Thrift 序列化协议浅析
动手点关注干货不迷路
背景
Thrift 是 Facebook 开源的一个高性能,轻量级 RPC 服务框架,是一套全栈式的 RPC 解决方案,包含序列化与服务通信能力,并支持跨平台/跨语言。整体架构如图所示:
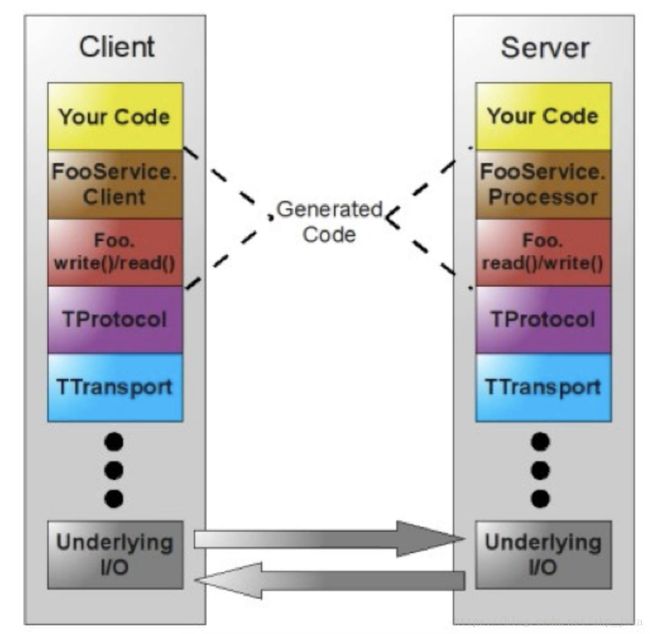
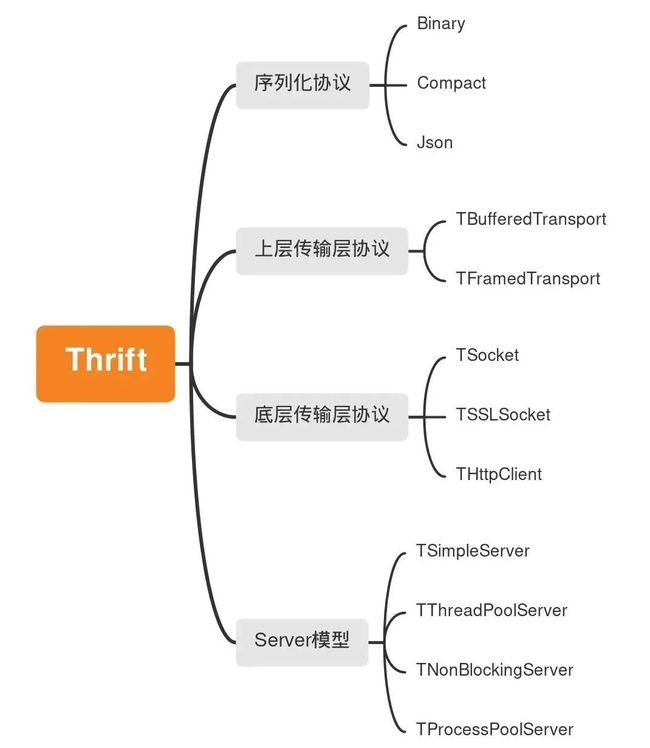
Thrift 软件栈定义清晰,各层的组件松耦合、可插拔,能够根据业务场景灵活组合,如图所示:
Thrift 本身是一个比较大的话题,这篇文章不会涉及到全部内容,只会涉及到其中的序列化协议。
协议原理
Binary 协议
消息格式
这里通过一个示例对 Binary 消息格式进行直观的展示,IDL 定义如下:
// 接口
service SupService {
SearchDepartmentByKeywordResponse SearchDepartmentByKeyword(
1: SearchDepartmentByKeywordRequest request)
}
// 请求
struct SearchDepartmentByKeywordRequest {
1: optional string Keyword
2: optional i32 Limit
3: optional i32 Offset
}
// 假设request的payload如下:
{
Keyword: "lark",
Limit: 50,
Offset: nil,
}编码简图

编码具体内容
抓包拿到编码后的字节流(转成了十进制,方便大家看)
/* 接口名长度 */ 0 0 0 25
/* 接口名 */ 83 101 97 114 99 104 68 101 112 97 114 116
109 101 110 116 66 121 75 101 121 119 111
114 100
/* 消息类型 */ 1
/* 消息序号 */ 0 0 0 1
/* keyword 字段类型 */ 11
/* keyword 字段ID*/ 0 1
/* keyword len */ 0 0 0 4
/* keyword value */ 108 97 114 107
/* limit 字段类型 */ 8
/* limit 字段ID*/ 0 2
/* limit value */ 0 0 0 50
/* 字段终止符 */ 0编码含义
消息头
msg_type:消息类型,包含四种类型
Call:客户端消息。调用远程方法,并且期待对方发送响应。
OneWay:客户端消息。调用远程方法,不期待响应。
Reply:服务端消息。正常响应。
Exception:服务端消息。异常响应。
msg_seq_id:消息序号。客户端使用消息序号来处理响应的失序到达,实现请求和响应的匹配。服务端不需要检查该序列号,也不能对序列号有任何的逻辑依赖,只需要响应的时候将其原样返回即可。
消息体
消息体分为两种编码模式:
定长类型 -> T-V 模式,即:字段类型 + 序号 + 字段值
变长类型 -> T-L-V 模式,即:字段类型 + 序号 + 字段长度 + 字段值
field_type:字段类型,包括 String、I64、Struct、Stop 等。字段类型有两个作用:
Stop 类型用于停止嵌套解析
非 Stop 类型用于 Skip(Skip 操作是跳过当前字段,会在「常见问题 - 兼容性」进行讲解)
fied_id:字段序号,解码时通过序号确定字段
len:字段长度,用于变长类型,如 String
value:字段值
数据格式
1. 定长数据类型
| 数据类型 | 类型标识(8 位) | 类型尺寸(单位:字节) |
|---|---|---|
| bool | 2 | 1 |
| byte | 3 | 1 |
| double | 4 | 8 |
| i16 | 6 | 2 |
| i32 | 8 | 4 |
| i64 | 10 | 8 |
2. 变长数据类型
| 数据类型 | 类型标识(8 位) | 类型尺寸(长度 + 值) |
|---|---|---|
| string | 11 | 4 + N |
| struct | 12 | 嵌套数据 + 一个字节停止符(0) |
| map | 13 | 1 + 1 + 4 + N*(X+Y) 【key 类型 + val 类型 + 长度 + 值】 |
| set | 14 | 1 + 4 + N 【val 类型 + 长度 + 值】 |
| list | 15 | 1 + 4 + N 【val 类型 + 长度 + 值】 |
其他协议
Compact 协议
Compact 协议是二进制压缩协议,在大部分字段的编码方式上与 Binary 协议保持一致。区别在于整数类型(包括变长类型的长度)采用了【先 zigzag 编码 ,再 varint 压缩编码】实现,最大化节省空间开销。
那么问题来了,varint 和 zigzag 是什么?
varint 编码
解决的问题:定长存储的整数类型绝对值较小时空间浪费大
据统计,RPC 通信时大部分时候传递的整数值都很小,如果使用定长存储会很浪费。
举个 ,对 i32 类型的 7 进行编码,可以说前面 3 个字节都浪费了:
00000000 00000000 00000000 00000111
解决思路:将整数类型由定长存储转为变长存储(能用 1 个字节存下就坚决不用 2 个字节)
原理并不复杂,就是将整数按 7bit 分段,每个字节的最高位作为标识位,标识后一个字节是否属于该数据。1 代表后面的字节还是属于当前数据,0 代表这是当前数据的最后一个字节。
以 i32 类型,数值 955 为例,可以看出,由原来的 4 字节压缩到了 2 字节:
binary编码: 00000000 00000000 00000011 10111011
切分: 0000 0000000 0000000 0000111 0111011
compact编码: 00000111 10111011当然,varint 编码同样存在缺陷,那就是存储大数的时候,反而会比 binary 的空间开销更大:本来 4 个字节存下的数可能需要 5 个字节,8 个字节存下的数可能需要 10 个字节。
zigzag 编码
解决的问题:绝对值较小的负数经过 varint 编码后空间开销较大 举个 ,i32 类型的负数(-11)
原码: 10000000 00000000 00000000 00001011
反码: 11111111 11111111 11111111 11110100
补码: 11111111 11111111 11111111 11110101
varint编码: 00001111 11111111 11111111 11111111 11110101显然,对于绝对值较小的负数,用 varint 编码以后前导 1 过多,难以压缩,空间开销比 binary 编码还大。
解决思路:负数转正数,从而把前导 1 转成前导 0,便于 varint 压缩
算法公式 & 步骤 & 示范:
// 算法公式
32位: (n << 1) ^ (n >> 31)
64位: (n << 1) ^ (n >> 63)
/*
* 算法步骤:
* 1. 不分正负:符号位后置,数值位前移
* 2. 对于负数:符号位不变,数值位取反
*/
// 示例
负数(-11)
补码: 11111111 11111111 11111111 11110101
符号位后置,数值位前移: 11111111 11111111 11111111 11101011
符号位不变,数值位取反(21): 00000000 00000000 00000000 00010101
正数(11)
补码: 00000000 00000000 00000000 00010101
符号位后置,数值位前移(22): 00000000 00000000 00000000 00101010【奇怪的知识】为什么取名叫 zigzag?
因为这个算法将负数编码成正奇数,正数编码成偶数。最后效果是正负数穿插向前,就像这样:
编码前 编码后
0 0
-1 1
1 2
-2 3
2 4Json 协议
Thrift 不仅支持二进制序列化协议,也支持 Json 这种文本协议
数据格式
/* bool、i8、i16、i32、i64、double、string */
"编号": {
"类型": "值"
}
// 示例
"1": {
"str": "keyword"
}
/* struct */
"编号": {
"rec": {
"成员编号": {
"成员类型": "成员值"
},
...
}
}
// 示例
"1": {
"rec": {
"1": {
"i32": 50
}
}
}
/* map */
"编号": {
"map": [
"键类型",
"值类型",
元素个数,
"键1",
"值1",
...
"键n",
"值n"
]
}
// 示例
"6": {
"map": [
"i64",
"str",
1,
666,
"mapValue"
]
}
/* List */
"编号": {
"set/lst": [
"值类型",
元素个数,
"ele1",
"ele2",
"elen"
]
}
// 示例
"2": {
"lst": [
"str",
2,
"lark","keyword"]
}case 分析
修改字段类型导致 RPC 超时
现象:A 服务访问 B 服务,业务逻辑短时间处理完,但整个请求 15s 超时,必现。
直接原因:IDL 类型被修改;并且只升级了服务端(B 服务),没升级客户端(A 服务)
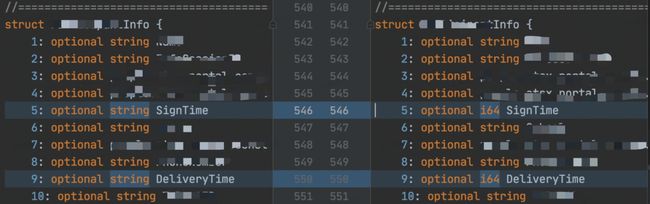
本质原因:string 是变长编码,i64 是定长编码。由于客户端没有升级,所以反序列化的时候,会把 signTime 当做 string 类型来解析。而变长编码是 T-L-V 模式,所以解析的时候会把 signTime 的低位 4 字节翻译成 string 的 length。
signTime 是时间戳,大整数,比如:1624206147902,转成二进制为:
00000000 00000000 00000001 01111010 00101010 00111011 00000001 00111110
低位 4 字节转成十进制为:378
也就是要再读 378 个字节作为 SignTime 的值,这已经超过了整个 payload 的大小,最终导致 Socket 读超时。
【注】修改类型不一定就会导致超时,如果 value 的值比较小,解析到的 length 也比较小,能够保证读完。但是错误的解析可能会导致各种预期之外的情况,包括:
乱码
空值
报错:unknown data type xxx (skip 异常)
常见问题
兼容性
增加字段
通过 skip 来跳过增加的字段,从而保证兼容性

删除字段
编译生成的解析代码是基于 field_id 的 switch-case 结构,语法结构上直接具备兼容性。
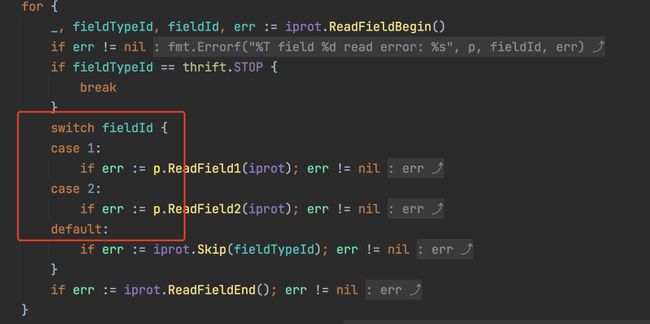
修改字段名
不破坏兼容性,因为 binary 协议不会对 name 进行编码
Exception
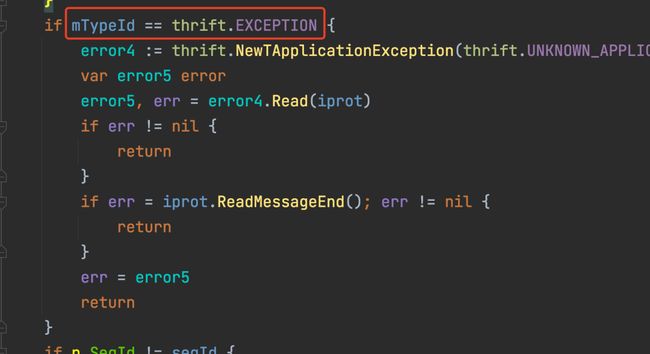
Thrift 有两种 Exception,一种是框架内置的异常,一种是 IDL 自定义的异常。
框架内置的异常包括:「方法名错误」、「消息序列号错误」、「协议错误」,这些异常由框架捕获并封装成 Exception 消息,反序列化时会转成 error 并抛给上层,逻辑如下:
另一种异常是由用户在 IDL 中自定义的,关键字是 exception,用法上跟 struct 没有太大区别。
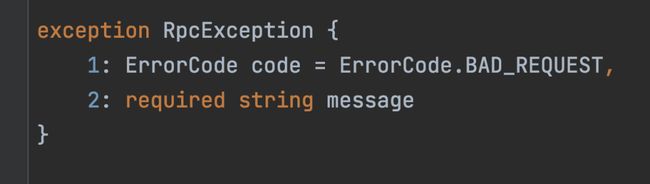
optional、require 实现原理
optional 表示字段可填,require 表示必填
字段被标识为 optional 之后:
基本类型会被编译为指针类型
序列化代码会做空值判断,如果字段为空,则不会被编码
字段被标识为 require 之后:
基本类型会被编译为非指针类型(复合类型 optional 和 require 没区别)
序列化不会做空值判断,字段一定会被编码。如果没有显式赋值,就编码默认值(默认空值,或者 IDL 显式指定的默认值)