数据仓库4.0
仅用于自己学习
数据流程设计

搭建
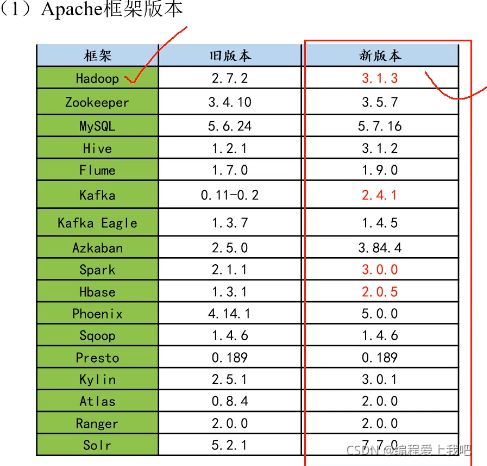
版本选择
Apache :运维麻烦,组件间兼容性需要自己调研
CDH: 国内使用最多的版本,6.32之前免费,从2021年开始收费。 1个节点1万美元
云服务选择
阿里云的EMR(不用搭建平台和考虑兼容性问题),MaxCompute, DataWorks
亚马逊云的EMR
腾讯云EMR
华为云EMR(市场份额少)
物理机和云主机选择
集群规模
计算例子 用户100万,每个用户平均100条数据,每条日志1k左右,
每天100w1001000/1024/1024约等于100G
如果1年不扩充服务器的话100G360约等于36T
保存3个副本 36T3=108T
预留30%的空间 108%0.7= 144T
还要考虑数仓分层和数据压缩
有了物理机如何分配搭建规则
(1) 消耗内存的分开(比如说namenode和ResourceManager)
(2)数据传输比较紧密的放在一起 (比如说zk和kafka)
(3) 客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(hive和Azkaban)
测试集群
目标数据
页面数据,事件数据,曝光数据,启动数据,错误数据
登录shell和非登录Shell的区别
如果登录shell通过账户密码 他会从新加载/etc/profile ~/.bash_profile ~/.bashrc 如果是非登录shell,通过ssh,只会加载 ~/.bashrc的数据,所以要把配置文件/etc/profile/放到 ~./bashrc里边 。
hdfs数据均衡
节点间数据均衡
开启数据均衡命令
start-balancer.sh -threshould 10
使每个节点之间磁盘空间利用率不超过10%
stop-balancer.sh
磁盘间数据均衡
生成均衡计划
hdfs diskbalancer -plan hadoop103
执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
查看当前执行情况
hdfs diskbalancer -query hadoop103
取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
lzo压缩
1下载插件
2在core.site中配置
3 命令行带参数开启
4 对lzo文件建立索引
基准测试
调优
Jvm重用 合并小文件 数据倾斜 io阻塞 网络异常 调整nodeManager 的内存和核数
kafka
producer
设置batch.size(数据量多大发一次) 和linger.ms(多少秒发一次) 要更改成最适合项目的
consumer
增大fetch的大小
分区数的设置
期望100M/s 100/min(producer,consumer)=分区数
flume
- 配置组件
- source
- channel
- sink
- 拼接组件
source
exec: 好处 可以实时监控文件变化
坏处 网络断掉或者其他问题,这个时间段的数据会丢失。
spooling: 监控的是文件夹。好处 可以实现断点续传 坏处 不能实时监控文件变化
taildir: 断点续传,可以实时监控文件变化
channel
file :数据存储在磁盘中,可靠性高
memory channel : 数据存储在内存中
kafka channel : 数据存储在kafka中,所以存储在磁盘中,存储效率高 (1.6的时候,由于传输的flume数据(head,body),设置参数不起作用所以没有火)
interceptor过滤器
用法:1在idea中编写一个类继承interceptor并写一个类继承builder
2打包放到flume的lib目录下
3在配置文件中 配置interceptor
零点漂移问题
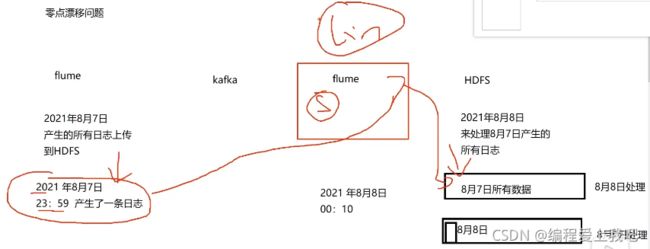 解决方法,flume在存储的时候按照日志时间而不是系统时间
解决方法,flume在存储的时候按照日志时间而不是系统时间
sink HDFS
最好配置合并小文件的参数(如下),否则会生成特别多的小文件,影响读取性能和浪费namenode的资源
hdfs.rollInterval 30
hdfs.rollSize 1024
hdfs.rollCount
flume调优
在env.sh文件里配置吞吐量,默认是2000M,实际生产中要尽量调大
电商常识
SPU(standard product unit)商品信息聚合的最小单位
SKU (stock keeping unit)库存量基本单位
例如 iphone 手机就是spu,sku就是白色,128G
Sqoop
底层是mapreduce,但是没有reduce阶段
数据集市
数据集市是一个微型数据仓库
命名规范
表命名
ODS层 ods_表名
DWD dwd_表名
脚本命名
数据源_to_目标_db/log.sh
用户行为脚本以log后缀,业务数据脚本以db为后缀
表字段类型
数量类型 bigint
金额类型 decimal(16,2) 16位有效数字,其中小数部分2位
字符串类型为string
主键外键类型string
时间戳类型为bigint
范式
满足三范式其实就是为了消除数据冗余
函数依赖
完全函数依赖 z=f(x,y) z完全依赖于x,y
部分函数依赖
传递函数依赖
第一范式
属性不可拆分 比如5台电脑 就不符合
第二范式
不能存在部分函数依赖
第三范式
不能存在传递函数依赖
关系模型
因为严格遵循三范式,所以不适合大数据查询
维度模型
存在数据冗余
维度表
事实表{
事务型事实表:适用于不变的数据,周期型快照事实表(每天全量一个快照),累积型快照事实表
}
星型模型,雪花模型
HIve
hive on spark hive做存储和sql优化,spark做算法
spark on hive spark做sql优化,hive只做存储
yarn配置
公平调度器
容量调度器(默认)
fifo调度器
ODS
日志数据通过flume采集logfile里边放入到hive
业务数据sqoop到hdfs,然后放入到hive
create database gmall
drop table if exists ods_log
Create EXTERNAL table ods_log ('line' string)
partitioned by ('dt' string)
stored as
inputformat 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
outputformat
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location '/warehouse/gmall/ods/ods_log';
outputformat对load写入没用 只对insert有用;
outputformat是写入 读数据是inputformat
load data inpath '/路径' into table ods_log partition(dt_'2020-06-14')
//创建索引
hadoop jar hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.Distribute
#!bin/bash
#定义变量方便修改
App=gmall
if[-n '$1'];then
do_date=$1
else
do_date='date -d "-1 day" +%F'
fi
sql='load data inpath $App/$do_date into table ${App}.ods_log partition(dt='$do_date')'
hive -e '$sql'
DIM
维度表的整合
Array(struct)类型
select sku_id
collect_set(named_struct('ar',attr_id,'value_id',value_id))
from ods_sku_attr_value
where dt='2020-06-14'
group by sku_id
如果读取的表是lzo文件,并且创建了lzo索引,这时候需要关闭map端的小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat
否则会把lzo和index文件合并
create table a(
'id' String comment'id'
) comment'时间维度表'
stored as parquet
location '/warehouse/gmall'
TBLPROPERTIES("parquet.compression"="lzo")
导入的文件必须是lzo文件,但是insert into table select * from table2 可以不用lzo压缩
拉链表
更加高效的存储历史状态,减少数据冗余
如何使用拉链表,(例如用户表)多设置个开始时间和结束时间,结束时间要的最新值要9999-99-99 方便与查询。
日志
第一:公共字段 设备信息,用户信息
第二:动作数组
第三 :曝光数组
第四:页面类型
第五: 错误信息
第六:启动日志
UDTF
打包后放到集群和hdfs上,然后运行create function
object inspector 对象检查器
执行hive过程中数据放到operator try中,数据类型放入到object inspector,
首先继承GenericUDTF
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
/**
* GenericUDTFCount2 outputs the number of rows seen, twice. It's output twice
* to test outputting of rows on close with lateral view.
*
*/
public class GenericUDTFCount2 extends GenericUDTF {
@Override
public void close() throws HiveException {
}
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
if(argOIs.length!=1)
{throw new UDFArgumentException("explode_json_array函数只能接收1个参数")}
ObjectInspetor arg01=argOIs[0];
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("col1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
count = Integer.valueOf(count.intValue() + 1);
}
}
Azkaban部署
常见的调度器(Oozie(在CDH集群上HUE页面可视化),Azkaban(轻量级),Airflow(python编写),DolphinScheduler(有可视化页面比较火))
下载后的安装包分为三个
executor,web,script 把script的脚本导入mysql数据库中,然后运行executor,激活executor
在配置文件properties-user里边配置用户和角色
案例
简单案例:
<- 第一步
新建两个文件
azkaban.project 作用:标识azkanban版本
azkaban-flow-version: 2.0
frist.flow
nodes:
- name: jobA
type: command
config:
command: echo "Hello World"
<- 第二步 将这两个包打包 upload到web页面
<- 第三步 把jar包打包放进去
也可以把jar包放进去,然后写flow配置文件配置他的路径
正常案列:
传入的是jar包
nodes:
- name:joba
type: javaprocess
config:
Xms: 96M
Xmx: 200M
java.class: com.atguigu.AzTest
classPath: /opt/azkanban/lib
- name:jobb
type: command
config:
command:echo "aa"
- name:jobc
type: command
dependsOn:
-jobA
-jobB
config:
command:echo "aa"
retries: 3
retry.backoff: 10000
传入的是脚本并且用到了上一个条件定义的变量
jobA
jobB
#!/bin/bash
echo "do jobA"
wk='date + %w'
echo "{\'wk\':$wk}" > $JOB_OUTPUT_PROP_FILE
jobA和jobB都是脚本文件,用jobA的条件去出发jobB
nodes:
- name:jobA
type: command
config:
command: sh jobA.sh
- name:jobB
type: command
dependsOn:
- jobA
config:
command: sh jobB.sh
condition: ${jobA:wk} == 1
预定义宏案列
预定义宏
all_success 父job全成功才执行(默认)
all_done 父job全部执行完才执行
all_failed 父job全部失败才执行
one_failed 父job至少有一个失败才执行
one_success 父job至少有一个成功才执行
nodes:
- name:jobA
type: command
config:
command: sh jobA.sh
- name:jobB
type: command
config:
command: sh jobB.sh
- name:jobC
type: command
dependsOn:
- jobA
- jobB
config:
command: sh jobB.sh
condition: one_success
定时执行
cron 表达式
点击web页面的左下角 shedule
*表示anyvalue
,表示切分
-表示i区域
/ 表示 step value */2 每两分钟执行一次
邮件报警案列
1 开启邮箱协议
 开启POP3/SMTP协议 ,如果使用第三方想要用这个邮箱,需要开启这个协议。得到第三方授权码
开启POP3/SMTP协议 ,如果使用第三方想要用这个邮箱,需要开启这个协议。得到第三方授权码
2 在azkaban中配置邮箱
配置文件azkaban.properties
 重启 start-web.sh
重启 start-web.sh
3 配置发送邮箱
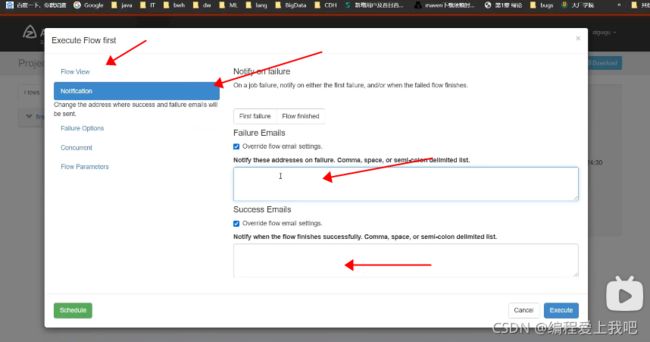
电子电话报警案例
第三方告警平台集成
睿象云
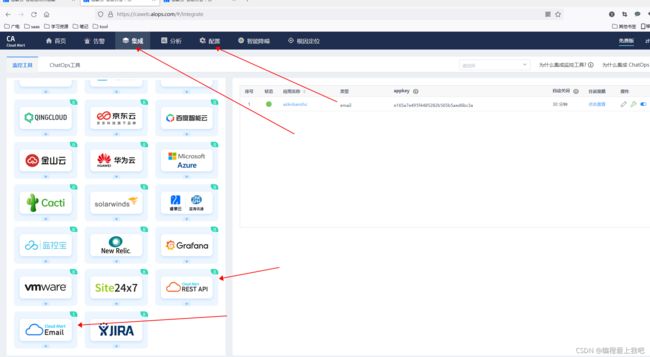 配置一个和emall的集成会生成一个邮箱,这时候在执行azkaban的时候,把生成的那个邮箱写进去就可以,(原理是,报警发送给这个邮箱,就会有电话通知)然后再编写个通知人,注意:azkaban.properties里边配置的发送邮箱不能是qq邮箱,qq邮箱不能够给睿象云邮箱发邮件,这里建议用126邮箱。
配置一个和emall的集成会生成一个邮箱,这时候在执行azkaban的时候,把生成的那个邮箱写进去就可以,(原理是,报警发送给这个邮箱,就会有电话通知)然后再编写个通知人,注意:azkaban.properties里边配置的发送邮箱不能是qq邮箱,qq邮箱不能够给睿象云邮箱发邮件,这里建议用126邮箱。
azkaban多Executor模式注意事项
如果运行的脚本或者类没有部署到个别Executor,那么这个Executor将不能够执行
解决方法:
第一种方法:指定特定excutor
首先在mysql 的excutor表 找到要执行的executor的id,然后在web页面中配置USEExcutor id
第二种方法:所有executor都添加脚本或者要执行的类
Superset
https://www.jianshu.com/p/b02fcea7eb5b
能够对接多种数据源,支持自定义仪表盘,并拥有十分友好的用户界面。简单来说就是把mysql的数据直接以图片的形式展现在前端。
安装
第一步:用conda自由的切换python环境
python语言编写,先安装python环境,python3.7以上
yum 依赖python,
conda是一个开源的包,能够切换不同的python包
conda环境管理常用命令
创建环境 : conda create -n env_name
查看所有环境: conda info --envs
删除一个环境: conda remove -n env_name --all
激活superset环境 conda activate base
退出环境: conda deactivate
创建python环境 conda create --name 名字 python=3.7
和上边 “ 创建环境 ” 是一个东西
pip是python的包管理工具,类似于centos的yum
第二步 安装supeset
第三步 创建superset数据库和管理员用户
第四步 安装gunicorn是一个python web server 类似于java的tomcat
第五步 对接数据源mysql
使用
下载mysql驱动
然后用可视化页面连接数据库,用dataset来连接表
用Dashboards创建仪表盘
既席查询
根据用户的选择来查询数据。
例如presto 或者ktlin
Kylin
分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及OLAP能力以支持超大规模数据,最初由eBay(购物)开发,里边的 中国团队 开发。在亚秒内查询巨大的HIve表
基本原理
就是把所有的查询情况都查出来了,所以才是亚秒级别。
OLAP
从多维度观察数据,对预计算提供基础。
简单理解:olap就是包不同的列的组装起来了,方便于查询的时候更快。
ROLAP 不需要进行预计算 都在一个表中。
MOLAP 需要进行预计算,为了保存一个表中的数据,预先聚合多个cube 每个cube里边存储的是维度。
架构

可以对接的数据源
hadoop hive(离线) kafka(实时) RDBMS
数据存储用hbase
补充知识点:Hbase对海量数据进行随机读写
(Hbase底层也是hdfs,为啥他可以随机呢,从写角度来说,它是先追加上,然后才合并,从写的角度来说,从读的角度来说,它是设置了rowkey并且rowkey有序)
HDFS对海量数据进行批量读写。
安装
前期 安装hadoop (yarn hdfs historyserver(必须启动,在后续配置cube的过程中,它是观察历史服务器来判断的))
启动kylin
使用
页面上添加hive表后,***kylin不能处理HIve表中的复杂数据类型例如(Array 和 struct),***即便复杂类型的字段并未参与到计算之中,所以在加载hive数据源时,不能直接加载带有复杂数据类型字段的表。
解决方法:
第一种:创建临时表,临时表不带那两个复杂的数据
第二种:创建视图


new model 告诉kylin 哪些是事实表,哪些是维度表,把这些表关联起来。
new Cube 告诉kylin 哪些维度计算参与计算。
KylinCube构建原理
维度和度量
Cube和Cubeid
存储原理存储于hbase
把每个维度表转换成维度字典
rowkey就是cuboid+字典里的值的拼接 value值就是度量值
CUBE降维构建算法
先计算高维的数据,然后通过降维聚合。
cube优化
两方面 计算,查询
衍生维度优化的是计算 : 选择衍生维度的话,该维度是不会参与到最终的计算当中,参与的是事实表相对应的字段 这就导致了影响后边查询的速度。
rowkey优化(查询)
被用作过滤查询的维度放到前面
基数大的向前调整,基数小的向后调整。
JDBC接口
zepplin
和superset差不多的一个工具
Presto
presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景。
架构
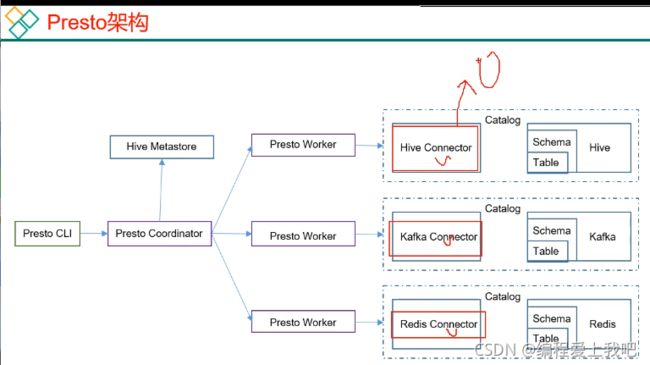 优点: 1) Presto基于内存计算,减少了硬盘IO,计算更快。
优点: 1) Presto基于内存计算,减少了硬盘IO,计算更快。
2) 能够连续多个数据源,跨数据源连查表,如从Hive查询大量网站访问记录,然后从Mysql中匹配出设备信息。
缺点:边读数据边计算,再清内存,碰到跨数据源join速度太慢
集群监控Zabbix
监控各种网络参数以及服务器健康性和完整性的软件,Zabbix使用灵活的通知机制,允许用户为几乎任何事件基于邮件的告警。
说白了三个功能: 监控,报警,页面
基础架构

使用
创建主机
给每台主机创建监控项
创建触发器
配置action 可以发送通知和执行脚本
集成Granfana 展示Zabbix中的监控项
KerberoS
一个网络认证协议
安全
1认证 2授权
术语
KDC(key distribute Center) 密钥分发中心,存储用户信息,管理发放票据
Realm kerberos所管理的一个领域
Rincipal kerberos 所管理的一个用户或者一个服务,指一个账号。 primary/instance@realm
keytab kerberos中的用户认证,可通过密码或者密钥文件证明身份,keytab指密钥文件。