同性能下比MobileFormer快38倍!苹果提出对移动设备友好的高效主干网络MobileOne,运行时间小于1毫秒...
关注公众号,发现CV技术之美
本篇分享论文『An Improved One millisecond Mobile Backbone』,相同性能下比MobileFormer快38倍!苹果提出对移动设备友好的高效主干网络MobileOne,在 iPhone12 上的运行时间小于1毫秒!
详细信息如下:

论文链接:https://arxiv.org/abs/2206.04040
项目链接:
https://github.com/facebookresearch/mobile-vision/tree/4d5207cf50cdcf260e240871abf04686ab7087ed/mobile_cv/arch/fbnet_v2 (Facebook 工程师的实现,非官方)
https://github.com/shoutOutYangJie/MobileOne (性能接近,非官方)
01
摘要
移动设备的高效神经网络主干通常针对FLOPs或参数计数等指标进行优化。然而,当部署在移动设备上时,这些指标可能与网络的延迟没有很好的相关性。因此,作者通过在移动设备上部署多个移动友好的网络来对不同的指标进行广泛的分析。作者识别和分析了最近高效神经网络中的架构和优化瓶颈,并提供了缓解这些瓶颈的方法。
为此,作者设计了一种高效的主干网络MobileOne,其变体在iPhone12上的推断时间小于1 ms,在ImageNet上的准确率为75.9%。作者表明,MobileOne在高效的结构中实现了最先进的性能,同时在移动设备上的速度快了很多倍。本文的最佳模型在ImageNet上的性能与MobileFormer相似,但速度要快38倍。
在相同的延迟下,本文的模型在ImageNet上的top-1准确性比EfficientNet高2.3%。此外,作者还表明,与部署在移动设备上的现有高效结构相比,本文的模型可推广到多个任务–图像分类、目标检测和语义分割,在延迟和准确性方面有显著改进。
02
Motivation
为移动设备设计和部署高效的深度学习结构取得了很大进展,不断减少浮点运算(FLOP)和参数计数,同时提高准确性。然而,就延迟而言,这些指标可能与模型的效率不太相关。像FLOPs这样的效率指标并没有考虑内存访问成本和并行度,这可能会对推断过程中的延迟产生非常重要的影响。参数计数与延迟也没有很好的相关性。例如,共享参数会导致更高的FLOPs,但模型尺寸更小。此外,无参数操作(如残差连接或分支)可能会产生巨大的内存访问成本。
本文的目标是通过识别影响设备延迟的关键瓶颈,提高高效结构的延迟成本,同时提高其准确性。为了识别这些瓶颈,作者使用CoreML在iPhone12上部署了神经网络,并对其延迟成本进行了基准测试。优化是另一个瓶颈,尤其是在训练容量有限的较小神经网络时。这可以通过解耦训练时间和推理时间架构来缓解,即在推理时重新参数化线性结构的参数。作者通过在整个训练过程中动态放松正则化来防止已经很小的模型被过度正则化,从而进一步缓解优化瓶颈。
基于对模型结构和优化瓶颈的研究结果,作者设计了一种新型结构MobileOne,其变体在iPhone12上运行时间不超过1毫秒,在高效结构系列中实现了最先进的准确性,同时在设备上运行速度显著加快。与之前关于结构重新参数化的工作一样,MobileOne在训练运行时引入了线性分支,这些分支在推理时重新参数化。
本文的模型与之前的结构重参数化工作之间的关键区别在于引入了over-parameterization分支,这进一步改进了低参数区域和模型缩放策略。在推理时,本文的模型具有简单的前馈结构。由于这种结构产生了较低的内存访问成本,作者可以在网络中加入更宽的层,从而提高表示能力。MobileOne-S1的参数为4.8M,延迟为0.89ms,而MobileNet-V2的参数为3.4M(比MobileOne-S1少29.2%),延迟为0.98ms。在此操作上,MobileOne的top-1精度比MobileNet-V2高3.9%。
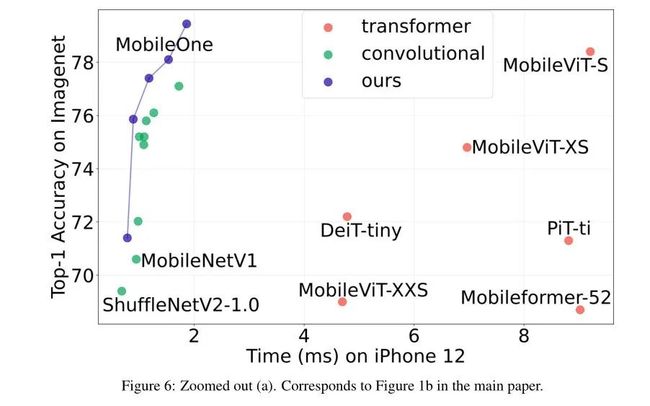
与高效模型相比,MobileOne在延迟方面取得了显著改进,同时在图像分类、目标检测和语义分割等多项任务上保持了准确性。如上图所示,MobileOne的性能优于MobileViT-S,同时在图像分类方面的速度是MobileViT-S的5倍。

如上图所示,与EfficientNet-B0相比,本文在ImageNet上实现了2.3%的top-1精度提升,并且延迟成本相似。

如上图所示,MobileOne模型不仅在ImageNet上表现良好,还可以推广到其他任务,如目标检测。
本文的主要贡献如下:
本文提出了MobileOne,这是一种在移动设备上运行时间不超过1 ms的新型结构,在高效的模型结构中实现了最先进的图像分类精度。本文模型的性能也推广到桌面级CPU。
作者分析了在最近高效的网络中,在移动设备上导致高延迟成本的激活函数和分支中的性能瓶颈。
作者分析了训练中训练时可重参数化分支和正则化动态松弛的影响。结合起来,它们有助于缓解训练小型模型时遇到的优化瓶颈。
本文的模型可以很好地推广到其他任务——目标检测和语义分割,同时优于以前最先进的高效模型
03
方法
3.1 Metric Correlations
比较两个或多个模型的大小最常用的成本指标是参数计数和FLOPs。然而,它们可能与实际移动应用程序中的延迟没有很好的相关性。因此,作者研究了延迟与FLOPs和参数计数的相关性。
作者考虑了最新的模型,并使用它们的Pytorch实现将其转换为ONNX格式,使用Core ML工具将这些模型转换为coreml包。然后,作者开发了一个iOS应用程序来测量iPhone12上模型的延迟。
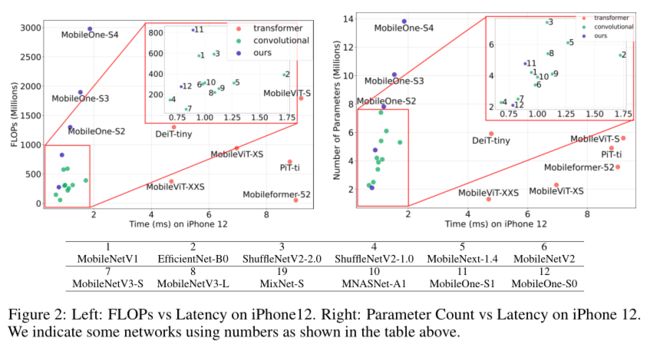
作者绘制了延迟与FLOPs以及延迟与参数计数的关系图,如上图所示。可以观察到,许多具有较高参数计数的模型可以具有较低的延迟,FLOPs和延迟之间有类似曲线。此外,作者注意到卷积模型,如MobileNets,对于类似的FLOPs和参数计数,其延迟比对应的Transformer更低。
在下表中,作者还估算了Spearman rank correlation。对于移动设备上的高效体系结构,延迟与FLOPs中度相关,与参数计数弱相关。这种相关性在桌面CPU上甚至更低。

3.2 Key Bottlenecks
Activation Functions

为了分析激活函数对延迟的影响,作者构建了一个30层卷积神经网络,并使用高效的CNN主干中常用的不同激活函数在iPhone12上对其进行了测试。除了激活之外,上表中的所有模型都具有相同的体系结构,但它们的延迟截然不同。这可归因于同步成本,主要是由最近提出的激活函数(如SE ReLU、Dynamic Shift Max和DynamicCrelus)产生的。
DynamicReLU和dynamicshift-Max在极低的FLOPs模型(如MicroNet)中表现出了显著的改进,使用这些激活的延迟成本可能非常大。将来,这些激活函数可能会得到硬件加速,但其好处将限于实现它们的平台。因此,作者仅在MobileOne中使用ReLU激活。
Architectural Blocks
影响运行时性能的两个关键因素是内存访问成本和并行度。在多分支体系结构中,内存访问成本显著增加,因为必须存储每个分支的激活,以计算图中的下一个张量。如果网络具有较少的分支,则可以避免此类内存瓶颈。
强制同步的结构块(如SENet中使用的全局池化操作)也会由于同步成本而影响总体运行时间。为了证明隐藏的成本,如内存访问成本和同步成本,作者在一个30层卷积神经网络中使用残差连接和SE(Squeeze-Excite)块来消融。
在下表中,作者展示了每种选择是如何影响延迟的。因此,作者采用了一种在推理时没有分支的体系结构,从而降低了内存访问成本。此外,为了提高精度,作者在本文最大的变体上限制了SE块的使用。

3.3 MobileOne Architecture
基于对不同设计选择的评估,作者开发了MobileOne的结构。与之前关于结构重参数化的工作一样,MobileOne的训练和推理架构是不同的。
MobileOne Block

MobileOne块与重参数工作中提出的块相似,不同之处在于本文的块是为卷积层设计的,卷积层被分解为depthwise层和pointwise层。此外,作者引入了trivial over-parameterization branches ,这提供了进一步的收益。
本文的基本块构建在MobileNet-V1块上,该块由3x3深度卷积和1x1逐点卷积组成。然后,使用batchnorm以及复制结构的分支引入可重新参数化的残差连接,如上图所示。trivial over-parameterization 因子k是一个从1到5变化的超参数。在测试时,通过重参数技术,MobileOne模型没有任何分支。
对于核大小为K、输入通道尺寸为、输出通道尺寸为的卷积层,权重矩阵表示为,bias表示为。batchnorm层包含累积均值µ、累积标准差σ、scale参数γ和bias参数β。由于卷积和batchnorm在推理时是线性运算,因此可以将它们折叠到一个权值为,bias为的卷积层中。
Batchnorm被折叠到所有分支的前一个卷积层中。对于残差连接,batchnorm被折叠为1x1的卷积层(关于重参数技术的细节可以参见丁霄汉的ACNet、RepVGG、DBBNet的论文)。在获得每个分支中的batchnorm折叠权重后,获得推理处卷积层的权重和bias,其中M是分支数。

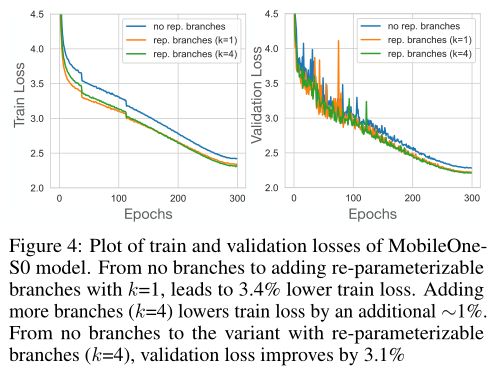
为了理解trivial over-parameterization分支的重要性,在上表中,作者对rivial over-parameterization因子k的选择进行了讨论。对于更大的MobileOne变体,从简单的参数化改进开始逐渐减少。对于较小的变体,如MobileOne-S0,可以看到通过使用简单的参数化分支,改进了0.5%。在下图中,可以看到添加可重新参数化的分支可以改进优化,因为训练和验证损失都进一步降低。
Model Scaling
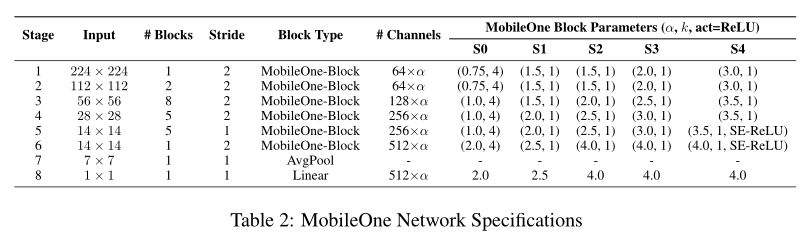
最近的作品缩放了模型尺寸,如宽度、深度和分辨率,以提高性能。MobileOne具有与MobileNet-V2相似的深度缩放。作者提出了5种不同的模型大小,如上表所示。此外,作者没有探讨随着FLOPs和内存消耗的增加,输入分辨率的放大,这对移动设备上的运行时性能有害。
由于模型在推理时没有多分支的体系结构,因此不会产生前面章节中讨论的数据移动成本。这使本文的模型能够与多分支架构(如MobileNet-V2、EfficientNets等)相比,积极地扩展模型参数,而不会产生显著的延迟成本。增加的参数计数使本文的模型能够很好地推广到其他计算机视觉任务,如目标检测和语义分割。
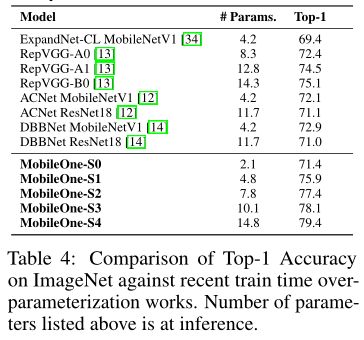
在下表中,作者将最近的模型运行时间与重参数化工作进行了比较,可以看出MobileOne-S1变体优于RepVGG-B0。
3.4 Training

与大型模型相比,小型模型需要较少的正则化来防止过度拟合。因此,在训练的早期阶段weight decay是很重要的。作者发现,在训练过程中,对weight decay正则化引起的损失进行退火处理更有效,而不是完全消除weight decay正则化。
在本文所有的实验中,作者使用cosine schedule来计算学习率。因此,只需使用相同的cosine schedule来退火权重衰减系数。在上表中,作者对各种训练设置进行了烧蚀,保持所有其他参数不变。可以看到退火权重衰减系数提高了0.5%
3.5 Benchmarking
在移动设备上获得准确的延迟测量可能很困难。在iPhone 12上,没有命令行访问或功能来保留所有计算结构,仅用于模型执行。也无法将往返延迟细分为网络初始化、数据移动和网络执行等类别。
为了测量延迟,作者使用swift开发了一个iOS应用程序来对这些模型进行基准测试。应用程序使用Core ML运行模型。为了消除启动不一致,加载模型图,预先分配输入张量,并在基准测试开始之前运行一次模型。在基准测试期间,应用程序会多次运行该模型(默认值为1000),并累积统计数据。为了实现最低的延迟和最高的一致性,手机上的所有其他应用程序都将关闭。
对于实验中所示的模型延迟,作者报告了完整的往返延迟。这一时间的很大一部分可能来自非模型执行的平台进程,但在实际应用程序中,这些延迟可能是不可避免的。因此,作者选择将它们包括在报告的延迟中。为了过滤掉来自其他进程的中断,作者报告了所有模型的最小延迟。对于CPU延迟,作者在带有2.3 GHz–Intel Xeon Gold 5118处理器的Ubuntu桌面上运行这些模型。
04
实验

上表展示了本文模型和其他方法在IPhone和CPU上进行ImageNet分类时候的对比,可以看出,本文的模型能够在较低的延迟下,实现较高的性能。

上表展示了本文方法的目标检测和语义分割上的实验结果,可以看出本文的方法在其他任务上具有很强的泛化性。

上图展示了MobileOne-S2-SSDLite和MobileNetV2-SSDLite进行目标检测的定性结果。

上表展示了本文方法和其他方法在分割任务上的定性结果
05
总结
本文为移动设备提出了一种高效的通用主干网。该主干适用于图像分类、目标检测和语义分割等一般任务。作者表明,在有效的机制中,延迟可能与其他指标(如参数计数和FLOPs)没有很好的相关性。此外,作者通过直接在移动设备上测量CNN的延迟来分析现代高效CNN中使用的各种架构组件的效率瓶颈。
实验表明,通过使用可重新参数化的结构,优化瓶颈得到了改善。本文的模型缩放策略使用可重新参数化的结构,在移动设备和桌面CPU上都很有效,同时达到了最先进的性能。
参考资料
[1]https://arxiv.org/abs/2206.04040

END
加入「计算机视觉」交流群备注:CV
