异常检测论文(二)
NSA: Natural Synthetic Anomalies(synthetic:合成的人造的)
摘要
我们在此提出了一种全新的自监督方法:NSA,该方法可以仅使用正常数据训练出一个解决异常检测和定位问题的端到端模型。NSA利用泊松图像编辑(Poisson image editing)将来自不同图像的按比例缩小的各种尺寸的patch进行无缝(seamless:无缝的)融合(即从不同的图像中取出不同尺寸的patch,且尺寸也是按照不同的比例缩小的)。这种方法就创造了大量的人工合成的异常,并且这种异常比以前数据增强的方法产生的异常相比,与自然的像素级别的(sub-image)不规则形式更相似,更适合自监督方法的异常检测。我们用自然图片和医学图片对该方法进行了评价。我们使用MVTec AD数据集进行的实验表明:一个训练好的能够对NSA方法产生的异常进行定位的模型,在对真实世界的预先未知的各种类型的制造缺陷进行检测时,具有很好的泛化性能。我们的方法实现了总共97.2的AUROC,比以前所有的不使用预训练数据集从零开始(scratch:擦伤,刮痕,零开始)学习的方法表现都要优异(outperforming:表现优异)。
先总体概括论文提出方法的主体思路,大概两句话。然后将自己的和他人的进行对比,专挑自己好的讲,加一些限定条件,在限定条件下我就是最棒的。该方法的思路也是通过自监督的方法人工制造异常,制造异常的方法用到了Poisson image editing,与CutPaste相比不同在于NSA是一个end-to-end模型,而CutPaste是一种两阶段模型
1 引言
异常检测是一种二(binary:二)分类任务,旨在从正常数据中检测出(这里用了separate,分离的意思,个人认为翻译成检测更好)异常的样本。有很多不同的异常检测方法都依赖于现成的训练数据集及其标签。但是目前一个困难又现实的问题是如何在训练中只能获取正常数据的情况下,对未知类型的异常进行检测和定位。为了能够在真实应用中发挥作用,一个自动化(automated:自动化的)系统必须能够检测出,微小(subtle:微小的,巧妙的,微妙的)且不常见的异常,甚至对于一些人类由于背景统一或者因远程任务的刺激(task-remote stimuli)而导致的注意力不集中盲区而不可能识别的不规则的异常,也能够轻松的识别出来[1]。
对监督学习方法来说,要想要检测出稀有的异常就意味着要获取足够多的人为标注(annotate:标注)的训练数据,这是不可能的。获取珍贵的真实标签标注是一项非常耗时的工作,并且要求在该项应用的领域具有专家级知识的人参与。基于正常训练数据集的异常检测应用于诸多领域:在医学图像中无监督方式的病变(lesion:病变)检测[2,3,4,5,6];工业生产线中的缺陷检测[7,8,9,10,11,12];或者在监控视频中找出反常事件[13,8,9]。
对于无监督学习方法最大的挑战在于设计出一种特殊的训练模式(training setup),能够使得模型在对可能出现的异常类型没有任何先验知识的情况下学习到对异常检测有帮助的特征。很多异常检测的无监督方法依赖于学习正常数据的压缩(compressed)表示,然后利用从压缩表示中派生出的embedding或重建结构来定义异常得分。通过设计一个适当的任务,自监督学习可以成为监督学习的有效代替(proxy:代表,代理),且省去了对标签的需要。相比于大多数自监督方法,诸如上下文(context:上下文,语境)预测[14]或者几何变换评估[15]都能够用来学习数据的压缩表示,但最近的一些工作[2,11]表明:使用数据增强策略来模仿(mimicking:模仿)真实缺陷对于像素级别的(sub-image:像素级别)缺陷检测非常有效。然而通过CutPaste产生的异常特征具有明显的不连续性,所以模型可能会对于人为操控(manipulation:操控)更加敏感而产生过拟合。同时FPI(Foreign Patch Interpolation:外来补丁插入法)专门应用于医学图像领域,所以对其他领域如工业缺陷检测来说,该方法产生的异常过于微小。
先介绍一下自监督和无监督的区别,得出无监督方便,不需要标签,然后介绍一下最近无监督方法的研究工作,说出他们的不足,为下文介绍自己的方法做铺垫。
我们在此介绍一种新的自监督图像异常检测方法:NSA,该方法利用泊松图像编辑将来自不同图像的各种尺寸的patch按比例缩小和移动,并进行无缝融合,以创造出大量的人工合成的异常,这些异常与之前一些应用于自监督异常检测的数据增强方法,如FPI、CutPaste相比,与自然的像素级别的异常形式更相似。与FPI类似,NSA能够应用于训练一个异常检测和定位的端到端模型,而不是将学习到的压缩表示传入到多阶段模型中。
我们将提出的方法在MVTec AD数据集[7](该数据集包含正常的训练数据,也包含具有正常和异常的训练数据,且所有数据都含有大量的自然和制造缺陷,包含10个实物类别和5中文本类别)上进行了评估实验。NSA达到了SOTA的水平:定位96.3AUROC及检测97.2AUROC,且这是从零开始学习的结果。该方法与使用在ImageNet上进行预训练的模型相比也差不多。且与拥有大量类别种类和数据的ImageNet相比,MVTec AD中每个类别只有60到391张图片。
NSA是一种泛化性能很强的方法,它能够在图像中产生多种现实性的人工合成异常,且其应用并不仅限于自然图像。我们利用一个公共胸部X射线影像的数据集创建了子集,NSA在子集上相比于其他自监督疾病监测也达到了SOTA的水平
大致介绍自己的方法,强调结果很好。
2 相关工作
基于重建的异常检测:VAE(变分自编码机)、GAN(生成对抗网络)
基于embedding的异常检测:SVDD(支持向量数据描述)、GDE(高斯分布估计)、KNN(K近邻算法)、pre-trained DNN(预训练的深度神经网络)、
自监督学习:一些之前文献的介绍
这里对异常检测相关方法进行了一个小总结,基本都是两阶段的模型,相关文献之后可继续深入了解。
泊松图像编辑:将一张图片的一部分粘贴到另一张图片上会造成明显的不连续性。[20]中提出一个可以将目标(在此任务中的目标就是patch,各种尺寸,各种大小的patch)从一张图片中无缝克隆到另一张图片的方法。对一个由g![]() 给出的原图像,一个由f*
给出的原图像,一个由f*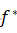 给出的目标图像,我们要在边界为∂Ω
给出的目标图像,我们要在边界为∂Ω![]() 的区域Ω
的区域Ω![]() 内找到一个插值函数满足下面的最小化问题(1)。根据[20],在由目标图像给出的迪利克雷边界条件(Dirichlet boundary condition)下,对泊松偏微分方程(2)有唯一解。
内找到一个插值函数满足下面的最小化问题(1)。根据[20],在由目标图像给出的迪利克雷边界条件(Dirichlet boundary condition)下,对泊松偏微分方程(2)有唯一解。
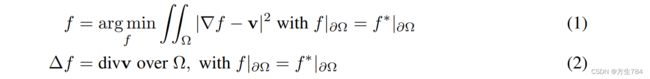
[20]中为定义引导向量场(guidance field)给出了两种选择:a):使用原图像梯度(3);b):原图像和目标图像的混合(4).
实际上,方程(2)由于存在有限差分离散化(finite difference discretization),可以解出数值解。无缝克隆在OpenCV库中已经实现了,我们也将此项技术应用在自监督任务中。
3 NSA自监督任务
由于在训练时只有正常数据,这个模型需要使用一个代理任务来训练(即NSA作为模型的proxy task,以创建异常的数据集)。在我们的实验中,这个代理任务就是在正常数据中将源图像的patch融合到目标图像中,并将此过程产生的异常进行定位,步骤如下
- 在源图像中随机选取一块矩形patch
- 随机resize矩形patch并选择一块与源图像不同的目标图像
- 将patch无缝融合进目标图像
- 选择性地重复上述1-3步骤,将多个patch融入同一个图像
- 创造了一个像素级别地标签掩膜(label mask)
正常来说,给出两个N×N![]() 训练图像xs
训练图像xs![]() 和xd
和xd![]() ,我们随机选取一个矩形patch,ps
,我们随机选取一个矩形patch,ps![]() ,宽为w
,宽为w![]() ,高为h
,高为h![]() ,patch所在源图像xs
,patch所在源图像xs![]() 中的中心坐标为cx,cy
中的中心坐标为cx,cy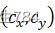 ,且有:
,且有:
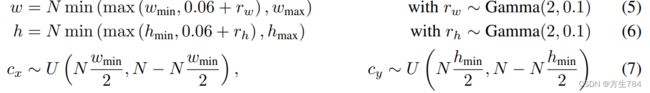
(U代表均匀分布,Nwmin2![]() 是宽度最小值的二分之一,保证中心坐标服从此均匀分布是保证在截取patch时是完整的;wmin、wmax
是宽度最小值的二分之一,保证中心坐标服从此均匀分布是保证在截取patch时是完整的;wmin、wmax![]() 表示的是截取的倍率,在代码中的值是(0.05,0.2))
表示的是截取的倍率,在代码中的值是(0.05,0.2))
Patch宽度和高度的数值是从截断伽马分布(truncated Gamma distribution)中采样的,这意味着我们认为虽然异常是比较小且只出现在局部位置,但是希望这个模型也能够有识别稍大一点的不规则样式的能力。因此,一些细长的矩形patch或者有时候稍大一点的patch也会被产生出来。宽度和高度的边界值(bound)是基于图像中目标的维度而选择的。对于包含一个目标和平顺(plain)背景的图像,我们通过限制图像和背景之间亮度(也不能说是亮度,就是像素值)的绝对值差值来计算图像中目标的掩膜ms![]() 和md
和md![]() 。对每一个像素i
。对每一个像素i![]() 的掩膜计算(这里应该是指掩膜的透明度)由以下公式给出(其中的b是背景的像素值):
的掩膜计算(这里应该是指掩膜的透明度)由以下公式给出(其中的b是背景的像素值):
![]()
我们重复方程(7)直到满足:ps∩mswh>tobject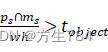 ,即能够保证patch中包含目标物体的一部分。然后我们将patch重新resize成新的ps'
,即能够保证patch中包含目标物体的一部分。然后我们将patch重新resize成新的ps'![]() ,宽为w'=sw
,宽为w'=sw![]() ,高为h'=sh
,高为h'=sh![]() ,我们在目标图像xd
,我们在目标图像xd![]() 中以相同的维度选取目标patch,pd
中以相同的维度选取目标patch,pd![]() ,且其中心坐标为c'x,c'y
,且其中心坐标为c'x,c'y![]() ,具体计算由下式得到:
,具体计算由下式得到:
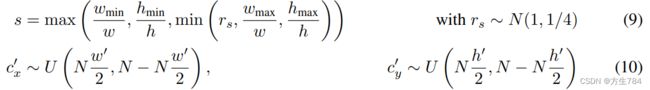
为了避免造成大量的patch样本在图像背景的浮动(原文中用了floating,不是很能理解),我们重复方程(10)直到pd∩mdw'h'>tobject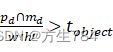 (保证patch中包含目标的一部分)且mpd∩mp'smp's>toverlap
(保证patch中包含目标的一部分)且mpd∩mp'smp's>toverlap (overlap:叠加,套,交叉,此不等式保证了p's
(overlap:叠加,套,交叉,此不等式保证了p's![]() 和目标图像中由目标的部分是重合的,就是说要把从源图像截下来的p's
和目标图像中由目标的部分是重合的,就是说要把从源图像截下来的p's![]() ,要大致放在pd
,要大致放在pd![]() 的位置),上述式中mpd
的位置),上述式中mpd![]() 和mp's
和mp's![]() 分别是目标(destination)图像中的pd
分别是目标(destination)图像中的pd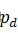 与源图像的目标(object)ps'
与源图像的目标(object)ps'![]() 掩膜。我们将p's
掩膜。我们将p's![]() 以中心坐标c'x,c'y
以中心坐标c'x,c'y![]() 无缝融合进xd
无缝融合进xd![]() 中,获得训练样本x
中,获得训练样本x![]() 。在融合了第一个patch之后,我们通过随机翻转n-1个硬币来决定是否融合另外的patch,则最多可以再融合n-1个patch(we add up to n − 1 further patches by flipping n − 1coins whether to add another patch or not,这句话着实没弄懂,只能大概这样翻译)。Figure 1(a)展示了简化的人工合成异常的产生过程,Figure 1(b)从左到右分别是原始图像和两张CutPaste, FPI, NSA产生的异常图片。
。在融合了第一个patch之后,我们通过随机翻转n-1个硬币来决定是否融合另外的patch,则最多可以再融合n-1个patch(we add up to n − 1 further patches by flipping n − 1coins whether to add another patch or not,这句话着实没弄懂,只能大概这样翻译)。Figure 1(a)展示了简化的人工合成异常的产生过程,Figure 1(b)从左到右分别是原始图像和两张CutPaste, FPI, NSA产生的异常图片。

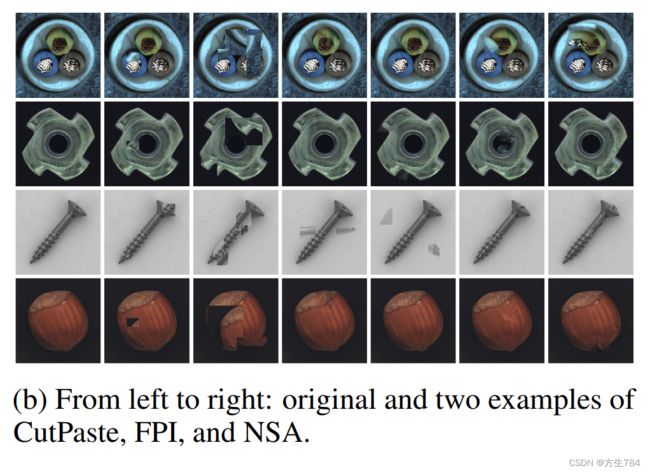
外来patch的引入给图像带来了局部强度(intensity:强度,亮度)的差异,利用此差异来创造像素级别的标签y![]() ,创造标签的方式有:
,创造标签的方式有:
a)二分类方式:以是否有差异作为判断依据
b)连续值方式:三个通道的平均绝对强度差值
c)前两种方式的逻辑回归函数
所有标签值都经过中值滤波(median filtered),变得更加连贯。在过滤之前,所有的像素值是通过下列公式计算的:

相比之下,FPI使用插值系数作为标签。这一操作在一定程度上是有一些问题的,因为在不知道源图像和目标图像的像素强度(pixel intensity)的情况下是无法确定插值系数的。我们的标签与像素强度的变化(由patch融合产生的变化)是有直接关系的,因此可以提供一个更加连贯(或者说更加稳定的)训练信号。
当使用的是有界的标签(ybinary![]() 或者ylogistic
或者ylogistic![]() )时,我们将我们的像素级的回归目标定义为二分类交叉熵损失函数;对于无界的标签(ycontinuous
)时,我们将我们的像素级的回归目标定义为二分类交叉熵损失函数;对于无界的标签(ycontinuous![]() ),我们使用均方差损失。损失公式如下,其中的y=fx
),我们使用均方差损失。损失公式如下,其中的y=fx![]() 是由一个深度卷积的编码-解码器训练产生。
是由一个深度卷积的编码-解码器训练产生。
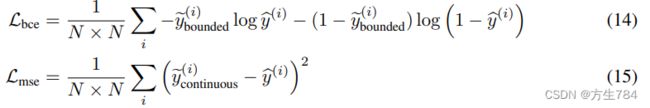
通过不断变化尺寸、长宽比、patch在源图像和目标图像的位置以及对patch尺度的重新调整,NSA方法很有活力地(dynamically)在训练中创造了大量的人工合成异常。这些样本的尺寸、形状、纹理(texture)、位置、局部图像的成分(component)以及由于融合patch中包含一些背景的遗失成分等特征都各不相同,能够保证所有图像总的分布的真实同时,也能避免明显的不连续性。因此,这些样本是对自然的像素级别的异常更加真实的近似,而不是像CutPaste[11]增强那样简单地将patch paste到不同的位置;,尽管对人类观测者还是能明显地感觉出这些异常是人工制造的,NSA产生的异常的种类也更加多样,而不是像FPI[2]直接对两个独立图像在对应位置进行patch的插入。
4 实验
我们将使用我们的自监督任务训练的端到端检测和定位的模型与使用FPI、FPI with 泊松融合、CutPaste数据增强的模型在MVTec AD数据集和公共的胸腔X射线的经过筛选的(curate:策划)子集上进行了对比。我们用AUROC(area under the receiver operating characteristic curve)对模型的性能进行评价。
数据集:MVTec AD包含10目标类和5个纹理类数据。作者对原公共胸腔X射线数据集进行了重新筛选,留下了1973张正常的训练图像,299张正常的和139张不正常的男性患者的测试图像以及有1641张正常训练图像,244张正常图像和123张异常图像的女性患者图像。
4.1 网络结构和训练数据
我们使用没有分类层(也就是全连接层)的ResNet-18[23]的编码器-解码架构作为编码器,然后在瓶颈处利用1×1![]() 卷积减少通道数,最后是一个更简单的解码器。除使用NSA的模型外,最终的激活函数用的是sigmoid,损失函数用的是二分类交叉熵损失,使用NSA(连续,这个连续指的是)的模型激活函数用的是ReLU,损失函数用的是平方差损失,因为标签是无界的。这些模型训练时的各个参数为:batch_size:64、梯度下降方式:Adam、学习率变化:cosine-annealing,超过320个epochs梯度从10-3衰减到10-6。对于相互之间没有联系的物体,损失要花更久才能收敛,所以在MVTec AD的数据集上中榛果、金属螺母、和螺丝这些类别上我们用了560个epochs。对于rCXR数据集,我们用了240个epochs。对于所有的自监督任务的方法以及其变种,训练时使用的超参数都是一样的。补充材料中给出了这些超参数。注意在使用FPI和CutPaste方法时,我们所使用的目标掩膜和patch的尺寸大小数值都是从截断的Gamma分布中获取的,而不是像其原论文中描述的从均匀分布中取样,这样也是为了与NSA有一个更公平的对比。
卷积减少通道数,最后是一个更简单的解码器。除使用NSA的模型外,最终的激活函数用的是sigmoid,损失函数用的是二分类交叉熵损失,使用NSA(连续,这个连续指的是)的模型激活函数用的是ReLU,损失函数用的是平方差损失,因为标签是无界的。这些模型训练时的各个参数为:batch_size:64、梯度下降方式:Adam、学习率变化:cosine-annealing,超过320个epochs梯度从10-3衰减到10-6。对于相互之间没有联系的物体,损失要花更久才能收敛,所以在MVTec AD的数据集上中榛果、金属螺母、和螺丝这些类别上我们用了560个epochs。对于rCXR数据集,我们用了240个epochs。对于所有的自监督任务的方法以及其变种,训练时使用的超参数都是一样的。补充材料中给出了这些超参数。注意在使用FPI和CutPaste方法时,我们所使用的目标掩膜和patch的尺寸大小数值都是从截断的Gamma分布中获取的,而不是像其原论文中描述的从均匀分布中取样,这样也是为了与NSA有一个更公平的对比。
4.2 结果
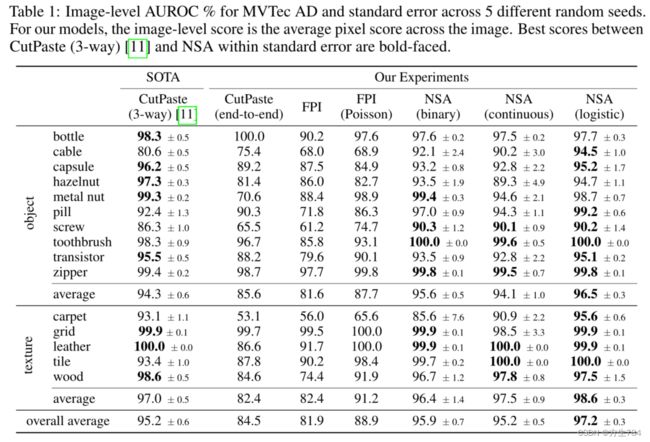
(这一节还描述了很多之前重复过的总结性的东西,看了一遍之后发现并没有过多有助于理解整篇文章的内容,就不再费力翻译了)
5 结论
我们提出了解决一种自监督任务的方法,这种方法能够创造出多样的与实际相类似的人工合成的异常。用此方法在可控的条件下产生的训练样本能够帮助产生一些相似的微小的异常。这为对真是异常的检测提供了一个更一致的训练信号和结果。这种损失函数和人工标签的制定产生了一个有效的且计算效率高的训练任务。使得NSA能够不论在自然图像数据集还是医学图像数据集上表现得都比一些SOTA方法更好,这也证实了NSA的良好的泛化性能。在之后的研究中,加入一些诸如量化不确定性或者利用已知异常的种类等操作能够帮助促进(facilitate,促进、帮助、使容易)NSA在更多重要场合的应用。
翻译完了,还是一头雾水?!
解决以下问题:
- NSA除了利用图像的无缝融合创造异常外,它还干了什么?√
- NSA创造异常的详细的具体的过程是啥?√
- 损失和标签的制定是怎么回事?√
- 训练网络中的bottleneck用了1x1卷积的作用是啥?√
- ResNet的解码器结构是什么意思?√
- 预测阶段模型如何起作用,输出的是什么?√
- 论文中的那些数学公式每一个都有什么作用。√
问题1:主要在最后一步,Create a pixel-wise label mask,直译过来就是“创建一个像素级的标签掩膜”,也就是说,NSA创造了异常之后,并没有简单的用0和1去表示正常还是异常,而是采用了另一种方式来制造标签!所以,这个掩膜与训练标签之间有何联系、标签又是如何被产生的呢?
公式8中,计算图像中目标的掩膜,利用原像素统一减去背景像素,且对此差值绝对值进行限制,保证出现正常的物体掩膜。且计算了源图像的物体掩膜、目标图像的物体掩膜、源图像patch和目标图像的掩膜。以保证进行图像融合时异常能够被置于合适的位置!具体见问题二。由此可见,掩膜到这一段与训练的标签没有任何关系。
论文提到,创造了样本x![]() 之后接下来要创建标签y
之后接下来要创建标签y![]() 。这里的y
。这里的y![]() 不是CutPaste中的0或1,而是“像素级别的标签”,也就是好多像素组成的图,当然也不能称之为严格意义上的图片,就只是用来当作标签,形式上和feature map有点像,也可以说就是一种feature map,包含着正常或者异常的特征信息。制作此种标签的方式有三种:二分类、连续型、逻辑回归型,计算公式就是公式11、12、13.但是这也仅仅是训练时所用的标签,目的是使得模型能够训练出提取图片异常特征的能力。比CutPaste的优势在于,模型更加细致,达到了像素级别,但是训练计算也会变得复杂。
不是CutPaste中的0或1,而是“像素级别的标签”,也就是好多像素组成的图,当然也不能称之为严格意义上的图片,就只是用来当作标签,形式上和feature map有点像,也可以说就是一种feature map,包含着正常或者异常的特征信息。制作此种标签的方式有三种:二分类、连续型、逻辑回归型,计算公式就是公式11、12、13.但是这也仅仅是训练时所用的标签,目的是使得模型能够训练出提取图片异常特征的能力。比CutPaste的优势在于,模型更加细致,达到了像素级别,但是训练计算也会变得复杂。
(问题1正好解决了问题3,可以偷懒了![]() ,但是这里又产生了新的问题:如果标签是特征图形式的话,预测阶段输出的是什么?加上,变成9个问题)
,但是这里又产生了新的问题:如果标签是特征图形式的话,预测阶段输出的是什么?加上,变成9个问题)
问题2:详细流程如下:
- 对于给定大小的图像,首先在源图像中随机截取一个patch,ps
 。截取的规则为公式5、6、7. ps
。截取的规则为公式5、6、7. ps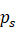 高度和宽度的计算由公式5、6决定,中心位置的选择由公式7决定。
高度和宽度的计算由公式5、6决定,中心位置的选择由公式7决定。 - 计算源图像中的物体掩膜ms
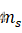 ,并利用公式7重复选择ps
,并利用公式7重复选择ps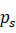 的中心位置使得ps
的中心位置使得ps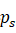 满足ps∩mswh>tobject
满足ps∩mswh>tobject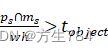 ,以保证ps
,以保证ps 中有一部分的物体。
中有一部分的物体。 - 重新调整ps
 的大小成ps'
的大小成ps' ,ps'
,ps' 尺寸大小的调整由公式9决定。
尺寸大小的调整由公式9决定。 - 根据ps'
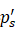 的尺寸在目标图像中截取一个patch,pd
的尺寸在目标图像中截取一个patch,pd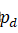 的中心位置的选择由公式10决定。
的中心位置的选择由公式10决定。 - 利用公式10重复选取pd
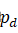 直到满足pd∩mdw'h'>tobject
直到满足pd∩mdw'h'>tobject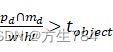 ,即pd
,即pd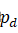 中也要包含物体的一部分,并且计算ps'
中也要包含物体的一部分,并且计算ps' 和pd
和pd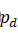 的掩膜mps'
的掩膜mps'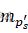 和mpd
和mpd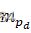 ,以满足mpd∩mp'smp's>toverlap
,以满足mpd∩mp'smp's>toverlap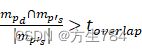 ,保证ps'
,保证ps'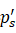 和pd
和pd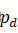 有重叠的部分。
有重叠的部分。
即ps'![]() 中有物体的一部分,pd
中有物体的一部分,pd![]() 中也有物体的一部分,且ps'
中也有物体的一部分,且ps'![]() 和pd
和pd![]() 有重叠的物体部分,也就是说ps'
有重叠的物体部分,也就是说ps'![]() 和pd
和pd![]() 非常像,但是又不是,这就叫做人工合成的自然异常,即NSA
非常像,但是又不是,这就叫做人工合成的自然异常,即NSA
6. 满足(5)的要求后将ps'![]() 通过泊松融合(即无缝融合)融合到pd
通过泊松融合(即无缝融合)融合到pd![]() 的位置,如此供训练使用的异常样本就做好了。
的位置,如此供训练使用的异常样本就做好了。
问题4:首先看一下什么叫bottleneck。对于一个网络结构,组成部分可分为:backbone、neck、head三大部分。
Backbone:主干网络,用来提取图像的特征信息,这些网络在分类问题上已经展现了非常好的特征提取性能,可以直接从官网加载。我们在进行网络搭建的时候经常讲我们构建的网络接在backbone后面以适应我们自己的任务。比较常用的backbone有ResNet、VGG等。
Head:预测输出的网络,利用backbone的输出特征做出预测,比方说全连接神经网络就是一个典型的预测输出网络。
Neck:放在backbone和head之间的,对特征进行一些微调,使得head能够更好的利用这些特征。
所谓bottleneck,也是neck的一种,瓶颈,指的就是输出的维度比输入的维度小了许多,1x1卷积实现的就是这个功能,比如说backbone输出的特征图有1024个通道,我们使用1x1卷积,设置多少个卷积核,通过bottleneck后的输出通道数就是几个。
问题5和问题6:训练中的解码器结构负责将1x1卷积后的feature map转化为标签类型。注意,论文中说这是一个端到端的网络,也就是说输入一张图直接就可以输出一张预测图,正如论文中的Figure 2所示的那样,预测图是一种heat map,这种heat map可以显示出图片是否有异常,也会显示出异常的位置在哪里。回到问题5和问题6,就是不要想多了,训练时候的模型和预测时候的模型是一样的,正所谓end-to-end!所以说那个标签y![]() 很关键。
很关键。
问题7:除了泊松融合的公式没有弄懂外,其余在本轮文中出现的公式已经在上述问题中解释清楚。泊松融合这块与图像处理有关,这里就不详细介绍。
直接复制上来有点乱码,见谅
原论文:NSA论文链接
参考代码:NSA代码