【时间序列异常检测】Anomaly-Transformer
论文链接:https://arxiv.org/pdf/2110.02642.pdf
来自 ICLR 2022
Anomaly-Transformer:基于关联差异(Association Discrepancy)的时间序列异常检测方法
摘要
时间序列异常点的无监督检测是一个具有挑战性的问题,需要模型推导出一个可区分的判据。以往的方法主要通过学习点表示或成对关联来解决这个问题,但这两种方法都不足以对复杂的动力学进行推理。近年来,Transformers 在点向表示和成对关联的统一建模方面表现出了强大的能力,我们发现每个时间点的 self-attention 权重分布可以体现出与整个序列的丰富关联。我们的重点观察是,由于异常非常罕见,很难建立从异常点到整个序列的有用的关联,因此异常关联主要集中在其相邻时间点上。这种 adjacent-concentration bias 固有的蕴含了一种基于关联的标准,可以区分正常点和异常点,我们通过Association Discrepancy强调了这一点。技术上,我们提出了一种基于新的Anomaly-Attention 机制的 Anomaly Transformer 来计算关联差异(association discrepancy)。设计了一种极大极小(minimax)策略来放大 关联差异的 normal-abnormal 可分。该Anomaly Transformer 在三种应用的六种无监督时间序列异常检测基准上取得了最先进的结果:服务监测、空间&地球勘探和水处理。
5 总结和展望
本文研究了无监督时间序列异常检测问题。与以前的方法不同,我们通过 Transformers 学习到更多信息的时间点关联。在关联差异观测的基础上,我们提出了Anomaly Transformer,包括一个带有两个分支结构的Anomaly Attention来体现关联差异。采用极大极小(minimax)策略进一步放大正常和异常时间点的差异。通过引入关联差异,提出了基于关联的准则,使重构性能与关联差异协同。Anomaly Transformer在一系列详尽的实证研究中取得了最先进的结果。
未来的工作包括参照经典的自回归分析和状态空间模型对Anomoly Transformer进行理论研究。
3. 方法
假设监测一个 d个测量值 的连续系统,并记录一段时间内等间隔的观测结果。观测到的时间序列X表示为一组时间点![]() ,其中
,其中![]() 表示时间 t 的观测值。无监督时间序列异常检测问题是在没有标签的情况下判断
表示时间 t 的观测值。无监督时间序列异常检测问题是在没有标签的情况下判断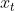 是否异常。
是否异常。
这里的意思是:每个时间点观测 d 个值,假设时间点有N长。
如前所述,我们强调了无监督时间序列异常检测的关键是学习信息表示和找到可区分的标准。我们提出了 Anomaly Transformer 来发现更多的信息关联,并通过学习关联差异( Association Discrepancy) 来解决这个问题,Association Discrepancy 本质上是 normal-abnormal 可分的。技术上,我们提出了Anomaly-Attention 来体现先验关联和序列关联,以及一个极小极大优化策略来获得更容易区分的关联差异。与该架构共同设计,我们根据学习到的关联差异得出了一个基于关联的准则。
3.1 Anomaly Transformer
考虑到 Transformers (Vaswani et al.,2017)在异常检测方面的局限性,我们使用Anomaly-Attention 机制将普通架构更新为Anomaly Transformer (图1)。
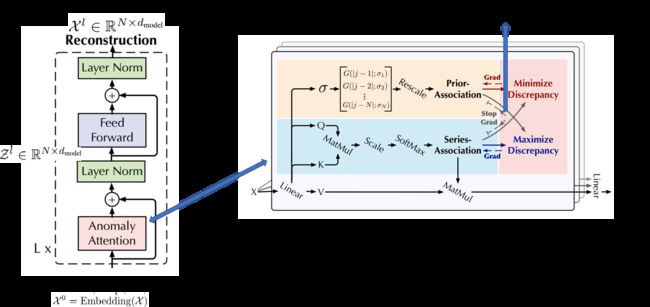
图1:Anomaly Transformer架构。Anomaly-Attention (右)同时建模了先验关联(prior-association)和序列关联(series-association)。除了重建损失,我们的模型还通过minimax策略进行优化,该策略带有一个特殊设计的停止梯度机制(灰色箭头),以约束先验关联和序列关联,以获得更可区分的关联差异。
Overall Architecture
Anomaly Transformer 的特点是将 Anomaly-Attention blocks 与 feed-forward layers 交替叠加。这种堆叠结构有利于从深度多层特征中学习潜在关联。假设length-N 的输入时间序列为 ![]() ,模型包含L层,length-N 的 输入时间序列
,模型包含L层,length-N 的 输入时间序列 ![]() ,则第 L层的整体方程为:
,则第 L层的整体方程为:
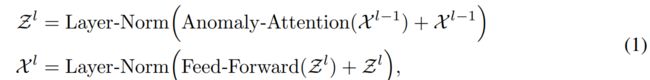
这里 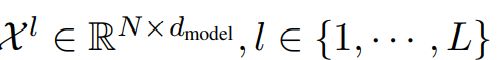 表示 有
表示 有  通道的第 L 曾的输出。
通道的第 L 曾的输出。
初始输入 ![]() 表示原始序列的 embed。
表示原始序列的 embed。![]() 表示 第L层的隐藏表示。Anomaly-Attention(·) 是用来计算 关联差异( Association Discrepancy)。
表示 第L层的隐藏表示。Anomaly-Attention(·) 是用来计算 关联差异( Association Discrepancy)。
Anomaly-Attention
需要注意的是,单分支(single-branch)的self-attention 机制(Vaswani et al.,2017)不能同时建模 prior-association和 series-association。我们提出了一个带有两个分支结构的AnomalyAttention(图1)。对于prior-association ,我们采用一个可学习的高斯核来计算相对时间距离的先验。得益于高斯核的单峰性质,该设计可以从本质上更多地关注相邻视界。在高斯核函数中,我们还使用了可学习的尺度参数 σ,使先验关联适应于不同的时间序列模式,如不同长度的异常段。series-association 分支是从原始序列中学习关联,它能自适应地找到最有效的关联。请注意,这两种形式维护了每个时间点的时间依赖性,这比 point-wise表示的信息更丰富。它们也分别反映了adjacent-concentration 先验和学习到的真实关联,其差异应是 normal-abnormal 可区分的。第L 层的 Anomaly-Attention 是:
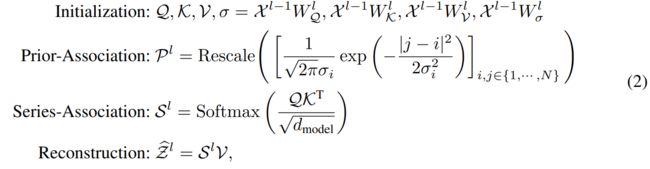
 分别 表示 self-attention 的query, key, value 和 可学习的 scale。
分别 表示 self-attention 的query, key, value 和 可学习的 scale。![]() 分别表示在第L层中 Q, K, V, σ 的参数矩阵。
分别表示在第L层中 Q, K, V, σ 的参数矩阵。
Prior-association 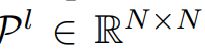 是根据学习 的 scale
是根据学习 的 scale ![]() 生成的,第 i 个元素
生成的,第 i 个元素 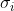 对应第 i个时间点。
对应第 i个时间点。
具体而言,对于第i个时间点,利用高斯核函数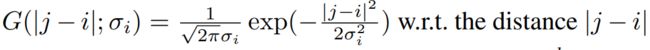 计算到第 j 个点的 association weight。进一步,我们使用Rescale(·)通过除行和( the row sum )将 association weight 转换为离散分布
计算到第 j 个点的 association weight。进一步,我们使用Rescale(·)通过除行和( the row sum )将 association weight 转换为离散分布![]() 。
。![]() 表示 series-associations 。Softmax(·) 沿着最后一个维度 normalizes the attention map。
表示 series-associations 。Softmax(·) 沿着最后一个维度 normalizes the attention map。
因此,![]() 的每一行 构成一个离散分布。
的每一行 构成一个离散分布。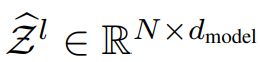 为第L 层 Anomaly-Attention 后的隐藏表示。我们用 Anomaly-Attention(·) 总结公式2。
为第L 层 Anomaly-Attention 后的隐藏表示。我们用 Anomaly-Attention(·) 总结公式2。
在我们使用的 multi-head 版本中,对于 h heads 的可学习 scale 是![]() 。
。![]()
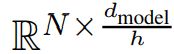 分别表示 第m个head 的query, key 和 value。该模块将多个heads的输出
分别表示 第m个head 的query, key 和 value。该模块将多个heads的输出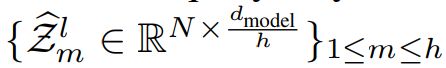 concatenates起来,得到最终结果
concatenates起来,得到最终结果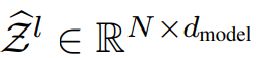 。
。
Association Discrepancy关联差异
我们将Association Discrepancy 形式化为 prior- and series- associations之间的 对称KL散度(the symmetrized KL divergence),它代表了这两个分布之间的信息增益(Neal, 2007)。 我们平均来自多层的association discrepancy ,将来自多层特征的关联组合成一个信息更丰富的measure 为:
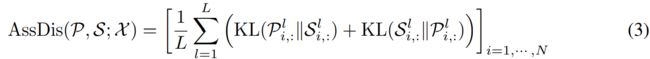
这里  是对应于每一行
是对应于每一行![]() 和
和![]() 的两个离散分布之间计算的KL散度。
的两个离散分布之间计算的KL散度。![]() 是关于来自多层的 prior-association P 和 series-association S的X的 point-wise association discrepancy。results 的第i个元素对应于X的第i个时间点。从以前的观测来看,异常会出现较小的
是关于来自多层的 prior-association P 和 series-association S的X的 point-wise association discrepancy。results 的第i个元素对应于X的第i个时间点。从以前的观测来看,异常会出现较小的![]() 比正常时间点,这使得AssDis具有内在的可区分性。
比正常时间点,这使得AssDis具有内在的可区分性。
3.2 极小极大关联学习 MINIMAX ASSOCIATION LEARNING
作为一种无监督任务,我们利用重建损失来优化我们的模型。重建损失将引导 series-association找到最有信息的关联。为了进一步放大正常和异常时间点的差异,我们还使用了一个额外的损失来放大关联差异。由于先验关联(prior-association)的单峰性,差异损失将引导序列关联(series-association)更多地关注非相邻区域,这使得异常的重建更加困难,也使异常更加容易识别。输入序列 ![]() 的损失函数形式化为:
的损失函数形式化为:![]()
这里 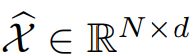 表示X的重建。
表示X的重建。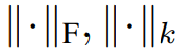 表示Frobenius和k-norm。λ是对loss 项进行权衡。当λ > 0,优化是放大关联差异。提出了一种极大极小策略,使关联差异更易于识别。
表示Frobenius和k-norm。λ是对loss 项进行权衡。当λ > 0,优化是放大关联差异。提出了一种极大极小策略,使关联差异更易于识别。
Minimax Strategy
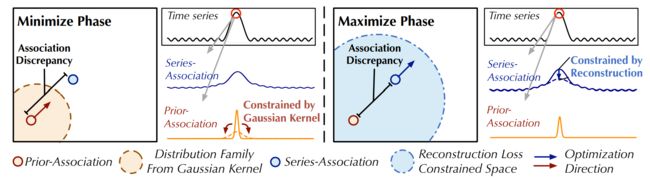
图2:极大极小关联学习。在最小阶段,prior-association 使高斯核函数得到的分布族内的Association Discrepancy 最小。在最大化阶段,series-association 在重构损失下使 Association Discrepancy最大化。
需要注意的是,直接将关联差异最大化会极大地减小高斯核的尺度参数(Neal, 2007),使得之前的关联毫无意义。为了更好地控制关联学习,我们提出了一个极大极小策略(图2)。具体地说,在最小化阶段,我们驱动prior-association ![]() 来近似从原始序列学习到的 series-association
来近似从原始序列学习到的 series-association ![]() 。这一过程将使 prior-association 适应不同的时间模式。在最大化阶段,我们对 series-association 进行优化,扩大关联差异。这个过程迫使 series-association更加关注非相邻的视界。因此,整合重建损失,两阶段的损失函数为:
。这一过程将使 prior-association 适应不同的时间模式。在最大化阶段,我们对 series-association 进行优化,扩大关联差异。这个过程迫使 series-association更加关注非相邻的视界。因此,整合重建损失,两阶段的损失函数为:
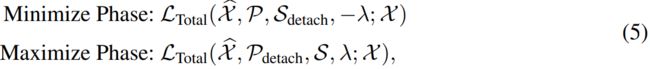
这里λ > 0 和 ∗detach 表示停止关联的梯度反向传播(图1)。 由于 P 在最小化阶段近似于![]() ,最大化阶段会对 series-association 进行更强的约束,迫使时间点更多地关注非相邻区域。在重构损失的情况下,异常比正常时间点更难实现这一点,从而放大了关联差异的normal-abnormal 可分辨性。
,最大化阶段会对 series-association 进行更强的约束,迫使时间点更多地关注非相邻区域。在重构损失的情况下,异常比正常时间点更难实现这一点,从而放大了关联差异的normal-abnormal 可分辨性。
Association-based Anomaly Criterion
我们将normalized association discrepancy 引入到重构准则中,既利用了时间表征的优点,又利用了可区分的association discrepancy。![]() 的最终异常 score 如下图所示:
的最终异常 score 如下图所示:
![]() 这里
这里  是 element-wise 乘法。
是 element-wise 乘法。![]() 表示 point-wise 异常判据。为了更好的重建,异常通常会减少association discrepancy,这仍然会得到更高的异常评分。因此,该设计可以使重构误差与关联误差协同作用,提高检测性能。
表示 point-wise 异常判据。为了更好的重建,异常通常会减少association discrepancy,这仍然会得到更高的异常评分。因此,该设计可以使重构误差与关联误差协同作用,提高检测性能。
1. 引言
真实世界的系统总是以连续的方式工作,可以产生由 多个传感器监测的多个连续的测量,如工业设备、空间探测器等。从大规模系统监控数据中发现故障,可以简化为 从时间序列中发现异常时间点,这对保证安全、避免经济损失具有重要意义。但异常通常很罕见,并被大量正常点所隐藏,这使得数据标注困难且昂贵。因此,我们专注于无监督设置下的时间序列异常检测。
无监督时间序列异常检测在实践中具有极大的挑战性。模型应该通过无监督任务学习来自复杂时间动态的信息表示。尽管如此,它也应该得出一个可区分的标准,可以从大量正常时间点检测出罕见的异常。各种经典的异常检测方法提供了许多无监督的范例,例如在局部异常因子中提出的密度估计方法(LOF, Breunig等人(2000)),在 one-class SVM 中提出的基于聚类的方法(OC-SVM, Scholkopf等人(2001))和SVDD (Tax &Duin, 2004)。这些经典方法不考虑时间信息,难以推广到不可见的真实场景。得益于神经网络的表示学习能力,最近的深度模型(Su等人,2019;Shen等,2020;Li等人,2021年)取得了卓越的业绩。一类主要的方法专注于通过设计良好的 recurrent 网络学习 pointwise 表示,并由重建或自回归任务进行自监督。这里,一个自然而实用的异常判据是 pointwise 重构或预测误差。然而,由于异常的罕见性,对于复杂的时间模式,pointwise 表示的信息量较少,并且pointwise 表示 由正常时间点主导,这使得异常难以区分。此外,重建或预测误差是逐点计算的,不能提供对时间上下文的全面描述。
另一类主要方法是基于显式关联建模来检测异常。向量自回归模型和状态空间模型就属于这一类。通过将不同时间点的时间序列表示为顶点,并通过随机游走检测异常,图还用于显式捕捉关联(Cheng等人,2008;2009)。通常,这些经典方法很难学习信息表示和建模细粒度的关联。近年来,图神经网络(GNN)被用于学习多元时间序列中多个变量之间的动态图(Zhao et al., 2020;邓,Hooi, 2021)。虽然具有更强的表达能力,但被学习的图仍然局限于单个时间点,这对于复杂的时间模式来说是不够的。此外,基于子序列的方法通过计算子序列之间的相似性来检测异常(Boniol &Palpanas, 2020)。在探索更广泛的时间上下文时,这些方法不能捕获每个时间点与整个序列之间的细粒度时间关联。
在本文中,我们将Transformers(Vaswani et al., 2017)应用于无监督状态下的时间序列异常检测。Transformers 在各个领域都取得了很大的进展,包括自然语言处理(Brown et al., 2020)、机器视觉(Liu et al., 2021)和时间序列(Zhou et al., 2021)。这归功于其在 global 表征和长期关系的统一建模方面的强大能力。将 Transformers 应用于时间序列,我们发现每个时间点的时间关联可以从 self-attention 图中获得,self-attention 图 表现为对于所有时间点的关联 weights 沿时间维度的分布。每个时间点的关联分布可以为时间上下文提供更有信息的描述,表明时间序列的周期或趋势等动态模式。我们将上面的关联分布命名为 series-association,它可以被Transformers 从原始系列中发现。
此外,我们还观察到,由于异常的罕见性和正常模式的支配地位,异常很难与整个序列建立强大的关联。异常的关联应集中在相邻的时间点上,由于连续性,这些时间点更有可能包含相似的异常模式。这种 邻接归纳的偏差(an adjacent-concentration inductive bias)被称为先验关联(prior-association)。相反,占主导地位的正常时间点可以发现与整个序列的信息关联,而不局限于邻近区域。在此基础上,我们试图利用关联分布固有的normal-abnormal 可分性。这就产生了一种新的异常判据,用每个时间点的 prior-association 与其 series-association 之间的距离来量化,称为关联差异。如前所述,由于异常的关联更有可能是相邻集中的,异常会比正常时间点呈现更小的关联差异。
超越以往的方法,我们将 Transformers 引入到无监督时间序列异常检测中,并提出了用于关联学习的Anomaly Transformer。为了计算关联差异,我们将 self-attention 机制更新为 Anomaly-Attention 机制,该机制包含两个分支结构,分别对每个时间点的 prior-association 和 series-association进行建模。prior-association 采用可学习的高斯核表示每个时间点的 adjacent-concentration inductive bias,prior-association 对应从原始序列学习到的self-attention weights。此外,在两个分支之间应用极大极小(minimax)策略,放大了关联差异的 normal-abnormal 可分性,并进一步推导出一种新的基于关联的准则。Anomaly Transformer在6个基准测试中取得了出色的结果,涵盖了3个真正的应用。其贡献总结如下:
- 在 Association Discrepancy 关键观测数据的基础上,提出了一种基于 Anomaly-Attention 机制的Anomaly Transformer,该Anomaly Transformer 可以同时对prior-association和 series-association 进行建模,从而体现关联差异。
- 我们提出一种极大极小策略来放大关联差异的 normal-abnormal 可分性,并进一步推导出一种新的基于关联的检测准则。
- 在3个实际应用中,Anomaly Transformer在6个基准测试中获得了最先进的异常检测结果。给出了广泛的消融和深刻的案例研究。
2. 相关工作
2.1无监督时间序列异常检测
无监督时间序列异常检测作为一个重要的现实问题,已经得到了广泛的研究。根据异常判定准则进行分类,大致分为 密度估计方法、基于聚类的方法、基于重建的方法和基于自回归的方法。
对于密度估计方法,经典方法 局部离群因子(LOF, Breunig et al.(2000))和连通性离群因子(COF, Tang et al.(2002))分别计算局部密度和局部连通性来确定离群值。DAGMM (Zong et al., 2018)和MPPCACD (Yairi et al., 2017)集成高斯混合模型来估计表示的密度。
在基于聚类的方法中,通常将异常分数公式化为到聚类中心的距离。SVDD(税收,Duin, 2004)和Deep SVDD (Ruff等人,2018) 将正常数据的表示收集到一个紧凑的 cluster 中。THOC (Shen et al., 2020)通过 分层聚类机制融合中间层的多尺度时间特征,并通过多层距离检测异常。ITAD (Shin et al.,2020)对分解的张量进行聚类。
基于重构的模型试图通过重构错误来检测异常。Park等人(2018)提出了LSTM-VAE模型,该模型使用LSTM backbone 进行时间建模,并使用变分自编码器(VAE)进行重建。由Su等人(2019)提出的OmniAnomaly用一个归一化流(normalizing flow) 进一步扩展了LSTM-VAE模型,并使用重构概率进行检测。Li等人(2021)的InterFusion将backbone 更新为分层的VAE,以同时模拟多个序列之间的相互依赖和内部(inter- and intra-)依赖。GANs (Goodfellow等人,2014)也用于基于重建的异常检测(Schlegl等人,2019;Li等人,2019a;Zhou等人,2019)并作为对抗性正则化进行。
基于自回归的模型通过预测误差来检测异常。VAR扩展了ARIMA (Anderson & Kendall, 1976),并基于滞后依赖协方差(lag-dependent covariance)对未来进行预测。自回归模型也可以用 LSTMs代替(Hundman et al., 2018;Tariq等人,2019年)。
本文提出了一种新的基于关联的准则。不同于随机游走和基于子序列的方法(Cheng et al., 2008;Boniol,Palpanas, 2020),我们的准则体现在一个共同设计的时间模型,以学习更多的信息量大的 time-point 关联。
2.2 Transformers时间序列分析
最近,Transformers (Vaswani et al., 2017)在序列数据处理中显示出了巨大的能力,如自然语言处理(Devlin et al., 2019;Brown等人,2020年)、音频处理(Huang等人,2019年)和计算机视觉(Dosovitskiy等人,2021年;Liu等人,2021年)。对于时间序列分析,得益于 self-attention 机制的优势,Transformers 被用于发现可靠的长期时间依赖性(Kitaev等人,2020;Li等人,2019b;Zhou等,2021;Wu等人,2021年)。特别是对于时间序列异常检测,Chen等人(2021)提出的GTA采用图结构来学习多个物联网传感器之间的关系,以及用于时间建模的Transformer和异常检测的重构准则。与以往的 Transformers 不同,Anomaly Transformer 基于关联差异的关键观测,将 self-attention 机制更新为 Anomaly-Attention 机制。
参考资料:
Anomaly Transformer: Time Series Anomaly Detection with Association Discrepancy
ICLR 2022分享会-吴海旭-基于关联差异的时序异常检测算法_哔哩哔哩_bilibili
https://wuhaixu2016.github.io/pdf/ICLR2022_Anomaly.pdf