统计学习方法-001_感知机算法及python代码实现
学习参考b站视频:
https://www.bilibili.com/video/BV1W7411N7Ag?p=35
我的笔记
一、背景:
通过学习第二章-感知机模型,由简入深,逐渐了解统计学习的三大要素和机器学习的基础。熟悉整个流程。

二、统计学习三大要素:
模型、策略、算法。
三、具体到感知机的三大要素:
模型:如下图所示的函数模型

策略:找到一个损失函数,并将损失函数最小化。

感知机的损失函数:

算法:随机 梯度下降算法。
这里的随机指的是,在原损失函数中,要求求出所有的误分点的和,但是在w和b的每一次更新迭代中,如果每一次都计算所有点的总和,那么计算量过大,算力和效益不成正比,那么干脆只随机取一个误分点,对两个参数进行更新。

- 批量梯度下降和随机梯度下降算法的区别:
批量梯度下降是将所有的点都用来计算,用来更新参数。随机梯度下降是每一次更新只随机取一个点。
四、python代码实现感知机算法
这里的感知机算法实现和线性回归算法差不多。
(一)、准备工作
(1)在代码同目录下存储TXT文件存储训练样本集数据,格式如下:
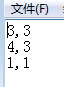
(2)开始编写代码:
- 导入pandas库,读取TXT文件数据,载入存储在dataframe对象中
import pandas as pd
# 1、读取文件,载入数据
df = pd.read_csv("ganzhiji.txt", names=["x1", "x2"])
(3)导入seaborn 和matplotlib.pyplot库,看一下载入的原始数据
import seaborn as sns
import matplotlib.pyplot as plt
# 2、原始数据可视化,看一下数据
sns.lmplot("x1", "x2", df, height=6, fit_reg=False)
plt.show()
这里显示的图形如下:

(4)先了解一下什么是DataFrame数据帧,后面提取特征会用到
①Pandas数据帧(DataFrame)
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
数据帧(DataFrame)的功能特点:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
pandas中的DataFrame可以使用以下构造函数创建 -
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
构造函数的参数如下:

②创建DataFramePandas数据帧
(DataFrame)可以使用各种输入创建,如 -
- 列表
- 字典
- 系列
- Numpy ndarrays
- 另一个数据帧(DataFrame)
关于数据帧的介绍摘自于易百教程,更多关于DataFrame的中文介绍可以参考:
https://www.yiibai.com/pandas/python_pandas_dataframe.html
(5)编写提取特征函数 get_X(df)
因为想要进行向量化的计算方便计算,即
h(x) = theta0 + theta1 * x1 + theta2 * x2 变为 h(x) = theta0 * x0 + theta1 * x1 + theta2 * x2(这里的x0=1) , 即 h(x) = theta转置 * X。所以需要对X特征向量除了原有的x1和x2之外加上x0。
那么,怎么实现上面说的对向量X的改造呢?即要借助DataFrame数据帧来实现~
通过先创建一个数据帧DataFrame,他的data参数的输入在这里是一个字典,然后再和原有的X向量数据合并,即X向量从二维变成三维。
①先创建一个m行(df的长度)1列全1的数据帧DataFrame对象ones:
ones = pd.DataFrame({'ones': np.ones(len(df))}) #ones是m行1列的值为全1的dataframe数据帧
②再将新的ones数据帧和原来的df对象合并数据,根据列合并
# (2)再合并数据,根据列合并
# 使用concat添加相交特征以避免副作用,虽然对于大型数据集效率不高
data = pd.concat([ones, df], axis=1) # axis=1表示列轴,即进行的是列合并
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合。
关于concat函数,可以参考:https://blog.csdn.net/stevenkwong/article/details/52528616
pd.concat(objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)
参数说明:
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
③函数返回:
return data.iloc[:, :-1].as_matrix() # 这个操作返回 ndarray数组,不是矩阵
iloc[ , ]:根据行号、列号来取数据。第一个参数是行号,第二个参数是列号。
[:-1]:表示正向输出,从开始~倒数第一个(不包括倒数第一个)。因为这里最后一列是标签。
as_matrix():因为这里提取完数据后,数据是DataFrame的形式,这个时候要记得转换成数组。作用参考:https://blog.csdn.net/weixin_41884148/article/details/88783328
- 关于ndarray对象:
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
(6)编写读取标签函数 get_Y(df)
def get_Y(df):
return np.array(df.iloc[:,-1]) # #df.iloc[:, -1]是指df的最后一列
(7)编写特征缩放函数 normalize_feature(df)
def normalize_feature(df):
# """Applies function along input axis(default 0) of DataFrame."""
return df.apply(lambda column: (column - column.mean()) / column.std())#特征缩放
好的,以上都是为了写出假设函数(回归函数)的铺垫,接下来就是要写出算法实现的正经第一步了:写出回归函数h(x)!

(二)写出回归函数
# 6、写出线性回归函数
def linear_regression(X_data, y_data, alpha, epoch,
optimizer=tf.train.GradientDescentOptimizer): # 这个函数是旧金山的一个大神Lucas Shen写的
# placeholder for graph input
X = tf.placeholder(tf.float32, shape=X_data.shape)
y = tf.placeholder(tf.float32, shape=y_data.shape)
# construct the graph
with tf.variable_scope('linear-regression'):
W = tf.get_variable("weights",
(X_data.shape[1], 1),
initializer=tf.constant_initializer()) # n*1
y_pred = tf.matmul(X, W) # m*n @ n*1 -> m*1
loss = 1 / (2 * len(X_data)) * tf.matmul((y_pred - y), (y_pred - y), transpose_a=True) # (m*1).T @ m*1 = 1*1
opt = optimizer(learning_rate=alpha)
opt_operation = opt.minimize(loss)
# run the session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
loss_data = []
for i in range(epoch):
_, loss_val, W_val = sess.run([opt_operation, loss, W], feed_dict={X: X_data, y: y_data})
loss_data.append(loss_val[0, 0]) # because every loss_val is 1*1 ndarray
if len(loss_data) > 1 and np.abs(
loss_data[-1] - loss_data[-2]) < 10 ** -9: # early break when it's converged
# print('Converged at epoch {}'.format(i))
break
# clear the graph
tf.reset_default_graph()
return {'loss': loss_data, 'parameters': W_val} # just want to return in row vector format
再一次读取数据,赋予列名:
data = pd.read_csv('ganzhiji.txt', names=['population', 'profit'])#读取数据,并赋予列名
data.head() # 看下数据前5行
(三)计算代价函数

- 看一下数据维度
X = get_X(data)
print(X.shape, type(X))
y = get_y(data)
print(y.shape, type(y))
theta = np.zeros(X.shape[1])#X.shape[1]=2,代表特征数n
def lr_cost(theta, X, y):
# """
# X: R(m*n), m 样本数, n 特征数
# y: R(m)
# theta : R(n), 线性回归的参数
# """
m = X.shape[0]#m为样本数
inner = X @ theta - y # R(m*1),X @ theta等价于X.dot(theta)
# 1*m @ m*1 = 1*1 in matrix multiplication
# but you know numpy didn't do transpose in 1d array, so here is just a
# vector inner product to itselves
square_sum = inner.T @ inner
cost = square_sum / (2 * m)
return cost
lr_cost(theta, X, y)#返回theta的值
(四)批量梯度下降
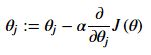
def gradient(theta, X, y):
m = X.shape[0]
inner = X.T @ (X @ theta - y) # (m,n).T @ (m, 1) -> (n, 1),X @ theta等价于X.dot(theta)
return inner / m
def batch_gradient_decent(theta, X, y, epoch, alpha=0.01):
# 拟合线性回归,返回参数和代价
# epoch: 批处理的轮数
# """
cost_data = [lr_cost(theta, X, y)]
_theta = theta.copy() # 拷贝一份,不和原来的theta混淆
for _ in range(epoch):
_theta = _theta - alpha * gradient(_theta, X, y)
cost_data.append(lr_cost(_theta, X, y))
return _theta, cost_data
#批量梯度下降函数
epoch = 500
final_theta, cost_data = batch_gradient_decent(theta, X, y, epoch)
final_theta
#最终的theta
cost_data
# 看下代价数据
# 计算最终的代价
lr_cost(final_theta, X, y)
(五)代价数据可视化
ax = sns.tsplot(cost_data, time=np.arange(epoch+1))
ax.set_xlabel('epoch')
ax.set_ylabel('cost')
plt.show()
#可以看到从第二轮代价数据变换很大,接下来平稳了
b = final_theta[0] # intercept,Y轴上的截距
m = final_theta[1] # slope,斜率
plt.scatter(data.population, data.profit, label="Training data")
plt.plot(data.population, data.population*m + b, label="Prediction")
plt.legend(loc=2)
plt.show()