【Mysql高级】【第十章】【 索引优化与查询优化】
索引优化与查询优化
- 1.数据准备
- 2.索引失效案例
-
- 2.1 全职匹配我最爱
- 2.2 最佳左前缀法则
- 2.3主键插入顺序
- 2.4 计算、函数 、类型转换 导致索引失效
- 2.5 范围条件右边的列索引失效
- 2.6 不等于(!= or <>)索引失效
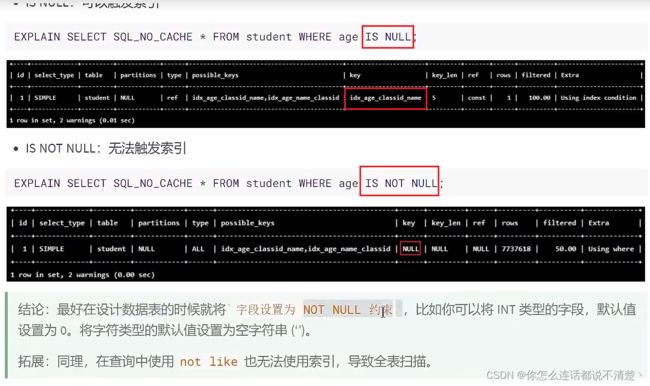
- 2.7 is null可以用索引,is not null不可以用索引
- 2.8 like以通配符%开头索引失效
- 2.9 OR前后存在非索引列,索引失效
- 2.10 数据库和表的字符集统一使用uft8mb4
- 2.11 练习及一般性建议
- 3.关联查询优化
-
- 3.1 数据准备
- 3.2 采用左外连接
- 3.3 采用内连接
- 3.4 join原理
-
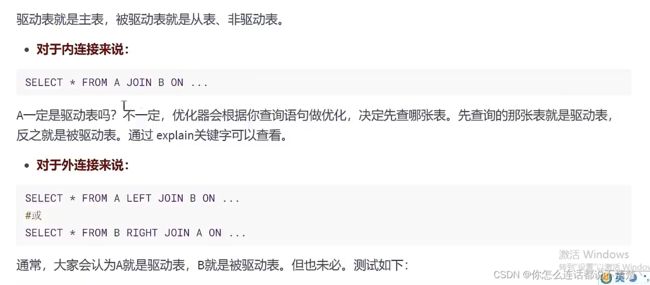
- 1.驱动表和被驱动表
- 2.Simple Nested-Loop Join(简单嵌套循环链接) (5.5)
- 3.Index Nested-Loop Join(索引嵌套循环连接)
- 4.Block Nested-Loop Join(块嵌套循环链接) (5.5 ~ )
- 5.Join小结
- 6.Hash Join
- 3.5 小结
- 4. 子查询优化
- 5. 排序优化
-
- 5.2 案例实战
- 5.4 fileSort算法:双路排序和单路排序
- 6.Group by优化
- 7. 优化分页查询
- 8. 索引查询优化
-
- 8.1 什么是覆盖索引
- 8.2 覆盖索引的利弊
- 9. 如何给字符串添加索引
-
- 9.1 前缀索引
- 9.2 前缀索引对覆盖索引的影响
- 9.3 拓展内容
- 10. 索引下推
-
- 10.1 使用前后对比
- 10.2 ICP的开启和关闭
- 10.3 ICP使用案例
- 10.4 ICP的好处
- 10.5 ICP的使用条件
- 11. 普通索引 vs 唯一索引
-
- 11.1 查询过程
- 11.2 更新过程
- 11.3 change buffer的使用场景
- 12. 其他优化策略
-
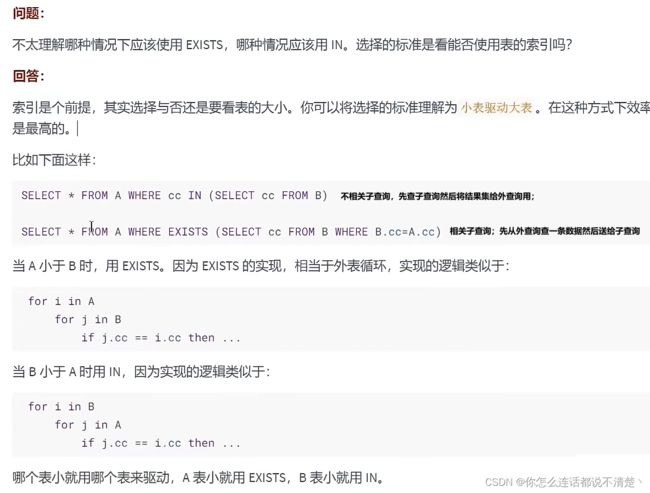
- 12.1 EXISTS和IN的区分
- 12.2 COUNT(*)和COUNT(具体字段)效率
- 12.3 关于SELECT(*)
- 12.4 LIMIT 1 对优化的影响
- 12.5 多使用COMMIT
- 13.淘宝数据库的主键是如何设计的?
https://www.bilibili.com/video/BV1iq4y1u7vj?p=141
数据库调优的几个维度:
- 查询优化
(1)索引失效或者没有充分利用索引----建立索引
(2)关联查询太多(join) 库表设计缺陷或者不得已的需求----SQL优化 - 服务器调优及参数设置(缓冲、线程数等)---- 调整my.cnf
- 数据量太大----分库分表
关于数据库调优的知识是非常分散的。 不同的DBMs,不同的公司,不同的职位,不同的项目遇到的问题都是不一样的。 这里我们分为三个章节进行细致讲解。
虽然SQL查询优化技术有很多,但在大方向上可以分为物理查询优化和逻辑查询优化两大类:
物理查询优化是通过索引与表的连接等技术进行优化,关键是掌握索引的使用。逻辑查询优化说白了就是换一种执行效率更高的sql写法
1.数据准备
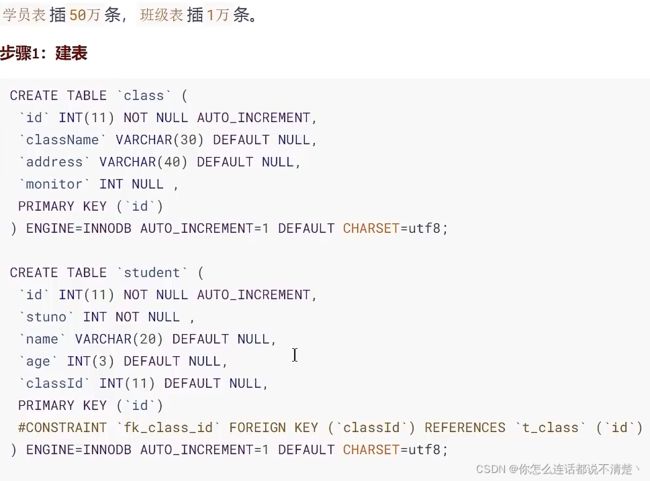
2.索引失效案例

2.1 全职匹配我最爱
宋红康版本讲解:
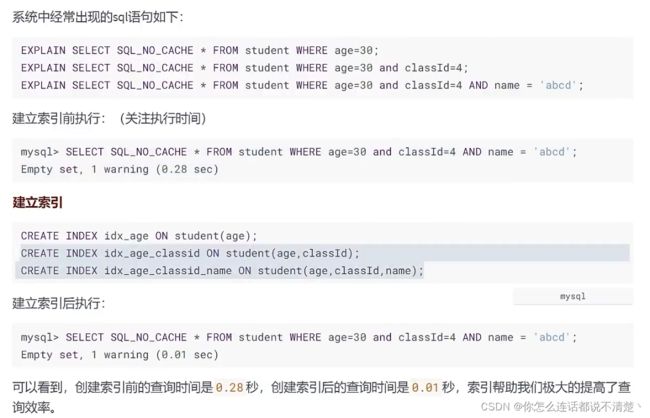
另一个讲解:

满足最左原则的查询:

全值匹配我最爱: 联合索引的字段全部用到了,且是从左往右按顺序的;完全是为这条SQL量身定做的索引
2.2 最佳左前缀法则
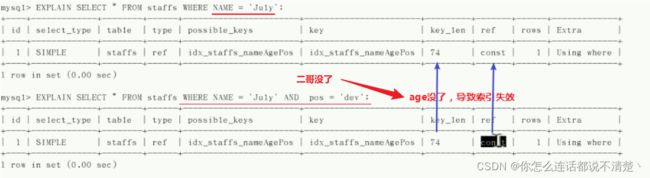
(1) 带头大哥无了

(2) 二哥没了
二哥没了,可以看出来 按照(1,3)进行检索和按照(1)进行检索,对索引的使用效率是一样的;key_len都是74,引用也只有一个;说明找大哥的时候用到了索引,但是找三弟的时候没用到索引;
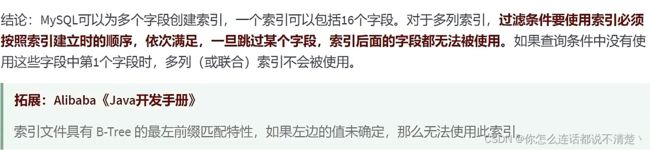
最佳左前缀法则: 如果索引用了多列,检索条件从索引的最左列开始并且不跳过中间的列 (1.火车头不能丢 2.中间不能断)
2.3主键插入顺序
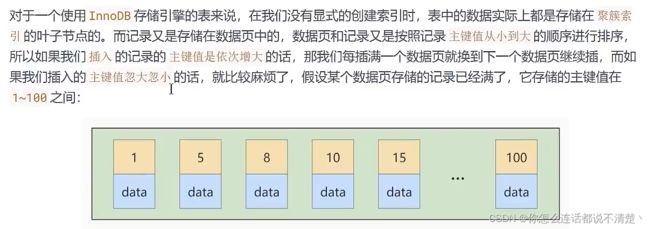
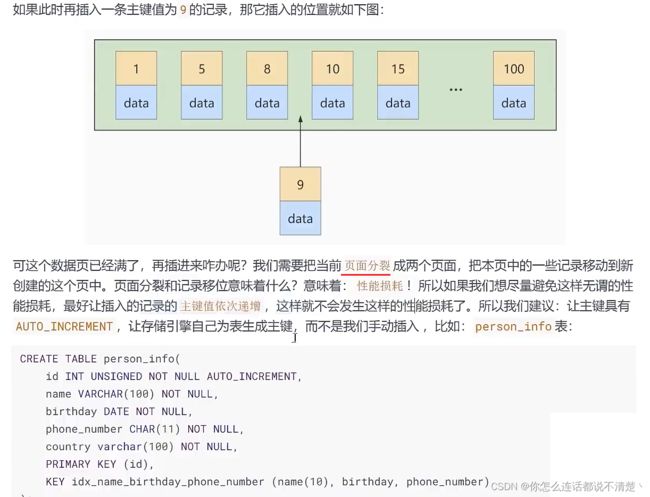
2.4 计算、函数 、类型转换 导致索引失效
函数

计算

类型转换

2.5 范围条件右边的列索引失效
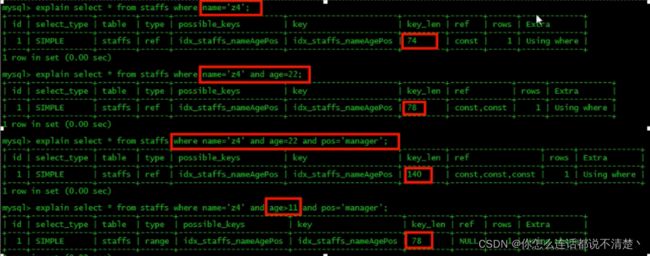
图中可以看出,一个索引的key_len是74,两个是78,三个是140,在最后一个sql中,age用了范围,key_len是78,只有name和age用到了索引,pos的索引失效,ref为null
2.6 不等于(!= or <>)索引失效
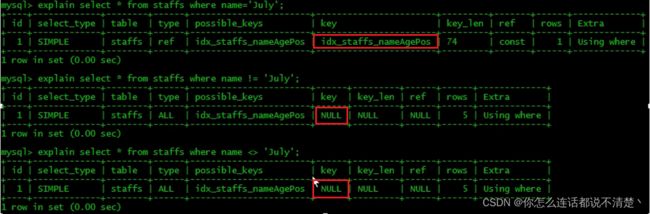
2.7 is null可以用索引,is not null不可以用索引
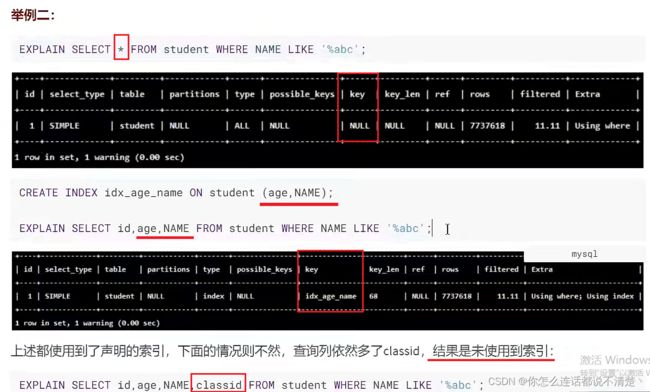
2.8 like以通配符%开头索引失效
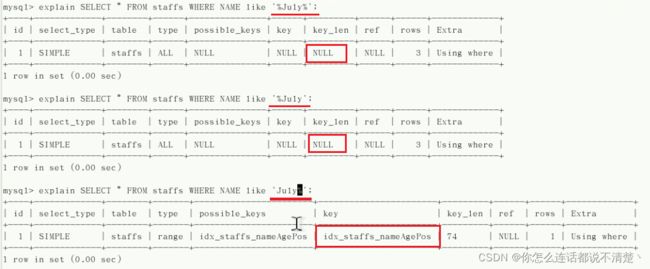
like如果在开头写%会导致全表扫描;

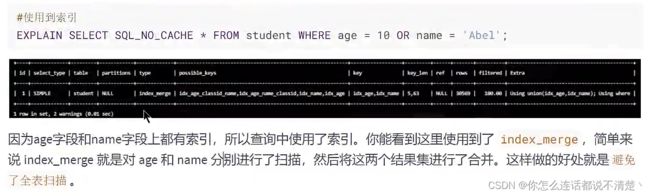
2.9 OR前后存在非索引列,索引失效
2.10 数据库和表的字符集统一使用uft8mb4
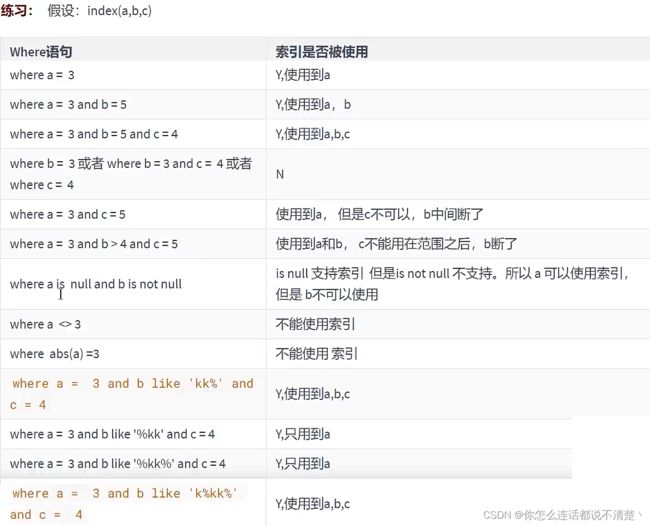
2.11 练习及一般性建议

3.关联查询优化
https://www.bilibili.com/video/BV1iq4y1u7vj?p=143
3.1 数据准备
3.2 采用左外连接
(1) join字段 都不建立索引
两张表都是全表扫描,两张表都做全表扫描;

左连接,左表为驱动表,原理为:
for(记录1 in 左表){ for(记录2 in 右表){ 记录1 join 记录2 } } 所以时间复杂度O(n*m); 由于被驱动表需要被遍历n次,所以查询优化器进行了优化, 使用`join buffer` 将被驱动表缓存起来,从而提升检索速度;
(2) join字段 被驱动表上建立索引
在左外连接的场景下,由于驱动表所有数据都要,因此可以接受左表全表扫描,可以在被驱动表的连接字段上建立索引;
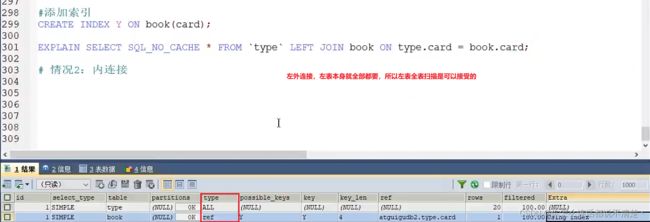
(3) 驱动表和被驱动表都对连接字段建立索引
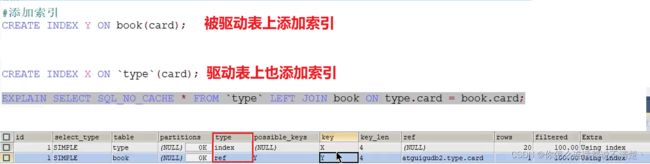
(4) 只在驱动表上建立索引

外连接总结:
- 外连接场景下,索引不影响驱动和被驱动的关系
3.3 采用内连接
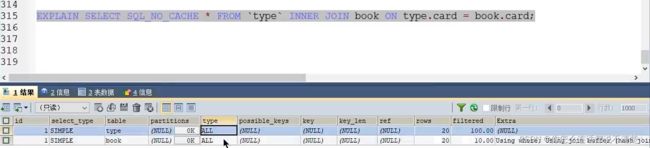
(1) 都不加索引
结论: 内连接都不添加索引,小表驱动大表
(2) book上加索引
结论: 内连接添加索引的表会被当做被驱动表

(3) 都上加索引
结论1: 对于内连接来说,两个表的地位是一样的,查询优化器可以决定谁作为驱动表,谁作为被驱动表;所以不是随机的;
此时,向type表添加数据,使得type表数据量更大:
结论2: 内连接中,都建立了索引时,数据量更大的表会被优化为被驱动表


(4) 内连接,有索引的表作为被驱动表 性能更好
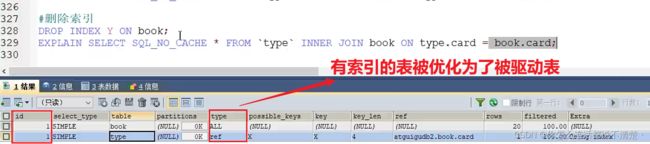
内连接总结:
- 当两个表都没有建立索引时,小表驱动大表
- 当两个表都建立了索引时,小表驱动大表
- 当两个表只有一个建立索引时,索引表作为被驱动表
3.4 join原理
https://www.bilibili.com/video/BV1iq4y1u7vj?p=144&spm_id_from=pageDriver

1.驱动表和被驱动表

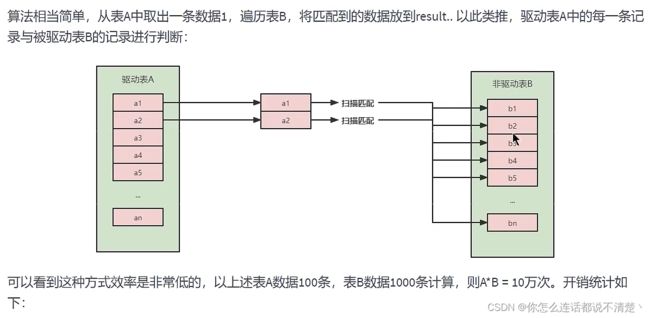
2.Simple Nested-Loop Join(简单嵌套循环链接) (5.5)
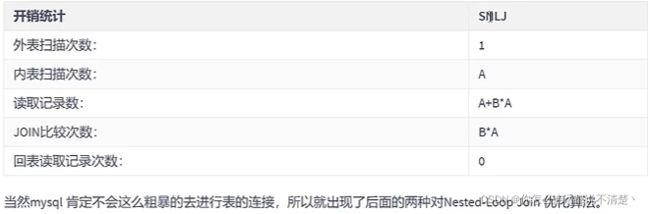
补充说明:
- join操作是在where子句后执行,join操作的是经过where过滤后的两个表的数据!
- 从开销统计来看,A影响更大,因此小表驱动大表更好!
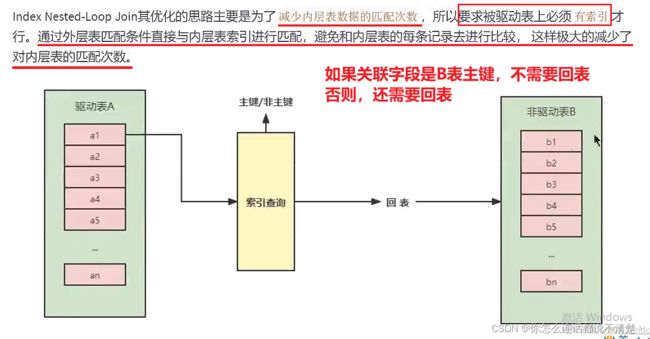
3.Index Nested-Loop Join(索引嵌套循环连接)
- 思想:在被驱动表上建立索引,从而减少被驱动表中查找记录的时间
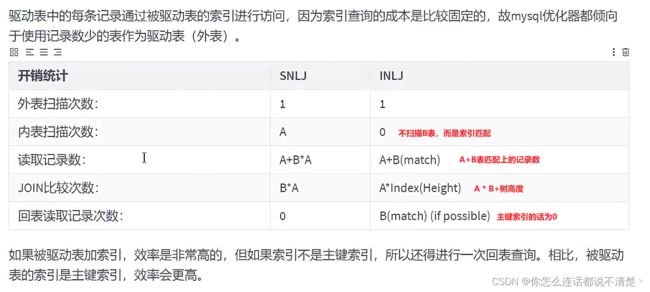
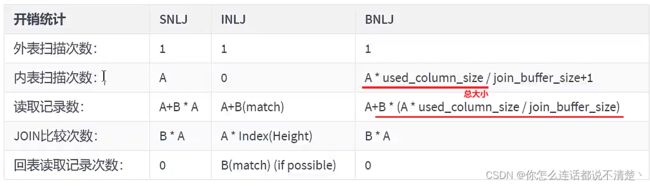
4.Block Nested-Loop Join(块嵌套循环链接) (5.5 ~ )
- 目的:减少非驱动表加载到内存的次数;
- 思路:在
Simple Nested-Loop Join中,驱动表A有多少条记录,就加载多少次B表;现在优化为一次用N条 驱动表记录来join B表;这样就减少了B表加载次数; - 这种优化方式和索引无关

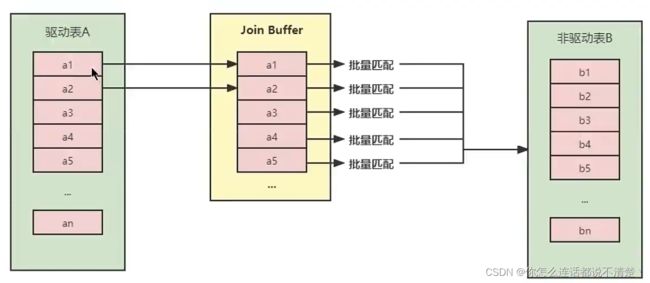
Join Buffer
- 存放驱动表 被select的字段 和 join字段
- N个Join,有N-1个Join Buffer
5.Join小结

-
小 指的是 :
表行数 * 每行大小更小,buffer 可以存更多,减少被驱动表IO; -
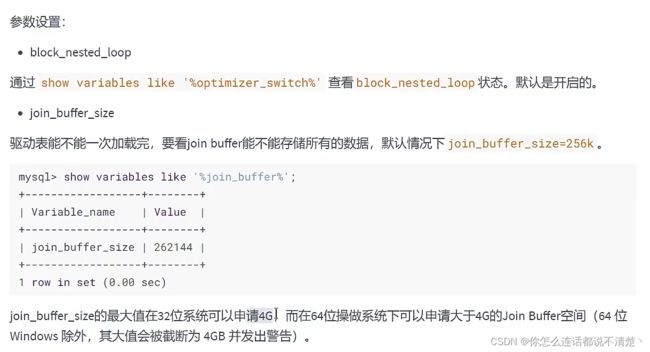
Mysql5.7 中使用的就是Block Join
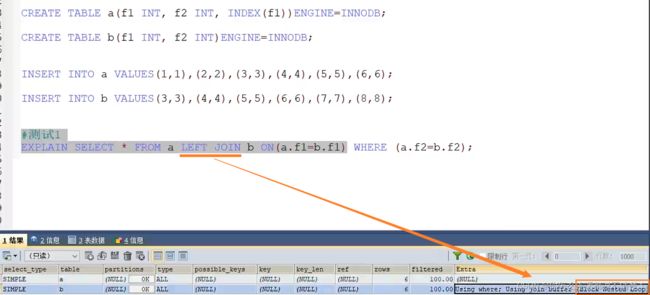
6.Hash Join

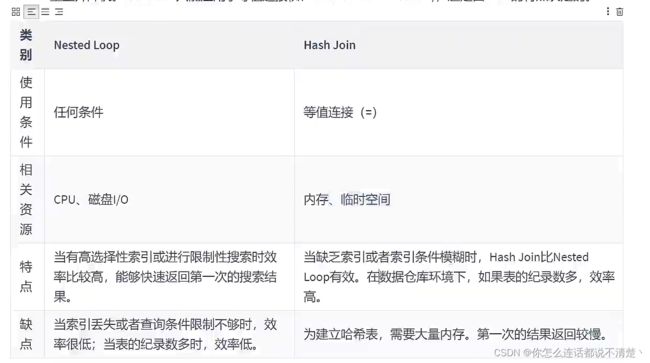
3.5 小结

4. 子查询优化
https://www.bilibili.com/video/BV1iq4y1u7vj?p=145&spm_id_from=pageDriver

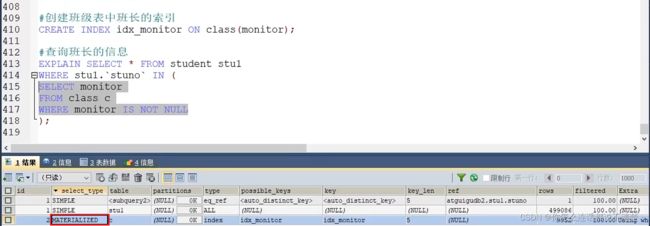
子查询优化1:推荐使用多表查询
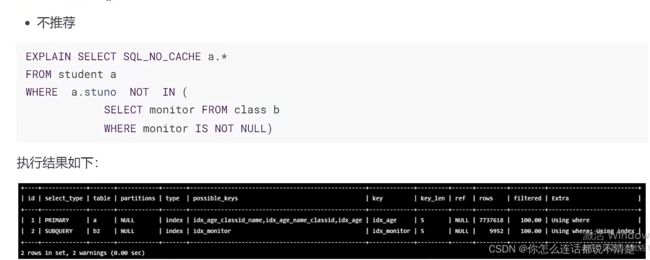
不推荐:
推荐:

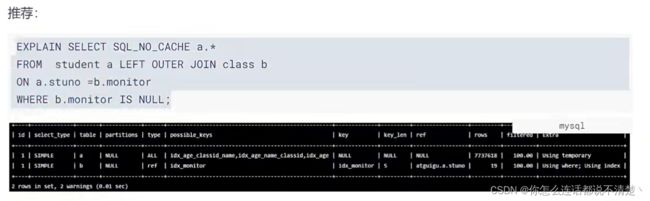

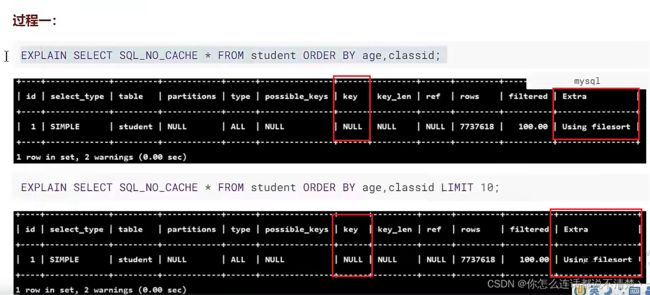
5. 排序优化

案例
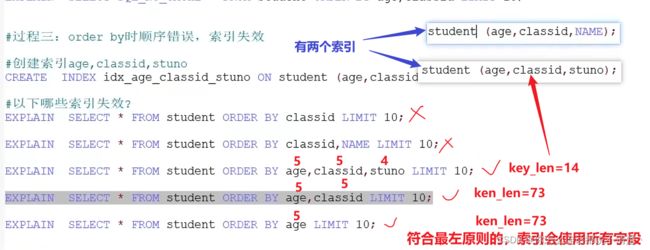
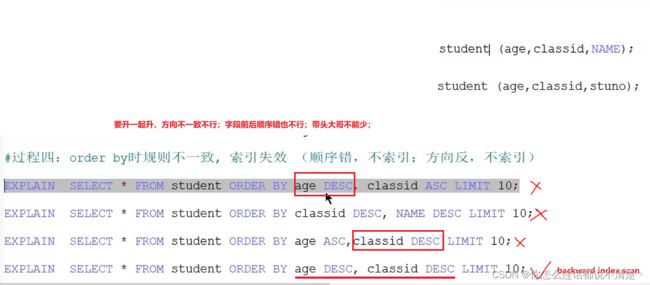
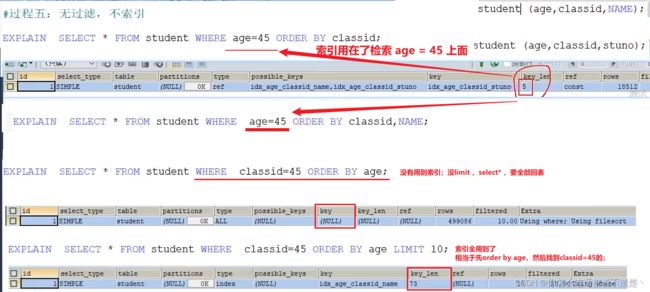
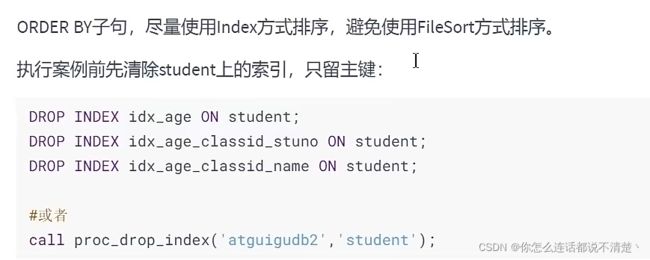
student表和class表只保留主键索引;
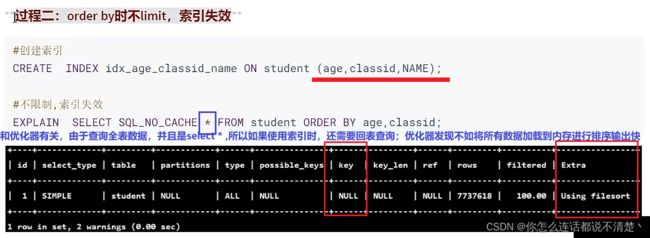

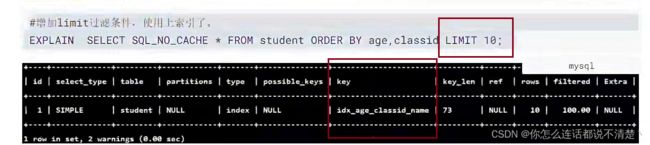
加上limit后,不需要全表回表查询,只需要topN条进行回表,因此此时使用上了索引;

5.2 案例实战
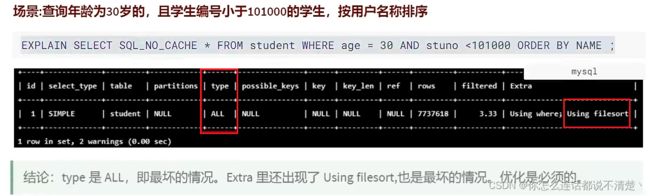
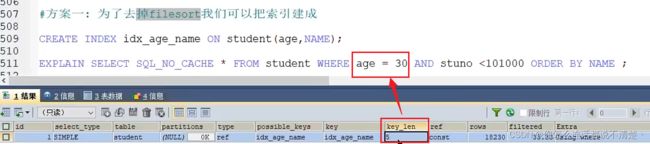
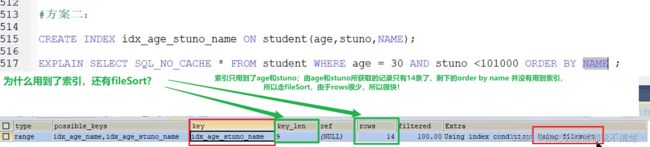


过滤和排序 如何建立索引?

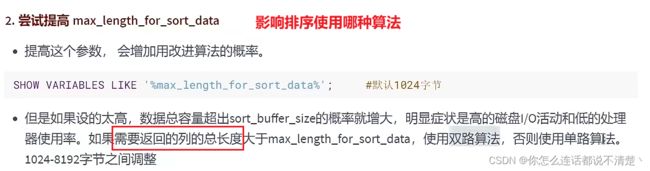
5.4 fileSort算法:双路排序和单路排序

双路排序:要进行两次磁盘扫描获取结果;
第一次扫描:读取行指针和order by的列; 然后将order by列进行排序
第二次扫描:由于行指针和order by的列已经排好序了,然后第二次扫描磁盘,通过行指针读取其他所需要的字段;
单路排序:只扫描一次磁盘
空间换时间

fileSort 优化策略:
实在用不了index,必须有fileSort的时候,采用如下优化策略
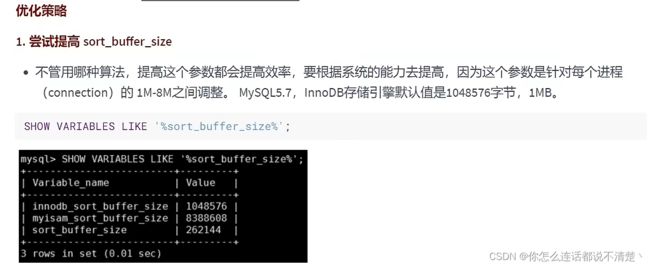

6.Group by优化
https://www.bilibili.com/video/BV1iq4y1u7vj?p=146&spm_id_from=pageDriver

7. 优化分页查询
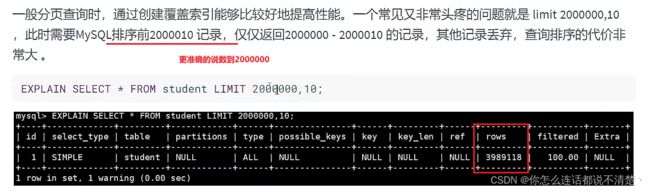
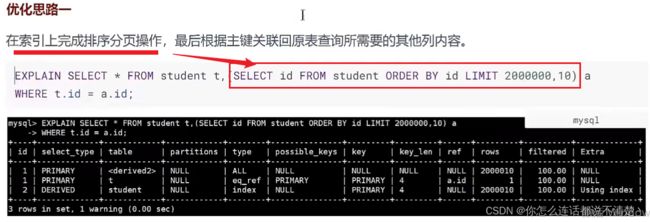
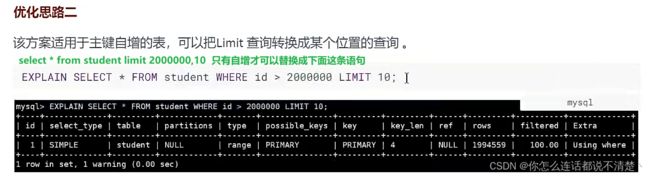
8. 索引查询优化
https://www.bilibili.com/video/BV1iq4y1u7vj?p=147&spm_id_from=pageDriver
8.1 什么是覆盖索引


8.2 覆盖索引的利弊

9. 如何给字符串添加索引
9.1 前缀索引
9.2 前缀索引对覆盖索引的影响
9.3 拓展内容
10. 索引下推

- 索引下推 全称叫做索引条件下推
- 是Mysql5.6的新特性
- 是一种在存储引擎层使用索引过滤数据的优化方式
- 在EXPLAIN的Extra字段中出现了
Using Index Condition表示使用到了索引下推
10.1 使用前后对比
使用ICP前的扫描过程
先通过索引idx_key1,过滤到100多条数据;然后回表100多次,在聚簇索引的叶子节点中的数据 根据 like '%a’的条件找到目标数据;
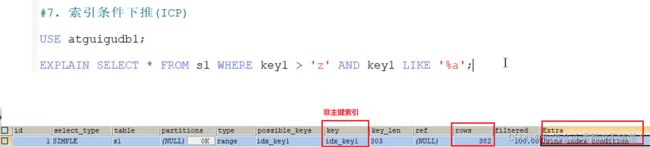
ICP后
通过非聚簇索引idx_key1,就能找到满足 key1>‘z’ 的索引;
后面一个条件 恰好用的也是字段 key1,那么我们直接可以在非聚簇索引上进行二次过滤,而不需要回表查询了;
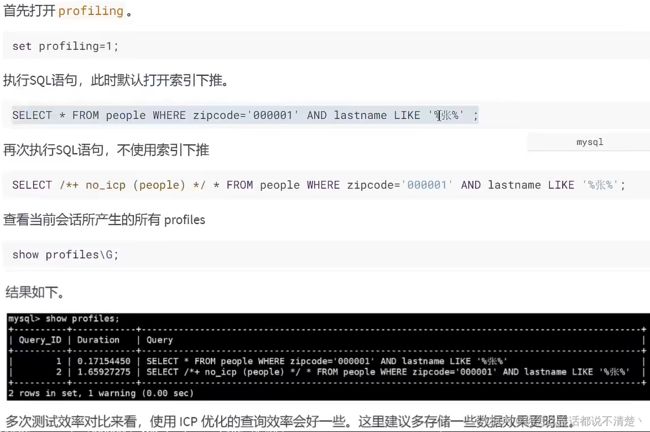
10.2 ICP的开启和关闭

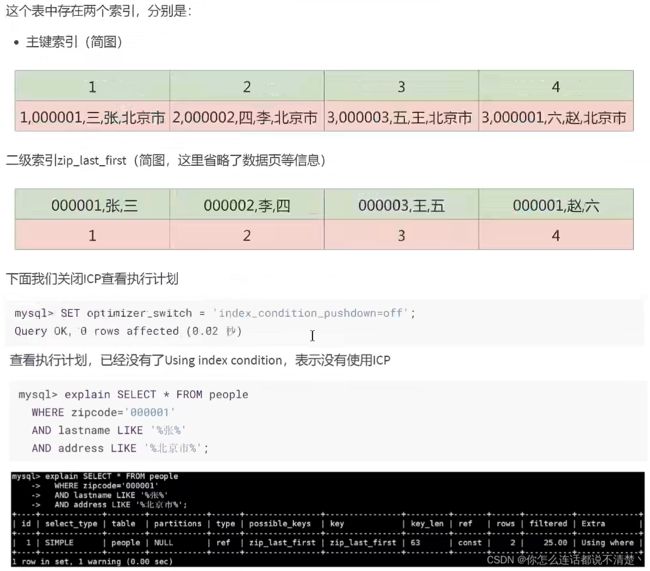
10.3 ICP使用案例

- 当前查询只有zipcode='00001’这个条件用到了索引;
- 由于lastName也属于非聚簇索引的一部分,因此用到了ICP,所以Extra中有Using index condition;
- 由于where条件中还有个address是非索引字段,所以Extra中有Using where
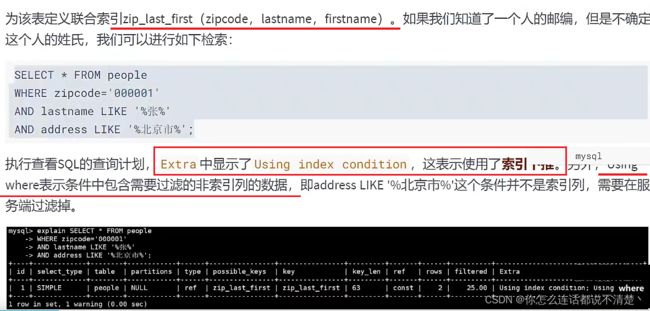

10.4 ICP的好处
- 在索引中有这个字段,但是用这个字段进行检索没法使用索引,此时可以使用索引条件下推,在进行回表查询之前进行二次过滤;
- 回表前过滤,减少IO,提高效率;
10.5 ICP的使用条件
ICP的本质就是使用二级索引,然后减少回表次数;所以只有在用二级索引的时候才会产生ICP

11. 普通索引 vs 唯一索引
11.1 查询过程
11.2 更新过程
11.3 change buffer的使用场景
12. 其他优化策略
https://www.bilibili.com/video/BV1iq4y1u7vj?p=149&spm_id_from=pageDriver
12.1 EXISTS和IN的区分
12.2 COUNT(*)和COUNT(具体字段)效率

统计表记录数:
(1)count(*) 和 count(1) 没差;选择空间小(key_len小)的二级索引进行计算;
(2)InnoDB时间复杂度O(n) MyIsam是O(1)
(3)count(具体字段):尽量选择key小的二级索引;因为统计会加载数据到内存,所以选择空间小的
12.3 关于SELECT(*)

12.4 LIMIT 1 对优化的影响

12.5 多使用COMMIT
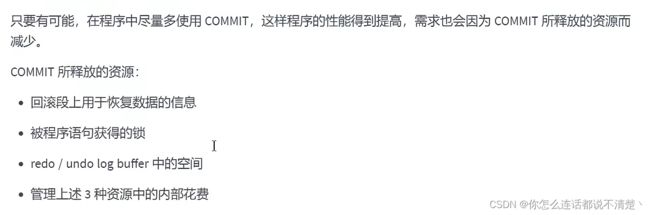
说白了就是减少内存中存储的数据;
13.淘宝数据库的主键是如何设计的?
https://www.bilibili.com/video/BV1iq4y1u7vj?p=150&spm_id_from=pageDriver