重生之——C语言与我不得不说的故事(正文篇)
目录
1.指针
1.1指针的声明:
1.2间接访问操作:
1.3NULL指针
1.4指针常量
1.5指针的指针
1.6指针的运算
1.6.1算术运算
1.6.2关系运算
2.函数
2.1函数的定义
2.2函数的声明
2.3关键字return void
2.4函数的参数
2.4.1传值调用
2.4.2传址调用
2.5函数的指针
2.6递归函数
2.7可变参数列表
3数组
3.1一维数组
3.1.1数组名
3.1.2下标引用和间接访问
3.1.3数组和指针
3.1.4数组作为函数参数
3.1.5数组的初始化
3.1.6字符串数组的初始化
3.2多维数组
3.2.1多维数组的定义
3.2.2下标
3.2.3指向数组的指针
3.2.4多维数组作为函数参数
3.3指针数组
4字符串,字符和字节
4.1字符串基础
4.2不受限制的字符串函数
4.2.1复制字符串
4.2.2连接字符串
4.2.3函数的返回值
4.2.4字符串比较
4.3长度受限的字符串函数
4.4字符串查找基础
4.4.1查找一个字符
4.4.2查找多个字符
4.5高级字符串查找
4.5.1查找一个字符串前缀
4.5.2查找标记
4.6字符操作
4.6.1字符分类
4.6.2字符转换
4.7内存操作
5结构和联合
5.1结构基础知识
5.1.1结构声明
5.1.2结构成员
5.1.3结构成员的直接访问
5.1.4结构成员的间接访问
5.2作为函数参数的结构
5.3联合
6动态内存分配
6.1 malloc
6.2 free
6.3 calloc
6.4 realloc
6.5动态内存分配实例
7 使用结构和指针
7.1链表
7.2单链表
7.2.1单链表插入
7.3双链表
1.指针
1.1指针的声明:
int a = 1;//定义整型变量a赋值为1
int *pa = &a;//定义指针变量pa且赋a的地址1.2间接访问操作:
int a = 1;//定义整型变量a赋值为1
int *pa = &a;//定义指针变量pa且赋a的地址
*pa = *pa + 1;
//通过访问指针所指向的地址的过程注意事项:*pa = *pa + 1;只对指针pa位置处的值进行+1,也就是a=2,但是指针pa位置不变
1.3NULL指针
注意事项:是一种特殊指针,表示这个指针当前没有指向任何东西。
1.4指针常量
*(int *)100 = 25;注意事项:由于100是整型所以不能直接*100=25,而是把100先强制转换为“指向整型的指针”。
1.5指针的指针
int **pa = &a;注意事项:**pa代表拆开来看是*(*pa),从里往外算,也就是先访问pa所指向的位置然后再访问该位置指向的地址。
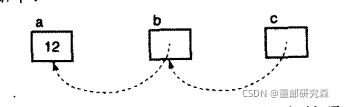
如上图,a中存放整型变量,b里面存放指向a的指针变量,c中存放指向b的指针变量。
1.6指针的运算
1.6.1算术运算
注意事项:对于定义的一个int指针pa,pa+1表示指向写一个int(float和char同理)
例如:在一个数组中,*pa代表指向第一个元素,那么*(pa+1)代表指向第二个元素
1.6.2关系运算
>,<,>=,<=,++,--,!=
2.函数
2.1函数的定义
类型+函数名(形参)
{
功能
}
2.2函数的声明
1.在程序之前写好定义,例如:void Sum(int a, int b);
2.创建头文件进行调用,例如#include
2.3关键字return void
return:返回函数值,由函数定义的类型决定,如果一个函数定义不是void,则必有返回值
void:函数类型特殊形式,表示该函数无返回值。
2.4函数的参数
2.4.1传值调用
注意事项:被调用参数的值不变(例如常量)
2.4.2传址调用
注意事项:被调用的参数值变化(例如数组)
2.5函数的指针
定义:类型 (*名字)(int ,char)用一个指针变量来调用该函数。其中指针变量的地址是函数的首地址
举例如下:
#include
//返回两个数中较大的一个
int max(int a, int b){
return a>b ? a : b;
}
int main(){
int x, y, maxval;
//定义函数指针
int (*pmax)(int, int) = max; //也可以写作int (*pmax)(int a, int b)
printf("Input two numbers:");
scanf("%d %d", &x, &y);
maxval = (*pmax)(x, y);
printf("Max value: %d\n", maxval);
return 0;
} 2.6递归函数
举例如下:
#include
void Deal( int x);
int main()
{
int x;
scanf("%d",&x);
Deal(x);
printf("%c",x%10+'0');
}
void Deal( int x)
{
int Values=x/10;
if(Values != 0)
{
Deal(Values);
printf("%c",Values%10+'0');
}
}
//利用递归实现输入整型获得字符型 2.7可变参数列表
定义:当函数的定义形参数多于调用函数的型参数。
举例如下:该函数形参定义是5个变量,而实际调用只有3个变量,程序仍然可以正确运行
#include
#include
int main()
{
int x=6,y=2;
aver(2,x,y);
return 0;
}
void aver(int Value,int x,int y,int z,int q)
{
int sum=0;
if(Value==1)
{
sum=sum+x;
printf("%d",sum/1);
}
if(Value==2)
{
sum=sum+x+y;
printf("%d",sum/Value);
}
} 3数组
3.1一维数组
3.1.1数组名
int a[]
这里的a是一个指针常量,代表指向这个数组第一个元素的地址
注意事项:
int a[10];
int *pa
pa=a //正确,把数组d的首地址传递给指针变量pa
a=pa //错误,因为a是指针常量,不能再修改3.1.2下标引用和间接访问
*(a+2) 这里的(a+2)是下标访问,而*()则是间接访问。两者优先级相等。
表示数组a的第三个位置之后,访问这个位置的值
注意事项:
a[0]=pa[0]
*a=*pa
*(a+1)=*(pa+1)3.1.3数组和指针
数组:编译器将根据生命所指定的数组元素数量保留内存空间,然后再创建数组名。它的值是一个常量,指向这段空间的起始位置
指针:编译器只为指针本身保留内存空间(当指针变量未被初始化时,不会有内存空间)
3.1.4数组作为函数参数
void swap(int a[])//形参为数组
{
int b[]={0,0,0,0,0,};
int i;
for(i=0;i<5;i++)
{
a[i]=b[i];
printf("%d,%d\n",a[i],a+i);
}
}void swap(int c)//变量作为参数
{
c=c+2;
printf("%d,%d\n",c,&c);
}被调用的a数组的值皆为0,但每个数组值的地址并没有发生变化。
被调用的变量c的值和地址都没有发生变化。
3.1.5数组的初始化
int a[]={1,2,3}//a[0]=1,a[1]=2,a[2]=3其中,a[0]=1,a[2]=3
注意:a[2]={1,2,3}是错的,a[2]={1}是对的。不能把三个值装到两个变量中,而第二个则是把后面元素补0装到两个元素中,因此一般采用代码中的数组定义方法。
3.1.6字符串数组的初始化
char ljs[]="Hello";3.2多维数组
3.2.1多维数组的定义
定义:数组的维数不止一个,则被称为多维数组,例如
int message[][]={{1,2,3},{4,5,6}};//这是一个两行三列数组,也可以理解为:这是两个元素的数组且每个元素又有三个元素。其中message是指向第一个元素{1,2,3}的指针
3.2.2下标
int a[2][3]={{11,22,33},{44,55,66}};
printf("%d\n",a); //表示指向二维数组第一行的指针
printf("%d\n",a+1); //表示指向二维数组第二行的指针
printf("%d\n",*a); //表示指向二维数组第一行的指针基础上再取*,指向第一个元素的指针
printf("%d\n",*(a+1)) //表指向二维数组第二行的指针基础上再取*,指向第一个元素的指针
printf("%d\n",*a+1);//表示指向二维数组第一行的指针基础上再取*,指向第二个元素的指针
printf("%d\n",**a); //表示指向二维数组第一行第一个元素的指针再*,访问第一个元素的值
printf("%d\n",*(*(a+1))) 表指向二维数组第二行第一个元素指针再*,访问第一个元素的值
注意事项:二维数组要访问值的时候要取**,因为一个*只代表二维数组的某行的某个元素的指针,因此要访问该指针指向的变量还需要再取*来访问此处的值。
3.2.3指向数组的指针
初始化方式:
int *pa = &message[0][0]int *pa = message[0]
int (*pa)[X] = message //在已知X的具体值时,可以用这种初始化,否则不要使用
注意事项:
int message[2][3] int *pa =message //错误定义,因为pa是整型指针,但是message是整型数组的指针
3.2.4多维数组作为函数参数
初始化方式:mat[3][10]
void fcn(int (*mat)[10])//指针形式
void fcn(int mat[][10]) //数组形式
3.3指针数组
定义:一个数组里面存放的全是指针
声明:int *pa[10]
4字符串,字符和字节
4.1字符串基础
字符串中,不包含NUL字符,字符串的长度:字符个数
4.2不受限制的字符串函数
4.2.1复制字符串
函数原型:char *strcpy(char *dst, char const *src)把src的字符复制到dst中
int main()
{
char src[]="This is runoob.com";
char dest[100];
strcpy(dest, src);
printf("最终的目标字符串: %s\n", dest);
return(0);
}
//输出结果:This is runoob.com4.2.2连接字符串
函数原型:char *strcat(char *dst, char *src) 把src的字符放到dst的末尾
int main()
{
char src[]="This is runoob.com";
char dest[]=”ljs“;
strcpy(dest, src);
printf("最终的目标字符串: %s\n", dest);
return(0);
}
//输出结果:ljsThis is runoob.com4.2.3函数的返回值
用于函数的嵌套:函数的返回值是指向目标字符数组的指针
strcat(strcpy(dst,a),b)//把a复制到dst,再把b放到dst后面
4.2.4字符串比较
函数原型:int strcmp(char const *s1, char const *s2)
4.3长度受限的字符串函数
4.4字符串查找基础
4.4.1查找一个字符
char *strchr(char const *str, int ch);//查找str中第一个ch,并且返回当前指针
char *strrchr(char const *str, int ch);//查找str中最后一个ch,并且返回当前指针
int main ()
{
const char str[] = "htt!p:ru!nooc!om";
const char ch = '!';
char *ret;
ret = strchr(str, ch);
printf("|%c| 之后的字符串是 - |%s|\n", ch, ret);
return(0);
}
//输出结果是p:ru!nooc!om
4.4.2查找多个字符
函数原型:char *strpbrk(char const *str, char const *group)//在str中查找group
4.5高级字符串查找
4.5.1查找一个字符串前缀
函数原型:size_t strspn(char const *str, char const *group) //在str中去匹配group,且必须从第一个字符开始算
int main ()
{
int len;
const char str1[] = "ABCDEFG019874";
const char str2[] = "AB1987D";
len = strspn(str1, str2);
printf("初始段匹配长度 %d\n", len );
return(0);
}
//输出结果:24.5.2查找标记
4.6字符操作
4.6.1字符分类

4.6.2字符转换
函数原型:
int tolower(int ch)//把大写转为小写
int toupper(int ch)// 把小写转为大写
int main ()
{
int i;
char str[] = "ABC";
for(i=0;i<5;i++)
{
putchar(tolower(str[i]));
}
return 0;
}
输出结果:abc
4.7内存操作
5结构和联合
5.1结构基础知识
解释:结构是用来存放不同数据类型的“数组”,而数组是用来存放相同类型的。数组通过指针或者下标访问,但是结构通过名字访问。
5.1.1结构声明
声明(1):定义一个叫x变量的结构体,x中包含2个成员
struct ljs {
int a;
char b;
}x;
struct ljs y;//声明了ljs类型结构体y
注意事项:ljs只是这种结构类型的名字,而x才是真正的结构体
声明(2):定义一个叫x变量的结构体类项名
typedef struct {
int a;
char b;
}x;
x ljs; //定义一个x类型的ljs结构体变量
注意事项:x只是这种结构类型的名字,而ljs才是真正的结构体
5.1.2结构成员
int float char [] * struct 都可以,一般字符串用字符数组或者字符指针
5.1.3结构成员的直接访问
使用方式:针对结构体变量 . 例如 ljs.name
((compose.sa)[4]).c) 分析一下:compose是一个结构体,访问它内部的sa,且sa是一个数组,访问它的第五个元素 [4],且这个元素存放的是一个结构体,访问它内部的c
5.1.4结构成员的间接访问
使用方式:针对指向这个结构体的指针使用。 (*pa).name,其中pa是指向结构体的指针
除了上文的使用,对于指针更多的是这种:pa->name
5.2作为函数参数的结构
方式(1)结构体 其中ljs是结构体类型,tran是ljs类型的结构体
void printf_rec(ljs tran)
{
printf(“%d”,tran.name); 打印tarn里面的name
}
方式(2)指针 其中ljs是结构体类型,tran是指向某个结构体的指针
void printf_rec(ljs *tran)
{
printf(“%d”,tran->name); 打印tarn里面的name
}
范例(1)
# include
# include
struct Student
{
int num;
char name[30];
};
void Display(struct Student su)
{
printf("%d",su.num);
}
int main ()
{
struct Student student={1,"dire"};
Display(student);
return 0;
}
范例(2)
# include
# include
struct Student
{
int num;
char name[30];
};
void Display(struct Student *su)
{
printf("%s",su->name);
}
int main ()
{
struct Student student={2,"dire"};
struct Student *pa = &student;
Display(pa);
return 0;
}
5.3联合
解释:联合所有成员引用的是内存中相同的位置,适用于不同时刻存放在相同位置的存储。
声明:
unio {
float f;
int i;
} fi;
fi.f = 1.1;// fi.i = 1;
printf(“ %d ”,fi.i); //把3.14浮点存于 fi ,然后把 fi 作为整型输出。结果报错!!
初始化:
unio {
float f;
int i;
} fi = {2.1};//这里只能先赋值给联合的第一个元素,且用花括号扩起来。
6动态内存分配
解释:一个数组所在的内存在编译时就被分配。但是也可以使用动态内存,也就是在运行时给它分配内存。为什么这样做呢?因为数组的长度其实往往在运行时才确定,所以为了避免最初设置时数组过大浪费内存,引入了动态内存。
6.1 malloc
作用:执行动态内存的分配。简单来说就是当你需要额外内存时,通过malloc函数从内存池中给你提供额外,连续字节的函数。如果内存池没有就像系统请求,如果系统没有则会返回NULL。
声明: void *malloc(size_t size);
其中size是需要分配的内存字节数。当满足分配条件后,malloc就返回一个指向分配起始位置的指针。由于这个指针目前是void *,因此可以转换指针类型。
6.2 free
作用:执行动态内存的释放。简单来说就是你用完刚刚给你分配的新内存之后,通过 free 又把它归还给内存池。
声明: void free(void *pointer);
free 的参数可以是 NULL ,也可以是malloc返回的值。
6.3 calloc
作用:分配动态内存。与malloc区别如下:(1)在返回指针之前把它初始为0.(2)根据所需元素的数量和各个元素的字节数进行计算分配。
声明: void *calloc(size_t num_elements,size_t element_size);
6.4 realloc
作用:用于修改一个原先已经分配的内存块的大小。放大内存:在原先内容的尾部添加新的内存。缩小内存:去掉原先内容的尾部。如果,原内存无法改变,readlloc会找一个新地址来满足现在要求,因此不能再使用旧指针,而是用relloc返回的新指针
声明:void realloc(void *ptr,size_t new_size);
如果realloc的第一个参数是 NULL,则它和 malloc一样
6.5动态内存分配实例
6.5.1 指针运算
本代码是想表面,通过malloc函数分配地址之后,给新地址的每个值赋为 0 ,然后输出结果,这里的结果输出使用了 pi 和 pi2 .因为 pi 随着 for 循环已经指向数组外的指针了,因此需要用减法,减到之前的地址。而 pi2 是最开始指向 pi 的指针,可以用加法从头开始输出。
#include
#include
int main()
{
int *pi;
int *pi2,i;
pi = (int *)malloc(25 *sizeof(int)); 给 pi 分配100 个字节地址
pi2=pi;//指向pi的首地址的指针 pi2
for(i=0;i<25;i+=1)
{
*pi=0;//pi指向的第一个值为0
pi++;//pi指针+1,也就是指向第二个指针的值。
printf("%d\n",*(pi2+i));//这里的 pi2 指向第一个值,因此要输出pi2 必须 +
}
pi=pi-1;//因为指针指向了26的位置,所以 -1 让它回到25.
printf("hello\n");
printf("%d\n",*(pi-20));//这里的pi指向最后面的值,所以要输出pi,必须 -
return 0;
}
6.5.2 间接访问操作
int main()
{
int *p;
p=(int *)malloc(25*sizeof(int));
for(int i=0;i<25;i++)
{
p[i]=0;
}
for(int i=0;i<25;i++)
{
printf("%d",p[i]);
}
return 0;
}
7 使用结构和指针
7.1链表
解释:在实时游戏中,为了解决游戏实时界面中未知内存出现,引入了链表,其好处在于,就像车的链条一样,第一个一定和第二个相连,通过第一个就可以找到第二个。在电脑中也是”连着的“,不过是通过指针。
节点:数据1,数据2都是一个节点
根指针:指向第一个数据的指针
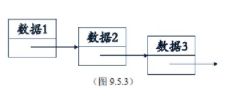
数据1中有自己的东西之外,还包括下一个数据2的指针,供我们快速找到数据2。
7.2单链表
定义:每个节点包含下一个节点的指针,最后一个节点指针为NULL。存在一个根指针,用来指向第一个数据。单链表无法反方向遍历,但可以在进入下一个节点前,保存当前节点指针。
声明:typedef struct NODE{
struct NODE *link;
int value;
}
7.2.1单链表插入
现针对一个单链表,每个格子里面存放一个整型值和指向下一个格子的指针值。通过对比格子的整型值,来判断插入的地方。插入的整型值=12,当链表值>12时,就插入当前链表的前一个位置。
(一)中间插入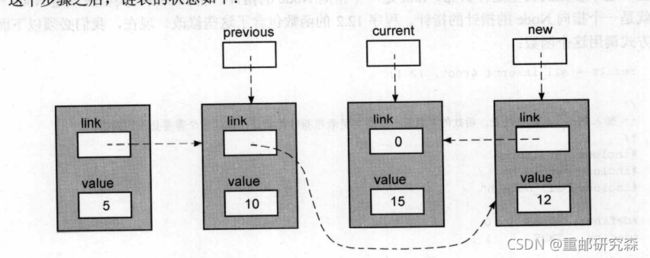
当12<15时,new=current。(new就是新格子的指向指针)。然后让previous=指向这个新格子
让15这个格子指向NULL。
(二)末尾插入
(三)起始插入
7.3双链表
双链表相当于是在单链表之上还存在了上个链表的指针。
作者发现写到这里C语言能力提升不大,因此刷题去了,拜拜拜!!!
以后会分享一些C语言经典题目分析!!!