【主流技术】Redis 在 Spring 框架中的实践
前言
在Java Spring 项目中,数据与远程数据库的频繁交互对服务器的内存消耗比较大,而 Redis 的特性可以有效解决这样的问题。
Redis 的几个特性:
- Redis 以内存作为数据存储介质,读写数据的效率极高;
- Redis 支持 key-value 等多种数据结构,提供字符串,哈希,列表,队列,集合结构直接存取于内存,可持久化(RDB 和 AOF);
- 支持主从模式,可以配置集群。
下面,我将和大家一起学习分享 Redis 的相关知识。
一、Redis 概述
1.1Redis 是什么?
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的API。
Redis会周期性地把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave (主从)同步。
1.2Redis 能做什么?
Redis适用的几个场景:
- 数据库;
- 会话缓存;
- 消息队列;
- 发布、订阅消息;
- 加载商品列表、评论等。
1.3基础知识
- Redis 默认有16个数据库,在配置文件中表明了 database 16。默认使用第0个,且可以使用 select 进行切换数据库。
[root@localhost bin]# redis-cli -p 6379 #进入客户端
127.0.0.1:6379>
127.0.0.1:6379> select 3 #选择数据库
OK
127.0.0.1:6379[3]> dbsize #查看数据库大小
(integer) 0
- Redis 的线程相关知识
Redis 在6.0版本以后开始支持多线程,Redis 是基于内存操作,CPU 性能不是 Redis 的瓶颈,Redis 的性能取决机器的内存和网络带宽是否良好。
Redis 默认是关闭多线程的,即默认只使用单线程。
为什么 Redis 是单线程还这么快?
- 误区1:高性能的服务器一定是多线程的?
- 误区2:多线程(CPU调度,上下文切换)一定比单线程的效率高?
原因:Redis 所有的数据都是存放在内存中的,单线程的操作没有上下文的切换,从而达到很高的效率。
二、Redis 安装与基本命令
2.1Windows 安装
-
方式一
GitHub 地址:Release 5.0.10 · redis/redis · GitHub
解压缩后:双击 redis-server.exe 即可在 Windows 上开启服务。
-
方式二
在 Redis 的安装目录切换到 cmd,运行:redis-server.exe redis.windows.conf;
在保持上一个窗口开启的情况下,再次在 Redis 目录下开启另一个 cmd 窗口,运行:redis-cli.exe -h 127.0.0.1 -p 6379;
当输入 ping 时,返回 PONG 代表服务创建成功。
注:虽然在 Windows 上使用很方便,但官方推荐在 Linux 上使用 Redis 。
2.2Linux 安装
官网下载最新:Download | Redis redis-7.0.2.tar.gz
放入 Linux 文件夹中,比如可以放入 home/dingding 目录下后解压:
tar -zxvf redis-5.0.8.tar.gz

可以进入解压后的文件后:

看到配置文件:redis.conf,上述操作只是解压操作,真正安装往下看:
安装 Redis :
1.还是在上述解压目录中,首先安装 gcc-c++:
yum install gcc-c++
2.make 配置好所有的环境:
make

3.检查 make 后是否成功安装所需环境:
make install
安装好后的默认路径为:/usr/local/bin,进入后可以看到 redis-cli、redis-server 等内容。

4.将之前 redis 解压目录文件夹(home/dingding)中的 redis.conf 文件复制到 redis 的安装目录(/usr/local/bin)下:
cp /opt/redis-7.0.2/redis.conf bin
注:或者可以在 bin目录中新建一个 config 文件夹:mkdir config,上述命令则变为:
cp /opt/redis-7.0.2/redis.conf config
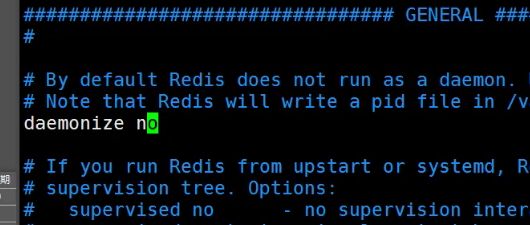
5.Redis 不是默认后台启动的,当前 /bin 目录下应该有了复制过来的 redis.conf文件,此时需要修改配置信息:
vim redis.conf
将 daemonize no 改为 daemonize yes 即可保证 Redis 在后台时可以运行:
远程连接 Redis 服务:将 bind 127.0.0.1注释掉,同时*protected-mode yes* 改成 protected-mode no
6.在 bin 目录下,启动 Redis 服务:需要用指定文件下的 redis.conf 文件来启动:
redis-server bin/redis.conf
或者:
redis-server config/redis.conf
7.在 bin 目录下,进入 redis client 终端,连接默认的端口号:
redis-cli -p 6379
8.在 任意 目录下,确定 Redis 服务是否开启:
ps -ef|grep redis
9.在 任意 目录下,关闭 Redis 服务:
shutdown
exit
2.3 Redis-benchmark 性能测试
Redis-benchmark 是 Redis 中自带的性能测试插件,可能通过一系列的命令来测试 Redis 的性能。
这些命令都在 Redis 的 Linux 安装目录下进行。
- 测试100个并发连接,进行100000个请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000

Redis-BenchMark 测试结果
测试结果解读:
100000次请求在4.84秒内完成,共100个并行客户端,平均每秒完成27000+次请求,每次写入3个字节,以上都是在1台服务器上完成。
三、Redis 之 String 类型
3.1 Redis-key 详解
127.0.0.1:6379> flushall //清空数据库
OK
127.0.0.1:6379> set name zzz //设置key为name,value为zzz
OK
127.0.0.1:6379> set age 3 //设置key为age,值为3
OK
127.0.0.1:6379> keys * //查看所有的 key
1) "name"
2) "age"
127.0.0.1:6379> exists name //检查是否存在 名为 name 的 key
(integer) 1 // 1 表示存在
127.0.0.1:6379> exists name1
(integer) 0
127.0.0.1:6379> move name 1 //移除 name
(integer) 1 // 1 表示移除成功
(1.16s)
127.0.0.1:6379> keys * //查看所有的 key
1) "age"
127.0.0.1:6379> expire name 10 //设置 name 的过期时间为 10 秒钟,单点登录可以使用 Redis 的过期功能
(integer) 1
127.0.0.1:6379> ttl name //查看过期时间,已经过期2秒钟
(integer) -2
127.0.0.1:6379> get name //此时 name 已不存在
(nil)
127.0.0.1:6379> type name //查看 key 中所存储的 value 的数据类型
string // string 类型
127.0.0.1:6379> type age //查看 key 中所存储的 value 的数据类型
string // string 类型
Redis 所有命令可以在:Commands | Redis 中去查看。
3.2 String 类型
由于在 Linux 环境中是使用终端命令来对 Redis 进行一些操作的,所以下面通过对一些 String 类型的命令的操作来进行讲解。
127.0.0.1:6379> set key1 v1 //设置 key-value
OK
127.0.0.1:6379> get key1 //通过 get-key 来获取 value
"v1"
127.0.0.1:6379> append key1 "hello" //追加字符串,如果 key 不存在,就相当于重新 set key
(integer) 7
127.0.0.1:6379> get key1
"v1hello"
127.0.0.1:6379> strlen key1 //获取字符串长度
(integer) 7
127.0.0.1:6379> append key1 "+apluemxa" //追加字符串
(integer) 16
127.0.0.1:6379> get key1
"v1hello+apluemxa"
下面再对 Redis 中一些现有的自增、自减、设置步长操作进行讲解:
127.0.0.1:6379> set views 0 //设置 key 为0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views //自增
(integer) 1
127.0.0.1:6379> incr views
(integer) 5
127.0.0.1:6379> get views
"5"
127.0.0.1:6379> incrby views 20 //设置步长,并指定增量
(integer) 23
127.0.0.1:6379> get views
"23"
127.0.0.1:6379> DECRBY views 8 //设置步长,并指定减量
(integer) 15
下面是对字符串范围 range 做一个讲解:
127.0.0.1:6379> set key1 "helle,world!" //设置 key 以及 value
OK
127.0.0.1:6379> get key1 //通过 key 获取 value
"helle,world!"
127.0.0.1:6379> GETRANGE key1 0 3 //截取字符串 [0,3](数组下标)
"hell"
127.0.0.1:6379> GETRANGE key1 0 -1 //表示截取所有的字符串,与 get key 作用一致
"helle,world!"
127.0.0.1:6379> GETRANGE key1 2 6 //截取字符串 [2,6](数组下标)
"lle,w"
127.0.0.1:6379> SETRANGE key1 2 xx //替换字符串为 xx,2为数组下标
(integer) 12
127.0.0.1:6379> get key1 //查看被替换后的字符串
"hexxe,world!"
下面再对设置过期时间、判断是否存在(分布式锁中使用)进行讲解:
127.0.0.1:6379> setex key3 30 "hello" //设置 key 的 value 为30,过期时间为30秒
OK
127.0.0.1:6379> ttl key3
(integer) 20
127.0.0.1:6379> setnx mykey "redis" //如果 mykey 不存在则创建
(integer) 1
(0.55s)
127.0.0.1:6379> keys *
1) "mykey"
2) "key1"
127.0.0.1:6379> setnx mykey "MySQL" //如果 mykey 已存在,则提示创建失败,返回0
(integer) 0
下面再对 Redis 的批量操作命令进行讲解:
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 //同时创建多个 key-value
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
127.0.0.1:6379> mget k1 k2 k3 //同时获取多个 value
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 // msetnx 是一个原子性操作,要么一起成功,要么一起失败
(integer) 0
127.0.0.1:6379> get k4 // 因为上述的 k1 v1 已经存在,所以上述命令执行失败,k4 没有创建成功
(nil)
最后再介绍几个 Redis 的高阶实战用法:
set user:1{name:zhuzqc,age:123} //设置一个 user:1 对象,其 value 使用一个 json 字符串来保存
127.0.0.1:6379> mset user:1:name zhuzqc user:1:age 123 //同时为 user 对象设置 key为 name 和 age,并设置value
OK
127.0.0.1:6379> mget user:1:name user:1:age //通过 user 对象的 key,获取对应的 value
1) "zhuzqc"
2) "123"
127.0.0.1:6379> getset db redis //先 get 后 set,若没有值则返回 nil
(nil)
127.0.0.1:6379> get db //上述命令中已 set 了值
"redis"
127.0.0.1:6379> getset db mysql //同理先 get 到 db 的 value
"redis"
127.0.0.1:6379> get db //再重新 set db 的 value
"mysql"
3.3小结
本节讲解的是 Redis 中关于 String 类型数据类型的基本命令以及进阶用法,主要包括:
-
计数器(自增,设置步长)
如:某网站的浏览量统计
uid:1234:views:0 incr views //用户id、浏览量、浏览量自增 -
对象存储
如:过期时间、是否存在(分布式锁)
-
批量操作
如:同时创建多个 key-value、先设置 key 再设置 value
四、Redis 使用场景(拓展)
4.1Redis 基本事务操作
前提:Redis 单条命令保证原子性,但是 Redis 的事务不保证原子性。
比如在关系型数据库 MySQL 中,事务是具有原子性的,所有的命令都是一起成功或者失败。
-
Redis 事务的本质:
- 一组命令一起执行的集合(事务不保证原子性);
- 一个事务中的所有命令都会按照顺序执行;
- 其它3大特性:一次性、顺序性和排他性;
- Redis 事务没有隔离级别的概念,所有命令只有发起执行时才会被执行(exec);
-
Redis 的执行过程:
- 开启事务(multi);
- 命令入队(按照顺序执行);
- 执行事务(exec)。
基本操作过程如下:
127.0.0.1:6379> multi #redis开启事务
OK
127.0.0.1:6379(TX)> FLUSHDB #命令开始入队
QUEUED
127.0.0.1:6379(TX)> keys *
QUEUED
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> get k2
QUEUED
127.0.0.1:6379(TX)> exec #执行事务,上述命令开始按顺序执行并给出展示执行结果
1) OK
2) (empty array)
3) OK
4) OK
5) "v2"
编译型异常(代码有问题或者命令有错):事务中所有的命令都不会被执行;
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> getset k3 v33 #正确的 getset 语句
QUEUED
127.0.0.1:6379(TX)> getset k3 #错误的语句:编译时(未执行)发生错误
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379(TX)> set k4 v4
QUEUED
127.0.0.1:6379(TX)> exec #事务中所有的命令都不会执行
(error) EXECABORT Transaction discarded because of previous errors.
运行时异常:如果事务队列中存在语法性错误,那么执行事务时,其它命令可以正常执行,错误的命令会抛出异常。
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> INCR k1 #对字符串的 value 使用自增,语法不报错
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> get k3
QUEUED
127.0.0.1:6379(TX)> exec #执行事务后,只有错的命令未被执行,其余命令都被执行了
1) (error) ERR value is not an integer or out of range
2) OK
3) OK
4) "v3"
4.2Redis 实现乐观锁
悲观锁
- 简单来说,就是什么时候都会出问题,无论做什么都会加锁!
乐观锁
- 很乐观,认为无论什么时候都不会出问题,所以不会上锁!
- 在数据进行更新的期间,会对数据进行判断,期间这个数据是否被修改(如 mysql 中的 version)。
- 步骤一:获取 version;
- 步骤二:更新的时候比较 version。
Redis 监视(watch)测试
- 正常步骤执行的过程:
127.0.0.1:6379> set money 1000
OK
127.0.0.1:6379> set cost 0
OK
127.0.0.1:6379> watch money #监视 money 对象
OK
127.0.0.1:6379> multi #开启事务,数据正常变动
OK
127.0.0.1:6379(TX)> DECRBY money 28
QUEUED
127.0.0.1:6379(TX)> INCRBY cost 28
QUEUED
127.0.0.1:6379(TX)> EXEC #执行后得到正常的数据
1) (integer) 972
2) (integer) 28
- 多线程情况下对值进行更改:
127.0.0.1:6379> watch money #使用 watch 进行乐观锁操作
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> DECRBY money 100 #另一个线程操作
QUEUED
127.0.0.1:6379(TX)> INCRBY money 100
QUEUED
127.0.0.1:6379(TX)> exec #执行失败
(nil)
######################################### 解决办法 ##########################################
127.0.0.1:6379> unwatch #先解锁
OK
127.0.0.1:6379> watch money #再次监视,获取最新的值
OK
127.0.0.1:6379> multi #启用事务
OK
127.0.0.1:6379(TX)> DECRBY money 10
QUEUED
127.0.0.1:6379(TX)> INCRBY cost 10
QUEUED
127.0.0.1:6379(TX)> exec #执行成功
1) (integer) 480
2) (integer) 48
4.3 Jedis 相关操作
什么是 Jedis?
Jedis 是官方推荐的 Java 连接开发工具,本质上是一个 Java 操作 Redis 的中间件。
如果要使用 Java 操作 Redis ,那么应该要先熟悉 Jedis 的一些操作。
-
导入依赖
redis.clients jedis 4.2.3 com.alibaba fastjson 1.2.83 -
编码测试
- 连接数据库(Rdies 可以看作是一种数据库)
- 操作命令
- 断开连接
/**
* @author Created by zhuzqc on 2022/6/20 23:04
*/
public class TestPing {
public static void main(String[] args) {
//1、new 一个 Jedis 对象
Jedis jedis = new Jedis("127.0.0.1",6379);
//2、所有 Jedis 命令都在 jedis 对象中去操作
System.out.println(jedis.ping());
}
}
-
常用 API
-
关于 String
/** * @author Created by zhuzqc on 2022/6/20 23:15 */ public class TestAPI { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); //添加 key-value jedis.set("name","zhuzqc"); jedis.set("age","123"); //使用 append 添加字符串 jedis.append("name","-alumna"); //批量增加、获取 key-value jedis.mset("k1","v1","k2","v2"); jedis.mget("k1","k2"); //分布式锁的是否存在、设置过期时间 jedis.setnx("k1","v1"); jedis.setex("k2",10,"v2"); //先 get 后 set jedis.getSet("k2","vv22"); //截取 k2 的字符串 System.out.println(jedis.getrange("name", 2, 5)); } } -
常用方法
public Long hlen(String key) { this.checkIsInMultiOrPipeline(); this.client.hlen(key); return this.client.getIntegerReply(); } public Sethkeys(String key) { this.checkIsInMultiOrPipeline(); this.client.hkeys(key); return (Set)BuilderFactory.STRING_SET.build(this.client.getBinaryMultiBulkReply()); } public List hvals(String key) { this.checkIsInMultiOrPipeline(); this.client.hvals(key); List lresult = this.client.getMultiBulkReply(); return lresult; } public Map
-
-
关于事务
/** * @author Created by zhuzqc on 2022/6/20 23:32 */ public class TestTX { public static void main(String[] args) { Jedis jedis = new Jedis("127.0.0.1",6379); //自定义 JSON 数据 JSONObject jsonObject = new JSONObject(); jsonObject.put("name","Jackson"); jsonObject.put("age","123"); //强转为 String String result = jsonObject.toString(); try { //开启事务 Transaction multi = jedis.multi(); multi.set("user1",result); //代码抛出异常则事务都不执行 int i = 1/0; multi.set("user2",result); //执行事务 multi.exec(); } catch (Exception e) { e.printStackTrace(); }finally { //执行时报错,不影响其它事务执行 System.out.println(jedis.get("user3")); System.out.println(jedis.get("user2")); System.out.println(jedis.get("user1")); jedis.close(); } } }
五、Spring Boot 集成 Redis
5.1基本概念与操作
在 Spring Boot 中操作数据的框架(组件)一般有:Spring-data、JPA、JDBC、Redis等。
说明:在Spring 2.x 版本后,原来使用的 Jedis 被替换成为了 lettuce。
原因:
- Jedis:采用直连的方式,多个线程操作是不安全的,使用 Jedis pool 连接池可以避免线程不安全。(BIO模式)
- lettuce:采用netty,实例可以在多个线程中进行共享,不存在线程不安全的情况,可以减少线程数量,性能较高。(NIO模式)
源码解读:
@Bean
//自己可定义一个 redisTemplate 来替换默认的
@ConditionalOnMissingBean(
name = {"redisTemplate"}
)
@ConditionalOnSingleCandidate(RedisConnectionFactory.class)
//两个泛型都是Object,使用时需要强转为
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
导入依赖:
org.springframework.boot
spring-boot-starter-data-redis
配置文件:
# Redis 配置
spring.redis.host=127.0.0.1
spring.redis.port=6379
spring.redis.database=0
简单测试:
/**
* 获取某个项目中会使用到的 accessToken
* @return accessToken
*/
public String getAccessToken() throws Exception {
String accessToken = null;
Jedis jedis = null;
try {
// 如果 redis 对象中已经存在 accessToken,则直接返回
jedis =jedisPool.getResource();
accessToken = jedis.get("accessToken:" + appKey);
if (StringUtils.isNotBlank(accessToken)){
return accessToken;
}
// 获取 accessToken 所必须的参数
Client client = createClient();
GetAccessTokenRequest getAccessTokenRequest = new GetAccessTokenRequest()
.setAppKey(appKey)
.setAppSecret(appSecret);
GetAccessTokenResponse res = client.getAccessToken(getAccessTokenRequest);
//获取到 accessToken 后将其以 K-V 的形式存入 redis 对象中,并设置过期时间为30分钟
accessToken = res.getBody().getAccessToken();
jedis.set("accessToken:" + appKey, accessToken);
jedis.expire("accessToken:" + appKey, 1800);
// 异常捕获
} catch (TeaException err) {
if (!com.aliyun.teautil.Common.empty(err.code) &&
!com.aliyun.teautil.Common.empty(err.message)) {
log.error("code:{}, message:{}", err.code, err.message);
}
} catch (Exception _err) {
TeaException err = new TeaException(_err.getMessage(), _err);
if (!com.aliyun.teautil.Common.empty(err.code) &&
!com.aliyun.teautil.Common.empty(err.message)) {
log.error("code:{}, message:{}", err.code, err.message);
}
}
//释放 redisPool 资源池中的 redis 对象资源,保证 redis 对象数量够用
finally {
if (jedis != null) {
jedis.close();
}
}
return accessToken;
}
自定义 Redis 配置类:
/**
* @author Created by zhuzqc on 2022/6/21 22:27
*/
@Configuration
public class RedisConfig {
/**
* 自定义 redisTemplate
* */
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate template = new RedisTemplate();
//配置具体的序列化方式,如 JSON 的序列化
Jackson2JsonRedisSerializer 使用 Redis 工具类:
@Test
public void Test_1(){
redisUtil.set("nnaammee","zzzzzz");
System.out.println(redisUtil.get("nnaammee"));
}
5.2Redis 持久化操作
Redis 是基于内存的数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失,所以 Redis 提供了数据持久化的能力 。
5.2.1RDB(Redis DataBase)
RDB 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中(触发SnapShot 快照)。即在指定目录下生成一个dump.rdb文件。Redis 重启会通过加载dump.rdb文件恢复数据。
配置文件(原理)
# save ""
# save 指定时间间隔 <执行指定次数>
save 900 1
save 300 10
save 60 10000
分析:save <指定时间间隔> <执行指定次数更新操作>
满足条件就将内存中的数据同步到硬盘中:
官方出厂配置默认是 900秒内有1个更改、00秒内有10个更改、60秒内有10000个更改,则将内存中的数据快照写入磁盘。
# 指定本地数据库文件名,一般采用默认的 dump.rdb
dbfilename dump.rdb
# 默认开启数据压缩
rdbcompression yes
触发机制
- 在指定的时间间隔内,执行指定次数的写操作;
- 执行save(阻塞, 只管保存快照,其他的等待) 或者是bgsave (异步)命令;
- 执行flushall 命令,清空数据库所有数据(不推荐);
- 执行shutdown 命令,保证服务器正常关闭且不丢失任何数据。
RDB 数据恢复
将上述dump.rdb 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可恢复数据。
RDB 优缺点
优点:
- 适合大规模的数据恢复;
- 如果对数据完整性和一致性要求不高,RDB是很好的选择。
缺点:
- 由于 RDB 可能在最后一次备份时遇到服务器宕机的情况,这时数据的完整性和一致性不高;
- 由于 Redis 在备份时会独立创建一个子进程将数据写入临时文件,再将临时文件替换为需要备份的文件时,需要占用双份的内存。
5.2.2AOF(Append Only File)
Redis 默认不开启 AOF。
AOF 的出现是为了弥补 RDB 的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。
Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
配置文件(原理)
打开 redis.conf 文件,找到 APPEND ONLY MODE 对应内容:
# redis 默认关闭,开启需要手动把 no 改为 yes
appendonly yes
# 指定本地数据库文件名,默认值为 appendonly.aof
appendfilename "appendonly.aof"
# 指定更新日志条件
# appendfsync always # 同步持久化,每次发生数据变化会立刻写入到磁盘中。(性能较差,但数据完整性比较好)
appendfsync everysec # 默认每秒异步记录一次
# appendfsync no # 不同步
# 配置重写触发机制
auto-aof-rewrite-percentage 100 #当AOF文件大小是上次rewrite后大小的一倍
auto-aof-rewrite-min-size 64mb #且文件大于64M时触发。(一般都设置为2G,64M太小)
AOF 数据恢复
正常情况下,将 appendonly.aof 文件拷贝到 redis 的安装目录的 bin 目录下,重启redis服务即可。
注:如果因为某些原因导致 appendonly.aof 文件格式异常,从而导致数据还原失败,可以通过命令 redis-check-aof --fix appendonly.aof 进行修复。
AOF 重写机制
当 AOF 文件的大小超过所设定的阈值时,Redis 就会对 AOF 文件的内容压缩。
Redis 会 fork 出一条新进程,读取内存中的数据,并重新写到一个临时文件中。并没有读取旧文件,最后替换旧的 AOF 文件。
5.3 Redis 集群(主从复制)
5.3.1基本概念
主从复制:是指将一台 Redis 服务器端的数据,复制到其它 Redis 服务器的过程。
读写分离:一般项目中的业务数据 80% 的情况下都是在进行读的操作,多个从节点进行读操作,可以减轻 Redis 服务器压力。
前者称为主节点(Master/laeder),后者称为从节点(slave/follower),最低数量标准为“一主二从”。
在这个过程中数据的复制是单向的,数据只能从主节点复制到从节点。
其中 Master 节点以写为主,Slave 节点以读为主。
默认情况下每台 Redis 都是主节点,一个主节点可以有多个从节点(也可以无从节点),但每个从节点只能有唯一的主节点。
5.3.2主要作用
- 数据备份:主从复制实现了数据的热备份(系统处于正常运转状态下的备份),是除 Redis 持久化外的另一种方式。
- 故障恢复:主节点出现故障时,可以由从节点提供服务,实现数据的快速恢复。
- 负载均衡:在主从复制的基础上配合读写分离,可以分担服务器负载,尤其是在读多写少的情况下,大大提高了 Redis 服务器的并发量。
- 高可用(集群):主从复制和哨兵模式是集群能够实施的基础。
5.3.3环境配置
集群的配置只配置从库、不用配置主库。
检查 Redis 服务器信息:
127.0.0.1:6379> info replication
# Replication
role:master # 当前角色默认是 Master
connected_slaves:0 # 当前从机为 0 个
master_failover_state:no-failover
master_replid:e87ac50f5b4f345c1a2a8f3a7374b25ef109219f
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
修改 conf 文件中以下几处:
- 端口(每个从节点的端口需要不同);
- pid file的名称;
- log 文件名;
- dump.rdb 名称;
5.3.4主从配置
配置原则:从机认定一个主机即可。
如:一主(79)二从(80、81):
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 #认79为主机
OK
127.0.0.1:6380> info replication
# Replication
role:slave #当前角色为从机
master_host:127.0.0.1
master_port:6379
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 #认79为主机
OK
127.0.0.1:6381>
127.0.0.1:6381> info replication
# Replication
role:slave #当前角色为从机
master_host:127.0.0.1
master_port:6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2 # 该主机有两个从机
slave0:ip=127.0.0.1,port=6380,state=online,offset=350,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=350,lag=1
注意:在 Redis 服务器的配置文件中对主、从进行配置才能真正生效,上述命令配置是临时的。
5.3.5测试主从复制
# 主节点可以读也可以写
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
# 从节点可以获取到主节点的数据
127.0.0.1:6380> keys *
1) "k1"
127.0.0.1:6380> get k1
"v1"
# 从节点只允许读,不允许写
127.0.0.1:6380> set k2 v2
(error) READONLY You can't write against a read only replica.
# 主节点宕机后,从节点仍然可以获取到主节点数据
127.0.0.1:6379> shutdown
127.0.0.1:6380> get key2
"shutdown"
BASH 复制 全屏
5.3.6复制原理
Slave 启动连接成功到 Master 后会发送一个 sync 的同步命令,Master 接收到命令后将会传送整个数据文件到 Slave,并完成一次完全同步。
5.4小结
- Redis 是一个高性能的 key-value 存储系统。
- 它支持存储的 value 类型包括:string (字符串)、list (链表)、set (集合)、zset (sorted set 有序集合)和 hash(哈希类型)。
- Redis 提供了Java、Python、Ruby、Erlang、PHP等客户端,使用起来很很方便。
- Redis 支持支持持久化、主从同步:数据可以从主服务器向任意数量的从服务器上同步,保证 Redis 服务器的高可用。