使用基于Web的交互式开发工具Zeppelin
使用基于Web的交互式开发工具Zeppelin
- 1. 实验室名称:
- 2. 实验项目名称:
- 3. 实验学时:
- 4. 实验原理:
- 5. 实验目的:
- 6. 实验内容:
- 7. 实验器材(设备、虚拟机名称):
- 8. 实验步骤:
-
- 8.1 安装和配置zeppelin
- 8.2 启动zeppelin服务
- 8.3 创建notebook文件
- 8.4 执行Spark交互式操作
- 8.5 关闭zeppelin服务
- 9. 实验结果及分析:
- 10. 实验结论:
- 11. 总结及心得体会:
原创申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计3176字,阅读大概需要3分钟
欢迎关注我的个人公众号:不懂开发的程序猿
1. 实验室名称:
大数据实验教学系统
2. 实验项目名称:
使用基于Web的交互式开发工具Zeppelin
3. 实验学时:
4. 实验原理:
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。当前已经实现的Interpreter有spark解释器、python解释器、Spark SQL解释器、JDBC解释器、Markdown解释器和shell解释器等。
5. 实验目的:
掌握zeppelin的安装和配置。
掌握在zeppelin中配置和使用Spark解释器。
掌握在zeppelin中创建notebook文件和执行Spark交互式操作。
6. 实验内容:
1、安装zeppelin。
2、在zeppelin中配置Spark解释器。
3、在zeppelin中创建和notebook文件。
4、在zeppelin中执行Spark交互式操作。
7. 实验器材(设备、虚拟机名称):
硬件:x86_64 ubuntu 16.04服务器
软件:JDK1.8,Spark-2.3.2,zeppelin 0.8.1
在本实验环境中,zeppelin安装包位于:/data/software/zeppelin-0.8.1-bin-all.tgz
8. 实验步骤:
8.1 安装和配置zeppelin
1、将zeppelin安装包解压缩到”/data/bigdata/“目录下,并重命名为zeppelin。打开一个终端窗口,执行如下命令:
1. $ cd /data/bigdata
2. $ tar xvf /data/software/zeppelin-0.8.1-bin-all.tgz
3. $ mv zeppelin-0.8.1-bin-all zeppelin
2、打开conf/zeppelin-env.sh文件(默认没有,从模板复制一份)。在终端窗口中,执行如下命令:
1. $ cd /data/bigdata/zeppelin/conf
2. $ cp zeppelin-env.sh.template zeppelin-env.sh
3. $ vim zeppelin-env.sh
在打开的文件最后添加如下两行内容:
1. export JAVA_HOME=/opt/jdk
2. export SPARK_HOME=/opt/spark
4. 打开zeppelin-site.xml文件(默认没有,从模板复制一份)。在终端窗口中,执行如下命令:
1. $ cd /data/bigdata/zeppelin/conf
2. $ cp zeppelin-site.xml.template zeppelin-site.xml
3. $ vim zeppelin-site.xml
在打开的文件中,修改如下两个属性,设置新的端口号,以避免冲突:
1. <property>
2. <name>zeppelin.server.port</name>
3. <value>9090</value>
4. <description>Server port.</description>
5. </property>
6.
7. <property>
8. <name>zeppelin.server.ssl.port</name>
9. <value>9443</value>
10. <description>Server ssl port. (used when ssl property is set to true)</description>
11. </property>
5. 配置zeppelin的系统环境变量。使用如下命令打开”/etc/profile”文件:
1. $ vim /etc/profile
在打开的配置文件中,添加(或修改,如果已经配置了的话)如下两行内容:
1. export ZEPPELIN_HOME=/data/bigdata/zeppelin
2. export PATH=$PATH:$ZEPPELIN_HOME/bin
然后保存文件并退出。执行以下命令,让配置生效:
1. $ source /etc/profile
8.2 启动zeppelin服务
在终端窗口中,执行以下命令,启动zeppelin服务:
1. $ zeppelin-daemon.sh start
执行过程如下图所示:

8.3 创建notebook文件
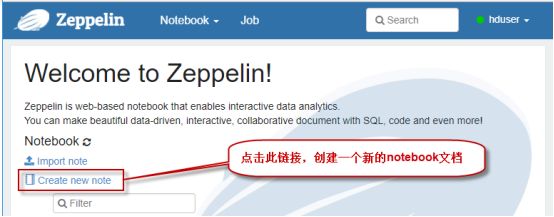
1、首先启动浏览器,在浏览器地址栏输入:http://localhost:9090/, 打开访问zeppelin首页界面,如下图(第一次访问,建立连接可能需要一点时间,多刷新几次即可)。然后点击【Create new node】按钮,创建一个新的notebook文件,如下图所示:
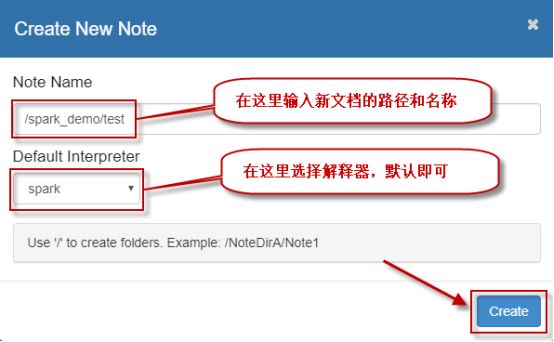
2、然后在弹出的创建窗口,填写相应信息,然后单击【Create】按钮即可:
8.4 执行Spark交互式操作
说明:如果是在standalone集群模式下使用Zeppelin,请先启动Spark集群。
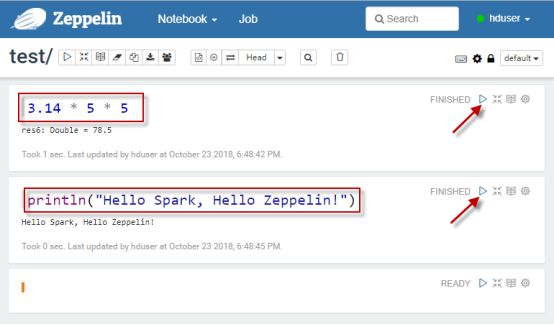
在新打开的notebook界面,执行Spark代码,如下图所示:
8.5 关闭zeppelin服务
在终端窗口中,执行以下命令,停止zeppelin服务:
1. $ zeppelin-daemon.sh stop
9. 实验结果及分析:
实验结果运行准确,无误
10. 实验结论:
经过本节实验的学习,通过学习使用基于Web的交互式开发工具Zeppelin,进一步巩固了我们的Spark基础。
11. 总结及心得体会:
Zeppelin提供了基于web的notebook工具,以非常友好的方式实现交互式数据分析,特别适合于数据分析人员和开发人员进行代码调试和数据探索。
配置Zeppelin,关键是选择合适的Spark解释器,并配置正确的参数。
在Zeppelin中创建的文档,可以导出为json格式的文件,然后分发到另一台机器上,再导入到Zeppelin中进行编辑和执行。