GZIP文件压缩原理以及实现
目录
一、简单介绍Huffman压缩
1.Huffman压缩原理及流程
2.Huffman压缩格式
3.Huffman解压缩步骤
4.Huffman压缩的优缺点
二、简单介绍LZ77压缩
1.LZ77压缩算法原理及流程
1.1压缩原理
1.2压缩具体流程
1.3哈希桶的设计
1.4元素的插入
1.5最长匹配的查找
1.6补充窗口数据
1.7压缩伪码
2.LZ77压缩文件格式
3.LZ77解压缩
3.1解压缩的具体步骤
3.2解压缩的伪码
三、GZIP压缩
1.GZIP压缩算法的原理及流程
1.1压缩算法的原理
1.2压缩具体流程
1.3源字符和长度的压缩
1.4.距离的压缩
1.5压缩相关的代码
2.压缩文件的格式
3.解压缩
3.1解压缩的流程
3.2解压缩的伪代码
四、泛式Huffman树
1.Huffman树的缺陷
2.泛式Huffman树
3.泛式Huffman树的创建
五、压缩效率的比较
一、简单介绍Huffman压缩
1.Huffman压缩原理及流程
1.1压缩原理:使用文件中字符出现的次数构造Huffman树,生成Huffman编码,使用Huffman编码对源文件进行压缩。
1.2压缩具体流程
- 打卡被压缩文件,获取文件中每个字符出现的总次数
- 将文件后缀以及统计好的字符信息(字符出现的次数)写入压缩文件用于解压缩使用
- 以每个字符串出现的总次数为权值构造Huffman树
- 通过Huffman树获取每个字符的Huffman编码
- 读取源文件,对源文件中的每个字符使用获取的Huffman编码进行改写,将改写结果写到压缩文件中,直到文件结束
2.Huffman压缩格式

3.Huffman解压缩步骤
- 从压缩文件中获取源文件的后缀
- 从压缩文件中获取字符次数的总行数
- 获取每个字符出现的次数
- 重建Huffman树
4.Huffman压缩的优缺点
优点:实现简单
缺点:压缩效率较低,原因如下:
1.Huffman压缩中如果字符的种类较多且出现的次数又很均匀就会导致Huffman树很高,导致编码位数较长,从而导致压缩效率较低,当编码位数超过8位时甚至可能导致压缩文件变大。
2.Huffman的压缩文件中除了需要保存压缩源文件的部分之外还需要额外保存字符出现的频次信息,导致压缩文件较大(如果使用泛式Huffman树则只需要保存编码位长)
3.每次解压缩都需要先构造Huffman树(泛式Huffman树可以解决)
二、简单介绍LZ77压缩
1.LZ77压缩算法原理及流程
1.1压缩原理
LZ77是基于字节的通用压缩算法,它的原理就是将源文件中的重复字节(即在前文中出现的重复字节)使用(长度,距离)对进行替换,从而达到压缩的目的。
1.2压缩具体流程
(1)打开待压缩的文件(注意:必须按照二进制的格式打开,因为用户进行压缩的文件不确定)
(2)获取文件的大小,如果文件大小小于3个字节,则不进行压缩
(3)读取一个窗口的数据,即64K
(4)用前两个字符计算第一个字符与后两个字符构成字符串哈希地址的一部分,因为哈希地址是通过3个字节计算出来的,先用前两个字节算出一部分,再结合第三个字节算出第一个字符串完整的哈希地址。
(5)循环开始压缩
- 计算哈希地址,将该字符串首地址在窗口中的位置插入到哈希桶中,并返回该桶的状态matchHead
- 根据matchHead检测是否找到匹配
- 如果matchHead等于0,未找到匹配,表示该三个字符在前文中没有出现过,将该字符作为源字符写到压缩文件中
- 如果matchHead不等于0,表示找到匹配,matchHead代表匹配链的首地址,从哈系统matchHead位置开始找最长匹配,找到后用该(距离,长度对)替换该字符串写到压缩文件中,然后将该替换串三个字符一组添加到哈希表中
- 如果窗口中的数据小于MIN_LOOKAHEAD时,将右窗口中数据搬移到左窗口,从文件中重新读取一个窗口的数据放到右窗,更新哈希表,继续压缩,直到压缩结束。
1.3哈希桶的设计
哈希桶的设计
因为时每3个字符一组进行插入,三个字符可以组成2的24次方种取值,桶的个数需要2的24次方个,而每个字符占2字节,总共桶需要占32M字节,是一个非常大的开销。这是一个非常大的开销,会降低程序的运行效率,因此我们将哈希桶的个数缩小为:2^15(即32K)
原本需要2^24个桶现在缩小为2^15个桶,难免会产生哈希冲突,如果使用开散列解决,链表中的节点要不断申请与释放,而且浪费空间,影响呈现效率。因此我们的哈希表采用一整块连续的内存构成,分成两个部分,每部分大小为一个WSIZE(32K),如下图
prev指向整个内存的起始位置,head = prev + WSIZE,内存是连续的,所以prev和head可以看作两个数组,即prev[]和head[].
head数组用来保存三个字符串首字符的索引位置,head的索引为三个字符通过哈希函数计算的哈希值,而prev就是用来解决冲突的。

1.4元素的插入
元素的插入
1.将新插入的字节与前两个字节构成一个三字节的字符串
2.使用哈希函数计算出哈希地址headAddr
3.将该本次要插入的三个字节的首字节插入到headAddr的地址(如果需要则进行碰撞处理)
4.将matchHead(最近的一个匹配串)带出去
// hashAddr:上一次哈希地址 //ch:三个字节中的第三个字节 // pos:三个字节中的第一个字节在窗口中的下标 //matchHead:如果匹配,保存匹配串的起始位置 void HashTable::InsertString(ush& hashAddr, uch ch, ush pos, ush& macthHead) { HashFunc(hashAddr, ch); //1.将hassAddr位置存储的前文中的匹配搬移到prev的pos位置 _prev[pos & HASH_MASK] = _head[hashAddr]; //2.将前文中找到匹配的最近一个通过macthHead带出去 macthHead = _head[hashAddr]; //3.将本次要插入的三个字节的首字节插入到head的headAddr位置 _head[hashAddr] = pos; }
1.5最长匹配的查找
最长匹配的找法
1.通过带出的matchHead进行判断
2.如果不等于0,则证明在查找缓冲区中找到了匹配
则进行最长匹配的查找(查找的时候注意控制查找的距离)
//获取最长匹配的字符串 //这里的距离是通过出参带出,长度是通过返回值返回的 ush Lz77::LongestMatch(ush matchHead, ush &matchDis,ush start) { ush curMatchDis = 0; ush curMatchLength = 0; ush bestLen = 0; //当使用掩码将start越界位置的值向_prev中搬移的时候有可能会覆盖之前_prev位置的值,如果之前该位置保存的下表为0 //则有可能会造成死循环,所以我们在这里需要控制查找的次数 uch maxMatchCount = 255; //往左侧找的时候不能找的太远 ush limit = start >= MAX_DIS ? start - MAX_DIS : 0; do { uch* pstart = _pWin + start; uch* pend = pstart + MAX_MATCH;//限制匹配字符串的长度 uch* pbegin = _pWin + matchHead; curMatchDis = 0; curMatchLength = 0; while (pstart < pend && *pstart == *pbegin) { pstart++; pbegin++; curMatchLength++; } curMatchDis = start - matchHead; if (curMatchLength > bestLen) { bestLen = curMatchLength; matchDis = curMatchDis; } } while ((_ht.GetPrevMatch(matchHead) < limit) && maxMatchCount--); if (curMatchDis > MAX_DIS) { bestLen = 0; } return bestLen; }
1.6补充窗口数据
窗口数据的补充
随着压缩的进行,先行缓冲区逐渐缩小,当缓冲区的大小小于我们设定的阈值的时候,即 lookhead <= MIN_LOOKAHEAD(MIN_LOOKAHEAD = MIN_MATCH(最短匹配距离:3) + MAX_MATCH(最长匹配距离:258) + 1),就需要对窗口进行填充
填充的步骤:
- 将右窗的数据搬到左窗中
- 更新哈希表,因为将右窗的数据搬移到左窗,则新搬到左窗的数据的下标需要进行更新
- 往右窗口填入数据
代码
void Lz77::FillWindow(FILE* fIn, ull& lookahead, ush& start) { if (start >= WSIZE + MAX_DIS) { //1.需要将右窗口的数据搬移到做窗口,因为从start位置向前找的时候最远只能找MAX_DIS的距离(局部匹配原则) memcpy(_pWin, _pWin + WSIZE, WSIZE); start -= WSIZE; //2.更新哈希表 //刚才在搬移的过程中,将右窗的数据搬移到了左窗,查找缓冲区中的字节的下标发生了变化,而哈希表中存储的就是查找缓冲区 //中三个字节一组首字节在窗口中的下标,既然下标发生了变化,必须要更新哈希表 _ht.UpdataTable(); //3.往右窗中填充WSIZE的数据 if (!feof(fIn)) { lookahead += fread(_pWin + WSIZE, 1, WSIZE, fIn); } } }注:哈希表的更新就是将左窗中保存的数据大于WSIZE的减去WISIZE,小于WSIZE的变为0即可,因为存在链表成环的问题,所以在找最长匹配的时候需要控制循环的次数。
1.7压缩伪码
//直接以二进制格式打开文件
FILE* fIn = fopen(fileName.c_str(), "rb");
//计算文件的大小
fseek(fIn, 0, SEEK_END);
ull fileSize = ftell(fIn);
fseek(fIn, 0, SEEK_SET);
if (fileSize <= MIN_MATCH)
{
//文件大小小于3,关闭文件
}
//向窗口中读取数据
ull lookhead = fread(_pWin, 1, 2 * WSIZE, fIn);
//需要先将前两个字节读入hashTable
for (uch i = 0; i < MIN_MATCH - 1; i++)
{
_ht.InsertString(hashAddr, _pWin[i], i, matchHead);
}
while (lookhead)
{
//将要查找的字串插入hashTable中,找距离最近的一个匹配串,通过出参带出来
_ht.InsertString(hashAddr, _pWin[start + 2], start, matchHead);
//查找缓冲区中存在匹配的字符串
if (matchHead != 0)
{
//在查找缓冲区中找到了匹配的字符串
//找最长匹配
}
if (matchLength < MIN_MATCH)
{
//没有找到符合条件的匹配串(匹配长度大于等于3的字符串 )
//将原字符串直接写入压缩文件中
}
else
{
//找到了匹配
//将长度和距离写入压缩文件
//这里需要将匹配上的那部分字符串也放入哈希表中
}
if (lookhead <= MIN_LOOKAHEAD)
{
//向窗口中填充数据
}
}
//额外处理最后剩余的不足8bit的字节
if (bitCount > 0 && bitCount < 8){}
}2.LZ77压缩文件格式
两个文件:
文件1:保存的是用于解压缩的标记位的信息
文件2:保存的压缩后的源文件(源字符和长度距离对)
3.LZ77解压缩
3.1解压缩的具体步骤
- 从文件1中读取标记,并对该标记进行分析
- 如果当前标记的是0,则表明到了读取到的是源字符,直接从文件2中读取一个字节放在解压缩后的文件中
- 如果当前标记的是1,则表明读到了长度距离对,则从文件2中读取到长度距离对,然后从解压缩的结果中找出匹配的字符串并写入解压缩的文件
- 获取下一个标记,直到所有的标记解析完
3.2解压缩的伪码
void Lz77::UNCompressFile(const string fileName)
{
//打开压缩文件和标记位文件
FILE* fIn = fopen(fileName.c_str(), "rb");
FILE* flag = fopen("temp.fzp", "rb");
//读取文件的大小
fseek(flag, -8, SEEK_END);
ull fileSize = 0;
fread(&fileSize, 1, sizeof(fileSize), flag);
fseek(flag, 0, SEEK_SET);
//打开解压缩后的文件,一次写,一次读(为了找匹配的)
FILE* fOut = fopen(unFileName.c_str(), "wb");
FILE* fR = fopen(unFileName.c_str(), "rb");
uch bitInfo = 0;
uch bitCount = 0;
ull uncompressSize = 0;
while (uncompressSize < fileSize)
{
if (bitCount == 0)
{
bitInfo = fgetc(flag);
bitCount = 8;
}
if (bitInfo & 0x80)
{
//读取到的是长度距离对
ush matchLength = fgetc(fIn) + 3;
ush matchDis = 0;
fread(&matchDis, 1, sizeof(matchDis), fIn);
uncompressSize += matchLength;
//之前解压缩的内容可能还在缓冲区中,所以在匹配之前
//先将缓冲区当中的内容写入解压缩文件
fflush(fOut);
fseek(fR, 0 - matchDis, SEEK_END);
while (matchLength--)
{
//从解压缩后的文件中找匹配的字符,写入文件
}
}
else
{
//读取到的是普通字符,直接写入文件
}
bitInfo <<= 1;
bitCount--;
}
//关闭各种文件
}三、GZIP压缩
1.GZIP压缩算法的原理及流程
1.1压缩算法的原理
GZIP压缩就是LZ77压缩和Huffman压缩的结合,但并不是直接将LZ77压缩的结果使用Huffman再压缩一次。
原因:
a.LZ77之后,有接近1/8的大小是标记位,如果直接采用Huffman的方式压缩LZ77的结果,标记位也会参与压缩
b.LZ77之后,压缩文件的结果也会非常大,直接交给Huffman压缩,可能会导致Huffman树非常高,可能就会导致平均每个字节的编码超过8个比特位,就会导致压缩结果较大,从而影响压缩效率
GZIP压缩算法就是针对上述的两条缺陷进行改进,
- a.GZIP压缩中,将源字符和长度放在一个放在一颗Huffman树进行压缩,将距离使用另一颗Huffman树进行压缩
- b.因为源字符和长度使用一颗Huffman树进行编码,所以为了对源字符和长度进行区分,将长度统一向后偏移了257位
- c.为了解决二叉树节点过多的情况,对其节点进行了分区
- d.使用了泛式Huffman树进行编码,压缩文件中只需要保存编码位长即可,这样解压缩的时候不需要构造Huffman树
- e.对大文件采取分片压缩的方式,这样就不会导致Huffman树过高
1.2压缩具体流程
因为前面部分与与LZ77相同,所以这里直接描述与LZ77压缩不同的部分
- a.在LZ77中不是将找到的字符和长度距离对直接写入源文件,而是使用数组保存(源字符和长度保留在一个数组,距离保留在一个数组,标记位保存在一个数组中),以待进一步压缩
- b.当保存字符和长度的大小达到设定的块大小时对文件进行压缩
- 压缩步骤:
- (1)统计字符出现的次数
- (2)构建Huffman树
- (3)获取编码位长:每个叶子节点的高度
- (4)生成Huffman编码:按照编码位长为第一字段,然后以字节大小为第二字段进行排序
- (5)写解压缩时需要用到的信息及编码位长
- (6)压缩
1.3源字符和长度的压缩
上述说到因为我们将源字符和长度使用一颗Huffman树进行压缩,为了区分二者将长度向后偏移257位,即我们使用整数[0~255]表示原字符,256表示块结束标记,即解码以后是256表示解码结束,从257开始表示距离,比如:257表示重复3个字符,258重复4个字符,但如果这样一一对应那么岂不是Huffman树要表示256 + 256 + 1 = 513个节点,岂不是树要很高?
所以我们将长度进行了分区,分成了29个区间,如下图
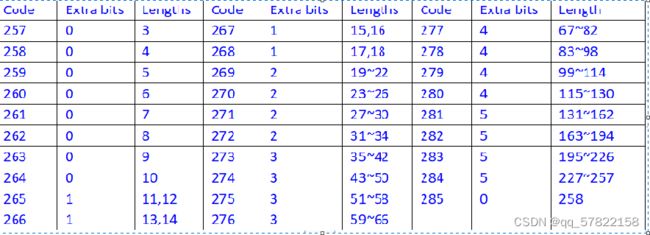
例如:当匹配的长度是40时,编码的步骤如下
- a.先要找到该长度属于哪个分区:273分区
- b.从Huffman树中找到273分区对应的编码-----写入压缩文件
- c.40属于该分区的第40-35=5:101写入到压缩文件
1.4.距离的压缩
距离的压缩和长度类似,也有属于自己的区间
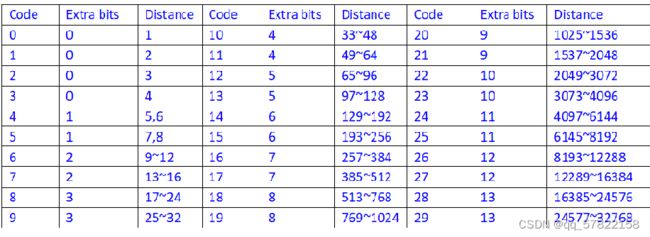
如上图可知,长度被分为了30个区间,这样划分的原因是根据重复的局部性原理,即距离越近出现重复字符串的概率越大,越远概率越小,所以我们将距离越近位置的编码设置的相对较短(区间小-----》额外的比特位少)
1.5压缩相关的代码
压缩伪代码
void LdZip::Deflate(const string fileName)
{
//注意:Lz77是通用的压缩算法,文本文件和二进制格式的文件都可以压缩
//直接以二进制格式打开文件
FILE* fIn = fopen(fileName.c_str(), "rb");
if (nullptr == fIn)
{
//待压缩文件打开失败
}
//计算文件的大小
fseek(fIn, 0, SEEK_END);
ull fileSize = ftell(fIn);
fseek(fIn, 0, SEEK_SET);
if (fileSize <= MIN_MATCH)
{
//文件大小小于等于3个字节不需要进行压缩
}
//向窗口中读取数据
ull lookhead = fread(_pWin, 1, 2 * WSIZE, fIn);
ush hashAddr = 0;
ush matchHead = 0;
uch bitInfo = 0;
uch bitCount = 0;
//需要先将前两个字节读入hashTable
for (uch i = 0; i < MIN_MATCH - 1; i++)
{
_ht.InsertString(hashAddr, _pWin[i], i, matchHead);
}
ush start = 0;
while (lookhead)
{
ush matchLength = 0;
ush matchDis = 0;
matchHead = 0;
_ht.InsertString(hashAddr, _pWin[start + 2], start, matchHead);
//查找缓冲区中存在匹配的字符串
if (matchHead)
{
//找最长匹配
matchLength = LongestMatch(matchHead, matchDis, start);
}
if (matchLength < MIN_MATCH)
{
//没有找到匹配(匹配长度大于等于3的字符串 )
//将原字符存入准备好的buff
}
else
{
//找到了匹配
//将长度距离保存到我们准备的buff中
//这里需要将匹配上的那部分字符串也放入哈希表中
while (matchLength--)
{
_ht.InsertString(hashAddr, _pWin[start + 2], start, matchHead);
start++;
}
}
if (lookhead <= MIN_LOOKAHEAD)
{
//向窗口中填充数据
FillWindow(fIn, lookhead, start);
}
}
if (_byteLengthLz77.size() < BUFF_SIZE)
{
//压缩文件最后一块可能大小不够BUFF_SIZE的块
CompressBlock();
}
fclose(fIn);
fclose(fOut);
}CompressBlock/块压缩代码
void LdZip::CompressBlock()
{
//0.清空前一个块的数据信息
ClearPrevStatInfo();
//1.统计字符出现的个数
StatAppearCount();
//2.构建Huffman树
huffmanTreebyteLengthTree(_byteLengthInfo, ByteLengthInfo());
huffmanTreedistTree(_distInfo, ByteLengthInfo());
//3.获取编码位长:将每个叶子节点高度
//4.生成Huffman编码:按照编码位长为第一字段,然后以字节大小为第二字段进行排序
//获取原字符和长度对应huffman中编码位长以及具体编码
GetCodeLen(byteLengthTree.GetRoot(), _byteLengthInfo);
GenerateHuffmanCode(_byteLengthInfo);
//获取距离对应huffman中编码位长以及具体编码
GetCodeLen(distTree.GetRoot(), _distInfo);
GenerateHuffmanCode(_distInfo);
//5.写解压缩时需要用到的信息----写编码位长
WriteInfo(fOut);
//6.压缩
uch bitInfo = 0;
uch bitCount = 0;
size_t flagIdx = 0;
size_t distIdx = 0;
uch CompressByteInfo = 0;
uch CompressByteCount = 0;
for (size_t i = 0; i < _byteLengthLz77.size(); i++)
{
if (0 == bitCount)
{
bitInfo = _flagLz77[flagIdx++];
bitCount = 8;
}
if (bitInfo & 0x80)
{
//_byteLengthLz77[i]是长度
//压缩一个长度距离对
CompressLengthDist(_byteLengthLz77[i], _distLz77[distIdx++], CompressByteInfo, CompressByteCount);
}
else
{
//_byteLengthLz77[i]是原字符
//压缩一个原字符
CompressByte(_byteLengthLz77[i], CompressByteInfo, CompressByteCount);
}
bitInfo <<= 1;
bitCount -= 1;
}
//压缩一个256表示块结束
CompressByte(256, CompressByteInfo, CompressByteCount);
if (CompressByteCount > 0 && CompressByteCount < 8)
{
CompressByteInfo <<= (8 - CompressByteCount);
fputc(CompressByteInfo, fOut);
}
//将前一次Lz77的结果清空
_byteLengthLz77.clear();
_distLz77.clear();
_flagLz77.clear();
}
2.压缩文件的格式

3.解压缩
3.1解压缩的流程
(1)打卡解压缩的文件
(2)读取编码位长信息
(3)根据编码位长信息求出解码表
(4)根据解码表解压缩一个块
- 根据解码表读取待解压缩文件
- 解压缩出一个字符symbol
- 如果该字符小于256则证明是原字符,则直接写入解压缩后的问价
- 如果该字符等于256则表明解压缩到了该块的最后
- 如果该字符大于256则证明是一个长度
解压缩 一个字符的流程:
- 1.从解码表的第i行开始,根据编码位长从压缩数据比特流中获取相应长度的比特位
- 2.将读取的数据与首编码相减,假设结果为num
- 3.如果num>=符号数量,i++,继续1,如果num小于符号数量,进行4
- 4.将符号索引加上num,用该结果从符号位长表对应位置解析出该符号位
长度距离对的处理:
- 1.根据该字符在压缩时使用的长度区间表中进行查找,再加上额外的比特位计算出长度
- 2.对距离进行解码,同样使用解码后的下标索引index在距离区间表中进行查找,再加上额外的比特位信息,计算出距离
- 3.根据得到的(长度,距离对)进行解压缩,与LZ77相同
3.2解压缩的伪代码
///解压缩
void LdZip::UNDeflate(const string fileName)
{
//1.检验格式
//2.打开文件
FILE* fIn = fopen(fileName.c_str(), "rb");
//3.计算解压缩后文件的名字并打开
FILE*fOut = fopen(unCompressFileName.c_str(), "wb");
FILE*fR = fopen(unCompressFileName.c_str(), "rb");
while (true)
{
_isLast = fgetc(fIn);
//1.获取编码位长信息
GetCodeBitLenInfo(fIn);
//2.生产解码表
//处理原字符长度
vectorbyteLengthDT;
GenerateDecode(byteLengthDT, _byteLengthInfo);
//处理距离
vectordistDT;
GenerateDecode(distDT, _distInfo);
//解压缩一个块
uch ch = 0;
uch bitCount = 0;
int i = 0;
while (true)
{
i++;
ush symbol = UNCompressSymbol(fIn, _byteLengthInfo, byteLengthDT, ch, bitCount);
if (symbol < 256)
{
//解压缩出来一个原字符
}
else if (256 == symbol)
{
//一个块结束
}
else
{
//是长度距离
}
}
if (!_isLast)
{
break;
}
}
fclose(fIn);
fclose(fOut);
fclose(fR);
}
四、泛式Huffman树
1.Huffman树的缺陷
Huffman树压缩完成后,必须要在压缩文件中保存你字节频次信息,才可以解压缩,如果字节频次信息比较大,对压缩也会有一定的影响。而且解压缩时通过不断遍历还原的Huffman树进行解压缩,对解压的效率也会有一定的影响,因此我们选择了泛式Huffman树来进行编码
2.泛式Huffman树
泛式Huffman树是在Huffman树的基础之上,进行了一些强制性的约定,即:对于同一层节点中,所有的叶子节点都调整到左边,然后,对于同一层的叶子接待你按照符号顺序从小到达调整,最后按照左0右1的方式编码。
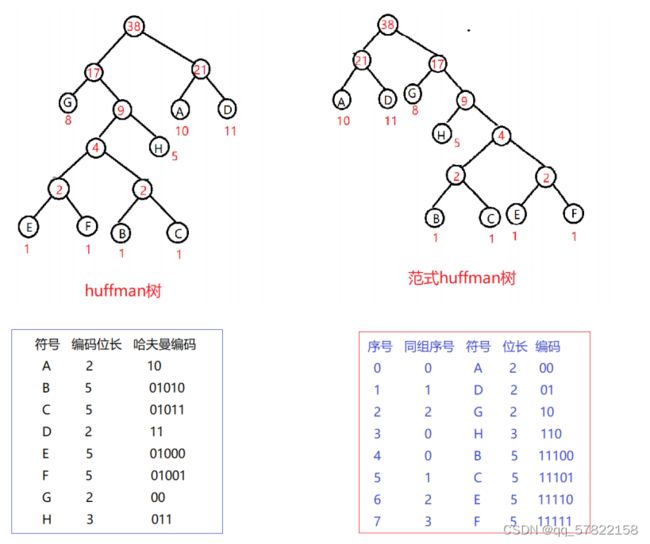
如上表我们可以看出
- 只要知道一个符号的编码位长就可以知道它在泛式树上的位置。即:码表中只要保存每个符号的编码长度即可
- 相同位长的编码之间都相差1
- 第n层的编码可以根据上层算出来:code = (code + count[n-1]) <<层数差
3.泛式Huffman树的创建
泛式Huffman树根本不需要创建,可以利用Huffman树推导出来:
- 1.对Huffman树中的每个叶子节点求层数,得出Huffman码表
- 2.对Huffman码表按照:码长(节点在树中的高度)为第一关键字、符号位第二关键字进行排序
五、压缩效率的比较
我们做一个小小的测试
现有一大小为101KB(104130字节)的txt文本

我们现在分别使用Huffman压缩,LZ77压缩和GZIP压缩 ,压缩后的文件大小如下

通过结果我们可以发现GZIP这种混合压缩算法的效率相对较好 。