基于Tensorflow2的YOLOV4 网络结构及代码解析(2)——NECK部分
笔者以tensorflow2代码作为基础,解析yolovV4的网络结构。
继上篇《基于Tensorflow2的YOLOV4 网络结构及代码解析(1)——backbone网络结构》博文后继续解析yoloV4的NECK
本篇博客主要介绍两个个方面:
1.SPPNET:SPP结构使用不同尺度的maxpooling后进行特征图堆叠
2.PANet:模型的neck
feat1, feat2, feat3 = darknet_body(inputs)通过特征提取函数darknet_body获得三组特征图像。维度分别对应:feat1=(52,52,256),feat2=(26,26,512),feat3=(13,13,1024)
SPPNET:
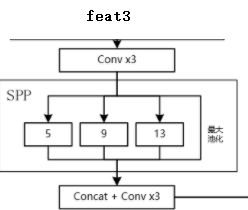
如上图所示,将feat3(13,13,1024)经过三次卷积后传入SPP结构中。
P5 = DarknetConv2D_BN_Leaky(512, (1, 1))(feat3)
P5 = DarknetConv2D_BN_Leaky(1024, (3, 3))(P5)
P5 = DarknetConv2D_BN_Leaky(512, (1, 1))(P5)
maxpool1 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(P5)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(P5)
maxpool3 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(P5)
P5 = Concatenate()([maxpool1, maxpool2, maxpool3, P5])
P5 = DarknetConv2D_BN_Leaky(512, (1, 1))(P5)
P5 = DarknetConv2D_BN_Leaky(1024, (3, 3))(P5)
P5 = DarknetConv2D_BN_Leaky(512, (1, 1))(P5)
其中有几个点值得关注:
1.feat3经过3次卷积后维度变为(13,13,512)。纵览整个网络结构可以发现,大量的使用了1*1 +3*3 +1*1这样的网络结构。不经要问,这样做的好处在哪儿?为什么不直接采用3*3卷积进行降维操作?笔者参考大量文献得到一个相对比较认可的结果。使用这样的网络结构的好处有两点:1.降低网络运算量。如果直接在1024的厚度上做卷积的话,运算量会大很多,因此通过1*1卷积降维至512。2.在feature map尺寸不变的情况下增加非线性特征。
2.经过最大值池化时选用三个不同的尺度,但并不改变特征图尺度,最后将他们拼接后使用1*1卷积降维。SPP结构的初衷是为了保障全连接层输入参数的统一,而yolov4使用SPP结构更多的是为了针对不同大小特征的融合问题。
PANet:

如上图所示,将经过SPP结构的“P5”以及feat1,feat2传入PANet结构中,获取特征的维度为(P3=(52,52,255),P4=(26,26,255),P5=(13,13,255))。最后还需要经过yolohead进行解码以完成最后的目标检测任务。
# 13,13,512 -> 13,13,256 -> 26,26,256
P5_upsample = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(P5)
# 26,26,512 -> 26,26,256
P4 = DarknetConv2D_BN_Leaky(256, (1,1))(feat2)
# 26,26,256 + 26,26,256 -> 26,26,512
P4 = Concatenate()([P4, P5_upsample])
# 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
P4 = make_five_convs(P4,256)
# 26,26,256 -> 26,26,128 -> 52,52,128
P4_upsample = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(P4)
# 52,52,256 -> 52,52,128
P3 = DarknetConv2D_BN_Leaky(128, (1,1))(feat1)
# 52,52,128 + 52,52,128 -> 52,52,256
P3 = Concatenate()([P3, P4_upsample])
# 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
P3 = make_five_convs(P3,128)
P3_output = DarknetConv2D_BN_Leaky(256, (3,3))(P3)
P3_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P3_output)
# 52,52,128 -> 26,26,256
P3_downsample = ZeroPadding2D(((1,0),(1,0)))(P3)
P3_downsample = DarknetConv2D_BN_Leaky(256, (3,3), strides=(2,2))(P3_downsample)
# 26,26,256 + 26,26,256 -> 26,26,512
P4 = Concatenate()([P3_downsample, P4])
# 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
P4 = make_five_convs(P4,256)
P4_output = DarknetConv2D_BN_Leaky(512, (3,3))(P4)
P4_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P4_output)
# 26,26,256 -> 13,13,512
P4_downsample = ZeroPadding2D(((1,0),(1,0)))(P4)
P4_downsample = DarknetConv2D_BN_Leaky(512, (3,3), strides=(2,2))(P4_downsample)
# 13,13,512 + 13,13,512 -> 13,13,1024
P5 = Concatenate()([P4_downsample, P5])
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
P5 = make_five_convs(P5,512)
P5_output = DarknetConv2D_BN_Leaky(1024, (3,3))(P5)
P5_output = DarknetConv2D(num_anchors*(num_classes+5), (1,1))(P5_output)
这部分需要注意的点有:
1.PANet相关的NECK结构:目标检测任务中,NECK部分起到承上启下的作用,它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习。大体上可以分为六种。上下采样:SSD,STDN,路径聚合:DSSD,FPN,PANET,Bi-FPN,NENET,NAS搜索:NAS-FPN,加权聚合:ASFF,非线性聚合:Feature Reconfiguration以及无限堆叠:i-FPN。

yolo使用的是路径聚合中的PANET(其他5种方式,笔者不太了解,不做赘述)。如上图所示,主流NECK的不同连接方式,实际工程中选择哪个neck需要根据测试结果进行判断。
分析PANET可以看出,通过上采样和下采样+5次卷积,将浅层特征与深层特征concatenate达到融合的效果。最后通过3*3和1*1卷积使得输出特征相同(num_anchors*(num_classes+5))=255
2.上采样时使用的算法原理
tf.keras.layers.UpSampling2D(
size=(2, 2), data_format=None, interpolation='nearest', **kwargs
)这个函数最重要的参数是size。代表的意义是在row和col方向上的数组重复几次。源码中size=2,也就是放大一倍。interpolation可选择"nearest"最近邻和“bilinear”算法。但考虑到运算时间,我们一般使用默认的最近邻插值法。
3.这里均采用Leaky激活函数而不是特征提取时使用的Mish激活

leaky激活函数如上图所示,唯一需要注意的是源码中alpha=0.1,而默认的alpha=0.3
完成yolo_body的构建。
self.yolo_model = yolo_body(Input(shape=(None, None, 3)), num_anchors // 3, num_classes)
self.yolo_model.load_weights(self.model_path)至此所有需要加载权值的部分已经全部结束,接下来需要对预测结果进行后处理,包括解码,非极大抑制,门限删选等。
本篇博客均为自己对yoloV4以及tensorflow2的部分理解,如果有错误,欢迎纠正和提出意见。
后续将持续更新
-
YOLOV4的YoloHead
-
YOLOV4的Loss和Input
-
YOLOV4的创新点以及一些tricks
E-mail:[email protected]