一文速学-最小二乘法曲线拟合算法详解+项目代码
目录
前言
一、曲线拟合策略
二、最小二乘法理论基础
1.残差
原理
特征
选取策略
2.最小二乘原则
定义
解法总览
三、最小二乘解法
1.确定函数类
2.求解方程
极小值原理:
求解方程组
定理
特例
四、代码实现
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
我们知道一般都是从多个点来画出直线,那么如果点的排列并非能够用一条直线来拟合,但是又需要找到这样一条线来拟合多个坐标轴上面的点,那么一般都是采用曲线进行拟合。但是如何在众多密集且离散的分布点中找到一条曲线来尽可能多的去拟合多个点呢?这就需要我们采取相应的算法或者策略。
我们需要使这条直线到各个数据点之间的误差最小且更可能的逼近,那么宏观来看该算法应该是全局最优算法,所以根据此我们使用最小二乘法来拟合离散的点尽可能使这些数据点均在离此曲线的上方或下方不远处。它既能反映数据的总体分布,又不至于出现局部较大的波动。我们现在我们来从零开始探索该算法。
本篇博客的愿景是希望我或者读者通过阅读这篇博客能够学会方法并能实际运用,而且能够记录到你的思想之中。希望读者看完能够提出错误或者看法,博主会长期维护博客做及时更新。
一、曲线拟合策略
在工程实际应用和科学实验中通过测量得到的一组离散的数据点,为了从中找到两个变量中间的内在规律性,也就是求自变量和因变量之间的近似程度比较好的函数关系式,这类问题有插值法和曲线拟合法。这类问题的插值法和曲线拟合法,当个别数据的误差较大时,插值效果显然是不理想的,而且实验或观测提供的数据个数往往较多,用插值法势必得到次数较高的插值多项式,会出现龙格现象。这时候最优策略就是选择曲线拟合策略了。

我们从数据出发构造一个近似函数,只要求所得的近似曲线能反映数据的基本趋势,使求得的逼近函数与已知函数从总体上来说偏差的平方和最小,这就是最小二乘法。
二、最小二乘法理论基础
1.残差
原理
要从零基础了解最小二乘法,那么我们需要把支撑最小二乘法的原理和算法搞懂,首先我们要了解什么是残差。我们知道曲线拟合不要求近似曲线严格过所有的数据点,但使求得的逼近函数与已知函数从总体上来说其偏差按某种方法度量达到总体上尽可能最小。那么我们估计的曲线与真实点的差距就是残差。
我们设线性回归模型为![]() ,其中:
,其中:
- Y是有相应变量构成的n维向量
- X是
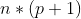 阶设计矩阵
阶设计矩阵  是
是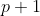 维向量
维向量 是n维随机变量
是n维随机变量
回归系数的估计值![]() ,拟合值
,拟合值![]() 为
为![]() ,其中:
,其中:
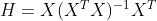 ,H为帽子矩阵
,H为帽子矩阵
则残差为![]() 。
。
特征
在回归分析中,测定值与按回归方程预测的值之差,以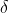 表示。残差遵从正态分布
表示。残差遵从正态分布![]() 。
。
![]() 的标准差,称为标准化残差,以
的标准差,称为标准化残差,以![]() 表示。
表示。![]() 遵从标准正态分布
遵从标准正态分布 。验点的标准化残差落在(-2,2)区间以外的概率≤0.05。若某一实验点的标准化残差落在(-2,2)区间以外,可在95%置信度将其判为异常实验点,不参与回归直线拟合。
。验点的标准化残差落在(-2,2)区间以外的概率≤0.05。若某一实验点的标准化残差落在(-2,2)区间以外,可在95%置信度将其判为异常实验点,不参与回归直线拟合。
显然,有多少对数据,就有多少个残差。残差分析就是通过残差所提供的信息,分析出数据的可靠性、周期性或其它干扰。
选取策略
通常我们构造拟合曲线,要使得残差 尽可能的小,有3中准则可供选择,具体内容如下:
- 残差的最大绝对值最小:
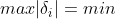
- 残差的绝对值之和最小:
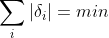
- 残差的平方和最小:
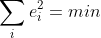
根据三种准则的具体形式,可以分析出前两种比较简单,而二者都含有绝对值运算,实际应用中不便于操作;基于第三种准则构造的拟合曲线方法便是曲线拟合的最小二乘法。
2.最小二乘原则
定义
我们将残差的平方和最小![]() 的原则称为最小二乘原则。
的原则称为最小二乘原则。
按照最小二乘原则选取拟合曲线的方法,称为最小二乘法。
解法总览
对于如何利用最小二乘法原则来解决问题,我们可以根据我们想要的结果来看:
在某个函数类![]() 来寻求一个函数
来寻求一个函数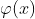 .
.
![]() .使其满足:
.使其满足:
![\sum_{i=1}^{m}[\varphi ^{*}(x_{i})-y_{i}]^{2}=\underset{\varphi (x)\epsilon \psi }{min}\sum_{i=1}^{m}[\varphi (x_{i})-y_{i}]^{2}](http://img.e-com-net.com/image/info8/33af9f82bd6b442a907cac9c29b1f77b.gif) ,其中
,其中![]() 是函数类
是函数类 中任意函数。
中任意函数。![]() 是待定常数。
是待定常数。
满足上述关系式的函数![]() 称为上述最小二乘问题的最小二乘解。
称为上述最小二乘问题的最小二乘解。
三、最小二乘解法
1.确定函数类
原则:根据实际问题域所给数据点的变化规律确定。
在实际问题中如何选择基函数是一个复杂的问题,一般要根据问题本身的性质来决定。通常可取的基函数有多项式、三角函数、指数函数。或者数据集可能本身就是一个轨迹点数据集,没有强关联的自变量因变量关系。这是要根据实际问题求解的目标调整算法。
2.求解方程
问题转化为求待定系数![]() 使得:
使得:
![\sum_{i=1}^{m}[\varphi ^{*}(x_{i})-y_{i}]^{2}=\underset{\varphi (x)\epsilon \psi }{min}\sum_{i=1}^{m}[\varphi (x_{i}-y_{i})]^{2}](http://img.e-com-net.com/image/info8/5815eced3791449cb1112653761c918f.gif)
极小值原理:
记![]() ,那么我们知道存在极小值的情况,原函数需要存在收敛。
,那么我们知道存在极小值的情况,原函数需要存在收敛。
证明函数收敛,![\sum_{i=1}^{m}[\sum_{k=0}^{n}a_{k}\varphi _{k}(x_{i})-f(x_{i})]^{2}](http://img.e-com-net.com/image/info8/5f33ba326b9b43e8881411c2b509ec76.gif) 则有多元函数极值必要条件有:
则有多元函数极值必要条件有:
![\frac{\partial S}{\partial a_{k}}=\sum_{i=1}^{m}\varphi _{k}(x_{i})[a_{0}\varphi _{0}(x_{i})+a_{1}\varphi _{1}(x_{i})+...+a_{n}\varphi _{n}(x_{i})-f(x_{i})]=0](http://img.e-com-net.com/image/info8/c0b8a65c71a34bad927b932742f8a438.gif) ,其中
,其中![]()
求解方程组
对任意函数h(x)和g(x)引入记号:
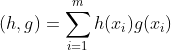
用向量内积形式表示,可得
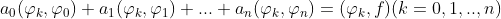
即: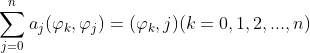
上式为求![]() 的法方程组,其矩阵的形式为:
的法方程组,其矩阵的形式为:
![]()
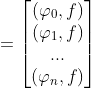
由于向量组![]() 是线性无关,故上式系数行列式
是线性无关,故上式系数行列式![]()
存在唯一解:![]() 于是得到函数
于是得到函数 的最小二乘解
的最小二乘解
![]()
故得到下列:
定理
对于给定的一组实验数据![]() ,
, 互异。在函数类
互异。在函数类![]() ,
,![]() 且
且![]() 线性无关,存在唯一的函数
线性无关,存在唯一的函数![]() 使得关系式成立,并且其系数
使得关系式成立,并且其系数![]() 可以通过解法方程组得到。
可以通过解法方程组得到。
特例
如取![]() 就得到代数多项式
就得到代数多项式![]()
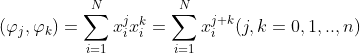

最小二乘的法方程为:
![]()

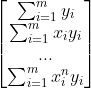
四、代码实现
首先进行曲线拟合的话肯定需要数据分析三巨头pandas、numpy和绘图用的matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt这里我们使用案例来实现最小二乘法拟合:
在某化学反应里,测得生成物浓度y(%)与时间t(min)的数据:
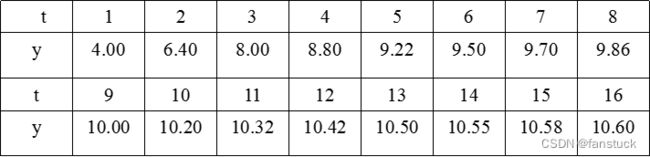
一般我们拿到数据都是在excel和csv,直接读取就好了:
df_metric=pd.read_excel('try_test.xlsx')
df_metric
通过绘制散点图我们很容易看出数据趋势:
x=df_metric['t']
y=df_metric['y']
plot1 = plt.plot(x, y, '*', label='origin data')
plt.title('polyfit')
plt.show()
在matplotlib库中polyfit函数可以实现多项式拟合,也就是最小二乘拟合:
# 使用polyfit方法来拟合,并选择多项式
z1 = np.polyfit(x, y, 2)
# 使用poly1d方法获得多项式系数,按照阶数由高到低排列
p1 = np.poly1d(z1)
#打印拟合多项式
print(p1) 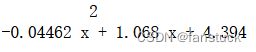
当然如果需要精度更高可以增加系数:
# 使用polyfit方法来拟合,并选择多项式
z1 = np.polyfit(x, y, 3)
# 使用poly1d方法获得多项式系数,按照阶数由高到低排列
p1 = np.poly1d(z1)
#打印拟合多项式
print(p1)
拟合之后对比:
# 求对应x的各项拟合函数值
fx = p1(x)
plot1 = plt.plot(x, y, '*', label='origin data')
plot2 = plt.plot(x, fx, 'r', label='polyfit data')
plt.legend(loc=4)
plt.show()
当系数更多越精确:

实际问题的解决中测得的数据都不是等精度的。显然,对于精度高、权重大的数据应该给予足够的重视,在计算时,给以足够的权重,在这种情况下就要使用加权最小二乘法。
利用最小二乘法原则上解决了最小二乘法意义下的曲线拟合问题,但在实际问题的解决时,n往往很大,法方程组往往是病态的,因而给求解带来了一定的困难。其中也有相当多的策略去优化该算法。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。