
方法
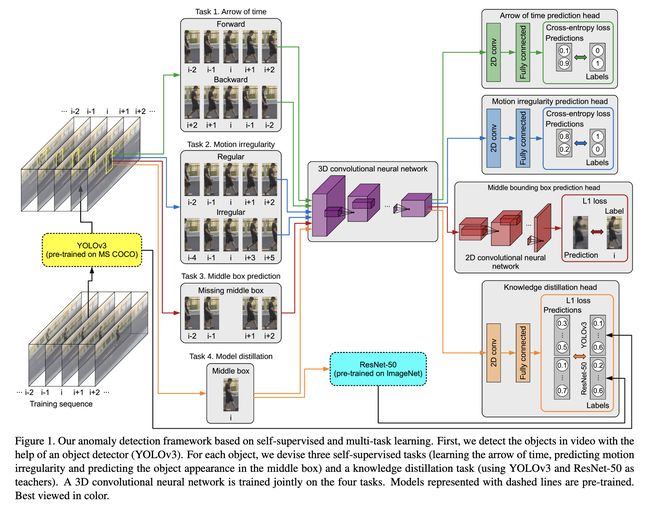
模型框架如图所示。首先,使用一个预训练的YOLOv3对每一帧的物体进行检测,得到一系列的bounding boxes。对每个帧i检测到的物体,生成一个物体为中心的时间序列 object-centric temporal sequence(具体操作是裁剪物体前后序列帧的bounding box对应范围,缩放到64x64的大小)。生成的时间序列作为3D CNN的输入,结构由一个共享的3D CNN和对应四个预测任务的四个分支组成。推断的时候,平均每个任务的分数得到最终的异常分数。
该文取得的成绩:
1.提出将学习 “the arrow of time”作为代理任务用于异常检测;
- 提出将运动不规则预测作为代理任务用于异常检测;
- 提出将模型蒸馏作为代理任务用于异常检测;
- 将视频的异常检测作为一个多任务学习的问题,整合了多种自监督的方法以及知识蒸馏的算法
- 通过实验证明了论文中提出的方法在三个benchmarks中都取得了很好的结果,是唯一一个在所有三个基准上都超过了 90% 的阈值。
论文二
MIST: Multiple Instance Self-Training Framework for Video Anomaly Detection
标题:MIST:用于视频异常检测的多实例自训练框架
论文:https://arxiv.org/abs/2104.01633
项目:https://kiwi-fung.win/2021/04/28/MIST
弱监督视频异常检测 (WS-VAD) 是基于判别式表示将异常与正常事件区分开来。作者发现现有方法没有充分考虑训练task-specific feature encoder来为事件提供可区分的表示。为克服这一难题,本文开发了一个多实例自训练框架 (MIST),以仅使用视频级注释有效地改进特定于任务的判别表示。
MIST 由两部分组成(1)多实例伪标签生成器,该生成器采用稀疏连续采样策略产生更可靠的clip-level伪标签;(2)self-attention feature encoder,该encoder目的是自动关注帧中的异常区域,同时提取特定的任务表示。作者采用自训练方案优化两个组件,最终获得任务特定的特征encoder。
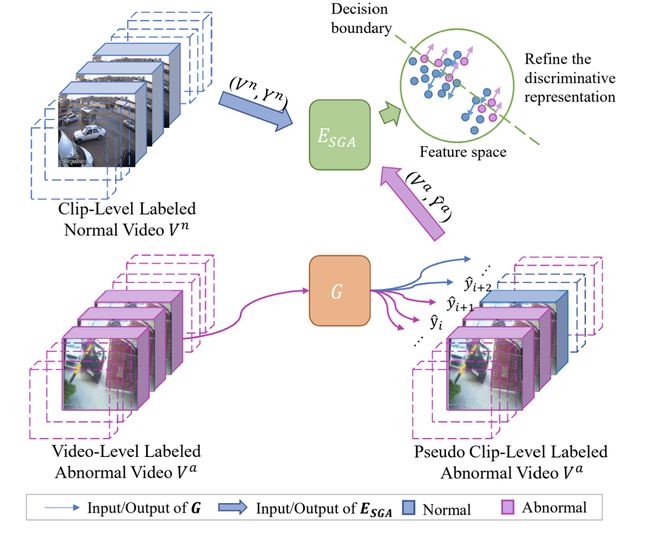
实验结果
- 作者在 UCF-Crime 和 ShanghaiTech 数据集上部署了大量实验,并在相同设置下优于其他方法。
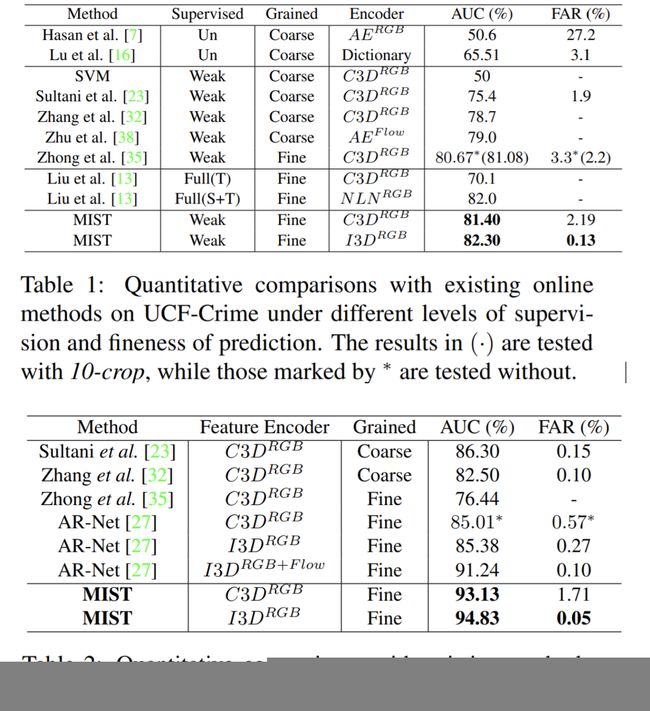
- 与之前基于编码器的方法 [Zhong .et al, CVPR 2019] 的比较如下,UCF-Crime明显优于 ShanghaiTech 的结果:UCF-Crime 测试结果的可视化更好地以彩色查看;并且UCF-Crime 上的更多空间异常激活图可视化。
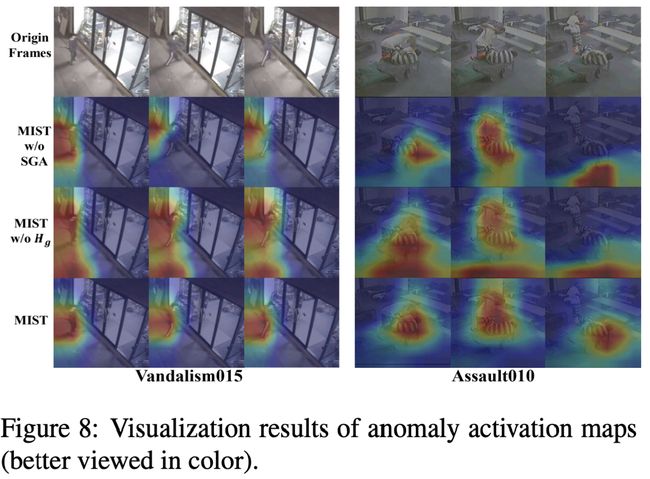
图注:UCF-Crime上的异常激活图。左边的 5 列是成功的结果,而右边的 2 列是失败的结果。
论文三
CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
题目:CutPaste:用于异常检测和定位的自我监督学习
论文:https://arxiv.org/abs/2104.04015
本文目标是构建一个用于缺陷检测的高性能模型,该模型在没有异常数据的情况下检测图像的未知异常模式。为此本文提出一个两阶段框架,用于仅使用正常训练数据构建异常检测器。
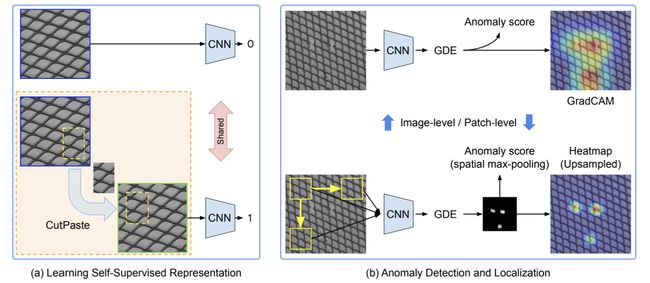
自监督学习中pretext task的思路分为两阶段(a)自监督学习表征阶段,对正样本采用cutpaste生成图像,训练一个二分类CNN,识别正常样本,及添加cutpaste后的图像。在(b)异常检测及定位阶段,CNN用来提取特征,高斯概率密度估计(GDE)使用CNN提取的特征计算异常分数,图像级别的异常检测可以使用GradCAM大致定位异常区域,patch级别的异常定位,对原图分割成若干patch,分别送到CNN–GDE计算异常分数,得出更细粒度异常热力图。
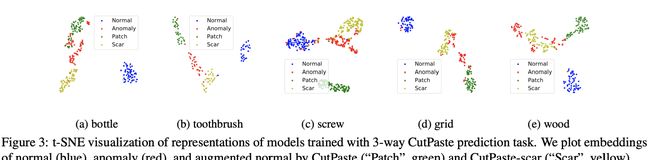
文章中使用的数据增强方法cutpaste和cutpaste(scar)试有cutout和scar启发而来,对于MVTec AD dataset,或者实际的缺陷检测任务,缺陷一般含有拉伸变形,特殊的纹理构造。作者对正常样本使用cutpaste的目的是希望在正常样本的表征学习中,能够通过cutpaste模拟异常样本,作者使用可视化技术发现,添加cutpaste后的正样本与原始正样本距离较大,但是与真实的异常样本接近度较小,说明仍需要更好的数据增强方法。
后经不同数据增强方法的消融实验,以及语义异常检测数据集上的实验之间进行对比和缺陷定位,作者对 MVTec 异常检测数据集的实证研究表明:
- 所提出的算法是通用的,能够检测各种类型的现实世界缺陷。当从头开始学习表示时,将以前的艺术改进了 3.1 AUC;
- 通过在 ImageNet 上对预训练表示进行迁移学习,本文实现了新的最先进的 96.6 AUC;
- 本文扩展了框架以从补丁中学习和提取表示,以允许在训练期间定位有缺陷的区域而无需注释。
论文四
Pixel-wise Anomaly Detection in Complex Driving Scenes
题目:复杂驾驶场景中的逐像素异常检测
论文:https://arxiv.org/pdf/2103.05445
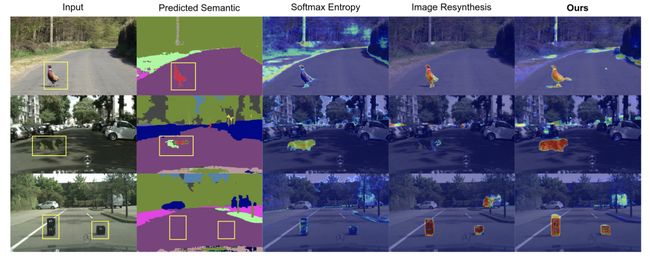
最先进的语义分割方法无法检测异常实例,这阻碍了它们被部署在安全关键和复杂的应用程序中,例如自动驾驶。最近的方法集中在利用分割不确定性来识别异常区域或从语义标签图中重新合成图像以找到与输入图像的不同之处。
本文研究了复杂驾驶场景(即城市景观)的像素级异常检测,提出一个像素级异常检测框架,该框架使用不确定性图来改进现有的再合成方法,以发现输入和生成图像之间的差异。在这项工作中,作者证明了这两种方法包含互补信息,可以结合起来为异常分割产生可靠的预测。
具体来说,此框架利用不确定性测量图(即 softmax 熵、softmax 距离和感知差异)来指导相异网络,以从预测的语义图中找到输入图像和生成图像之间的差异。
本文所做贡献:
- 设计了一个异常分割框架,它结合了两种互补的异常检测方法:不确定性和重新合成方法。
- 所提出的方法在 Fishyscapes 基准测试中,确保在不影响分割精度的情况下进行异常检测,一系列不同异常数据集的 Top-2 性能表明作者处理不同异常实例的方法的稳健性。是跨数据集的最佳整体方法。
- 该方法也适用于更轻的分割和合成网络,使其可以在自主机器中部署。
论文五
PANDA: Adapting Pretrained Features for Anomaly Detection and Segmentation
题目:PANDA:调整用于异常检测和分割的预训练特征
论文:http://arxiv.org/abs/2010.05903
代码:https://github.com/talreiss/PANDA
异常检测方法需要高质量的特征。近年来,异常检测社区试图利用深度自监督特征学习的进步来获得更好的特征。在本文中,我们首先凭经验建立了可能预期但未报告的结果,即将预先训练的特征与简单的异常检测和分割方法相结合,以期获得更优的先进方法。
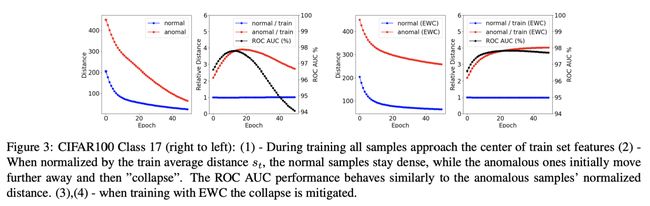
为了在异常检测中获得进一步的性能提升,作者使预训练的特征适应目标分布。尽管迁移学习方法在多类分类问题中已经很好地建立起来,但对一类分类 (OCC) 设置的探索还没有那么深入。通常在监督学习中效果很好的适应方法,通常会导致灾难性的崩溃(特征恶化)并降低 OCC 设置中的性能。目前一种流行的 OCC 方法 DeepSVDD 提倡使用专门的架构,但这限制了自适应性能的提升。
针对困境,文中提出了两种对抗崩溃的方法:
- 提出一种适应预训练特征和减少灾难性崩塌的方法,对强基线进行了进一步的改进。这种动态学习停止迭代的变体显着优于现有的方法,同时解决了它们的局限性;
- 受持续学习启发的弹性正则化。本文的 PANDA 方法在 OCC、异常值曝光和异常分割设置方面的表现明显优于最先进的方法。
这项工作的主要限制是需要强大的预训练特征提取器。许多工作已经完成了可转移的图像和文本特征,目前的提取器可能是有效的,以获得特征的时间序列和音频数据以及。通用特征提取器目前还不能用于表格数据,它们的开发是未来工作的一个令人兴奋的方向。
论文六
Multiresolution Knowledge Distillation for Anomaly Detection
题目:用于异常检测的多分辨率知识蒸馏
论文: https://arxiv.org/pdf/2011.11108
代码:https://github.com/Niousha12/Knowledge_Distillation_AD
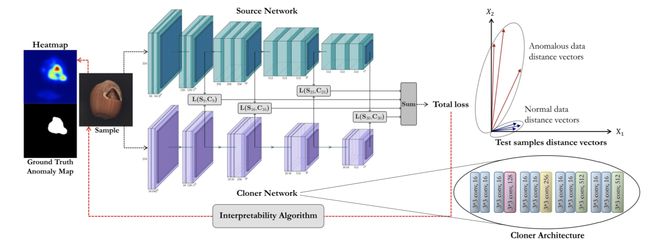
无监督表示学习已被证明是图像异常检测/定位的关键组成部分。学习这种表示的挑战是双重的。首先,样本量通常不够大,无法通过传统技术学习丰富的可概括表示。其次,虽然训练时只有正常样本可用,但学习到的特征应该区分正常和异常样本。
基于此,文中建议在 ImageNet 上预先训练的专家网络的各个层使用特征的“蒸馏”,将其转换为更简单的克隆网络来解决这两个问题。使用给定输入数据的专家和克隆网络中间激活值之间的差异来检测和定位异常。
总结
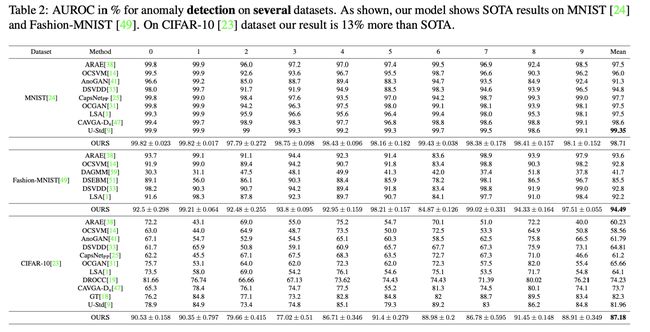
本文将 ImageNet 预训练的无异常数据专家网络的中间知识“提取”成一个更紧凑的克隆网络,然后利用它们对不同样本的不同行为,为寻找异常检测和定位的区别性标准提供了一个新的方向。
没有使用密集的基于区域的培训和测试,将可解释性算法纳入文中用于异常区域定位的新框架中。尽管一些测试数据集和 ImageNet 之间存在显着对比,但与 MNIST、F-MNIST、CIFAR-10、MVTecAD、Retinal-OCT 和两个医学数据集上的异常检测和定位的 SOTA 方法相比具有明显的竞争力,甚至远超 ImageNet 领域取得的成果。