前端面试(一)
1.数据类型
有基本数据类型,特点较为简单,所以存储在栈里,有:
Number, String, null, undefined, bool, Symbol
还有引用数据类型,比较复杂,所以放在堆里,但为了能找到,还需在栈里存放它的地址。有:
Function,Object, Array, Date, 正则表达式
栈内存自动释放,堆内存则不会,依靠垃圾回收机制回收,如果不用,最好将使用完的对象设为null
2.闭包
假设有两个函数,F1, F2 F1中包含F2, F1里面还有个变量dog,这个变量被F2引用 最后将F2返回
大概长这样:
function F1() {
var dog;
return function F2() {
console.log(dog);
}
}
然后,这个dog就超脱了。于是如果还有个叫dog的变量,它们不会因为命名而冲突。这个现象可以解决一些问题:比如for循环绑定问题,在没有引入es6的let关键字前,可以依靠闭包解决。什么是for循环绑定问题呢?
for循环绑定问题
假如现在有6个按钮,需要为其添加点击事件,打印0-5.然而每个按钮都只会打印5
for(var i = 0; i < 6; i++) {
arr[i] = function() {
console.log(i);
}
}
arr[]代表6个按钮
怎么用闭包解决?
没思路得话直接写出闭包的样子先
function F1() {
var dog;
return F2() {
console.log(dog);
}
}
//可以将每个i的值用闭包超脱出去,这样每个打印函数都有一个自己的i值了
for(var i = 0; i < 6; i++) {
(function(j) {
arr[j] = function() {
console.log(j);
}
})(i);
}
// 这里还使用了立即执行函数,(function() {} )() 将i的值传内层函数,并且被内层函数引用,返回给了arr[],形成了闭包
单例模式:闭包实现
单例模式的特点:只有一个实例,再次调用生成函数,还是那个实例。单例模式有很多应用:比如全局遮罩层,Vuex, 购物车
比如 a 和 b都是由S()生成,但是它们其实指向同个实例
var a = S();
var b = S();
a === b; // true
S()是生成函数
根据特点:其实现思想应该是当前如果不存在实例,则由生成函数生成,否则直接返回该实例
但是为了让这个实例全局唯一,超脱出来,所以这个实例应该被S()引用,并且外面还应该有个函数,才能形成闭包
var S = function() {
var instance;
function F(name, age) {
manager = {
name: name,
age: age
}
return manager;
}
return S() {
if(!instance) {
instance = new F();
}
return instance;
}
}
F()是instance构造函数
防抖
闭包还可以实现防抖,防抖的应用场景:防止事件多次触发,n秒后再触发,n秒内事件再触发,则重新计时,这样就可以实现在最后稳定的设定时间内再触发事件
function debounce(fn, delay) {
// 根据前面的经验,那么这里需要将哪个变量超脱出去呢
// 很明显,这里应该是定时器,因为该变量很可能需要重新设置
var timeout;
return function() {
// timeout在这里怎么使用呢
// 这是要实现防抖的功能,进入这个函数就说明还在抖,所以如果定时器存在,就应该清除,并且再次设置
if(timeout) clearTimeout(timeout);
timeout = setTimeout(()=> {fn();}, delay)
}
}
浏览器的缓存策略
为什么缓存?当然为了节省服务器资源,减轻其负载压力,还可以让客户端加载资源速度快,因为就在本地嘛,对客户和商家都好。当然缺点也有,缓存的资源可能更新跟不上服务器的。
那么缓存的规则有哪些呢?强缓存和协商缓存。
强缓存是什么?强缓存首先会去查看本地缓存的资源是否过期,如果没有,则去向服务器重新请求。这句话其实比较模糊,没头没尾。所以先了解浏览器缓存的全过程。
1.浏览器第一次向服务器请求资源时,服务器返回200,浏览器将资源下载了在本地进行了缓存,服务器还将一些信息放在response header里面返回给浏览器进行缓存。
2.浏览器第二次请求时,它会先去本地缓存里找,看下本地缓存的资源有没有过期,涉及的参数是 cache-control的属性max-age,就是第一步放在response header里面的,这里其实就是强缓存的过程。然后如果过期,就会开始下一步。
3.浏览器这时会开始协商缓存,也就是带着一些放在request header 里面的信息——If-None-Match和If-Modified-Since,去向服务器请求。
4.服务器收到请求后先根据etag判断资源文件是否被修改。Etag值一致则没有修改,命中协商缓存,则直接返回304和资源文件,否则就返回新资源和200。etag是什么呢,在第一次请求服务器时,服务器根据资源文件计算给的一个值。用来比较资源文件有没有修改。
但是如果服务器收到的请求没有etag,那么就拿If-Modified-Since和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回304;不一致则返回新的last-modified和文件并返回200;
typeof null 的结果是object
这是因为js引擎一开始创建的问题,已经是一个难以修改的bug. 以前的js的数据长度是32位的。拿前3位作为数据类型的标识。000代表的是object,但是null的二进制也是全0.所以判断null是就误判了。
== 和 === 区别
前者是不严格的相等,数据类型相同,则判断大小,数据类型不同,则根据下面判断:
null 和 undefined 相等
String 和 Number 比如 ‘1’ 和 1
Bool 和 Number 比如 true 和 1
后者必须数据类型相同 大小相同
浏览器输入url到页面渲染出来的过程
这个过程涉及的知识比较多,这是肯定的,你只是输入一个url,然后就有个很多内容的页面,这背后不简单。
1.url输入后,回车,然后浏览器先去找这个url相关的缓存【缓存策略】如果是第一次当然没有相关缓存
2.根据url进行DNS域名解析。url只是辅助记忆的东西,但想要找到相应的硬件服务器,那是需要ip才能找到的,所以需要dns域名解析,找该url对应的ip地址
dns解析的过程:递归的一个过程。先找本地域名服务器,没有去找根域名服务器,没有去找顶级域名服务器,找到成功。这里还有个概念:dns负载均衡。什么意思呢?像大公司的服务器肯定不止一个对吧,我们不可能全都挤到一个服务器那里,为了更好的利用服务器资源,提升用户体验,给你提供服务的服务器的距离和当前使用情况都是经过算法计算的,更加适合你。
3.发起tcp请求,建立tcp链接。tcp链接是你与服务器之间通信的通道。其过程就是三次握手。具体过程如下:
1.第一次握手:客户端发生syn包(Seq=x),并进入SYN_SEND状态,等待服务器确认
2.第二次握手:服务器接收客户端的SYN包,并且需要确认syn包(ack=x+1),且服务器会发送一个自己的syn包(Seq=y),即是向客户端发送两个包:ACK包+SYN包 前者是对客户端的syn包的确认 后者是自己的syn包,服务器进入SYN_RECV状态
3.第三次握手:客户端接收服务器发送的ACK包和SYN包,前者说明服务器收到了自己之前发送的syn包,后者是服务器发来的syn包,需要客户端确认该syn包(ack=y+1),并且将确认后的ACK包发送给服务器,此包发送完毕双方进入ESTABLISHED状态。
三次握手过程中不包含数据的传输,而且理想情况下,除非一方主动断开链接,否则一直保持链接
所以SYN是什么,ACK是什么。这和tcp报文有关。
通信的过程需要约定一些规则那就是通信协议。报文就是一些设定的标识数据。TCP链接提供面向链接的,可靠数据流的服务。
在这里插入图片描述
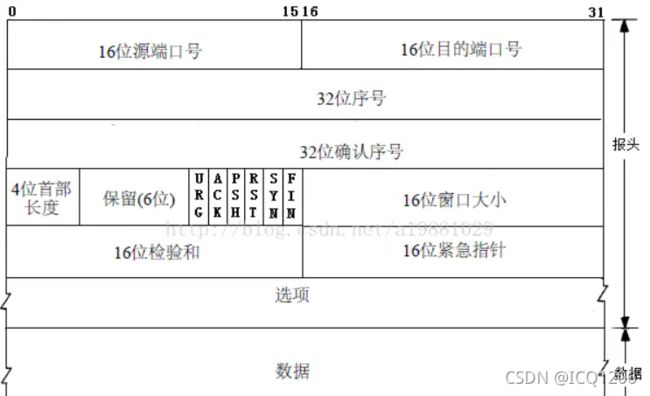
上图解析:
16位源端口号:16位即是两个字节,源端口号和IP标记报文的返回地址。IP锁定客户端的位置,源端口号锁定哪个应用程序接收报文
16位目的端口号:指定服务器哪个应用程序接收
序号:TCP传送的流中,每一个字节都有一个序号。比如一个报文段的序号为300,报文段数据部分共有100字节,则下一个报文段的序号为400。所以序号确保了TCP传输的有序性。
确认号:即ACK,指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
首部长度/数据偏移:占4位,它指出TCP报文的数据距离TCP报文段的起始处有多远。由于首部可能含有可选项内容,因此TCP报头的长度是不确定的,报头不包含任何任选字段则长度为20字节,4位首部长度字段所能表示的最大值为1111,转化为10进制为15,15*32/8=60,故报头最大长度为60字节。首部长度也叫数据偏移,是因为首部长度实际上指示了数据区在报文段中的起始偏移值。
控制位:URG ACK PSH RST SYN FIN,共6个,每一个标志位表示一个控制功能。
确认ACK:仅当ACK=1时,确认号字段才有效。TCP规定,在连接建立后所有报文的传输都必须把ACK置1
同步SYN:在连接建立时用来同步序号。当SYN=1,ACK=0,表明是连接请求报文,若同意连接,则响应报文中应该使SYN=1,ACK=1
窗口:滑动窗口大小,用来告知发送端接受端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。窗口大小时一个16bit字段,因而窗口大小最大为65535
校验和:奇偶校验,此校验和是对整个的 TCP 报文段,包括 TCP 头部和 TCP 数据,以 16 位字进行计算所得。由发送端计算和存储,并由接收端进行验证。
那么两次握手可以吗?不行,假如A【客户端】发了连接请求给B【服务器】,但是由于网络延迟,A收不到B的确认包,所以又发了一个连接请求。B同意了第二次的请求,A也同意了,这就建立了tcp连接。但是如果这时A的第一次请求经历八十一难终于到了B这里,B确认了,却迟迟等不到A的再次确认,因为A的目的已经达到了,第一次的请求早就被放弃了。这样就会让服务器一直在等待。消耗服务器资源。
那么四次握手呢?通信中有个红蓝军的故事。这个故事告诉我们,通信没有100可靠性。再加一次握手不能显著提高可靠性,没必要。
四次挥手
第一次挥手:客户端发送一个FIN,用来关闭客户端到服务器的数据传送,也就是客户端告诉服务器:我已经不会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,客户端依然会重发这些数据),但是,此时客户端还可以接受数据。
FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
第二次挥手:服务器收到FIN包后,发送一个ACK给对方并且带上自己的序列号seq,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)。此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
第三次挥手:服务器发送一个FIN,用来关闭服务器到客户端的数据传送,也就是告诉客户端,我的数据也发送完了,不会再给你发数据了。由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
注意点:客户端需要等待2MSL,才彻底关闭
为什么?1.保证最后一个客户端发送的ACK报文能被服务器接收。假如这个ACK报文不见了【第四次挥手时客户端发送的ack】,那么服务器它看不见你客户端的最后确认,在此之前服务器已经发了fin【第二次挥手】和ack【第三次挥手】,所以服务器认为客户端是因为收不到我发的fin和ack,所以就会重发这个报文。而客户端就可以在这个2msl时间内再次接收。并给出最后的ack确认【第四次挥手】,当然2msl重新计时。
为什么是三次握手,四次挥手。从四次挥手的过程中可以看出,第二次挥手仅发送一个fin包,第三次发了ack包。而在握手时,它们是一起发的。所以多了一次挥手。
回到正题:建立了tcp连接后的事
4.客户端发起http请求
tcp处于五层模型的传输层,它是为了通信而建立的。而http处于传输层的上层应用层,传输的是数据,按照http协议的格式来传输。打个比喻。tcp相当于拨通了电话给你的朋友,而http是你们的聊天内容,只不过,这个聊天内容得遵守http协议规定的格式。那么格式是什么?
发送http请求,其实就是构建http请求报文。报文通过tcp连接发送到对方的指定端口。
http请求报文的组成:请求行、请求头、请求正文
请求行:Method Request-URL HTTP-Version CRLF eg: GET index.html HTTP/1.1
这里面需要注意请求方法GET
请求方法GET和POST的重要区别:GET请求只会发送一个tcp包:包含请求头和数据 但POST请求会发两个tcp包,第一次发请求头 ,第二次发数据 【火狐浏览器POST只发一个tcp包】
还有其他区别,比如安全性,GET请求参数是可见的,比如GET请求会被自动缓存而POST不会
5.服务器响应请求
服务器【指硬件】对http request对象进一步封装,一般这个工作由web服务器【一个具有服务功能的程序】完成。
web服务器有:Apache Tomcat Nginx
服务器响应的报文组成:状态码 ,响应报头和响应报文
1开头的:服务器已经接收请求,继续处理中
2开头的:客户端请求已成功,资源返回成功
3开头的:需要进一步请求
4开头的:客户端方面请求错误语法什么的
5开头的:服务器端错误
常见状态码:200成功 301永久移动 302临时移动 304未修改 401未授权 403禁止 404未找到 500服务器错误
我们需要的资源就在响应报文这里
然而拿到数据,这还没完,数据只是数据,但是我们看到的却是一个页面。这就是浏览器要完成的工作了,渲染。
浏览器渲染页面
千辛万苦终于拿到了数据,然而还有很多问题。浏览器是怎么将这些数据渲染出了页面的。
下面介绍webkit的工作流程。【webkit是浏览器内核,出了webkit还有其他,比如IE的Trident,火狐的GEcko,浏览器内核就是渲染引擎,包括排版渲染【html,css],javascript引擎等】
1.html解析器解析html文档,得到html dom 树
2.css解析器解析css样式,得到css 样式树
3.合并两树,计算布局,调用操作系统的绘制api进行绘制。【这里需要大量计算,所以优化这里的性能很重要,如css资源可以设置link里面的preload属性,js资源异步加载或者开新的线程,这些都是首次问题,不要太拉跨就行,千万不能超过10秒,不然基本上用户没了兴趣】
两个概念:回流与重绘
首次加载必然遇到这两个问题,首次加载这里需要优化。然而,你想想,如果,某些骚操作使得浏览器需要不断进行计算渲染,那浏览器得多难受。回流就是当Render Tree中部分或全部元素的尺寸、结构、或某些属性发生改变时,浏览器重新渲染部分或全部文档的过程称为回流。重绘就是当页面中元素样式的改变并不影响它在文档流中的位置时(例如:color、background-color、visibility等),浏览器会将新样式赋予给元素并重新绘制它,这个过程称为重绘。这两个过程都需要大量计算。所以能避免就避免。提高性能。
导致回流的操作有哪些呢:
1.页面首次渲染
2.浏览器窗口发生变化
3.元素尺寸改变或属性改变
4.元素内容改变
5.字体大小改变
6.添加或删除可见dom结点
7.激活伪类
8.查询某些属性或调用某些方法
css优化:
避免使用table布局。
尽可能在DOM树的最末端改变class。
避免设置多层内联样式。
将动画效果应用到position属性为absolute或fixed的元素上。
避免使用CSS表达式(例如:calc())。