深度学习笔记-----归一化方法BN
1,概述
1. 什么是归一化:归一化又称规范化,并不是一个完全定义好的数学操作,通常是指将数据进行偏移和尺度缩放。是数据预处理中常用的手段。一般是将输入的数据约束固定到一定的范围如【0,1】。没有固定的数学表达式,根据需求定义将数据规定到一定范围内的数学表达式;
2.归一化方法的目的:实际上是通过采取不同的变换方式使各层的的输入数据近似满足独立的分布条件,并将各层的输出限定在一定的范围
3.在深度学习中常用的归一化方法:零均值归一化,也称为标准化方法,它用每一个变量值与其平均值之差除以该变量的标准差。经过这样的处理后,数据符合均值为0标准差为1的标准正态分布;
2,BN
Batch Normalization “批归一化”:Batch是批量的数据,即每次优化点的样本数目,通常BN层用在卷积层后面,用于重新调整数据分布;
将数据分为若干组,按组进行数据的更新参数,一组中的数据共同决定了本次梯度的方向,从而减少了下降的随机性;
具体的步骤为:
假设Batch Normalization的大小是m

其操作可以分成2步,
- Standardization:首先对m个x进行归一化,得到新的归一化的x^。
- scale and shift:然后对x^进行尺度缩放和偏移到新的分布y具有新的均值β方差γ。
BN的优势:
1)减轻对初始值的依赖;
2)训练更快,可以使用更高的学习速率;
缺点:
1)依赖批量的次数,例如ResNet 网络, Batch从16降低到8时,性能明显下降。
Batch Normalization的使用,需要根据实际的应用场景选择改。小的Batch 不适合应用在较大的场景检测中。
使用下面一个例子说明BN的操作过程:


实现代码如下:
import random
import torch.nn as nn
import torch
def BN(feature, mean, var):
feature_shape = feature.shape # (2, 2, 2, 2) = (batch_size, C, H, W)
for i in range(feature_shape[1]): # feature_shape[1] = 2 = C: channel
# [batch, channel, height, width]
feature_t = feature[:, i, :, :]
mean_t = feature_t.mean() # 求出整个channel的mean
# 训练:总体标准差
std_t1 = feature_t.std() # 求出整个channel的std
# 测试:样本标准差
std_t2 = feature_t.std(ddof=1)
# bn 对第i个channel的每一个元素 进行norm 初始伽马=1 贝塔=0
feature[:, i, :, :] = (feature[:, i, :, :] - mean_t) / std_t1
# update calculating mean and var 记录下mean和var用于测试集用
# 训练时使用总体标准差 测试时使用样本标准差
# 0.1为momentum
mean[i] = mean[i] * (1-0.1) + mean_t * 0.1
var[i] = var[i] * (1-0.1) + (std_t2 ** 2) * 0.1
return feature, mean, var
if __name__ == '__main__':
random.seed(1)
# 随机生成一个batch为2,channel为2,height=width=2的特征向量
# [batch, channel, height, width]
feature = torch.randn(2, 2, 2, 2)
print("=============feature================")
print(feature)
# 初始化统计均值和方差
mean = [0.0, 0.0]
variance = [1.0, 1.0]
# print(feature1.numpy())
# # 注意要使用copy()深拷贝
feature_bn, mean_bn, variance_bn = BN(feature.numpy().copy(), mean, variance)
print("================feature_bn_myself================")
print(feature_bn)
print("================mean================")
print(mean_bn)
print("================variance================")
print(variance_bn)
#
bn = nn.BatchNorm2d(2)
output = bn(feature)
print("================feature_bn_pytorch================")
print(output)
BN的优点总结
1,调参简单多了,对于权重初始化要求没那么高
2,起到了正则化的效果,可以不再使用Dropout,也可以不再使用L2正则化,
3,可以使用大的学习率而没有任何副作用,大大的加速了训练
4,一定程度缓解了深层网络中“梯度弥散(特征分布较散)”的问题
5,改善了Internal Covariate Shift(内部协变量偏移)现象
总而言之,经过这么简单的变换,带来的好处多得很,这也是为何现在BN这么快流行起来的原因。
使用BN的注意事项
1,训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
2,batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
3,建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias
3,Batch Renormalization
为了解决Batch Normalization对 Batch参数的依赖,提出了该方法的优化方法。Batch Normalization使用每个Batch的均值和方差来替代整个训练集的均值和方差,这就要求Batch必须在各类中均匀采样。当Batch值很小的时候,这一点是很难满足的。这时Batch Renormalization是使用每个Batch的均值和方差替代整个训练集的均值和方差之后,再通过一个线性变换来逼近数据的真实分布。

4,CBN(Cross-Iteration Batch Normalization)
BN有一个致命的缺陷,那就是我们在设计BN的时候有一个前提条件就是当batch_size足够大的时候,用mini-batch算出的BN参数(μ和σ )来近似等于整个数据集的BN参数。但是当batch_size较小的时候,BN的效果会很差。如下图的BN线,随着batch_size的减小,BN的表现骤减。
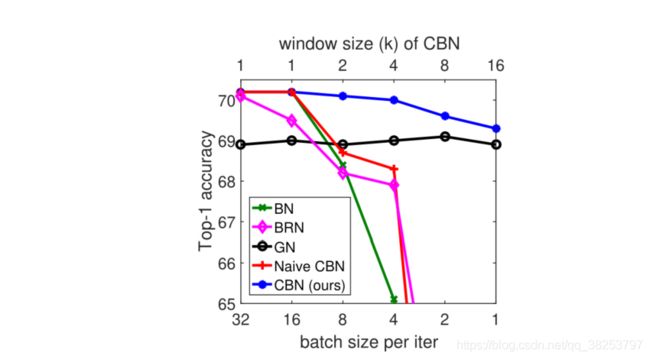
针对这个问题,很多学者从空间角度做了很多的尝试,比如LN、IN、GN等,但是这些方法都是针对不同的任务的,不具备一定的普适性。所以CBN就改变了思路,希望从时间维度尝试解决这个问题:batch_size太小,本质上还是数据太少不足以近似整个训练集的BN参数,那就通过计算前几个iteration计算好的BN参数(μ 和σ),一起来计算这次iter的BN参数。
转载博文:
【YOLO v4】Normalization: BN、CBN、CmBN_满船清梦压星河HK的博客-CSDN博客_cmbn和bn