CNN可视化技术总结(三)--类可视化
CNN可视化技术总结(一)-特征图可视化
CNN可视化技术总结(二)--卷积核可视化
导言:
前面我们介绍了两种可视化方法,特征图可视化和卷积核可视化,这两种方法在论文中都比较常见,这两种更多的是用于分析模型在某一层学习到的东西。在理解这两种可视化方法,很容易理解图像是如何经过神经网络后得到识别分类。
然而,上次我在知乎看到一个通过yolov3做跌倒检测,希望加上人脸识别进行多任务学习从而提高准确率的提问。这明显提问者并不理解神经网络是如何对这种带有时间维度的视频进行分析从而实现行为识别,从本质上来讲,这其实是不理解神经网络具体是如何识别一个类的。因此,当在这一点上理解错误后,所进行的模型选择、方案设计和改进,就都是不合理的。
(我在知乎上回答了这个问题正确的跌倒检测思路应该是什么,感兴趣的可以去看看,我的知乎id是仿佛若有光)
因此,在本文中,我们将介绍一种对于不同的类,如何知道模型根据哪些信息来识别的方法,即对类进行可视化,通俗一点来说就是热力图。这个方法主要是CAM系列,目前有CAM, Grad-CAM, Grad-CAM++。
CAM(Class Activation Map)
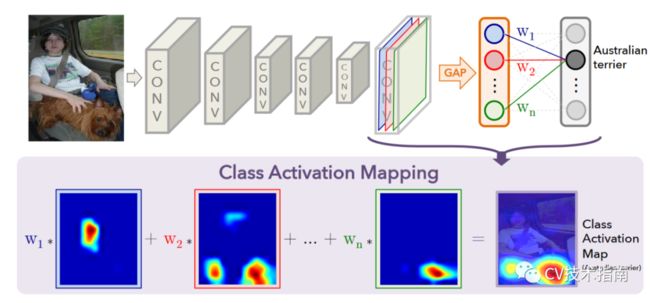
如上图所示,CAM的结构由CNN特征提取网络,全局平均池化GAP,全连接层和Softmax组成。
实现原理:一张图片在经过CNN特征提取网络后得到feature maps, 再对每一个feature map进行全局平均池化,变成一维向量,再经过全连接层与softmax得到类的概率。
假定在GAP前是n个通道,则经过GAP后得到的是一个长度为1x n的向量,假定类别数为m,则全连接层的权值为一个n x m的张量。(注:这里先忽视batch-size)
对于某一个类别C, 现在想要可视化这个模型对于识别类别C,原图像的哪些区域起主要作用,换句话说模型是根据哪些信息得到该图像就是类别C。
做法是取出全连接层中得到类别C的概率的那一维权值,用W表示,即上图的下半部分。然后对GAP前的feature map进行加权求和,由于此时feature map不是原图像大小,在加权求和后还需要进行上采样,即可得到Class Activation Map。
用公式表示如下:(k表示通道,c表示类别,fk(x,y)表示feature map)
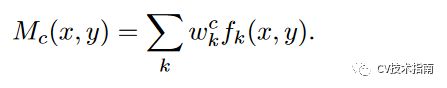
效果图:

CAM的分析
CAM有个很致命的缺陷,它的结构是由CNN + GAP + FC + Softmax组成,也就是说如果想要可视化某个现有的模型,但大部分现有的模型没有GAP这个操作,此时想要可视化便需要修改原模型结构,并重新训练,相当麻烦,且如果模型很大,在修改后重新训练不一定能达到原效果,可视化也就没有意义了。
因此,针对这个缺陷,其后续有了改进版Grad-CAM。
Grad-CAM
Grad-CAM的最大特点就是不再需要修改现有的模型结构了,也不需要重新训练了,直接在原模型上即可可视化。
原理:同样是处理CNN特征提取网络的最后一层feature maps。Grad-CAM对于想要可视化的类别C,使最后输出的类别C的概率值通过反向传播到最后一层feature maps,得到类别C对该feature maps的每个像素的梯度值,对每个像素的梯度值取全局平均池化,即可得到对feature maps的加权系数alpha,论文中提到这样获取的加权系数跟CAM中的系数几乎是等价的。接下来对特征图加权求和,使用ReLU进行修正,再进行上采样。
使用ReLU的原因是对于那些负值,可认为与识别类别C无关,这些负值可能是与其他类别有关,而正值才是对识别C有正面影响的。
用公式表示如下:



Grad-CAM的结构图如上图所示,对于Guided Backpropagation不了解的读者,可看CNN可视化技术总结的第一篇文章。
效果图如下:
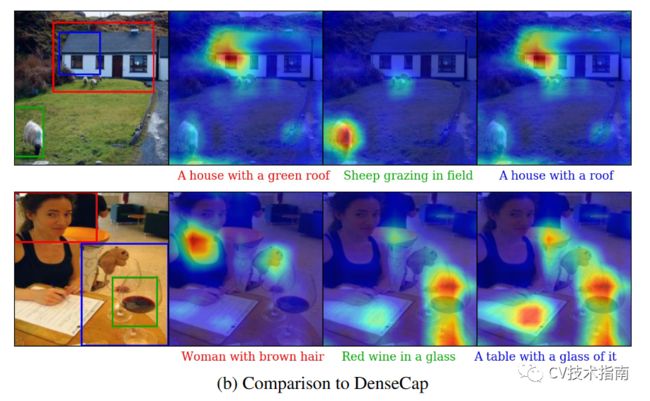
Grad-CAM后续还有改进版Grad-CAM++,其主要的改进效果是定位更准确,更适合同类多目标的情况,所谓同类多目标是指一张图像中对于某个类出现多个目标,例如七八个人。
改进方法是对加权系数的获取提出新的方法,该方法复杂到不忍直视。因此这里就不介绍了,感兴趣的读者可通过文章末尾的链接获取该论文。
下一篇将对所有的一些可视化工具进行总结。内容将放在CV技术总结部分。
CAM: https://arxiv.org/pdf/1512.04150.pdfGrad-CAM: https://arxiv.org/pdf/1610.02391v1.pdfGrad-CAM++: https://arxiv.org/pdf/1710.11063.pdf
参考论文:
1. Learning Deep Features for Discriminative Localization
2.Grad-CAM: Why did you say that?Visual Explanations from Deep Networks via Gradient-based Localization
3. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks
本文来源于公众号 CV技术指南 的技术总结系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。

其它文章
北京大学施柏鑫:从审稿人视角,谈谈怎么写一篇CVPR论文
Siamese network总结
计算机视觉专业术语总结(一)构建计算机视觉的知识体系
欠拟合与过拟合技术总结
归一化方法总结
论文创新的常见思路总结
CV方向的高效阅读英文文献方法总结
计算机视觉中的小样本学习综述
知识蒸馏的简要概述
优化OpenCV视频的读取速度
NMS总结
损失函数技术总结
注意力机制技术总结
特征金字塔技术总结
池化技术总结
数据增强方法总结
CNN结构演变总结(一)经典模型
CNN结构演变总结(二)轻量化模型
CNN结构演变总结(三)设计原则
如何看待计算机视觉未来的走向
CNN可视化技术总结(一)-特征图可视化
CNN可视化技术总结(二)-卷积核可视化
CNN可视化技术总结(三)-类可视化
CNN可视化技术总结(四)-可视化工具与项目