基于YOLO模型的安全帽佩戴检测
YOLO模型的基本原理
YOLO网络是一个以目标检测为目的而设计的网络。YOLO系列算法的基本思想是将输入图像分 割为S×S个单元格, 且每个单元格生成B 个边界框, 由被检测目标中心点所在的单元格负责该目标的检测, 并计算对应边界框的置信度。
YOLO网络仅使用卷积层, 属于全卷积网络。这在减少了参数变量的同时, 加快了网络的运行速度。相比于其他神经网络,YOLO系列神经网络通过合理的设计,成功地将目标检测问题转化为回归问题,因而直接通过网络产生物体的位置和所属类别信息。而其他主流网络,大多数需要对已经过神经网络处理输出的图像进行再处理。
YOLOv3网络是YOLO网络作者根据初代YOLO网络,经过数次改良的产物,具有更好的性能。
YOLOv3主体卷积网络是以 Darknet53结构为基础。由图1可知,Darknet 53 结构由53层卷积层搭建而 成。为了防止梯度消失以及梯度爆炸现象,Darknet-53 网路之间由加入了残差单元, 这样可以让网络进行层数更深的训练。由于残差单元过多会导致其他不良的结果, 因此 Darknet-53 选择加入五个残差单元( Resnetunit)。每个残差单元的搭建如图 1( a)所示,上层原始输入不仅仅会通过两个DBL 单元输入到更下层, 还会跳过DBL单元直接到下层。换而言之,下层会收到原始上层数据以及处理过的上层数据。通过这种方式,构建了一个残差单元。DBL单元结构包含卷积层、 批归一化层和leakyrelu激活函数层,共计3层结构。
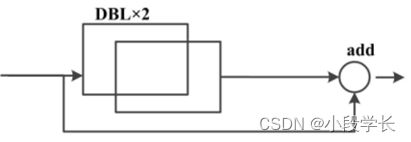
图1(a)残差单元

图1(b)Darknet53结构单元
YOLOv3加入了更多的卷积层,用于提取物体的深层特征。YOLOv3 共有 75 个卷积层, 包括跳跃连接和上采样层。此外, 它以 2 步长的卷积层替代了传统的最大池化层。卷积与池化层相比, 有了更多变化的可能。YOLOv3 网络对输入图片总共进行了5次降采样,并分别在最后3次降采样中对目标进行预测。最后3次降采样的输出, 可以理解为分别包含了3个尺度目标检测的特征图。当尺度越大时,其提取的特征图就越小。这些大小不同的特征图也有各自的作用:小特征图提供了深层次语义信息,大特征图则提供了目标位置信息。
此外,YOLOv3 网络中事先准备了通路,使得小特征图可以经过上采样和大特征图融合,从而使大特征图中含有小特征图中的特征信息。即使模型设定的检测目标较大,图中小特征的丢失也较少。因此,YOLOv3网络对于大小各异的目标均有不错的定位效果。
安全帽佩戴检测的一般步骤
采用YOLO v3算法设计一种变电站场景下作业人员检测和安全帽检测的级联网络, 如图2所示。首先检测作业人员,再将检测到的候选边框进行安全帽区域预估, 输入至安全帽检测网络中, 对变电站室内外的作业人员佩戴安全帽情况进行检测预警。

图2 安全帽检测流程
以下为示意图。

图3 安全帽检示意图
目标检测性能评估指标
基于深度学习的目标检测常用的评价指标通常包括准确率(Precision)、召回率(Recall)等:
Precision=TP/(TP+FP)
Recall=TP/(TP+FN)
式中:TP(true positive)为正确检测安全帽区域;FP(false positive)为将其他类别错误检测成安全帽区域;FN(false negative)为漏检的安全帽区域。
安全帽佩戴检测数据集(SHWD)的下载与读取
先根据链接下载数据集
创建数据集的配置文件
# 训练集和验证集的 labels 和 image 文件的位置
train: ./score/images/train
val: ./score/images/val
# number of classes
nc: 3
# class names
names: ['person', 'head', 'helmet']
创建每个图片对应的标签文件
使用标注工具LabelImg对图片标注,通过代码将xml文件解析并生成对应的txt文件。
文件数规范
VOC2028: .
├─Annotations # 标注文件
├─ImageSets
│ └─Main # 数据集分类
└─JPEGImages # 图片数据
将VOC标签格式转为yolo格式并划分数据集
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file= open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
在VOCdevkit目录下生成images和labels文件夹,文件夹下分别生成了train文件夹和val文件夹,里面分别保存着训练集的照片和txt格式的标签,还有验证集的照片和txt格式的标签。images文件夹和labels文件夹就是训练yolov5模型所需的训练集和验证集。在VOCdevkit/VOC2007目录下还生成了一个YOLOLabels文件夹,里面存放着所有的txt格式的标签文件。
YOLO模型的构建与训练
if __name__ == '__main__':
parser = argparse.ArgumentParser(prog='test.py')
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='*.data path')
parser.add_argument('--batch-size', type=int, default=32, help='size of each image batch')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.001, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.6, help='IOU threshold for NMS')
parser.add_argument('--task', default='val', help='train, val, test, speed or study')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--verbose', action='store_true', help='report mAP by class')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-json', action='store_true', help='save a cocoapi-compatible JSON results file')
parser.add_argument('--project', default='runs/test', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
opt.save_json |= opt.data.endswith('coco.yaml')
opt.data = check_file(opt.data) # check file
print(opt)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s_hat.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/hat.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=1)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
代码预测
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
cudnn.benchmark = True
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=opt.augment)[0]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], '%g: ' % i, im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s, getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if opt.save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or view_img: # Add bbox to image
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=3)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp8/weights/best.pt',
help='model.pt path(s)')
parser.add_argument('--source', type=str, default='./VOCdevkit/images/train/001146.jpg', help='source')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results',default=True)
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('pycocotools', 'thop'))
结果与对比分析
结果:

结果分析:
在目标检测算法测试中,常用的性能指标有准确率、召回率、平均准确率、平均准确率均值等等。
GloU:推测为GloU损失函数均值,越小方框越准;
Obeseness:推测为目标检测loss均值,越小目标检测越准;
Classification:推测为分类loss均值,越小分类越准;
Precision:精度(找对的正类/所有找到的正类);
Precision=TP/(TP+FP)
分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例,衡量的是一个分类器分出来的正类的确是正类的概率。两种极端情况就是,如果精度是100%,就代表所有分类器分出来的正类确实都是正类。如果精度是0%,就代表分类器分出来的正类没一个是正类。光是精度还不能衡量分类器的好坏程度,比如50个正样本和50个负样本,该分类器把49个正样本和50个负样本都分为负样本,剩下一个正样本分为正样本,这样我的精度也是100%,显然,这个分类器不太行。
Recall:召回率(找对的正类/所有本应该被找对的正类);
Recall=TP/(TP+FN)
分类器认为是正类并且确实是正类的部分占所有确实是正类的比例,衡量的是一个分类能把所有的正类都找出来的能力。两种极端情况,如果召回率是100%,就代表所有的正类都被分类器分为正类。如果召回率是0%,就代表没有正类被分为正类。
在实际测试时,算法可以检测出目标未佩戴安全帽或者其他帽子的情况,同时,在实际测试中,基于YOLO安全帽检测算法对多目标检测也有效果。试验结果表明,该检测方法能够在保持较高检测速率同时,基本满足实时检测要求。
出现的问题及解决方法
(1)在训练模型时如果速度过慢,可能是未使用GPU,可安装CUDA并通过pip install cudatoolkits对CUDA进行使用。
(2)在添加参数时,可将’—batch-size’的默认值适当调大(小于64),可是加快训练速度
(3)安装yolov5所依赖的包时,pycocotools这个包不再支持windows操作系统。把requirements.txt中最后一行的pycocotools >=2.0改为pycocotools-windows>=2.0然后再按照要求输入pip install -r requirements.txt即可
结果分析与体会
安全生产管理是建筑、重工业等高危企业发展的重要方针,安全帽在施工生产环境中对人员头部防护起着关键作用。 然而,由于施工人员流动性大、安全意识匮乏以及监管人员不到位等多种因素,导致实际工作中施工人员未佩戴安全帽的不安全行为时有发生,带来了极大的安全隐患。因此,安全帽 佩戴监管是高危作业环境中不可或缺的环节。传统依靠人工监管的方式存在效率低下、管理范围有 限、时效性差、无法全场监测等诸多缺陷,因此基于图像视觉的安全帽佩戴监测方法逐渐成为企业实施管理的主要手段。近年来,随着工业4.0概念的提出和深度学习等 高新技术的发展,场景目标物体检测逐渐成为计算机视觉领域的研究热点。传统视频监控系统对于工厂生产过程中设备或人为的异常情况,只能通过即时的人为监视或人工巡检,以及事后通过历史数据,查找当时事件发生状况。而智能检测系统能够在无人值守监控的情况下,随时随地使用一套固定的逻辑,及时记录不遵循规范的现场人员并通知相关人员。因此,研究如何从监控中提取有用信息,并对感兴趣的信息进行处理,具有重要的实际意义。 对于安全帽识别任务,目前大多数学者是基于传统方法。其中,利用肤色信息定位,再借助自动化仪表支持向量机,通过交叉验证选定合适的核函数,最终实现安全帽佩戴状态的识别;通过连续图像检测运动目标,根据颜色特征判断运动目标是否佩戴安全帽。上述研究已经取得了一些成果。但由于头盔颜色形状差异,以及相机角度、距离、光线等外界因素变化,这些安全帽识别算法的鲁棒性较差,易受外界环境干扰。综上所述,对于安全帽识别任务,目前欠缺一种高鲁棒性的分类算法。随着深度学习技术的不断发展,提出了多种基于深度学习的目标检测和目标跟踪算法,为研究者提供崭新的思路。
我们利用安全帽佩戴检测数据集(SHWD)了解了YOLO模型的基本原理。YOLO网络是一个以目标检测为目的而设计的网络。YOLO系列算法的基本思想是将输入图像分割为S×S个单元格, 且每个单元格生成B个边界框,由被检测目标中心点所在的单元格负责该目标的检测,并计算对应边界框的置信度。YOLO网络仅使用卷积层,属于全卷积网络。这在减少了参数变量的同时,加快了网络的运行速度。相比于其他神经网络,YOLO系列神经网络通过合理的设计,成功地将目标检测问题转化为回归问题,因而直接通过网络产生物体的位置和所属类别信息。而其他主流网络,大多数需要对已经过神经网络处理输出的图像进行再处理。YOLOv3网络是YOLO网络作者根据初代YOLO网络,经过数次改良的产物,具有更好的性能。YOLOv3主体卷积网络是以 Darknet53结构为基础。Darknet 53 结构由53层卷积层搭建而成。为了防止梯度消失以及梯度爆炸现象,Darknet-53 网路之间由加入了残差单元,这样可以让网络进行层数更深的训练。由于残差单元过多会导致其他不良的结果,因此 Darknet-53 选择加入五个残差单元( Resnetunit)。每个残差单元的搭建上层原始输入不仅仅会通过两个DBL单元输入到更下层,还会跳过DBL单元直接到下层。换而言之,下层会收到原始上层数据以及处理过的上层数据。通过这种方式,构建了一个残差单元。DBL单元结构包含卷积层、 批归一化层和leakyrelu激活函数层,共计3层结构。YOLOv3加入了更多的卷积层,用于提取物体的深层特征。YOLOv3 共有 75 个卷积层,包括跳跃连接和上采样层。此外,它以2步长的卷积层替代了传统的最大池化层。卷积与池化层相比,有了更多变化的可能。YOLOv3 网络对输入图片总共进行了5次降采样,并分别在最后3次降采样中对目标进行预测。最后3次降采样的输出,可以理解为分别包含了3个尺度目标检测的特征图。当尺度越大时,其提取的特征图就越小。这些大小不同的特征图也有各自的作用:小特征图提供了深层次语义信息,大特征图则提供了目标位置信息。此外,YOLOv3 网络中事先准备了通路,使得小特征图可以经过上采样和大特征图融合,从而使大特征图中含有小特征图中的特征信息。即使模型设定的检测目标较大,图中小特征的丢失也较少。因此,YOLOv3网络对于大小各异的目标均有不错的定位效果。
基于YOLO模型安全帽检测在企业安全生产场景中的方案运用到如下领域:
(1) 前端设备:AI安全生产高清摄像机
(2) 云服务端:EasyCVR视频融合云服务平台
(3) 客户终端:PC、智能手机、平板、微信端等
将安全生产AI摄像机部署在工地的各个出入通道口、施工作业区域等位置,对监控范围内的工作人员实时监测是否佩戴安全帽、是否穿戴反光服。当检测到进入施工场地的人员未佩戴安全帽/未穿戴反光服时,将及时抓拍保存,并联动语音广播发出警报提示,同时将告警信息传送到平台。
YOLO采用单个卷积神经网络来预测多个bounding boxes和类别概率。本方法相对于传统方法有如下优点:
(1) 速度非常快。YOLO预测流程简单,速度很快。基础版在Titan X GPU上可以达到45帧/s;快速版可以达到150帧/s。因此,YOLO可以实现实时检测。
(2) YOLO采用全图信息来进行预测。与滑动窗口方法和 regionproposal-based方法不同,YOLO在训练和预测过程中可以利用全图信息。FastR-CNN检测方法会错误的将背景中的斑块检测为目标,原因在于Fast R-CNN在检测中无法看到全局图像。相对于Fast R-CNN,YOLO背景预测错误率低一半。
(3) YOLO可以学习到目标的概括信息,具有一定普适性。采用自然图片训练YOLO,采用艺术图像来预测。YOLO比其它目标检测方法(DPM和 R-CNN)准确率高很多。
本方法有如下缺点:
(1) YOLO对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
(2) 对测试图像中,同一类物体出现的新的不常见的长宽比和其他情况是。泛化能力偏弱。
(3) 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。
课程实验是培养学生综合运用所学知识、发现问题、提出分析和解决实际问题,锻炼实践能力的重要环节,是对学生实际能力的具体训练和考察过程。完成课程实验,我们收获很多。首先是激发了我们的兴趣,将对我们以后的学习产生积极的影响。其次,这次课程实验让我们充分认识到团队合作的重要性,只有分工协作才能保证整个项目的有条不絮。另外在实验设计的过程中,我们当中有谁碰到不明白的问题时,会互相讨论,帮忙解答出点子,互相帮助,获益匪浅。通过这次课程实验,我们也懂得了学习的重要性,了解到理论知识与实践相结合的重要意义,学会了坚持、耐心和努力,这将对我们今后的学习和工作产生积极作用。作为学习信息安全专业的学生,这次课程设计是很有意义的,让我们对计算机领域——人工智能有了进一步了解,更重要的是学会了如何把自己平时所学的东西应用到实际中。我觉得课程项目反映的是一个从理论到实际应用的过程,但是更远一点可以联系到以后,毕业之后从学校转到踏上社会的一个过程。小组成员的配合、相处、以及自身的动脑和努力,都是以后工作中需要的。理论与实际相结合是很重要的,仅仅是理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从实践中得出结论,才能真正为社会服务,从而提高自己的实际动手能力和独立思考的能力。在完成课程项目的过程中遇到很多问题,可以说是困难重重,但可喜的是最终都得到了解决。
理论知识很必要,实践也不可缺少,只有在实践中才能更清楚的了解自己对理论知识的掌握程度,才能学以致用。这次课程项目极大地提高了我们组的实践能力。在完成作业过程中,学到了很多人生的哲理,懂得怎么样去制定计划,怎么样去实现这个计划,最终收获黎明。希望以后我们能再接再厉,了解更多的知识,增强自己实际运用能力,不断提升自己。
欢迎大家加我微信交流讨论(请备注csdn上添加)
