yolo3详解及TF2代码复现
本文代码参考了YunYang1994 的神经网络代码 https://github.com/YunYang1994
yolo3原理参考了 Bubbliiiing的博客 https://blog.csdn.net/weixin_44791964
对YOLOv3 的损失函数参考了 神罗Noctis的学习笔记 https://zhuanlan.zhihu.com/p/80208709

yolo3详解及TF2代码复现
一、计算loss所需参数
在计算loss的时候,实际上是y_pre和y_true之间的对比:
y_pre就是一幅图像经过网络之后的输出,内部含有三个特征层的内容;
y_true就是一个真实图像中,将它的真实框的位置以及框内物体的种类,转化成yolo3网络输出后的格式的值。
实际上y_pre和y_true内容的shape都是
(batch_size,13,13,3,85)
(batch_size,26,26,3,85)
(batch_size,52,52,3,85)
1、 y_pre
y_pre就是一幅图像图像经过网络之后的输出,内部含有三个特征层的内容;
# 2.返回三个特征层的内容 [conv_sbbox, conv_mbbox, conv_lbbox]
# 三个特征层的shape分别为(N,13,13,255),(N,26,26,255),(N,52,52,255)的数据
def YOLOv3(input_layer):
route_1, route_2, conv = backbone.darknet53(input_layer)
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv = common.convolutional(conv, (3, 3, 512, 1024))
conv = common.convolutional(conv, (1, 1, 1024, 512))
conv_lobj_branch = common.convolutional(conv, (3, 3, 512, 1024))
# 第一个输出 最后输出是不加激活也不加BN层
conv_lbbox = common.convolutional(conv_lobj_branch, (1, 1, 1024, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.upsample(conv)
# 在通道维度上拼接
conv = tf.concat([conv, route_2], axis=-1)
conv = common.convolutional(conv, (1, 1, 768, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv = common.convolutional(conv, (3, 3, 256, 512))
conv = common.convolutional(conv, (1, 1, 512, 256))
conv_mobj_branch = common.convolutional(conv, (3, 3, 256, 512))
# 第二个输出
conv_mbbox = common.convolutional(conv_mobj_branch, (1, 1, 512, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.upsample(conv)
conv = tf.concat([conv, route_1], axis=-1)
conv = common.convolutional(conv, (1, 1, 384, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv = common.convolutional(conv, (3, 3, 128, 256))
conv = common.convolutional(conv, (1, 1, 256, 128))
conv_sobj_branch = common.convolutional(conv, (3, 3, 128, 256))
# 第三个输出
conv_sbbox = common.convolutional(conv_sobj_branch, (1, 1, 256, 3*(NUM_CLASS + 5)),
activate=False, bn=False)
# 我们预测每个尺度上有3个盒子,因此对于4个边界框偏移量,
# 1个对象预测和80个类预测,张量为N×N×[3 *(4 + 1 + 80)]
# 问题来了,为啥刚好做完这么多运算输出的东西这么刚刚好呢
return [conv_sbbox, conv_mbbox, conv_lbbox]
对于yolo3的模型来说,其最后输出的内容就是三个特征层的内容,三个特征层分别对应着图片被分为不同size的网格后,
每个网格点上三个先验框对应的位置、置信度及其种类。
对于输出的y1、y2、y3而言,[…, : 2]指的是相对于每个网格点的偏移量,
[…, 2: 4]指的是宽和高,[…, 4: 5]指的是该框的置信度,[…, 5: ]指的是每个种类的预测概率。
现在的y_pre还是没有解码的,解码了之后才是真实图像上的情况,解码过程比较简单。
下面是解码前后张量的形状对比(conv:解码前;pred:解码后)
i = 0
conv: tf.Tensor([ 4 76 76 21], shape=(4,), dtype=int32)
pred: tf.Tensor([ 4 76 76 3 7], shape=(5,), dtype=int32)
i = 1
conv: tf.Tensor([ 4 38 38 21], shape=(4,), dtype=int32)
pred: tf.Tensor([ 4 38 38 3 7], shape=(5,), dtype=int32)
i = 2
conv: tf.Tensor([ 4 19 19 21], shape=(4,), dtype=int32)
pred: tf.Tensor([ 4 19 19 3 7], shape=(5,), dtype=int32)
# 3. 利用先验框对网络的输出进行解码(将模型预测参数转化为有物理意义的参数)
def decode(conv_output, i=0):
"""
return tensor of shape [batch_size, output_size, output_size, anchor_per_scale,
5 + num_classes]
contains (x, y, w, h, score, probability)
"""
conv_shape = tf.shape(conv_output)
batch_size = conv_shape[0] # 样本数
output_size = conv_shape[1] # 输出矩阵大小
# 这个reshape为什么能那么恰好地把所有bounding box的5个值都放在矩阵的最里边排列好
conv_output = tf.reshape(conv_output, (batch_size, output_size, output_size, 3,
5 + NUM_CLASS))
# (batch_size, output_size, output_size, 3, 5 + NUM_CLASS) 改为2 + NUM_CLASS
conv_raw_dxdy = conv_output[:, :, :, :, 0:2] # 每个box的tx,ty
conv_raw_dwdh = conv_output[:, :, :, :, 2:4] # 每个box的tw,th
conv_raw_conf = conv_output[:, :, :, :, 4:5] # 置信度
conv_raw_prob = conv_output[:, :, :, :, 5: ] # 类别class 80个 的条件概率
# 将预测值tx,ty,tw,th 通过预测公式的变量关系转化为bounding box中心点坐标以及宽高,bx,by,bh,bw
# 返回 [pred_xywh, pred_conf, pred_prob]
y = tf.tile(tf.range(output_size, dtype=tf.int32)[:, tf.newaxis], [1, output_size])
x = tf.tile(tf.range(output_size, dtype=tf.int32)[tf.newaxis, :], [output_size, 1])
xy_grid = tf.concat([x[:, :, tf.newaxis], y[:, :, tf.newaxis]], axis=-1)
xy_grid = tf.tile(xy_grid[tf.newaxis, :, :, tf.newaxis, :], [batch_size, 1, 1, 3, 1])
xy_grid = tf.cast(xy_grid, tf.float32)
pred_xy = (tf.sigmoid(conv_raw_dxdy) + xy_grid) * STRIDES[i]
pred_wh = (tf.exp(conv_raw_dwdh) * ANCHORS[i]) * STRIDES[i]
pred_xywh = tf.concat([pred_xy, pred_wh], axis=-1)
pred_conf = tf.sigmoid(conv_raw_conf)
pred_prob = tf.sigmoid(conv_raw_prob)
return tf.concat([pred_xywh, pred_conf, pred_prob], axis=-1)
2、y_true
y_true就是一个真实图像中,将它的真实框的位置以及框内物体的种类,转化成yolo3网络输出后的格式的值。
在yolo3中,其使用了一个专门的函数用于处理读取进来的图片的框的真实情况。
def preprocess_true_boxes(self, bboxes):
其实对真实框的处理是将真实框转化成图片中相对网格的xyhw,步骤如下:
1、取框的真实值,获取其框的中心及其宽高,除去input_shape变成比例的模式。
2、建立全为0的y_true,y_true是一个列表,包含三个特征层,
shape分别为(m,13,13,3,85),(m,26,26,3,85),(m,52,52,3,85)。
3、对每一张图片处理,将每一张图片中的真实框的wh和先验框的wh对比,计算IOU值,
选取其中IOU最高的一个,得到其所属特征层及其网格点的位置,在对应的y_true中将内容进行保存。
对于最后输出的y_true而言,只有每个图里每个框最对应的位置有数据,其它的地方都为0。
二、loss的计算过程综述
1、利用y_true取出该特征层中真实存在目标的点的位置(m,13,13,3,1)及其对应的种类(m,13,13,3,80)。
2、将yolo_outputs的特征层输出进行处理,得到reshape后的预测值y_pre,
shape分别为(m,13,13,3,85),(m,26,26,3,85),(m,52,52,3,85)。还有解码后的xy,wh。
3、获取真实框编码后的值,后面用于计算loss
4、对于每一幅图,计算其中所有真实框与预测框的IOU,取出每个网络点中IOU最大的先验框,
如果这个最大的IOU都小于ignore_thresh,意味着这个网络点内不存在目标,可以被忽略。
5、计算xy和wh上的loss,其计算的是实际上存在目标的,
利用第三步真实框编码后的的结果和未处理的预测结果进行对比得到loss。
6、计算置信度的loss,其有两部分构成,第一部分是实际上存在目标的,预测结果中置信度的值与1对比;
第二部分是实际上不存在目标的,在第四步中得到其IOU还较大的预测结果中的值与0对比。
7、计算预测种类的loss,其计算的是实际上存在目标的,预测类与真实类的差距。
def compute_loss(pred, conv, label, bboxes, i=0):
conv_shape = tf.shape(conv)
batch_size = conv_shape[0]
output_size = conv_shape[1]
# STRIDES[i]对应三种大小的特征层
input_size = STRIDES[i] * output_size
conv = tf.reshape(conv, (batch_size, output_size, output_size, 3, 5 + NUM_CLASS))
conv_raw_conf = conv[:, :, :, :, 4:5]
conv_raw_prob = conv[:, :, :, :, 5:]
# 预测出的4个坐标值
pred_xywh = pred[:, :, :, :, 0:4]
# 预测含object的概率
pred_conf = pred[:, :, :, :, 4:5]
# 从标签文件中提取的坐标真值
label_xywh = label[:, :, :, :, 0:4]
respond_bbox = label[:, :, :, :, 4:5] # respond_bbox 猜测存在目标为1,不存在目标为0
label_prob = label[:, :, :, :, 5:]
# 疑问:为什么这里计算了一个giou又计算了一个iou,有什么区别,各有什么用途
# ①计算xy和wh上的loss,其计算的是实际上存在目标的,
# 利用第三步真实框编码后的的结果和未处理的预测结果进行对比得到loss。
giou = tf.expand_dims(bbox_giou(pred_xywh, label_xywh), axis=-1)
input_size = tf.cast(input_size, tf.float32)
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3]
* label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1- giou)
# 对于每一幅图,计算其中所有真实框与预测框的IOU,取出每个网络点中IOU最大的先验框,
# 如果这个最大的IOU都小于ignore_thresh,意味着这个网络点内不存在目标,可以被忽略。
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :],
bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1)
respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < IOU_LOSS_THRESH, tf.float32 )
conf_focal = tf.pow(respond_bbox - pred_conf, 2)
# ②计算置信度loss
conf_loss = conf_focal * (
# 含object的box的confidence预测
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox,
logits=conv_raw_conf)
+
# 不含object的box的confidence预测
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox,
logits=conv_raw_conf)
)
# ③计算类别条件概率的loss
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob,
logits=conv_raw_prob)
giou_loss = tf.reduce_mean(tf.reduce_sum(giou_loss, axis=[1,2,3,4]))
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1,2,3,4]))
prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1,2,3,4]))
return giou_loss, conf_loss, prob_loss
三、loss function 各部分与代码的对应关系
1、解读YOLOv3 的损失函数
在分析yolo3的损失函数之前,先来回顾一下yolo1的损失函数。
一般来说系统设计需要平衡边界框坐标损失、置信度损失和分类损失。论文中设计的损失函数如下:

对于 YOLOv3 的损失函数, Redmon J 在论文中并没有进行讲解。
从darknet 源代码中的forward_yolo_layer函数中找到 l.cost ,通过解读,总结得到 YOLOv3 的损失函数如下:

与v1 Loss类似,主要分为三大部分: 边界框坐标损失, 分类损失和置信度损失。
1)边界框坐标损失
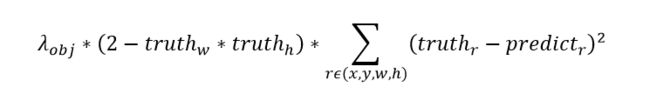
![]()
表示置信度,判断网格内有无物体。
与yolo v1的边界框坐标损失类似,v3中使用误差平方损失函数分别计算(x, y, w, h)的Loss,然后加在一起。
v1中作者对宽高(w, h)做了开根号处理,为了弱化边界框尺寸对损失值的影响。
在v3中作者没有采取开根号的处理方式,而是增加1个与物体框大小有关的权重,权重=2 - 相对面积,取值范围(1~2)。
2)分类损失
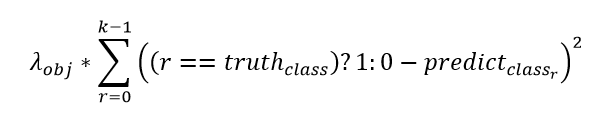
![]()
表示置信度,判断网格内有无物体。使用误差平方损失函数计算类别class 的Loss。
3)置信度损失
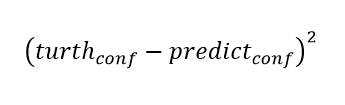
使用误差平方损失函数计算置信度conf 的Loss。
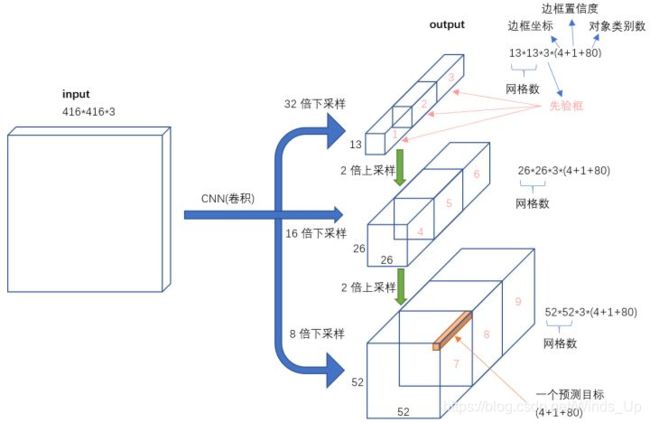
yolo v3三种不同尺度的输出,一共产生了(13133+26263+52523)=10647个预测框。

最终Loss采用和的形式而不是平均Loss, 主要原因为预测的特殊机制, 造成正负样本比巨大,
尤其是置信度损失部分, 以一片包含一个目标为例, 置信度部分的正负样本比可以高达1:10646,
如果采用平均损失, 会使损失趋近于0, 网络预测变为全零, 失去预测能力。
2. 边界框损失
目前目标检测中主流的边界框优化采用的都是BBox的回归损失(MSE loss, L1-smooth loss等),
这些方式计算损失值的方式都是检测框的“代理属性”—— 距离,而忽略了检测框本身最显著的性质——IoU。
由于IOU有2个致命缺点,导致它不太适合作为损失函数。GIoU延续了IoU的优良特性,
并消除了IoU的致命缺点。以下使用GIoU Loss作为边界框损失。
2.1 GIoU的计算
def bbox_giou(boxes1, boxes2):
# 将boxes[x,y,w,h]化为[x_min, y_min, x_max, y_max]的形式
boxes1 = tf.concat([boxes1[..., :2] - boxes1[..., 2:] * 0.5,
boxes1[..., :2] + boxes1[..., 2:] * 0.5], axis=-1)
boxes2 = tf.concat([boxes2[..., :2] - boxes2[..., 2:] * 0.5,
boxes2[..., :2] + boxes2[..., 2:] * 0.5], axis=-1)
boxes1 = tf.concat([tf.minimum(boxes1[..., :2], boxes1[..., 2:]),
tf.maximum(boxes1[..., :2], boxes1[..., 2:])], axis=-1)
boxes2 = tf.concat([tf.minimum(boxes2[..., :2], boxes2[..., 2:]),
tf.maximum(boxes2[..., :2], boxes2[..., 2:])], axis=-1)
# 计算boxes1、boxes2的面积
boxes1_area = (boxes1[..., 2] - boxes1[..., 0]) * (boxes1[..., 3] - boxes1[..., 1])
boxes2_area = (boxes2[..., 2] - boxes2[..., 0]) * (boxes2[..., 3] - boxes2[..., 1])
# 计算boxes1和boxes2交集的左上角坐标和右下角坐标
left_up = tf.maximum(boxes1[..., :2], boxes2[..., :2])
right_down = tf.minimum(boxes1[..., 2:], boxes2[..., 2:])
# 计算交集区域的宽高,如果right_down - left_up < 0,没有交集,宽高设置为0
inter_section = tf.maximum(right_down - left_up, 0.0)
# 交集面积等于交集区域的宽 * 高
inter_area = inter_section[..., 0] * inter_section[..., 1]
# 计算并集面积
union_area = boxes1_area + boxes2_area - inter_area
# 计算IOU
iou = inter_area / union_area
# 计算最小闭合凸面 C 左上角和右下角的坐标
enclose_left_up = tf.minimum(boxes1[..., :2], boxes2[..., :2])
enclose_right_down = tf.maximum(boxes1[..., 2:], boxes2[..., 2:])
# 计算最小闭合凸面 C的宽高
enclose = tf.maximum(enclose_right_down - enclose_left_up, 0.0)
# 计算最小闭合凸面 C的面积 = 宽 * 高
enclose_area = enclose[..., 0] * enclose[..., 1]
# 计算GIoU
giou = iou - 1.0 * (enclose_area - union_area) / enclose_area
return giou
xy均需要预测,wh不需要,代码框架不变
2.2 GIoU loss 的计算
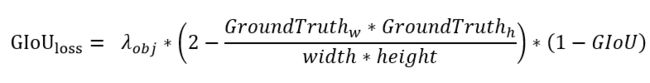
# ①计算xy和wh上的loss,其计算的是实际上存在目标的,
# 利用第三步真实框编码后的的结果和未处理的预测结果进行对比得到loss。
giou = tf.expand_dims(bbox_giou(pred_xywh, label_xywh), axis=-1)
input_size = tf.cast(input_size, tf.float32)
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3]
* label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1- giou)
respond_bbox 的意思是如果网格单元中包含物体,那么就会计算边界框损失;
box_loss_scale = 2 - 相对面积,值的范围是(1~2),边界框的尺寸越小,
bbox_loss_scale 的值就越大。box_loss_scale可以弱化边界框尺寸对损失值的影响;
两个边界框之间的 GIoU 值越大,giou 的损失值就会越小,
因此网络会朝着预测框与真实框重叠度较高的方向去优化。
3.置信度损失
3.1 引入Focal Loss
论文发现,密集检测器训练过程中,所遇到的极端前景背景类别不均衡(
extreme foreground-background class imbalance)是核心原因。
为了解决 one-stage 目标检测器在训练过程中出现的极端前景背景类不均衡的问题,
引入Focal Loss。Focal Loss, 通过修改标准的交叉熵损失函数,
降低对能够很好分类样本的权重(down-weights the loss assigned to well-classified examples),
解决类别不均衡问题.
Focal Loss的计算公式:

![]()


def focal(self, target, actual, alpha=0.25, gamma=2):
focal_loss = tf.abs(alpha + target - 1) * tf.pow(tf.abs(target - actual), gamma)
return focal_loss
3.2 计算置信度损失
conf_loss的计算公式:

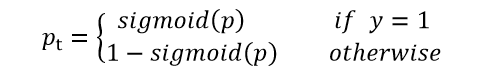
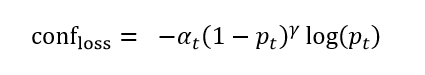
计算置信度损失必须清楚conv_raw_conf和pred_conf是怎么来的。边界框预测decode函数
conv_raw_conf 对应计算公式中的 , pred_conf 对应公式中的 。
开始动手构建conf_loss!
# ②计算置信度的损失
# 对于每一幅图,计算其中所有真实框与预测框的IOU,取出每个网络点中IOU最大的先验框,
# 如果这个最大的IOU都小于ignore_thresh,意味着这个网络点内不存在目标,可以被忽略。
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :],
bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
# 找出与真实框 iou 值最大的预测框
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1)
# 如果最大的 iou 小于阈值,那么认为该预测框不包含物体,则为背景框
respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < IOU_LOSS_THRESH, tf.float32 )
conf_focal = tf.pow(respond_bbox - pred_conf, 2)
# 置信度的损失(我们希望假如该网格中包含物体,那么网络输出的预测框置信度为 1,无物体时则为 0)
conf_loss = conf_focal * (
# 含object的box的confidence预测
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox,
logits=conv_raw_conf)
+
# 不含object的box的confidence预测
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, 、
logits=conv_raw_conf)
)
4.分类损失
这里分类损失采用的是二分类的交叉熵,即把所有类别的分类问题归结为是否属于这个类别,
这样就把多分类看做是二分类问题。

prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob,
logits=conv_raw_prob)
5. 最终Loss计算
将各部分损失值的和,除以均值,累加,作为最终的图片损失值。
giou_loss = tf.reduce_mean(tf.reduce_sum(giou_loss, axis=[1,2,3,4]))
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1,2,3,4]))
prob_loss = tf.reduce_mean(tf.reduce_sum(prob_loss, axis=[1,2,3,4]))
return giou_loss, conf_loss, prob_loss
四、自己的思考
有些地方还是想的不对,放在这里作个记录吧
这里放一张yolov1论文中定义的loss function,我们来对应一下
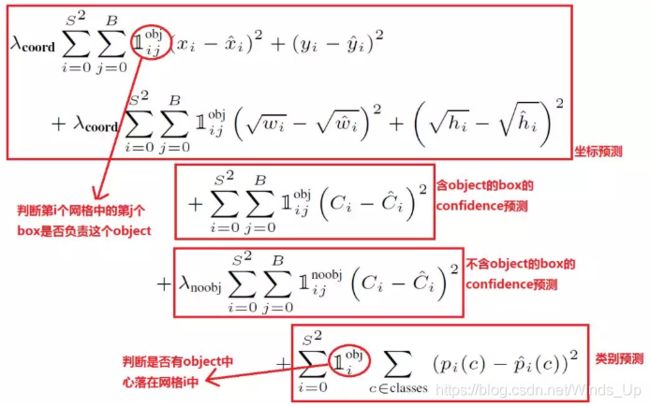
其实际上计算的总的loss是三个loss的和,这三个loss分别是:
①实际存在的框,编码后的结果与预测值的差距。
对应第一个红框,但是yolo3 的这一部分改成了计算预测框与真实框之间的iou loss
# ①计算xy和wh上的loss,其计算的是实际上存在目标的,
# 利用第三步真实框编码后的的结果和未处理的预测结果进行对比得到loss。
giou = tf.expand_dims(bbox_giou(pred_xywh, label_xywh), axis=-1)
input_size = tf.cast(input_size, tf.float32)
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3]
* label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1- giou)
②实际存在的框,预测结果中置信度的值与1对比;实际不存在的框,
在上述步骤中,第四步得到其IOU还较大的预测结果中的值与0对比。 对应中间两个红框
第一步:
# 对于每一幅图,计算其中所有真实框与预测框的IOU,取出每个网络点中IOU最大的先验框,
# 如果这个最大的IOU都小于ignore_thresh,意味着这个网络点内不存在目标,可以被忽略。
iou = bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :],
bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1)
respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < IOU_LOSS_THRESH, tf.float32 )
conf_focal = tf.pow(respond_bbox - pred_conf, 2)
第二步:
# ②计算置信度loss
conf_loss = conf_focal * (
# 含object的box的confidence预测
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox,
logits=conv_raw_conf)
+
# 不含object的box的confidence预测
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox,
logits=conv_raw_conf)
)
③实际存在的框,预测类别条件概率与实际结果的对比。对应最后一个红框
# ③计算类别条件概率的loss
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob,
logits=conv_raw_prob)