Python数据分析(三)—— Pandas数据统计
Pandas数据统计
- 1 简单统计
- 2 groupby
- 3 pivot table
本文主要介绍Pandas中的数据统计方法,部分使用的数据集为MovieLen 1M版本(m1-1m.zip)数据集。
import numpy as np
import pandas as pd
#加载数据集
fpath = r'datasets//'
usercol = ['uid','sex','age','occupation','zip']
ratcol = ['uid','mid','rating','timestamp']
movcol = ['mid','title','genres']
users = pd.read_table(fpath+'users.dat',sep='::',header=None, names=usercol,engine='python')
ratings = pd.read_table(fpath+'ratings.dat',sep='::',header=None, names=ratcol,engine='python')
movies = pd.read_table(fpath+'movies.dat',sep='::',header=None,names=movcol,engine='python')
data = pd.merge(pd.merge(users,ratings),movies)
1 简单统计
unique计算Series中的唯一值数组,按发现的顺序返回。
value_counts返回一个Series,索引为唯一值,值为频率,按计数值降序排列。
data.age.unique()
![]()
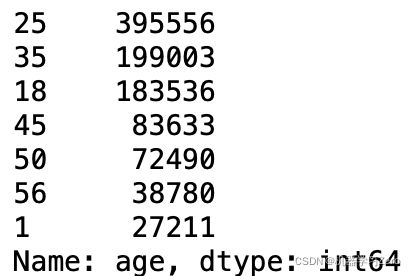
data.age.value_counts()
2 groupby
分组运算的过程被描述为split-apply-combine:数据根据提供的一个或多个键被拆分(split)为多组,拆分操作在对象的特定轴上执行的;然后将一个函数应用(apply)到各个分组并产生一个新值;最后所有函数的执行结果会被合并(combine)到最终的结果对象中。

import pandas as pd
import numpy as np
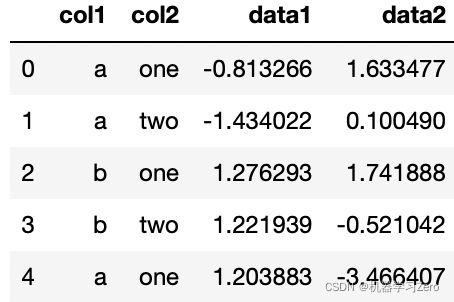
df = pd.DataFrame({'col1':['a','a','b','b','a'],
'col2':['one','two','one','two','one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
df
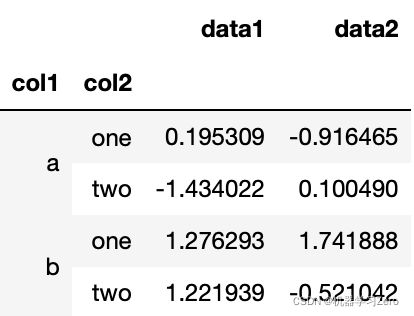
groupby方法形成一个Groupby对象,没有进行任何实际计算,只是含有一些有关分组键的中间数据,即该对象已包含接下来对各分组执行运算所需的一切信息。
grouped = df.groupby(['col1','col2'])
grouped.mean()
3 pivot table
透视表(pivot table)根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。pivot_table()函数除能为groupby提供便利外,还可以添加分项小计(margins)。
pivot_table(values,index,columns,aggfunc,fill_value)
主要参数如下:
values:数据透视表中的值index:数据透视表中的行columns:数据透视表中的列aggfunc:统计函数(应用到values上)fill_value:替换NA值
df.pivot_table(index='col1',aggfunc='mean')
#df.groupby(['col1']).mean()

df.pivot_table('data1',index='col1',aggfunc='mean')
#df.groupby(['col1']).data1.mean()

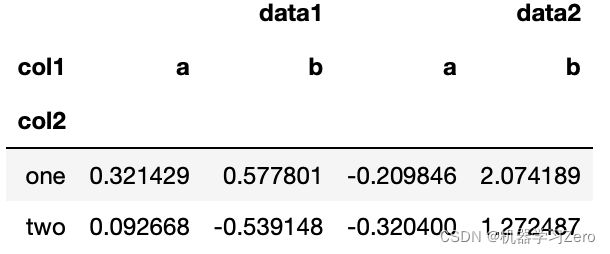
df.pivot_table(['data1','data2'],index='col2',columns='col1',aggfunc='mean')
#df.groupby(['col1','col2']).mean().unstack()