【尚硅谷】电商数仓V4.0丨大数据数据仓库项目实战【学习记录】第二节
注意
多表关联必须选择 不为null的值进行关联
需要函数: nvl coalesce
不使用的全外联的优化方法(全为数字类型的表可以这样做):
将字段补零,union,然后分组聚合
电商数据仓库系统
第6章 数仓搭建-DWD层
启动日志表–对应一个启动日志
页面日志表–对应一个页面埋点日志
动作日志表–在一个页面埋点日志会有多个动作
一行数据是一个动作,所以就需要一进多出的操作,UDTF函数
6.1.5 动作日志表装载中定义UDTF函数
动作日志解析思路:动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含action字段的日志过滤出来,然后通过UDTF函数,将action数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每43个字段。

DeveloperGuide UDTF
package com.atguigu.hive.udtf;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;
import org.json.JSONArray;
/**
* GenericUDTFCount2 outputs the number of rows seen, twice. It's output twice
* to test outputting of rows on close with lateral view.
*
*/
public class ExplodeJOSNArray extends GenericUDTF {
// 为了在 process 中能拿到 initialize传入的数据的ObjectInspector 来声明对象
private PrimitiveObjectInspector inputOI;
@Override
public void close() throws HiveException {
}
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
// 第一个功能 校验UDTF输入参数的合法性
if( argOIs.length!=1){
throw new UDFArgumentException("explode_json_array函数只能接收1一个参数");
}
ObjectInspector argOI = argOIs[0];
// 先判断是否是基本数据类型
if(argOI.getCategory()==ObjectInspector.Category.PRIMITIVE){
throw new UDFArgumentException("explode_json_array函数只能接收基本数据类型的参数");
}
// 强转为 PrimitiveObjectInspector类型
PrimitiveObjectInspector primitiveOI = (PrimitiveObjectInspector) argOI;
inputOI=primitiveOI;
// 判断是否是PrimitiveObjectInspector的STRING类型
if(primitiveOI.getPrimitiveCategory()==PrimitiveObjectInspector.PrimitiveCategory.STRING){
throw new UDFArgumentException("explode_json_array函数只能接收STRING类型的参数");
}
// 第二个功能 定义输出格式 列名和对象检查器
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("item");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,
fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
// 处理数据的逻辑
// 数据保存在Object中
// 数据类型保存在 ObjectInspector 中
Object arg = args[0];
// 从object中获取string类型的数据
String jsonArrayStr = PrimitiveObjectInspectorUtils.getString(arg, inputOI);
JSONArray jsonArray = new JSONArray(jsonArrayStr);
for (int i = 0; i < jsonArray.length(); i++) {
String json = jsonArray.getString(i);
String[] result = {json};
// initialize的输出是结构体,可能存在多列,因此要以 数组的形式返回
forward(result);
}
}
}
4)创建函数
(1)打包
(2)将hivefunction-1.0-SNAPSHOT.jar上传到hadoop102的/opt/module,然后再将该jar包上传到HDFS的/user/hive/jars路径下
[atguigu@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars
[atguigu@hadoop102 module]$ hadoop fs -put hivefunction-1.0-SNAPSHOT.jar /user/hive/jars
(3)创建永久函数与开发好的java class关联
hive (gmall)>create function explode_json_array as 'com.atguigu.hive.udtf.ExplodeJOSNArray' using jar 'hdfs://hadoop102:8020/user/hive/jars/hivefunction-1.0-SNAPSHOT.jar';
hive (gmall)> show functions like "*json*"
(4)注意:如果修改了自定义函数重新生成jar包怎么处理?只需要替换HDFS路径上的旧jar包,然后重启Hive客户端即可。
6.2.6 优惠券领用事实表(累积型快照事实表)
按天进行分区(未完成的放在9999-99-99分区)


-- 建表语句
DROP TABLE IF EXISTS dwd_coupon_use;
CREATE EXTERNAL TABLE dwd_coupon_use
(
`id` STRING COMMENT '编号',
`coupon_id` STRING COMMENT '优惠券ID',
`user_id` STRING COMMENT 'userid',
`order_id` STRING COMMENT '订单id',
`coupon_status` STRING COMMENT '优惠券状态',
`get_time` STRING COMMENT '领取时间',
`using_time` STRING COMMENT '使用时间(下单)',
`used_time` STRING COMMENT '使用时间(支付)',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券领用事实表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dwd/dwd_coupon_use/'
TBLPROPERTIES ("parquet.compression" = "lzo");
–首日装载
insert overwrite table dwd_coupon_use partition(dt)
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time,
coalesce(date_format(used_time,'yyyy-MM-dd'),date_format(expire_time,'yyyy-MM-dd'),'9999-99-99')
from ods_coupon_use
where dt='2020-06-14';
coalesce增强版nvl,
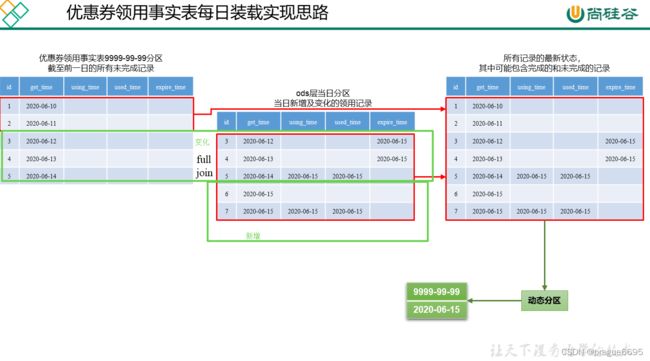
insert overwrite table dwd_coupon_use partition(dt)
select
nvl(new.id,old.id),
nvl(new.coupon_id,old.coupon_id),
nvl(new.user_id,old.user_id),
nvl(new.order_id,old.order_id),
nvl(new.coupon_status,old.coupon_status),
nvl(new.get_time,old.get_time),
nvl(new.using_time,old.using_time),
nvl(new.used_time,old.used_time),
nvl(new.expire_time,old.expire_time),
coalesce(date_format(nvl(new.used_time,old.used_time),'yyyy-MM-dd'),date_format(nvl(new.expire_time,old.expire_time),'yyyy-MM-dd'),'9999-99-99')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from dwd_coupon_use
where dt='9999-99-99'
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from ods_coupon_use
where dt='2020-06-15'
)new
on old.id=new.id;
6.2.9 订单事实表(累积型快照事实表)
select order_id,
str_to_map(concat_ws(",",collect_set(concat(order_status,"=",operate_time))),",",'=')
from ods_order_status_log
where dt = '2020-06-14'
group by order_id
6.2.11 DWD层业务数据每日装载脚本
#!/bin/bash
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$2" ] ;then
do_date=$2
else
do_date=`date -d "-1 day" +%F`
fi
# 假设某累积型快照事实表,某天所有的业务记录全部完成,则会导致9999-99-99分区的数据未被覆盖,从而导致数据重复,该函数根据9999-99-99分区的数据的末次修改时间判断其是否被覆盖了,如果未被覆盖,就手动清理
clear_data(){
current_date=`date +%F`
current_date_timestamp=`date -d "$current_date" +%s`
last_modified_date=`hadoop fs -ls /warehouse/gmall/dwd/$1 | grep '9999-99-99' | awk '{print $6}'`
last_modified_date_timestamp=`date -d "$last_modified_date" +%s`
if [[ $last_modified_date_timestamp -lt $current_date_timestamp ]]; then
echo "clear table $1 partition(dt=9999-99-99)"
hadoop fs -rm -r -f /warehouse/gmall/dwd/$1/dt=9999-99-99/*
fi
}
dwd_order_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table ${APP}.dwd_order_info partition(dt)
select
nvl(new.id,old.id),
nvl(new.order_status,old.order_status),
nvl(new.user_id,old.user_id),
nvl(new.province_id,old.province_id),
nvl(new.payment_way,old.payment_way),
nvl(new.delivery_address,old.delivery_address),
nvl(new.out_trade_no,old.out_trade_no),
nvl(new.tracking_no,old.tracking_no),
nvl(new.create_time,old.create_time),
nvl(new.payment_time,old.payment_time),
nvl(new.cancel_time,old.cancel_time),
nvl(new.finish_time,old.finish_time),
nvl(new.refund_time,old.refund_time),
nvl(new.refund_finish_time,old.refund_finish_time),
nvl(new.expire_time,old.expire_time),
nvl(new.feight_fee,old.feight_fee),
nvl(new.feight_fee_reduce,old.feight_fee_reduce),
nvl(new.activity_reduce_amount,old.activity_reduce_amount),
nvl(new.coupon_reduce_amount,old.coupon_reduce_amount),
nvl(new.original_amount,old.original_amount),
nvl(new.final_amount,old.final_amount),
case
when new.cancel_time is not null then date_format(new.cancel_time,'yyyy-MM-dd')
when new.finish_time is not null and date_add(date_format(new.finish_time,'yyyy-MM-dd'),7)='$do_date' and new.refund_time is null then '$do_date'
when new.refund_finish_time is not null then date_format(new.refund_finish_time,'yyyy-MM-dd')
when new.expire_time is not null then date_format(new.expire_time,'yyyy-MM-dd')
else '9999-99-99'
end
from
(
select
id,
order_status,
user_id,
province_id,
payment_way,
delivery_address,
out_trade_no,
tracking_no,
create_time,
payment_time,
cancel_time,
finish_time,
refund_time,
refund_finish_time,
expire_time,
feight_fee,
feight_fee_reduce,
activity_reduce_amount,
coupon_reduce_amount,
original_amount,
final_amount
from ${APP}.dwd_order_info
where dt='9999-99-99'
)old
full outer join
(
select
oi.id,
oi.order_status,
oi.user_id,
oi.province_id,
oi.payment_way,
oi.delivery_address,
oi.out_trade_no,
oi.tracking_no,
oi.create_time,
times.ts['1002'] payment_time,
times.ts['1003'] cancel_time,
times.ts['1004'] finish_time,
times.ts['1005'] refund_time,
times.ts['1006'] refund_finish_time,
oi.expire_time,
feight_fee,
feight_fee_reduce,
activity_reduce_amount,
coupon_reduce_amount,
original_amount,
final_amount
from
(
select
*
from ${APP}.ods_order_info
where dt='$do_date'
)oi
left join
(
select
order_id,
str_to_map(concat_ws(',',collect_set(concat(order_status,'=',operate_time))),',','=') ts
from ${APP}.ods_order_status_log
where dt='$do_date'
group by order_id
)times
on oi.id=times.order_id
)new
on old.id=new.id;"
dwd_order_detail="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_order_detail partition(dt='$do_date')
select
od.id,
od.order_id,
oi.user_id,
od.sku_id,
oi.province_id,
oda.activity_id,
oda.activity_rule_id,
odc.coupon_id,
od.create_time,
od.source_type,
od.source_id,
od.sku_num,
od.order_price*od.sku_num,
od.split_activity_amount,
od.split_coupon_amount,
od.split_final_amount
from
(
select
*
from ${APP}.ods_order_detail
where dt='$do_date'
)od
left join
(
select
id,
user_id,
province_id
from ${APP}.ods_order_info
where dt='$do_date'
)oi
on od.order_id=oi.id
left join
(
select
order_detail_id,
activity_id,
activity_rule_id
from ${APP}.ods_order_detail_activity
where dt='$do_date'
)oda
on od.id=oda.order_detail_id
left join
(
select
order_detail_id,
coupon_id
from ${APP}.ods_order_detail_coupon
where dt='$do_date'
)odc
on od.id=odc.order_detail_id;"
dwd_payment_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table ${APP}.dwd_payment_info partition(dt)
select
nvl(new.id,old.id),
nvl(new.order_id,old.order_id),
nvl(new.user_id,old.user_id),
nvl(new.province_id,old.province_id),
nvl(new.trade_no,old.trade_no),
nvl(new.out_trade_no,old.out_trade_no),
nvl(new.payment_type,old.payment_type),
nvl(new.payment_amount,old.payment_amount),
nvl(new.payment_status,old.payment_status),
nvl(new.create_time,old.create_time),
nvl(new.callback_time,old.callback_time),
nvl(date_format(nvl(new.callback_time,old.callback_time),'yyyy-MM-dd'),'9999-99-99')
from
(
select id,
order_id,
user_id,
province_id,
trade_no,
out_trade_no,
payment_type,
payment_amount,
payment_status,
create_time,
callback_time
from ${APP}.dwd_payment_info
where dt = '9999-99-99'
)old
full outer join
(
select
pi.id,
pi.out_trade_no,
pi.order_id,
pi.user_id,
oi.province_id,
pi.payment_type,
pi.trade_no,
pi.payment_amount,
pi.payment_status,
pi.create_time,
pi.callback_time
from
(
select * from ${APP}.ods_payment_info where dt='$do_date'
)pi
left join
(
select id,province_id from ${APP}.ods_order_info where dt='$do_date'
)oi
on pi.order_id=oi.id
)new
on old.id=new.id;"
dwd_cart_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_cart_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
source_type,
source_id,
cart_price,
is_ordered,
create_time,
operate_time,
order_time,
sku_num
from ${APP}.ods_cart_info
where dt='$do_date';"
dwd_comment_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_comment_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
create_time
from ${APP}.ods_comment_info where dt='$do_date';"
dwd_favor_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_favor_info partition(dt='$do_date')
select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from ${APP}.ods_favor_info
where dt='$do_date';"
dwd_coupon_use="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table ${APP}.dwd_coupon_use partition(dt)
select
nvl(new.id,old.id),
nvl(new.coupon_id,old.coupon_id),
nvl(new.user_id,old.user_id),
nvl(new.order_id,old.order_id),
nvl(new.coupon_status,old.coupon_status),
nvl(new.get_time,old.get_time),
nvl(new.using_time,old.using_time),
nvl(new.used_time,old.used_time),
nvl(new.expire_time,old.expire_time),
coalesce(date_format(nvl(new.used_time,old.used_time),'yyyy-MM-dd'),date_format(nvl(new.expire_time,old.expire_time),'yyyy-MM-dd'),'9999-99-99')
from
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from ${APP}.dwd_coupon_use
where dt='9999-99-99'
)old
full outer join
(
select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time,
expire_time
from ${APP}.ods_coupon_use
where dt='$do_date'
)new
on old.id=new.id;"
dwd_order_refund_info="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
insert overwrite table ${APP}.dwd_order_refund_info partition(dt='$do_date')
select
ri.id,
ri.user_id,
ri.order_id,
ri.sku_id,
oi.province_id,
ri.refund_type,
ri.refund_num,
ri.refund_amount,
ri.refund_reason_type,
ri.create_time
from
(
select * from ${APP}.ods_order_refund_info where dt='$do_date'
)ri
left join
(
select id,province_id from ${APP}.ods_order_info where dt='$do_date'
)oi
on ri.order_id=oi.id;"
dwd_refund_payment="
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table ${APP}.dwd_refund_payment partition(dt)
select
nvl(new.id,old.id),
nvl(new.user_id,old.user_id),
nvl(new.order_id,old.order_id),
nvl(new.sku_id,old.sku_id),
nvl(new.province_id,old.province_id),
nvl(new.trade_no,old.trade_no),
nvl(new.out_trade_no,old.out_trade_no),
nvl(new.payment_type,old.payment_type),
nvl(new.refund_amount,old.refund_amount),
nvl(new.refund_status,old.refund_status),
nvl(new.create_time,old.create_time),
nvl(new.callback_time,old.callback_time),
nvl(date_format(nvl(new.callback_time,old.callback_time),'yyyy-MM-dd'),'9999-99-99')
from
(
select
id,
user_id,
order_id,
sku_id,
province_id,
trade_no,
out_trade_no,
payment_type,
refund_amount,
refund_status,
create_time,
callback_time
from ${APP}.dwd_refund_payment
where dt='9999-99-99'
)old
full outer join
(
select
rp.id,
user_id,
order_id,
sku_id,
province_id,
trade_no,
out_trade_no,
payment_type,
refund_amount,
refund_status,
create_time,
callback_time
from
(
select
id,
out_trade_no,
order_id,
sku_id,
payment_type,
trade_no,
refund_amount,
refund_status,
create_time,
callback_time
from ${APP}.ods_refund_payment
where dt='$do_date'
)rp
left join
(
select
id,
user_id,
province_id
from ${APP}.ods_order_info
where dt='$do_date'
)oi
on rp.order_id=oi.id
)new
on old.id=new.id;"
case $1 in
dwd_order_info )
hive -e "$dwd_order_info"
clear_data dwd_order_info
;;
dwd_order_detail )
hive -e "$dwd_order_detail"
;;
dwd_payment_info )
hive -e "$dwd_payment_info"
clear_data dwd_payment_info
;;
dwd_cart_info )
hive -e "$dwd_cart_info"
;;
dwd_comment_info )
hive -e "$dwd_comment_info"
;;
dwd_favor_info )
hive -e "$dwd_favor_info"
;;
dwd_coupon_use )
hive -e "$dwd_coupon_use"
clear_data dwd_coupon_use
;;
dwd_order_refund_info )
hive -e "$dwd_order_refund_info"
;;
dwd_refund_payment )
hive -e "$dwd_refund_payment"
clear_data dwd_refund_payment
;;
all )
hive -e "$dwd_order_info$dwd_order_detail$dwd_payment_info$dwd_cart_info$dwd_comment_info$dwd_favor_info$dwd_coupon_use$dwd_order_refund_info$dwd_refund_payment"
clear_data dwd_order_info
clear_data dwd_payment_info
clear_data dwd_coupon_use
clear_data dwd_refund_payment
;;
esac
第7章 数仓搭建-DWS层
应该创建那些表:是以维度模型中的维度为基准的
用户维度,商品维度,地区维度
一行数据是一个维度对象的当日汇总行为
字段:
主键:维度id,
其他字段:与该维度相关的事实表的度量值的聚合值(天)
分区:按天分区
7.2.1 访客主题
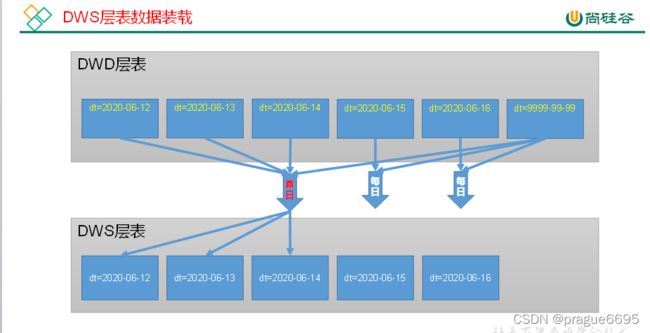

三表全外连接


7.2.5 活动主题
一个活动当中一条规则在一天的统计。
第8章 数仓搭建-DWT层
也是以维度为标准区分
行:一个维度对象的累积汇总行为
列:也是维度id为主键,其他字段为 该维度的相关的事实表的度量值的聚合值(n天)
分区 :也是按天分区,存储的截止到当日的全量的维度对象的累计汇总行为。


第9章 数仓搭建-ADS层
先考虑维度再考虑指标值。
统计值是按照维度字段分组聚合来的
9.1 建表说明
ADS层不涉及建模,建表根据具体需求而定。
9.2 访客主题
9.2.1 访客统计
该需求为访客综合统计,其中包含若干指标,以下为对每个指标的解释说明。

先计算总的统计值,然后 根据维度信息分组聚合。
2.数据装载
思路分析:该需求的关键点为会话的划分,总体实现思路可分为以下几步:
第一步:对所有页面访问记录进行会话的划分。
第二步:统计每个会话的浏览时长和浏览页面数。
第三步:统计上述各指标
统计最近天数的指标
UDTF把一份分成三份,然后分别过滤出最近1天,最近7天,最近30天的数据,然后进行分组统计。

获取每个会话的起始时间

装载数据时,因为数据量小所以没有分区,所以insert overwrite只会保留当前数据,删除历史数据,始终只有当天数据。
而insert into 会追加,但是会产生大量的小文件
解决方法:把原来的数据union进来,在进行overwrite操作。
9.2.2 路径分析
用户路径分析,顾名思义,就是指用户在APP或网站中的访问路径。为了衡量网站优化的效果或营销推广的效果,以及了解用户行为偏好,时常要对访问路径进行分析。
用户访问路径的可视化通常使用桑基图。如下图所示,该图可真实还原用户的访问路径,包括页面跳转和页面访问次序。
桑基图需要我们提供每种页面跳转的次数,每个跳转由source/target表示,source指跳转起始页面,target表示跳转终到页面。

1.建表语句
DROP TABLE IF EXISTS ads_page_path;
CREATE EXTERNAL TABLE ads_page_path
(
`dt` STRING COMMENT '统计日期',
`recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天',
`source` STRING COMMENT '跳转起始页面ID',
`target` STRING COMMENT '跳转终到页面ID',
`path_count` BIGINT COMMENT '跳转次数'
) COMMENT '页面浏览路径'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/ads/ads_page_path/';
2.数据装载
思路分析:该需求要统计的就是每种跳转的次数,故理论上对source/target进行分组count()即可。统计时需注意以下两点:
第一点:桑基图的source不允许为空,但target可为空。
第二点:桑基图所展示的流程不允许存在环。
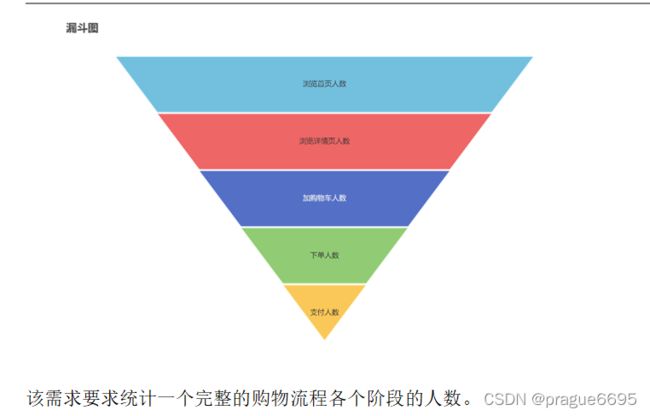
9.3.3 用户行为漏斗分析
漏斗分析是一个数据分析模型,它能够科学反映一个业务过程从起点到终点各阶段用户转化情况。由于其能将各阶段环节都展示出来,故哪个阶段存在问题,就能一目了然
9.3.4 用户留存率
留存分析一般包含新增留存和活跃留存分析。
新增留存分析是分析某天的新增用户中,有多少人有后续的活跃行为。活跃留存分析是分析某天的活跃用户中,有多少人有后续的活跃行为。
留存分析是衡量产品对用户价值高低的重要指标。
此处要求统计新增留存率,新增留存率具体是指留存用户数与新增用户数的比值,例如2020-06-14新增100个用户,1日之后(2020-06-15)这100人中有80个人活跃了,那2020-06-14的1日留存数则为80,2020-06-14的1日留存率则为80%。
要求统计每天的1至7日留存率,如下图所示。

9.4.2 品牌复购率
品牌复购率是指一段时间内重复购买某品牌的人数与购买过该品牌的人数的比值。重复购买即购买次数大于等于2,购买过即购买次数大于1。
此处要求统计最近1,7,30天的各品牌复购率。
2.数据装载
思路分析:该需求可分两步实现:
第一步:统计每个用户购买每个品牌的次数。
第二步:分别统计购买次数大于1的人数和大于2的人数。
HIVE相关操作
7.1.1 nvl函数
1)基本语法
NVL(表达式1,表达式2)
如果表达式1为空值,NVL返回值为表达式2的值,否则返回表达式1的值。
该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是表达式1和表达式2的数据类型必须为同一个类型。
2)案例实操
hive (gmall)> select nvl(1,0);
1
hive (gmall)> select nvl(null,"hello");
hello
7.1.2 日期处理函数
1)date_format函数(根据格式整理日期)
hive (gmall)> select date_format('2020-06-14','yyyy-MM');
2020-06
2)date_add函数(加减日期)
hive (gmall)> select date_add('2020-06-14',-1);
2020-06-13
hive (gmall)> select date_add('2020-06-14',1);
2020-06-15
3)next_day函数
(1)取当前天的下一个周一
hive (gmall)> select next_day('2020-06-14','MO');
2020-06-15
说明:星期一到星期日的英文(Monday,Tuesday、Wednesday、Thursday、Friday、Saturday、Sunday)
(2)取当前周的周一
hive (gmall)> select date_add(next_day('2020-06-14','MO'),-7);
2020-06-8
4)last_day函数(求当月最后一天日期)
hive (gmall)> select last_day('2020-06-14');
2020-06-30
7.1.3 复杂数据类型定义
1)map结构数据定义
map<string,string>
2)array结构数据定义
array<string>
3)struct结构数据定义
struct<id:int,name:string,age:int>
4)struct和array嵌套定义
array<struct<id:int,name:string,age:int>>
collect_set

7.1.4
array_contains(判断数组,是否存在的函数)
collect_set() 和groupby连用。
首次下单日期min(if(order_count>0,dt,null))
first_value(列名,是否跳过空值) 获取窗口函数的第一个值
last_value
datadiff(日期,减的天数)
出现报错
java.lang.OutOfMemoryError: GC overhead limit exceeded
Exception in thread "HiveServer2-Handler-Pool: Thread-405" java.lang.OutOfMemoryError: GC overhead limit exceeded
JVM的GC过程会因为STW,只不过停顿短到不容易感知。当引起停顿时间的98%都是在进行GC,但是结果只能得到小于2%的堆内存恢复时,就会抛出java.lang.OutOfMemoryError: GC overhead limit exceeded这个错误