概率模型校准
1、场景业务问题
现实业务问题中,时常会遇到一些业务模型【如信贷风控a/b/c卡模型、广告领域的CTR等模型】,我们一般的处理逻辑是: 梳理抽象业务问题为数据问题 -> 整理样本数据 -> 训练模型 -> 模型测试验证 -> 模型上线部署。如果我们用的模型是逻辑回归模型,则无需进行模型校验,而如果我们使用数模型 或者 深度学习模型,实际predict出来的概率并不是真正的“好人”或“坏人”概率,需要进行模型校准。
在执行分类时,我们通常不仅希望预测类标签,而且还希望获得相应标签的概率。这个概率让我们对预测更有信心。有些模型对类概率的估计很差,有些甚至不支持概率预测(例如,SGDClassifier的一些实例)。校准模块可以更好地校准给定模型的概率,或添加对概率预测的支持。经过良好校准的分类器是概率分类器,对于这种分类器,predict_proba方法的输出可以直接解释为置信水平。例如,一个校准良好的(二元)分类器应该对样本进行分类,在它给出的predict_proba值接近0.8的样本,大约有80%(的置信度)实际上属于阳性类别。
备注: 数值在0与1之间不代表它就是概率!当预测的概率反映了真实情况的潜在概率时,这些预测概率被称为“已校准”
2、模型校准前奏:偏差可视化
reliability diagram,这是一种相对简单而且常用的可视化方法,用它能大致评估出当前模型的输出结果与真实结果有多大偏差。如下面这段介绍,如果能得到斜率为45度的线,那么意味着模型输出的结果是有效的估计。
On real problems where the true conditional probabilities are not known, model calibration can be visualized with reliability diagrams (DeGroot & Fienberg, 1982). First, the prediction space is discretized into ten bins. Cases with predicted value between 0 and 0.1 fall in the first bin, between 0.1 and 0.2 in the second bin, etc. For each bin, the mean predicted value is plotted against the true fraction of positive cases. If the model is well calibrated the points will fall near the diagonal line.
样例如下:(一般而言,如果模型是一条斜45直线,则校准可以考虑忽略,加持) 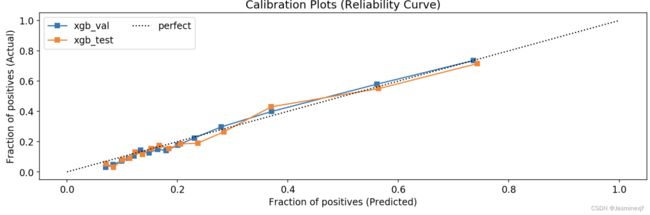
【】
3、模型校准方法
现在主流的模型校准算法有:Platt scaling[1] 和 Isotonic regression[2]。Platt scaling使用LR模型对模型输出的值做拟合(并不是对reliability diagram中的数据做拟合),适用于样本量少的情形。Isotonic regression则是对reliability diagram中的数据做拟合,适用于样本量多的情形。样本量少时,使用isotonic regression容易过拟合。需要注意一点,无论是对platt scaling方法还是isotonic regression方法,为了得到一个有效的校准模型,需要用一个独立于训练集的验证集,否则会引入偏差。

3.1 Platt scaling
platt scaling本质上是对模型sigmoid输出的分数做概率变化,在此,假设有两个参数a、b,输入样本为 ,模型输出分数为
,模型输出分数为 , 则最终输出的概率计算公式变为:
, 则最终输出的概率计算公式变为:
![]()
a,b参数优化则可以通过最大化似然函数的方法求得
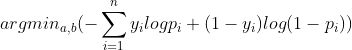
3.2 Isotonic regression
中文翻译为保序回归,是一种非参回归模型(nonparametric regression)。这种方法只有一个约束条件即,函数空间为单调递增函数的空间。

应用保序回归到CTR预估模型的校准上的流程大致有这样几步:
-
准备一份验证集(不同于用于训练CTR预估模型的训练集)用于训练保序回归模型。这份验证集的每个样本仍然是展示点击信息。
-
将[0, 1]区间划分为N个桶,每个桶的长度相同,比如N=105或者N=106。
-
用之前训好的CTR预估模型在此验证集上进行预测,给出每个样本的点击率估计值,基于这些点击率估计值,将验证集中的样本落入对应的桶中。
-
对每个桶,基于展示点击信息,计算落入样本的真实点击率。比如桶表示的区间为[1×10−5,2×10−5),取平均值为1.5×10−5,这个桶的真实点击率为10−6,这样这个桶就得到reliability diagram图的一个点(1.5×10−5,10−6),全部N个桶就构成了整个reliability diagram。
-
对上步生成的reliability diagram中的数据运行isotonic regression(这个数据量不大,N=106的数据大小也就几M空间,scikit-learn工具包完全可以胜任)
上述流程最终产出校准用的映射表,在线上加载这个映射表实时应用,比如在线上预估出的CTR值为x,查校准用的映射表,判断x所在的桶,取得映射后的校准值y。在训练校准模型的流程中,有2点是有讲究的:第2步N的设置和第4步如何判定算出的真实点击率是可信的,这2点都需要结合实际情况来分析。
3.3 histogram binning
对于所有输出未校准预测概率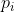 ,将其划分成M个bin,对于每个bin设置一个校准分数
,将其划分成M个bin,对于每个bin设置一个校准分数![]() ,然后进行函数校准。不常用,未实践。
,然后进行函数校准。不常用,未实践。
3.4 temperature scaling
是Platt scaling的一个变体,在softmax公式基础上引入温度参数T,对输出分数修改,以达到概率校准的目的。
样例代码
## 信贷场景的分类模型校验
from sklearn.metrics import log_loss
from sklearn.calibration import calibration_curve
from sklearn.calibration import IsotonicRegression
import matplotlib.pyplot as plt
from sklearn.metrics import (brier_score_loss, precision_score, recall_score,
f1_score)
import pandas as pd
model_res_df=pd.DataFrame()
calibration_socre_res_df = pd.DataFrame()
prod_sets = ['1.xxx','2.yyy','3.zzz','4.www','5.vvv','6.aaa']
for prodv in (prod_sets):
## 第一步计算log-loss
newdf = model_df[(model_df['prod'] == prodv)] ## model_df用于模型校验的数据
calibration_socreres_newdf = calibration_socre_df[(calibration_socre_df['prod'] == prodv)] ## 待进行模型校验的数据: calibration_socre_df
cal_score = log_loss(newdf['is_credit_success'], newdf['prob'])
print('The Log-loss about classifier of %s is %f, The shape of this data is %s' %(prodv, cal_score, newdf.shape))
# 第二步 绘图校准曲线calibration_curve
clf_score = brier_score_loss(newdf['is_credit_success'], newdf['prob'], pos_label=newdf['is_credit_success'].max())
fraction_of_positives, mean_predicted_value = calibration_curve(newdf['is_credit_success'], newdf['prob'],normalize=False,n_bins=5)
plt.plot(mean_predicted_value, fraction_of_positives, "s-",label="%s (%1.3f)" % (prodv, clf_score))
plt.legend(loc="lower right")
##第三步 直接进行保序回归
isotonic = IsotonicRegression(out_of_bounds='clip',
y_min=newdf['prob'].min(),
y_max=newdf['prob'].max())
isotonic.fit(newdf['prob'], newdf['is_credit_success'])
isotonic_probs = isotonic.predict(newdf['prob'])
calibration_socreres_probs = isotonic.predict(calibration_socreres_newdf['prob'])
newdf['isotonic_calibration'] = isotonic_probs
calibration_socreres_newdf['isotonic_calibration'] = calibration_socreres_probs
model_res_df=model_res_df.append(newdf)
calibration_socre_res_df = calibration_socre_res_df.append(calibration_socreres_newdf)[1] Isotonic regression (来自Wikipedia)
[2] Platt scaling (来自Wikipedia)
[3] 概率校准,scikit-learn中文社区:https://scikit-learn.org.cn/view/104.html
[4] 概率校准模型全链路实践:从样本到模型到校准全流程【超推荐】
- 1 Probability Calibration
- 1.1 Data Preprocessing
- 1.2 Model Training
- 1.3 Measuring Calibration
- 1.4 Calibration Model
- 1.5 Calibration Model Evaluation
- 1.6 Final Notes
- 2 Reference