视觉Transformer快速入门指南!

【栏目:前沿进展】Transformer 网络推动了诸多自然语言处理任务的进步,而近期 Transformer 开始在计算机视觉领域崭露头角,比如ViT和DETR等。
近日,华为诺亚方舟实验室高级研究员韩凯在第 26 期青源 Live 中带来了题为「视觉 Transformer 综述」的报告。在本次分享中,韩凯老师回顾了基于自注意力的 Transformer 模型的工作机制,并分析其优势。接着,韩凯老师回顾了 Transformer 在视觉任务中的应用,介绍了自监督学习、图像分类、目标检测、语义分割任务,以及「视觉-语言」多模态任务中的 Transformer 模型。
本文整理自报告,视频回放链接:https://hub.baai.ac.cn/live/?room_id=171


韩凯,华为诺亚方舟实验室高级研究员。北京大学硕士,浙江大学学士。主要研究方向为深度学习和计算机视觉,已在CCF-A类会议发表论文20余篇,其中GhostNet论文入围 PaperDigest CVPR 2020最具影响力论文之一。他还担任NeurIPS / CVPR / ICML / ICLR / AAAI / IJCAI / TNNLS / TCSVT等会议和期刊审稿人。
报告人:韩凯
整理:熊宇轩
编辑:李梦佳
01
Transformer 模型发展历程

Transformer 是谷歌于 2017 年提出的一种新型网络架构。有别于卷积神经网络和循环神经网络,Transformer 主要基于自注意力机制进行特征交互,其中还引入了多层感知机、ShortCut 连接等网络结构。Transformer 起初被用于自然语言处理领域,自 2020 年开始逐渐在计算机视觉领域兴起,取得了一些列惊艳的效果。
在 Transformer 模型的发展轨迹中,重要的里程碑式的工作包括:
(1)谷歌在论文「Attention is All You Need」中提出 Transformer 模型。(2)2018 年 10 月,研究人员提出 BERT,利用 NLP 领域的大量数据进行自监督学习,预训练得到的大模型在下游任务中展现出了很好的性能。
(3)2020 年 5 月,OpenAI 提出具有 1700 亿参数的 GPT-3 模型,在自然语言处理领域展现出了一定通用人工智能的特点,可以与人类进行较为自然的对话。
(4)2020 年 5 月,DETR 模型将 Transformer 用于目标检测任务。该模型无需进行 Region proposal 和 NMS 操作,极大简化了工作流程。
(5)2020 年 7 月,OpenAI 在 iGPT 中将 Transformer 用于图像预训练。(6)2020 年 10 月,谷歌的 ViT 模型首次基于纯 Transformer 架构实现图像分类,成为视觉 Transformer 领域的重要基础性架构。
(7)2020 年 12 月,华为诺亚方舟实验室提出用于底层视觉任务的 IPT 模型。
(8)2021 年至今,DeiT、PVT、TNT、Swin Transformer 等视觉 Transformer 模型相继被提出。
02
回顾:Transformer 工作原理
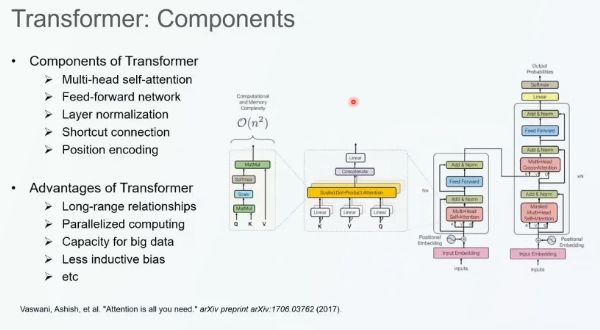
从广义的角度来看,Transformer 可以被用于处理序列化数据。Transformer 通过编码器提取输入序列的特征,并根据需要解码出新的序列,或完成分类等任务。
Transformer 包含多头自注意力机制、前馈神经网络、层归一化、Shortcut 连接、位置编码等组件。其中,最核心的部分为多头自注意力机制,它通过线性变换将输入转化为 Q(Query)、K(Key)、V(Value)矩阵。接着,我们通过 Q 和 K 的内积计算二者之间的相关性,再将相关性与 V 相乘得到修正后的 Token 表征作为多头自注意力的输出。
上述网络架构为 Transformer 带来了以下优势:
(1)多头自注意力机制可以捕获长程相关性。
(2)自注意力和前馈神经网络可以转化为矩阵乘法,从而实现并行计算,相较于循环神经网络可以大幅提高计算效率。
(3)前馈神经网络参数量大、模型结构易于拓展,可以构建处理大数据的大模型。
(4)对输入的序列没有先验要求,归纳偏置较少。
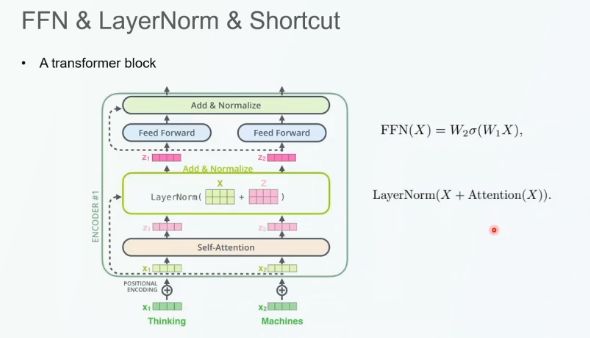
在每一个 Transformer 模块中,我们首先将自注意力机制的输入和输出通过 Shortcut 连接相加,接着我们将该值作为前馈网络层的输入,并再次通过 Shortcut 连接对前馈网路的输入和输出求和。通过迭代式地累加,我们可以实现对 Transformer 模型的扩展。同时,FFN 层的维度也可以被拓宽或缩小。

由于 Transformer 中的自注意力结构本身并不能刻画不同 token 的空间位置信息,因此我们通过位置编码来感知位置信息。通常而言,我们直接将位置编码向量与 token 的嵌入相加。解码器与编码器的结构类似,区别在于:输入给解码器的 K 和 V 来自于编码器的输出。
03
视觉 Transformer

华为诺亚方舟实验室将视觉 Transformer 模型领域的研究分为了骨干网络、高/中层视觉语义模型、底层视觉任务、视频处理、多模态任务、高效 Transformer 六大类:
(1)骨干网络:
监督式预训练(原始论文):ViT、TNT、Swin 等
自监督预训练(原始论文):iGPT、MoCo v3 等
(2)高/中层视觉语义模型:
目标检测:DETR、Deformable DETR、UP-DETR 等
分割:Max-DeepLab、VisTR、SETR 等
姿态估计:Hand Transformer、HOT-Net、METRO 等
(3)底层视觉任务:
图像生成:Image Transformer、Taming Transformer、TransGAN 等
图像增强:IPT、TTSR 等
(4)视频处理:
视频补绘:STTN 等
视频描述:Masked Transformer 等
(5)多模态任务:
分类:CLIP
图像生成:DALL-E、Cogview
NLP、CV 多任务:UniT
(6)高效 Transformer:
分解:ASH 等
蒸馏:TinyBert 等
量化:FullyQT 等
架构设计:ConvBert 等
基于Transformer的骨干网络
骨干网络:iGPT
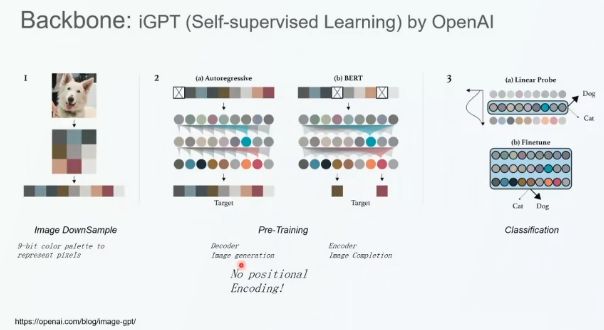
OpenAI 于去年提出了自监督学习模型 iGPT,该模型的工作流程分为三步:
(1)图像下采样,从而减小序列的长度
(2)预训练:自回归像素预测任务和类似于 BERT 的像素填充任务
(3)调优与分类

如图 x 所示,在图像填充任务中,给定图像上半部分,我们通过 iGPT 图像预测图像的下半部分,得到的图像语义上与上半部分具有一致性;在图像生成任务中,iGPT 模型生成的图像质量可以比肩 GAN 等模型。
此外,iGPT 模型的预训练结果还可以被用于图像分类任务,其性能与 SimCLR、AMDIM、Isometric Nets 等基于 CNN 的自监督模型相当。
骨干网络:ViT
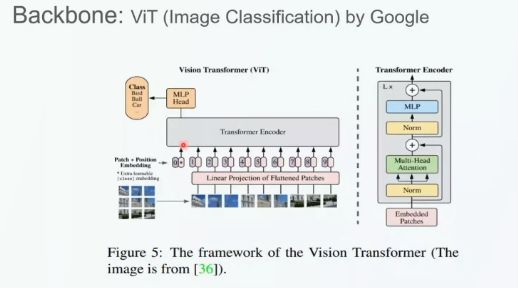
谷歌基于标准的 Transformer 编码器构建了著名的 ViT 模型。作者首先将模型切分成图块,再通过全连接层将图块投影为向量作为 Patch 嵌入。接着,我们将 Patch 嵌入与位置嵌入相加,输入给标准的 Transformer 编码器。最后,我们将 Transformer 编码器的编码结果输入给多层感知机分类头,从而对图像进行分类。这种简洁的模型架构在图像分类任务上取得了非常好的效果,在 JFT300M 数据集上预训练的 ViT 模型与使用 ResNet 等 CNN 架构的分类结果相当,且 ViT 所需要的预训练算力相较于 CNN 模型大幅减少。
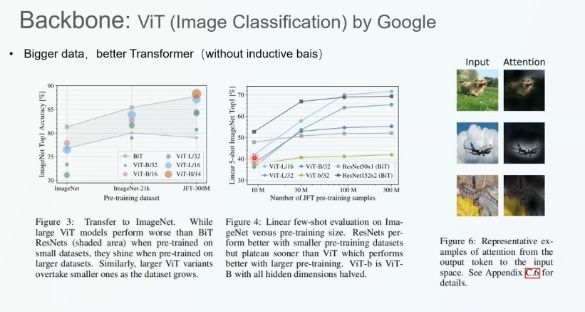
如图 x 所示,实验结果表明,预训练的数据量越大,Transformer 预训练的性能越好。这主要是因为 Transformer 没有引入过多的归纳偏置,对数据没有任何的假设,不会限制网络本身的表达能力。预训练数据量相对较少时,ViT 模型的性能弱于 CNN 模型;随着数据量的增加,CNN 网络的效果达到了瓶颈,而 Transformer 模型的性能越来越高。最终,在使用全量数据的情况下,Transformer 网络的性能超过了 CNN 网络。
骨干网络:DeiT

由于 ViT 模型的预训练需要使用大量的数据,其训练所需的算力也是普通研究者无法承担的,于是 Facebook 提出了效率叫高的视觉 Transformer 模型 DeiT。该模型的主要如下:
(1)广泛测试了各种常用的神经网络训练技巧,包括:不同的 Adam 优化器,Rand-Augment、AutoAug、Mixup、CutMix 等数据增广方法,Drop Path、Erasing 等正则化技巧。其中,Drop-Path 和 Erasing 对训练性能至关重要。
(2)测试了知识蒸馏方法,作者发现我们不能直接对 class token 进行蒸馏,需要新建一个蒸馏 token,然后对其进行蒸馏。
骨干网络:ViT 变体
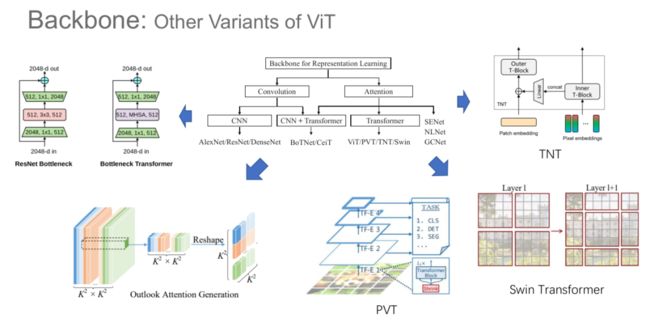
受 ViT 的启发,研究人员提出了一系列基于 Transformer 的视觉模型。具体而言,用于表征学习的骨干模型可以分类基于卷积的模型和基于注意力机制的模型。其中,基于注意力机制的模型又分为基于自注意力机制的 Transformer 模型和基于其它注意力机制的模型(如 SENet、NLNet、GCNet等)。基于自注意力机制的模型分为基于纯粹的 Transformer 架构的模型(例如,ViT、PVT、TNT、Swin),以及将 CNN 与 Transformer 相结合的模型(例如,BoTNet、CeiT)。
在 BotNet 中,由于 ResNet 中提取空间信息的是 3*3 的卷积层,作者将该层替换为了多头自注意力层,实现了性能提升。在 Outlook 注意力生成模型中,作者将 Transformer 的全局自注意力改为了局部的注意力结构。在 TNT 网络中,作者在每一个 Transformer 层中设计了内外两级 Transformer,外部的 Transformer 用于提取 patch 之间的全局相关性,内部的 Transformer 用于提取 patch 内部像素之间的局部相关性。PVT 首次将视觉 Transformer 改造为了层次化的金字塔结构,从而提取多尺度特征。Swin Transformer 也引入了金字塔结构和局部的自注意力机制,并通过有一定位移的窗口(shifted window)实现窗口之间的交互。
基于 Transformer 的骨干模型性能一览

华为诺亚方舟实验室对 CNN 模型、纯 Transformer 模型、CNN+Transformer 模型的运算效率进行了对比。实验结果表明,在相同的实验环境下,纯 Transformer 架构的 FLOPs 处于 ResNet 和 EfficientNet 之间。目前最优的模型是 CMT、VOLO 等将 CNN 与 Transformer 相结合的模型。
基于 Transformer 的目标检测
目标检测:DETR
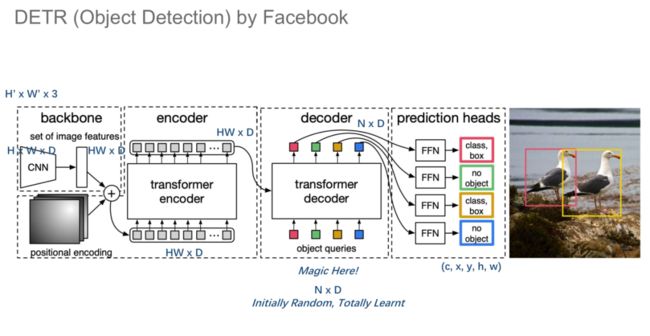
DETR 是第一个将 Transformer 用于目标检测任务的模型,其骨干网络为 CNN,然后通过 Transformer 实现目标检测。其中,骨干网络提取出的特征图维度为 H*W*D,将其投影为 HW*D 的序列,与位置编码相加之后输入给标准的 Transformer 编码-解码结构。值得注意的是,Object Queries 为预定义好的 N 个方框,我们将其与 Ground Truth 的差异作为训练网络的损失函数。

DETR 成功的主要原因是它使用了二部图匹配损失函数。作者首先将 Groud Truth 中的检测框的数量与预测的数量对齐,进而找到最优的二部图匹配方案,再根据分类和检测框坐标构建二部图匹配损失。与 Faster-RCNN 相比,在参数量相近的情况下,DETR 的性能有显著的提升。
目标检测:Deformable DETR

DETR 的训练收敛速度较慢,商汤科技的代季峰组提出了 Deformable DETR,能够以比 DETR 快 10 倍的速度训练模型。该模型使用了多尺度特征,将金字塔结构中不同层的特征输入给 Transformer 模型,并提出了 Deformable 自注意力机制。
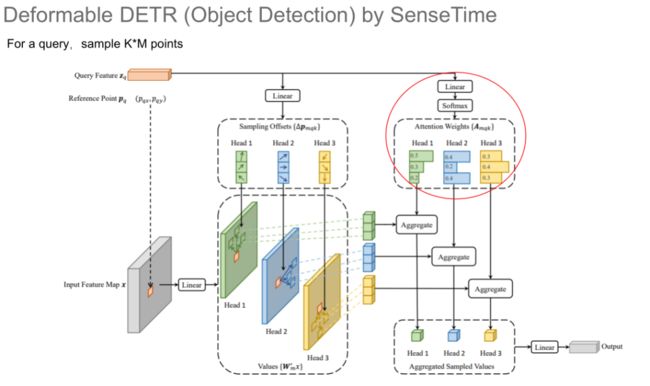
针对每一个 Query,该模型在每一个注意力头中都会通过Deformable 的方式找出与其最相关的位置,再对这些位置上的像素应用自注意力机制,进而通过注意力机制将不同头中提取出的特征进行聚合作为 Deformable 自注意力机制的输出,避免了全局自注意力机制中的大量冗余。实验结果表明,Deformable DETR 相较于 DETR 模型实现了 mAP 和运行速度的提升。
基于 Transformer 的目标检测模型性能一览
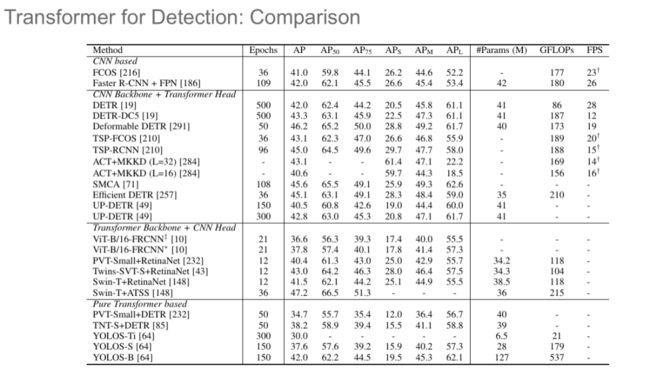
华为诺亚方舟实验室将目标检测模型分为了以下四类:
(1)基于 CNN 的模型:FCOS、Faster-RCNN 等
(2)CNN 作为骨干网络,Transformer 作为目标检测 Head:DETR、Deformable DETR 等
(3)Transformer 作为骨干网络,CNN 作为目标检测 Head:PVT+RetinaNet、Swin+ATSS 等
(4)纯 Transformer 模型:PVT+DETR、YOLOS 等
目前,性能最优的模型为 Deformable DETR 与 Swin+ATSS 的方案,研究人员正试图利用纯 Transformer 网络实现更好的目标检测性能。
语义分割:SETR
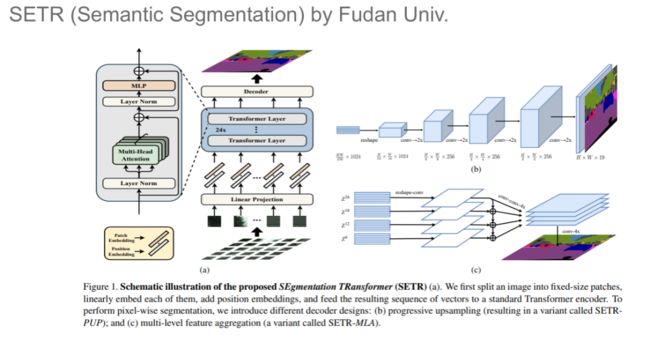
复旦大学提出了 SETR,将 Transformer 模型用于语义分割任务。该模型首先将图像划分为若干个 Patch,并将其输入给 Transformer 编码-解码结构,并通过少量的卷积层输出最终的分割结果。

实验结果表明,使用 ImageNet 21K 中的大量数据预训练的 SETR 模型可以在 ADE20K 数据集上取得超过 50% 的 mIoU,大幅优于基于 ResNet 的模型的性能。
多模态任务
CLIP
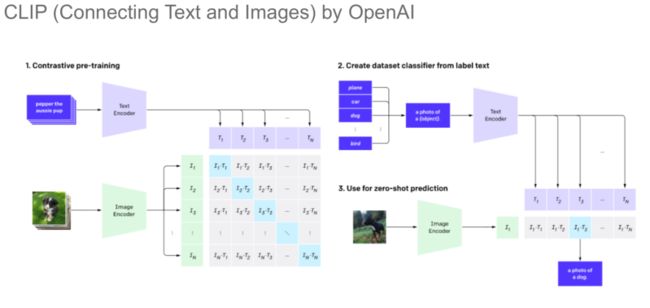
OpenAI 团队在 CLIP 项目中收集了大量的「文本-图像」对,用它们来训练模型,从而实现零样本的分类。具体而言,我们首先分别对收集到的图像和文本进行编码,然后通过对比学习预训练计算图文对两两之间的相似度,最终最大化对角线上的值。预训练得到的 CLIP 模型可以被用于进行零样本分类任务。实验结果表明,CLIP 模型的零样本分类性能优于以往的少样本学习分类器。
DALL-E

OpenAI 在 CLIP 的基础上进一步推出了可以根据文本生成图像的 DALL-E 模型,该模型可以「理解」输入文本的抽象含义,并以此生成生动的图像。在第一阶段,我们首先训练一个编码图像的编码-解码结构,并将中间表示作为图像特征。在第二阶段,我们提取文本的特征,并将其与图像特征拼接起来,从而得到图文对的特征。接着,我们通过 Transformer 模型生成图像。最后,我们通过 CLIP 模型重新对生成的图像排序,将排序最高的图像作为最终的输出。
04
结语
如今,有些研究者试图通过 Transformer 统一计算机视觉、自然语言处理等任务,我们可以将其看做对通用人工智能的进一步探索。除了 Transformer,近年来以多层感知机为代表的其它神经网络形态呈异军突起之势,存在巨大的探索空间。
了解更多信息请加入「计算机视觉」交流群
