【K8S】详解K8S中关于pod的一切问题
本文主要总结k8s学习中pod资源的一些问题,包括K8S通信网络模型,pod通信(第一节)和pod的其他问题(第二节)。
目录
第一节、K8S通信网络模型
补充:K8S的service是什么?
讲一讲通信网络模型:
1、分布式pod之间通信:
2、pod内不同容器间通信:
3、service和pod之间通信
4、外部与service之间的通信
CNI网络插件
第二节、Pod的其他问题
pod有哪些分类:
pod可能有什么状态?
Kubernetes创建一个Pod的主要流程?
Kubernetes 中Pod的健康检查方式?
简述Kubernetes 中Pod 的重启策略?
简述Kubernetes Pod的常见调度方式?
第一节、K8S通信网络模型
K8S集群的有4种网络:
具体如下:同一pod内的容器间通信、各pod彼此之间的通信、pod与service间的通信、以及集群外部的流量同service之间的通信。
补充:K8S的service是什么?
Service是K8S的核心资源类型之一,常被看作是微服务的一种实现,他其实是一种抽象,通过规则定义出由多个pod对象组合成的逻辑集合,以及访问这组pod的策略。
Service资源基于标签选择器把筛选出的一组pod对象定义为一个逻辑组合,并通过自己的ip地址和端口将请求转发到组内的pod对象,因此这种代理机制又被称为端口代理,或者四层代理,工作在传输层。如下图,service对象向客户端隐藏了真正处理用户请求得pod资源,使得客户端得请求看上去是由service 直接处理并响应的。
service对象会通过api server持续监视(watch)标签选择器匹配到的后端pod对象,并实时跟踪这些pod的变动情况,但是service不直接连接到pod对象,他们中间有一个endpoint层,endpoint资源对象是一个由ip和端口组成的列表,ip和端口来自于service标签选择器删选出来的pod对象的ip和端口,在创建service对象时,endpoint会被自动创建。
service对象的ip(可以称为是cluster ip /service ip)是一个虚拟ip,在K8S系统创建service时,在专用网络地址中分配或者用户手动配置,在整个Service周期中保持不变。

讲一讲通信网络模型:
K8S的pod网络管理并非K8S系统内置功能,而是需要第三方插件CNI(容器网络服务)来支持。目前的主要的CNI插件如下:(关于CNI网络插件的详细说明,见下文。)
Flannel: 支持网络配置
Calico: 网络配置,网络策略,部署使用比较复杂,能够基于BGP协议实现直接路由
Canel: 结合以上两者,支持网络配置和网络策略
……
1、分布式pod之间通信:
K8S上的所有pod默认会从同一平面网络得到全局一个唯一IP地址和一个虚拟网络接口,无论是否都处于一个namespace,各个pod之间都可使用各自的IP地址直接进行通信,如下图的PodP和PodQ之间的通信。
注意:同一平面网络是指在同一网段内
除此之外,运行pod的各个节点会通过桥接设备(如下图eth0)等持有此平面网络的一个IP地址(如下图的cni0),因此pod之间的通信和pod到node之间的通信,类似于同一网段内不同主机之间的通信。
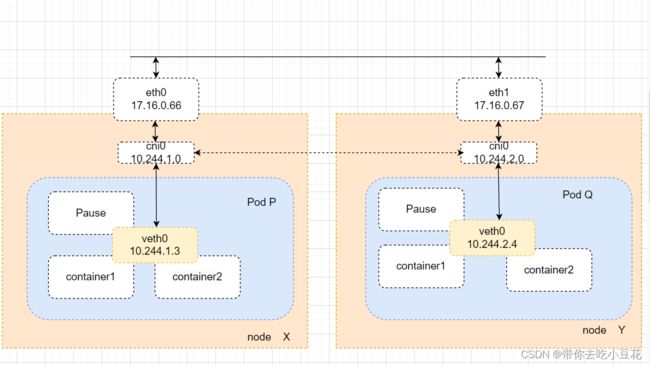
2、pod内不同容器间通信:
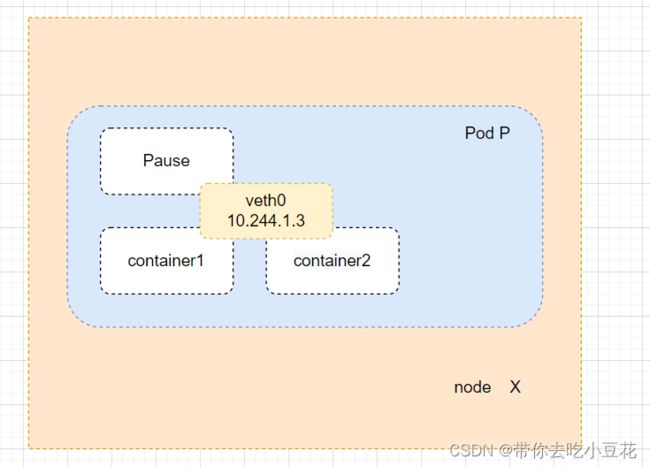
pod是K8S集群的最小单元,一个pod内部的容器必须位于用一个节点之上,前面说到,K8S的每个Pod都有一个独立的IP,因此使得同一个Pod内的不同容器会共享一个namespace,也就是同一个pod间的容器可以通过localhost接口即可连接对方端口,在本地内核协议栈上完成交互,如下图的container1和container2之间的通信,类似于一个主机上的多个进程间的本地通信。一个Pod内的网络名称空间,IP地址,网络设备,配置等都是共享的。一个pod内的pause容器有两个主要职责,一是为pod内其他容器提供网络名称空间共享的基础,二是扮演了PID1的角色,负责处理僵尸进程,因此不可随意删除。
3、service和pod之间通信
service ip又称为集群ip,需要在启动集群时指定,默认是10.96.0.0/12,也可以在启动ube-apiserver时由--service-cluster-ip-range指定,这个cluster ip 是固定的,管理员对service对象的创建或者更改操作会由Api server存储完成后触发各节点的kube-proxy,并将Service对象定义成iptables或者ipvs规则,pod或者节点客户端对service对象的ip地址的访问请求将由这些规则调度和转发,从而完成service和pod之间通信。
4、外部与service之间的通信
对于Kubernetes,集群外的客户端默认情况,无法通过Pod的IP地址或者Service 的虚拟IP地址:虚拟端口号进行访问。通常可以通过以下方式进行访问Kubernetes 集群内的服务:
映射Pod到物理机: 将Pod端口号映射到宿主机,即在Pod中采用hostPort方式,以使客户端应用能够通过物理机访问容器应用。
映射Service到物理机: 将Service端口号映射到宿主机,即在Service中采用nodePort方式,以使客户端应用能够通过物理机访问容器应用。
映射Service到LoadBalancer: 通过设置LoadBalancer 映射到云服务商提供的LoadBalancer地址。这种用法仅用于在公有云服务提供商的云平台上设置Service 的场景。
CNI网络插件
CNI:为容器解决网络解决方案,负责为各pod设置虚拟网络接口,分配ip,并将ip地址接入容器网络等任务,来实现pod间通信。
CNI网络插件是一个可执行程序文件,主要包括两部分:NetPlugin,IPAM
NetPlugin: 负责联通容器与容器之间以及容器与宿主机之间的通信,容器相关的网络设备通常由其创建,如:IP VLAN,Bridge,MAC VLAN,PTP,VETH,VLAN等虚拟设备。
IPAM(ip address management):负责管理IP地址,比如创建或删除地址池,分配或回收IP地址,其实现主要有host-local, dhcp两个,host-local 基于预先设置的地址范围进行地址分配,后一个通过DHCP协议来获取地址。
为了满足分布式pod必须位于同一个平面网络内,Netplugin目前常用的实现方案有:Overlay Network ,Underlay Network两类。

关于Overlay网络模型和underlay网络模型,下一篇文章再来详细说。
第二节、Pod的其他问题
pod有哪些分类:
自主式pod
控制器管理的pod,不同的控制器管理不用类型的pods,缺点是当node整个down掉,该node上所有pod就都丢失了
控制器管理的pod
Replication controller 副本控制器,比如定义允许两个pod副本存在,那就会多退少补,比如说有个节点宕机,副本数量少了一个,那么副本控制器就会象API server报告,然后再有调度器调度到一个合适的节点上,重新起一个pod,以满足2个副本。滚动更新,也可以回滚(1.2->1.1版本)
replicaSet 副本集控制器
Deployment 管理无状态应用
还支持HPA(horizontal pod autoscaler)水平pod自动伸缩控制器,实现水平自动扩展,pod数量不够自动扩展
statefulSet 有状态应用,表示一组具有唯一持久身份和稳定主机名的pod对象,旨在部署有状态应用和集群化应用,这些应用会将数据保存在永久性存储空间,适合部署kafka,mysql,redis,zookeeper以及其他需要唯一持久身份和稳定主机名的应用。
DaemonSet 单应用,用于运行一些系统级应用,比如说在每个节点上运行的日志收集守护进程fluentd,logstash等
Job 作业 适用于时间不固定的操作,比如临时清理一些数据,那就需要临时起一个pod,清理完了就不需要了,因此选择job控制器
Cronjob 周期性作业
pod可能有什么状态?
Pending: API Server 已经创建该 Pod, 且Pod 内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
Running: Pod 内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
Succeeded: Pod 内所有容器均成功执行退出,且不会重启。
Failed: Pod 内所有容器均已退出,但至少有一个容器退出为失败状态。
Unknown: 由于某种原因无法获取该Pod状态,可能由于网络通信不畅导致。
Kubernetes创建一个Pod的主要流程?
答: Kubernetes中创建一个Pod 涉及多个组件之间联动,主要流程如下:
1.用户通过kubectl命名发起请求。
2. apiserver 通过对应的kubeconfig 进行认证,认证通过后将yaml中的Pod信息存到etcd。
3.Controller-Manager 通过 apiserver的watch接口发现了Pod信息的更新,执行该资源所依赖的拓扑结构整合,整合后将对应的信息交给apiserver, apiserver写到etcd,此时Pod已经可以被调度了。
4. Scheduler 同样通过 apiserver 的watch接口更新到Pod 可以被调度,通过算法给Pod分配节点,并将pod和对应节点绑定的信息交给apiserver, apiserver 写到etcd,然后将 Pod交给kubelet。
5. kubelet 收到Pod 后,调用CNI接口给Pod创建Pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载。
Kubernetes 中Pod的健康检查方式?
答:对Pod的健康检查可以通过两类探针来检查: LivenessProbe和ReadinessProbe.
LivenessProbe探针: 用于判断容器是否存活(running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应处理。若一个容器不包含LivenessProbe探针,kubelet认为该容器的LivenessProbe探针返回值用于是"Success"
ReadinessProbe探针: 用于判断容器是否启动完成(ready状态)。如果ReadinessProbe探针探测到失败,则Pod 的状态将被修改。Endpoint Controller 将从 Service 的Endpoint 中删除包含该容器所在Pod的Eenpoint.
startupProbe探针: 启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被上面两类探针kill掉。
简述Kubernetes 中Pod 的重启策略?
答: Pod重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由 kubelet进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应操作。
Pod 的重启策略包括Always, OnFailure和Never,默认值为Always。
Always:当容器失效时,由kubelet 自动重启该容器;
OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器;
Never: 不论容器运行状态如何,kubelet都不会重启该容器。
同时Pod的重启策略与控制方式关联,当前可用于管理Pod的控制器包括ReplicationController, Job, DaemonSet 及直接管理 kubelet 管理(静态Pod) 。
不同控制器的重启策略限制如下:
RC和DaemonSet: 必须设置为Always,需要保证该容器持续运行;
Job: OnFailure 或 Never,确保容器执行完成后不再重启;
kubelet: 在Pod 失效时重启,不论将RestartPolicy设置为何值,也不会对Pod 进行健康检查。
简述Kubernetes Pod的常见调度方式?
答: Kubernetes中, Pod通常是容器的载体,主要有如下常见调度方式:
Deployment 或 RC: 该调度策略主要功能就是自动部署一个容器应用的多份副本,以及持续监控副本的数量,在集群内始终维持用户指定的副本数量。
NodeSelector: 定向调度,当需要手动指定将Pod调度到特定Node上,可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配。
NodeAffinity亲和性调度: 亲和性调度机制极大的护展了Pod的调度能力,目前有两种节点亲和力表达:
requiredDuringSchedulinglgnoredDuringExecution: 硬规则,必须满足指定的规则,调度器才可以调度Pod至Node上(类似nodeSelector,语法不同)
preferredDuringSchedulinglgnoredDuringExecution: 软规则,优先调度至满足的Node的节点,但不强求,多个优先级规则还可以设置权重值。
Taints和Tolerations (污点和容忍) :
Taint: 使Node拒绝特定Pod运行;
Toleration: 为Pod的属性,表示Pod能容忍(运行)标注了Taint的Node.
参考书籍:《kubernetes进阶实战》