【机器学习算法】聚类算法-3 K均值聚类法,PAM法,神经网络聚类法SOM
目录
划分聚类法
K-means均值聚类法
PAM 方法
PAM和K-means的优缺点
SOM(神经网络的划分聚类方法)
总结
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
划分聚类法
上次我们讲了层次聚类法,这次我们来讲效果比较好的划分聚类法
需要事先指定我们需要将数据聚成几群。
K-means均值聚类法
现在假设我们知道数据要分为2类,于是我们就把数据分为两类。
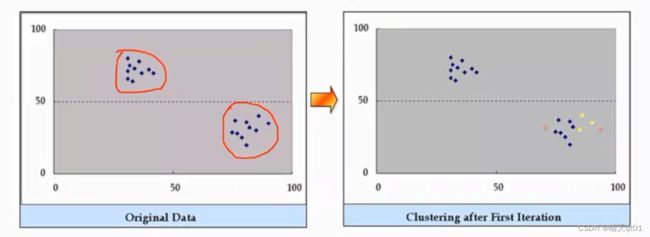
那么该方法会随机选择两个点,然后我们画这两个点的垂直平分线,做边属于第一类,右边属于第二类。于是我们把数据分为蓝色的点和黄色的点。
这里我们假设我们的输入变量只有2个x和y,我们把3个x加起来除以3,3个y加起来除以3,然后得到一个坐标,这个坐标就是我们新的中心。另外蓝色的17个点也是一样,我们将这17个点除以17,就会得到另一个中心。。
我们将这两个中心进行连线,画出垂直平分线,垂直平分线的左边是第一类右边是第二类。
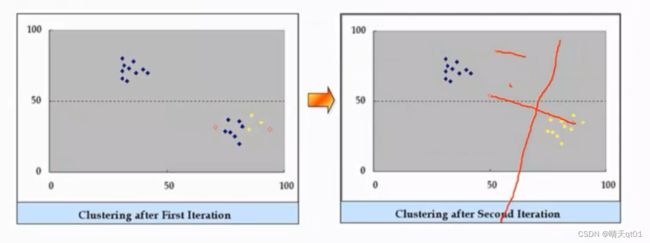
然后我们再次移动群中心。在进行分类
就会得到新的两类模型。
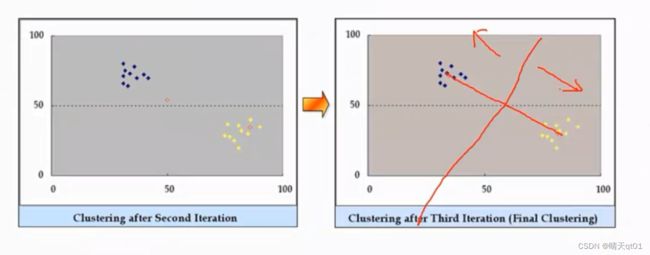
这时我们重新计算群中心,发现我们的分类也不会变化,于是我们就可以吧数据分为两群,群1和群2
这个方法简单,它只是一直在更改群中心的位置。然后进行聚类,速度非常的快
缺点:
缺点1对离群值非常敏感,如果我们这个题目,出现2个离群值,它就会把离群值聚为一群,非离群值聚为一群。K means如果不把离群值分为一群,那么它组间差异会太大。(不过有人认为,这个不算缺点,反而应该算优点,因为我们数据经常会有,outliers,如果我们用kmeans聚类中的类别非常少,那么我们就完全可以发现它是离群值,然后把它删除,重新聚类,之后聚类之后,在把离群值放进去,把它变为)
每次的结果都不一定会一致,不是一个最佳解
例如我们现在有一个点
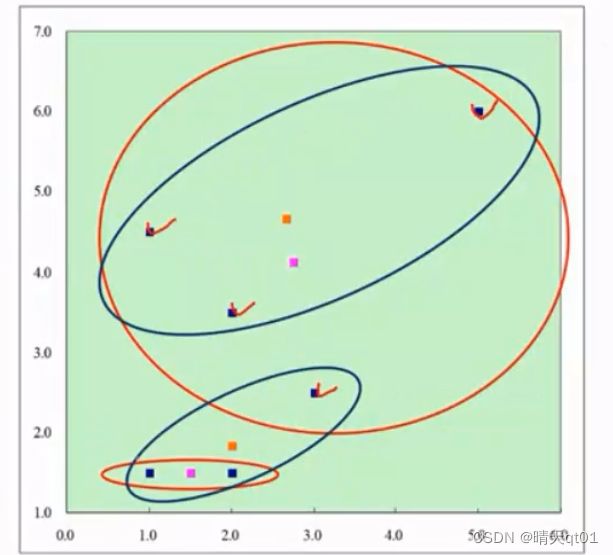
缺点2我们现在有6个资料点,蓝色就是我们的资料点,我们第一次kmeans的聚类位置为紫色时,kmeans的结果就是橙色的圈,分为两类
但是其实这种边缘的数据,它本身分在哪一类都可以,所以它跑出的结果是近似最佳解,其实我们也是可以接受的。
缺点3Kmeans只能处理数值型的字段。因为需要做平均
案例
银行聚类的问题:
这里我们用SS值(群内点距离求和)
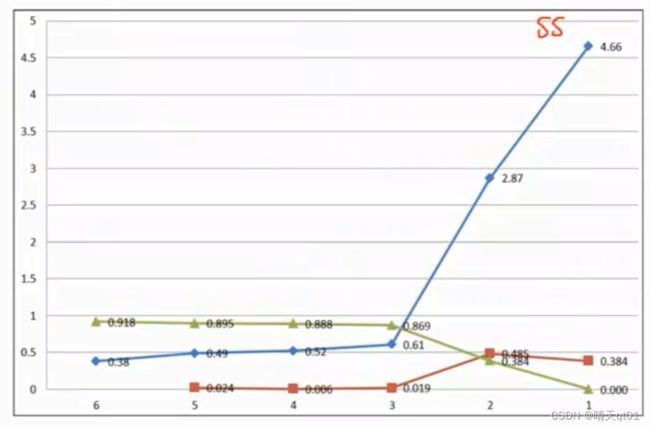
蓝色的线每个点代表聚类为该群的SS值,当群聚类数量下降的时候,SS值一定会增加。但是一般是上升趋势不会很大,如果上升趋势很大,说明群内变异增加很多,那么我们就不能考虑用这个群了,所以我们选择拐点处作为聚类规则。也就是分为将银行客户分为3类。
剩下绿色的线和红色的线用的是另外的两个评估方法,
初始群中心的选择
因为初始群中心和我们聚类的结果相关性很大,如果初始中心选择不当,就会出现很差的分群结果,
常用的方法如下
方法1常用的样本点作为初始的类群中心点(容易出现问题)
方法2,我们将第一个样本点作为群中心,然后设定一个既定标准,只有超过这个标准的下一个样本点才能被我们认定为第2个群中心点,以此类推来确定第3个样本点,(第3个样本点要和1群中心和2群中心的距离都超过标准距离),以此类推….
PAM 方法
解决K-means的2个问题
我们之前说过K-means的两个缺点,不能得到最佳分类规则,不能使用数值型的字段
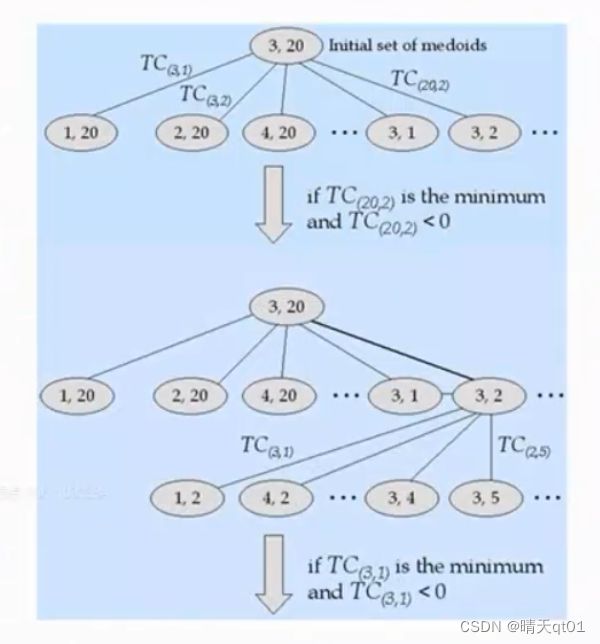
这时我们就有一个新方法,我们使用真实的资料点当群中心,比如看第一个图,我们把(3,20)当做群中心,也就是分两类,把3和20当做群中心,
然后我们再把3换成1,变成1和20个点作为群中心,再把3换成2,把2和20换成群中心。再把20换成1,换成2,把每个组合都换一边,再利用标准,我们这边采用SS值作为,标准,来求它的SS值,我们找出第一层谁的SS值最小,把它选出来,而且要求选出来的SS要比原材料点3,20的值好。
这时我们选择出了(3,2)这个点,还是一样,我们选择换其中一个真实资料点,其实下面每个群中心的SS值,然后我们发现1,2这个资料点能得到最小的SS值。
然后我们在进行交换的动作,有一个需要注意的点,如果更换之后的SS值变了,那么我们就停止,输出该分类结果,因为再怎么换SS值都不会减低。那就停止
所以用这个方法,得到的就是SS值最小的全域最佳解,解决了K-means的问题1
然后我们也可以使用非数值的字段,因为SS值是距离,而我们之前也说明了非数值字段如何计算距离。(也就是进行编码)
但是PAM的缺点就变成了速度很慢。
PAM方法和K-means聚类的优缺点刚好相反
举个例子。
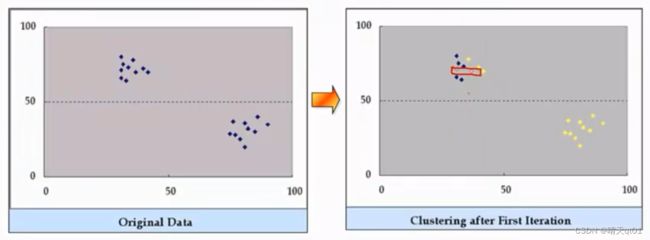
我们刚开始的群中心是右图,然后我们进行资料点的替换,替换到下图
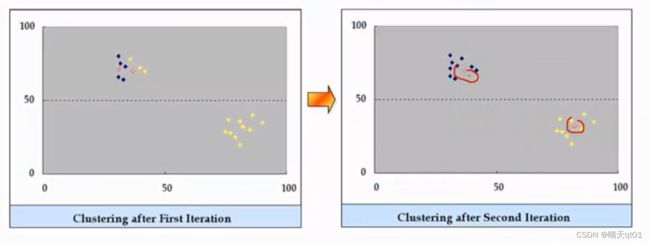
我们就可以进行第3次的替换,
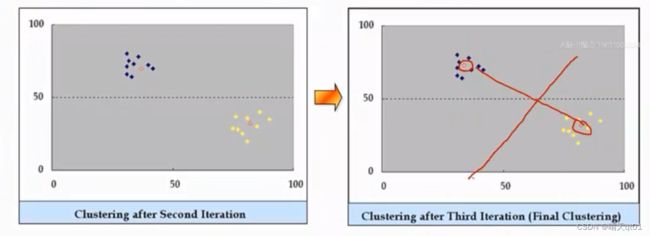
这时我们发现替换资料点,数据也不会变,于是我们就得出全域最佳解。
PAM和K-means的优缺点
K-means可以有效的处理大量的数据,但是不能处理数值型字段,而且对离群值很敏感
PAM则可以处理任何数据,但是资料集很大的时候,它会非常没有效率,速度上会慢很多。
SOM(神经网络的划分聚类方法)
要把群设定为?*?,比如我们要设定6个群,那么就要设定3*2
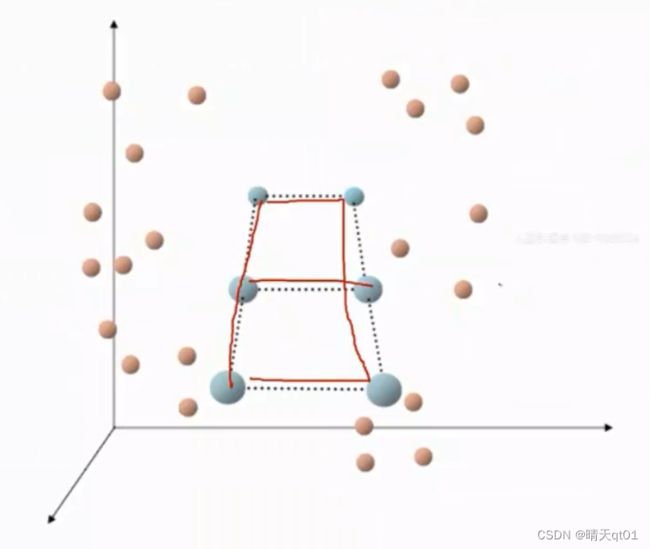
这时我们我们要修正群中心,群中心会主动向数据靠拢。
比如我们选择引入第一个数据,它最接近第一个群中心,那么群中心就会向第一个数据点靠拢
比较远的群中心也会移动,但是移动的距离会比较少一些。越远移动的越少。
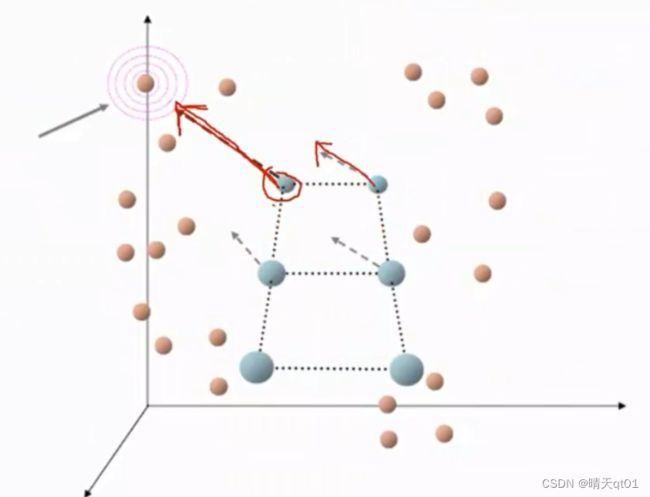
于是聚类点就变为下图
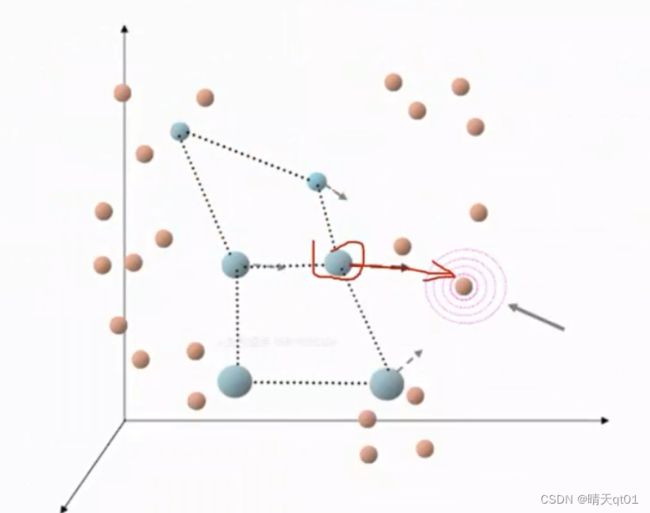
然后我们引入下一个真实数据点,,靠近它的群中心又会跑过去,每个数据点都会跑一遍,全部跑过一遍了,就叫做跑了一个回合。我们要不断的跑好几次,直到完全收敛。
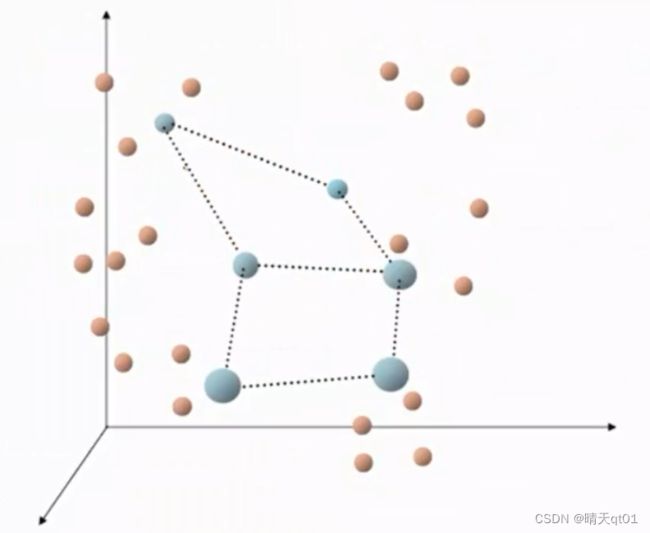
这时了很多回合后就可以得到最后的结果,如下图。
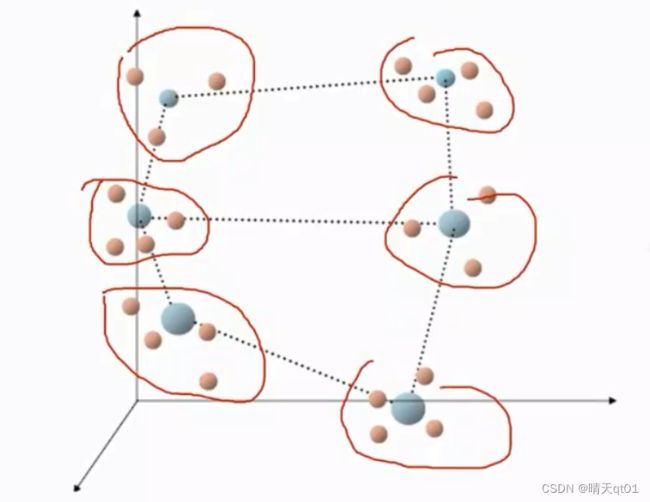
这就是SOM,叫自我组织映射法,的一个聚类过程。
总结
这就是我们3个比较有名的划分聚类法,K-means,PAM,SOM,这3个的软件资源最多,
Kmeans速度最快,但是只能处理数值字段,而且对outlier敏感,只能得到近似最佳解。
PAM能处理非数值型字段,也能得到全域最佳解,但是速度比Kmeans慢很多。
SOM是一个比较特殊的神经网络的聚类方法