深度学习笔记(6.DNN初始化权重和损失nan坑)
前言
权重初始化程序实现比较简单,修改dnn代码很少。不同初始化方式对结果影响很大。这部分根据课件实现了3中初始化方法,基本就是copy代码。但是这部分遇到了一个大坑,梯度爆炸还是消失。导致random随机初始化调试了好久才和课件上边的结果对上。这个目前还说不清楚,只能给出实验结果和程序修改过程,说一下大致数据变化。代码已更新
程序地址:https://github.com/ConstellationBJUT/Coursera-DL-Study-Notes
初始化公式
直接贴代码了,感觉很明了。he初始化公式,在随机初始化基础上除以下边的公式
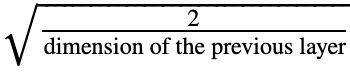
def init_parameters(self):
"""
初始化1~L层参数
:return:
"""
np.random.seed(3)
parameters = {}
for l in range(1, self.L + 1):
# 比直接*0.01效果好
if self.initialization == 'zeros':
Wl = np.zeros((self.layer_dims[l], self.layer_dims[l-1]))
elif self.initialization == 'random':
Wl = np.random.randn(self.layer_dims[l], self.layer_dims[l-1]) * 10
elif self.initialization == 'he':
Wl = np.random.randn(self.layer_dims[l], self.layer_dims[l-1]) * (np.sqrt(2. / self.layer_dims[l-1]))
else:
Wl = np.random.randn(self.layer_dims[l], self.layer_dims[l-1])/np.sqrt(self.layer_dims[l-1])
bl = np.zeros((self.layer_dims[l], 1))
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
return parameters
涉及代码修改文件
dnn.py : 深度神经网络程序
dnn_init_weight.py: 初始化权重实验程序
实验结果
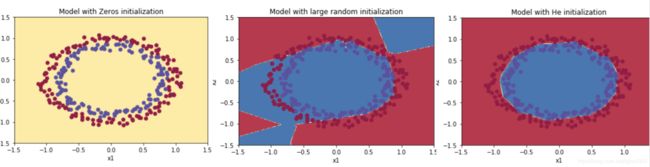
实验结果和课件给出的一模一样。从左到右依次是,zero、random、he,准确率变化很大。
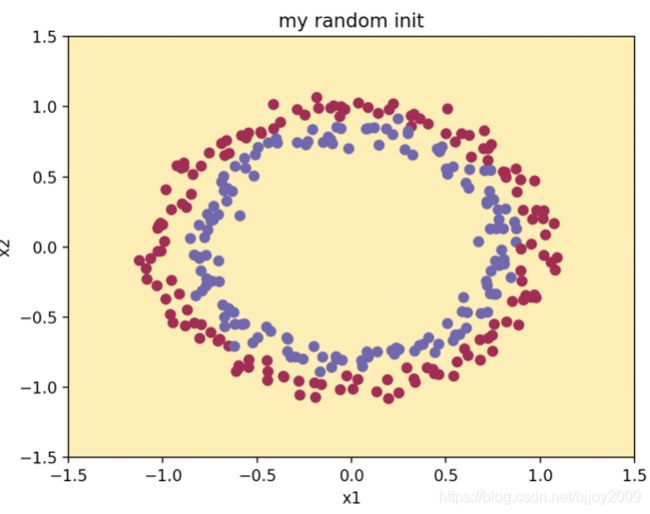
梯度爆炸和梯度消失坑
这个问题出现在random初始化,直接运行结果如下,可以看出准确率是0.5,损失是inf,之后多少次迭代都是-0.0
主要影响因素:程序中有Y/A和log(A),A接近或等于0.
程序中影响到结果的几个地方如下:
(1)损失函数(单纯计算,不影响最终结果,只是损失可能算的不对):
注释第一行:把AL限定最大和最小值,可以保证cost无法取值nan或者inf。
实际使用第二行:用nansum代替了sum,能保证cost是一个数或者inf,而不在出现nan。
# cost = (-1./self.m) * np.sum(np.multiply(Y, np.log(np.clip(AL, 1e-6, 1))) + np.multiply((1-Y), np.log(np.clip(1-AL, 1e-6, 1))))
cost = (-1./self.m) * np.nansum(np.multiply(Y, np.log(AL)) + np.multiply((1-Y), np.log(1-AL)))
(2)反向传播输出层计算(实际导致梯度爆炸地方)
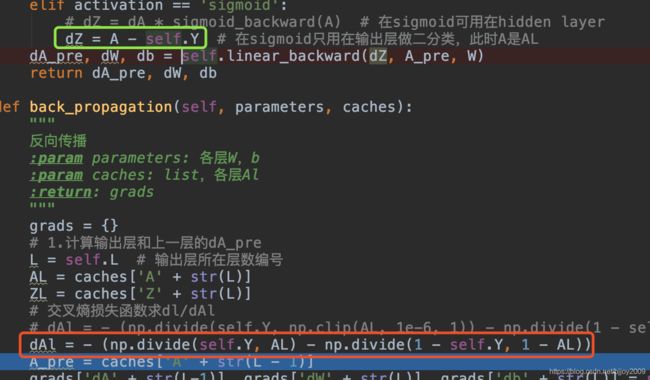
输出层求导代码如下2行:代码在下边给出(dAL=dA, sigmoid_backward(A)=AL*(1-AL))
dAL = -Y/AL - (1-Y)/(1-AL)
dZ = dAL * AL*(1-AL)
dAl = - (np.divide(self.Y, AL) - np.divide(1 - self.Y, 1 - AL))
dZ = dA * sigmoid_backward(A) # 在sigmoid可用在hidden layer
原因说明:权重初始值W太大,正向传播后AL全为1,导致1-AL基本为0,又导致(1-Y)/(1-AL)的值是inf和nan,有使得dAL矩阵值也由inf和nan组成。dZ自然也是inf和nan组成,再进入之后的迭代。如何下降都无法改变inf和nan的结局。
修改方法:输出层求导直接换成一行,保证dZ由0、1组成。修改后和课件random结果一样了。把上边两行代码由下边一行代替:
dZ = A - self.Y
程序中需要修改的就是反向传播程序:
代码绿色行,此时代码sigmoid不能作为隐藏层使用。
代码红色行,dAl虽然计算,但不再使用。
详情请看github程序
结论
程序调的差不多了,但对梯度爆炸和消失还是没有太多的感觉。用np.clip虽然可以限制数不能太大或太小,但是会导致损失根本不下降,一直是一个值。总的感觉来说,能公式直接算出来的就先不用中间步骤,减少除法和log的计算机会好一点吧。还需多感觉一下。