Mysql——索引
Mysql——索引
作用
海量数据情况下,提高查询效率
分类
存储结构
(注:这里指存储时的保存形式)
- BTree索引(B-Tree或 B+Tree索引)
- Hash索引
- full-index全文索引
- R-Tree索引
应用层次
- 普通索引
- 唯一索引
- 复合索引
物理顺序与键值的逻辑(索引)顺序关系
- 聚集索引
- 非聚集索引
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引;
唯一索引:索引列的值必须唯一,但允许有空值;
复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并;
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行;
非聚簇索引:不是聚簇索引,就是非聚簇索引。
底层实现
mysql默认存储引擎innodb只显式支持B-Tree( 从技术上来说是B+Tree)索引,对于频繁访问的表,innodb会透明建立自适应hash索引,即在B树索引基础上建立hash索引,可以显著提高查找效率,对于客户端是透明的,不可控制的,隐式的。
Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。
MySQL为什么选择B+tree?
1.二叉查找树
缺点:搜索效率不足,一般来说,树结构中数据的深度决定它的搜索io次数

2.平衡二叉查找树
缺点:节点数据内容太少,每一个磁盘块(节点/页)保存的关键字数据量太少,没有很好利用操作系统和磁盘数据的交换特性(最少4BK)和磁盘预读能力(空间局部性原理)

3.B tree(多路平衡查找树)
缺点:非叶子节点,保存了数据区,减少了关键字(相对于B+tree)
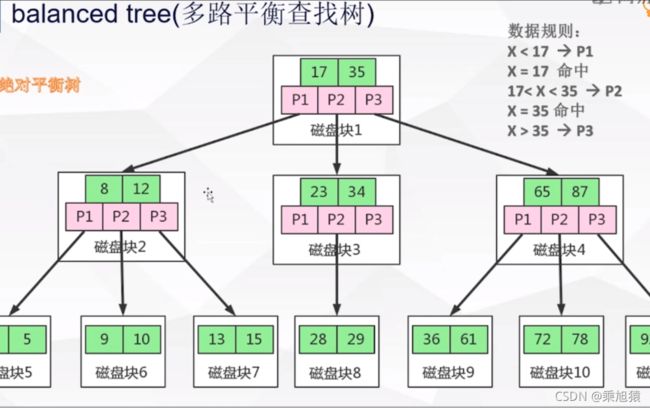
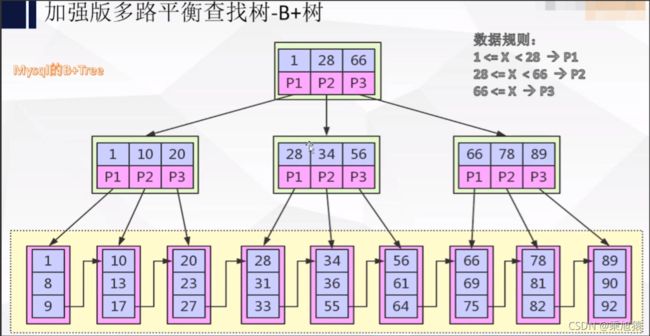
4.B+tree(加强版多路平衡查找树)
原理
新增数据根据所有索引列计算一个hash码,将记录按有序化(递增或递减)排列,采用二分查找,以从左至有原则匹配,满足最左前缀原则
二分查找
二分查找法(binary search) 也称为折半查找法,用来查找一组有序的记录数组中的某一记录。
其基本思想是:将记录按有序化(递增或递减)排列,在查找过程中采用跳跃式方式查找,即先以有序数列的中点位置作为比较对象,如果要找的元素值小于该中点元素,则将待查序列缩小为左半部分,否则为右半部分。
优点:①B+节点关键字搜索采用闭合区间、②B+非叶子节点不保存数据相关信息,只保存关键字和子节点的引用、③B+关键字对应的数据保存在叶子节点中、④B+叶子结点是顺序排列的,并且相邻节点具有顺序引用关系。
增强了扫库,扫表能力、磁盘读写能力、排序能力、查询效率更加稳定。
为什么索引结构默认使用B+Tree,而不是Hash,二叉树,红黑树?
B-tree:因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
Hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
总结
1、MySQL使用B+Tree作为索引数据结构;
2、B+Tree在新增数据时,会根据索引指定列的值对旧的B+Tree做调整;
3、从物理存储结构上说,B-Tree和B+Tree都以页(4K)来划分节点的大小,但是由于B+Tree中中间节点不存储数据,因此B+Tree能够在同样大小的节点中,存储更多的key,提高查找效率;
4、影响MySQL查找性能的主要还是磁盘IO次数,大部分是磁头移动到指定磁道的时间花费;
6、InnoDB存储引擎下索引的实现,(辅助索引)全部是依赖于主索引建立的(辅助索引中叶子结点存储的并不是数据的地址,还是主索引的值,因此,所有依赖于辅助索引的都是先根据辅助索引查到主索引,再根据主索引查数据的地址);
7、由于InnoDB索引的特性,因此如果主索引不是自增的(id作主键),那么每次插入新的数据,都很可能对B+Tree的主索引进行重整,影响性能。因此,尽量以自增id作为InnoDB的主索引。
存储引擎
执行该sql,查询存储引擎SHOW ENGINES
查看表存储引擎:(SHOW TABLE STATUS from 数据库库名 where Name=‘表名’ 或 mysqlshow -u 数据库登录帐号 -p ‘数据库登录帐号密码’ --status 数据库库名 表名)
更改数据库存储引擎:(ALTER TABLE 表名 ENGINE = InnoDB)
InnoDB
目前最广泛、最重要的存储引擎;
场景:支持事务处理,支持外键,支持崩溃修复能力和并发控制。
- 支持事务安全表(ACID)
- 支持行锁定
- 支持外键
MyISAM
基于ISAM存储引擎,并对其进行扩展。拥有较高的插入、查询速度,但不支持事物和外键。
- 静态表(默认):字段都是非变长的(每个记录都是固定长度的)。存储非常迅速、容易缓存,出现故障容易恢复;占用空间通常比动态表多。
- 动态表:占用的空间相对较少,但是频繁的更新删除记录会产生碎片,需要定期执行optimize table或myisamchk -r命令来改善性能,而且出现故障的时候恢复比较困难。
- 压缩表:使用myisampack工具创建,占用非常小的磁盘空间。因为每个记录是被单独压缩的,所以只有非常小的访问开支。
场景:如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。
MERGE
场景:对于服务器日志这种信息,一般常用的存储策略是将数据分成很多表,每个名称与特定的时间端相关。
MEMORY
将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。
默认使用哈希(HASH)索引,其速度比使用B-+Tree型要快,但也可以使用B树型索引,由于数据存于内存中,稳定性不强。
场景:如果需要该数据库中一个用于查询的临时表。
ARCHIVE
归档的意思,在归档之后很多的高级功能就不再支持了,仅仅支持最基本的插入和查询两种功能;
场景:由于高压缩和快速插入的特点Archive非常适合作为日志表的存储引擎,但是前提是不经常对该表进行查询操作。
CSV
使用该引擎的MySQL数据库表会在MySQL安装目录data文件夹中的和该表所在数据库名相同的目录中生成一个.CSV文件(所以,它可以将CSV类型的文件当做表进行处理),这种文件是一种普通文本文件,每个数据行占用一个文本行;
- 不支持索引,无主键列
- 不允许表中字段为null
场景:这种引擎支持从数据库中拷入/拷出CSV文件。如果从电子表格软件输出一个CSV文件,将其存放在MySQL服务器的数据目录中,服务器就能够马上读取相关的CSV文件。同样,如果写数据库到一个CSV表,外部程序也可以立刻读取它。在实现某种类型的日志记录时,CSV表作为一种数据交换格式。
BLACKHOLE(黑洞引擎)
该存储引擎支持事务,而且支持mvcc的行级锁,写入这种引擎表中的任何数据都会消失,主要用于做日志记录或同步归档的中继存储,这个存储引擎除非有特别目的,否则不适合使用。
PERFORMANCE_SCHEMA
主要用于收集数据库服务器性能参数。
- 提供进程等待的详细信息,包括锁、互斥变量、文件信息;
- 保存历史的事件汇总信息,为提供MySQL服务器性能做出详细的判断;
- 对于新增和删除监控事件点都非常容易,并可以随意改变mysql服务器的监控周期。
Federated
该存储引擎可以不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。这种存储引擎非常适合数据库分布式应用;
在本地数据库中访问远程数据库中的数据,针对federated存储引擎表的查询会被发送到远程数据库的表上执行,本地是不存储任何数据的。
缺点:
1.对本地虚拟表的结构修改,并不会修改远程表的结构
2.truncate 命令,会清除远程表数据
3. drop命令只会删除虚拟表,并不会删除远程表
4.不支持 alter table 命令
5. select count(*), select * from limit M, N 等语句执行效率非常低,数据量较大时存在很严重的问题,但是按主键或索引列查询,则很快,如以下查询就非常慢(假设 id 为主索引)
select id from db.tablea where id >100 limit 10 ;
而以下查询就很快:
select id from db.tablea where id >100 and id<150
6. 如果虚拟虚拟表中字段未建立索引,而实体表中为此字段建立了索引,此种情况下,性能也相当差。但是当给虚拟表建立索引后,性能恢复正常。
7. 类似 where name like “str%” limit 1 的查询,即使在 name 列上创建了索引,也会导致查询过慢,是因为federated引擎会将所有满足条件的记录读取到本地,再进行 limit 处理。
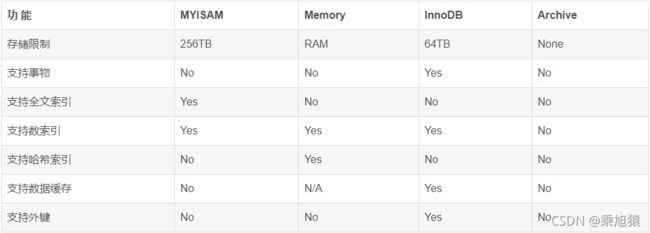
最后谈谈InnoDB 和 MyISAM之间的区别:
InnoDB支持事物,而MyISAM不支持事物
InnoDB支持行级锁,而MyISAM支持表级锁
InnoDB支持MVCC, 而MyISAM不支持
InnoDB支持外键,而MyISAM不支持
InnoDB不支持全文索引,而MyISAM支持。