Mysql进阶优化篇03——多表查询的优化
前 言
作者简介:半旧518,长跑型选手,立志坚持写10年博客,专注于java后端
专栏简介:mysql基础、进阶,主要讲解mysql数据库sql刷题、进阶知识,包括索引、数据库调优、分库分表等
文章简介:本文将介绍多表查询的sql优化,绝对不需要死记硬背,建议收藏备用。
相关推荐:
- MySql进阶索引篇01——深度讲解索引的数据结构:B+树
- Mysql进阶索引篇02——InnoDB存储引擎的数据存储结构
- Mysql进阶索引篇03——2个新特性,11+7条设计原则教你创建索引
- Mysql进阶优化篇01——四万字详解数据库性能分析工具(深入、全面、详细,收藏备用)
Mysql进阶优化篇02——索引失效的10种情况及原理- 大厂SQL面试真题大全
文章目录
- 1.数据准备
- 2. 采用左外连接
- 3.采用内连接
1.数据准备
创建type表。
CREATE TABLE IF NOT EXISTS `type` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
创建book表。
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
在type表中执行20次如下数据,插入20条数据。
INSERT INTO TYPE(card) VALUES(FLOOR(1 + RAND() * 20));
同样的,在book表中插入20条数据。
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
2. 采用左外连接
我们知道多表查询分为外连接和内连接,而外连接又分为左外连接,右外连接和满外连接。其中外连接中,左外连接与右外连接可以通过交换表来相互改造,其原理也是类似的,而满外连接无非是二者的一个综合,因此外连接我们只介绍左外连接的优化即可。
执行左外连接操作。
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
执行结果如下。

在上面的查询sql中,type表是驱动表,book表是被驱动表。在执行查询时,会先查找驱动表中符合条件的数据,再根据驱动表查询到的数据在被驱动表中根据匹配条件查找对应的数据。因此被驱动表嵌套查询的次数是20*20=400次。实际上,由于我们总是需要在被驱动表中进行查询,优化器帮我们已经做了优化,上面的查询结果中可以看到,使用了join buffer,将数据缓存起来,提高检索的速度。
为了提高外连接的性能,我们添加下索引。
CREATE INDEX Y ON book(card); #【被驱动表】,可以避免全表扫描
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
查询结果如下,用上了索引,效率提升了。
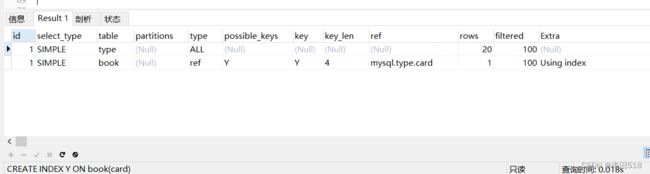
对于外层表来说,虽然其查询仍然是全表扫描,但是因为是左外连接,LEFT JOIN左边的表的数据无论是否满足条件都会保留,因此全表扫描也是不赖的。
我们当然也可以给type表建立索引。
CREATE INDEX X ON `type`(card); #【驱动表】,无法避免全表扫描
# ALTER TABLE `type` ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
结果如下
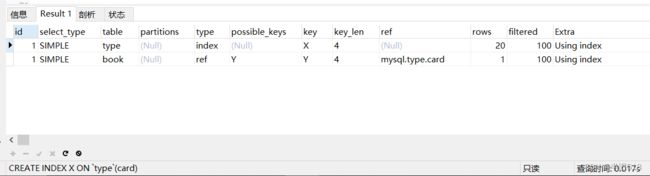
注意,外连接的关联条件中,两个关联字段的类型、字符集一定要保持一致,否则索引会失效哦。
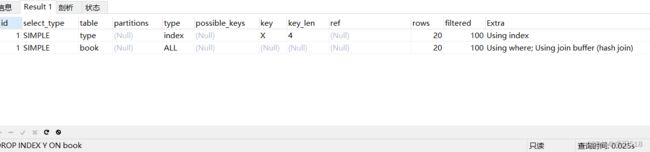
删除索引Y,再查询。
DROP INDEX Y ON book;
EXPLAIN SELECT SQL_NO_CACHE * FROM `type` LEFT JOIN book ON type.card = book.card;
结果如下。book表使用join buffer,再次验证了左外连接左边的表是驱动表,右边的表是被驱动表,后面我们将与内连接在这一点进行对比。
3.采用内连接
删除现有的索引。
drop index X on type;
drop index Y on book;(如果已经删除了可以不用再执行该操作)
执行内连接。
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
结果如下。

下面在book表中添加索引再执行查询。
ALTER TABLE book ADD INDEX Y ( card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
结果如下。

再给type加个索引。
ALTER TABLE type ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
执行结果如下。

您发现了吗?上面的两次查询中,第一次是使用type作为驱动表,book作为被驱动表。而第二次是使用book作为驱动表,type作为被驱动表。
删除被驱动表的索引。
DROP INDEX X ON `type`;
EXPLAIN SELECT SQL_NO_CACHE * FROM TYPE INNER JOIN book ON type.card=book.card;
又反转了。

这是因为内连接优化器可以决定驱动表。在只有一个表存在索引的情况下,会选择存在索引的表作为被驱动表(因为被驱动表查询次数更多)。
再加上索引。
ALTER TABLE `type` ADD INDEX X (card);
EXPLAIN SELECT SQL_NO_CACHE * FROM type INNER JOIN book ON type.card=book.card;
执行结果如下。又翻转了。

再在book表中添加三条数据,使book表的数据多于type表。
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
INSERT INTO book(card) VALUES(FLOOR(1 + RAND() * 20));
结果又翻转了。

在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表(大表全表扫描代价更大)。“小表驱动大表”。
工欲善其事,必先利其器”。要想成为工作上的数据库高手,面试时的题霸,独步江湖,就必须拿到一份"武林秘籍"。

我个人强推牛客网:找工作神器|大厂java面经汇总|超全笔试题库
推荐理由:
1.刷题题库,题目特别全面,刷爆笔试再也不担心
链接: 找工作神器|大厂java面经汇总|超全笔试题库
2.超全面试题、成体系、高质量,还有AI模拟面试黑科技
链接: 工作神器|大厂java面经汇总|超全笔试题库
3.超多面经,大厂面经很多
4.内推机会,大厂招聘特别多
链接: 找工作神器|大厂java面经汇总|超全笔试题库
5.大厂真题,直接拿到大厂真实题库,而且和许多大厂都有直接合作,题目通过率高有机会获得大厂内推资格。
链接: 找工作神器|大厂java面经汇总|超全笔试题库