背景
Android系统模块代码的编译实在是太耗时了,即使寥寥几行代码的修改,也能让一台具有足够性能的编译服务器工作十几分钟以上(模块单编),只为编出一些几兆大小的jar和dex。
这里探究的是系统完成过一次整编后进行的模块单编,即m、mm、mmm等命令。
除此之外,一些不会更新源码、编译配置等文件的内容的操作,如touch、git操作等,会被Android系统编译工具识别为有差异,从而在编译时重新生成编译配置,重新编译并没有更新的源码、重新生成没有差异的中间文件等一系列严重耗时操作。
本文介绍关于编译过程中的几个阶段,以及这些阶段的耗时点/耗时原因,并最后给出一个覆盖一定应用场景的基于ninja的加快编译的方法(实际上是裁剪掉冗余的编译工作)。
环境
编译服务器硬件及Android信息:
- Ubuntu 18.04.4 LTS
- Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (28核56超线程)
- MemTotal: 65856428 kB (62.8GiB)
- AOSP Android 10.0
- 仅修改某个Java文件内部的boolean初始化值(true改false)
- 不修改其他任何内容,包括源码、mk、bp的情况下,使用m单编模块(在清理后,使用对比的ninja进行单编)
- 使用time计时
- 此前整个系统已经整编过一次
- 编译时不修改任何编译配置文件如Android.mk
之所以做一个代码修改量微乎其微的case,是因为要分析编译性能瓶颈,代码变更量越小的情况下,瓶颈就越明显,越有利于分析。
关键编译阶段和耗时分析
由于Makefile结构复杂、不易调试、难以扩展,因此Android决定将它替换掉。Android在7.0时引入了Soong,它将Android从Makefile的编译架构带入到了ninja的时代。
Soong包含两大模块,其中Kati负责解析Makefile并转换为.ninja,第二个模块Ninja则基于生成的.ninja完成编译。
Kati是对GNU Make的clone,并将编译后端实现切换到ninja。Kati本身不进行编译,仅生成.ninja文件提供给Ninja进行编译。
Makefile/Android.mk -> Kati -> Ninja Android.bp -> Blueprint -> Soong -> Ninja
因此在执行编译之前(即Ninja真正开动时),还有一些生成.ninja的步骤。关键编译阶段如下:
Soong的自举(Bootstrap),将Soong本身编译出来
系统代码首次编译会比较耗时,其中一个原因是Soong要全新编译它自己
遍历源码树,收集所有编译配置文件(Makefile/Android.mk/Android.bp)
- 遍历、验证非常耗时,多么强劲配置的机器都将受限于单线程效率和磁盘IO效率
- 由于Android系统各模块之间的依赖、引入,因此即使是单编模块,Soong(Kati)也不得不确认目标模块以外的路径是否需要重新跟随编译。
验证编译配置文件的合法性、有效性、时效性、是否应该加入编译,生成.ninja
- 如果没有任何更改,.ninja不需要重新生成
- 最终生成的.ninja文件很大(In my case,1GB以上),有很明显的IO性能效率问题,显然在查询效率方面也很低下
最后一步,真正执行编译,调用ninja进入多线程编译
- 由于Android加入了大量的代码编译期工作,如API权限控制检查、API列表生成等工作(比如,生成系统API保护名单、插桩工作等等),因此编译过程实际上不是完全投入到编译中
- 编译过程穿插“泛打包工作”,如生成odex、art、res资源打包。虽然不同的“泛打包”可以多线程并行进行,但是每个打包本身只能单线程进行
下面将基于模块单编(因开发环境系统全新编译场景频率较低,不予考虑),对这四个关键阶段进行性能分析。
阶段一:Soong bootstrap
在系统已经整编过一次的情况下,Soong已经完成了编译,因此其预热过程占整个编译时间的比例会比较小。
在“环境”下,修改一行Framework代码触发差异进行编译。并且使用下面的命令进行编译。
time m services framework -j57
编译实际耗时22m37s:
build completed successfully (22:37 (mm:ss)) ####
real 22m37.504s
user 110m25.656s
sys 12m28.056s
对应的分阶段耗时如下图。
- 可以看到,包括Soong bootstrap流程在内的预热耗时占比非常低,耗时约为11.6s,总耗时约为1357s,预热耗时占比为
0.8%。

- Kati和ninja,也就是上述编译关键流程的第2步和第3步,分别占了接近60%(820秒,13分钟半)和约35%(521秒,8分钟半)的耗时,合计占比接近95%的耗时。
注:这个耗时是仅小幅度修改Java代码后测试的耗时。如果修改编译配置文件如Android.mk,会有更大的耗时。
小结:看来在完成一次整编后的模块单编,包括Soong bootstrap、执行编译准备脚本、vendorsetup脚本的耗时占比很低,可以完全排除存在性能瓶颈的可能。
阶段二:Kati遍历、mk搜集与ninja生成
从上图可以看到,Kati耗时占比很大,它的任务是遍历源码树,收集所有的编译配置文件,经过验证和筛选后,将它们解析并转化为.ninja。
从性能角度来看,它的主要特点如下:
- 它要遍历源码树,收集所有mk文件(In my case,有983个mk文件)
- 解析mk文件(In my case,framework/base/Android.mk耗费了~6800ms)
- 生成并写入对应的.ninja
- 单线程
直观展示如下,它是一个单线程的、IO速度敏感、CPU不敏感的过程:
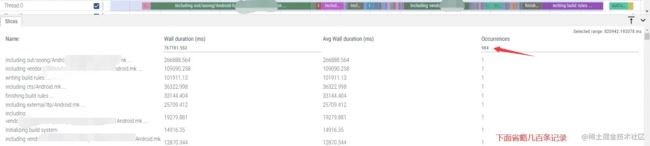
Kati串行地处理文件,此时对CPU利用率很低,对IO的压力也不高。
小结:可以确定它的性能瓶颈来源于IO速度,单纯为编译实例分配更多的CPU资源也无益于提升Kati的速度。
阶段三:Ninja编译
SoongClone了一份GNU Make,并将其改造为Kati。即使我们没有修改任何mk文件,前面Kati仍然会花费数分钟到数十分钟的工作耗时,只为了生成一份能够被Ninja或.ninja的生成工具能够识别的文件。接下来是调用Ninja真正开始编译工作。
从性能角度来看,它的主要特点如下:
- 根据目标target及依赖,读取前面生成的.ninja配置,进行编译
- 比较独立,不与前面的组件,如blueprint、kati等耦合,只要
.ninja文件中能找到target和build rule就能完成编译 - 多线程
直观展示如下,Ninja将会根据传入的并行任务数参数启动对应数量的线程进行编译。Ninja编译阶段会真正的启动多线程。但做不到一直多线程编译,因为部分阶段如部分编译目标(比如生成一个API文档)、泛打包阶段等本身无法多线程并行执行。
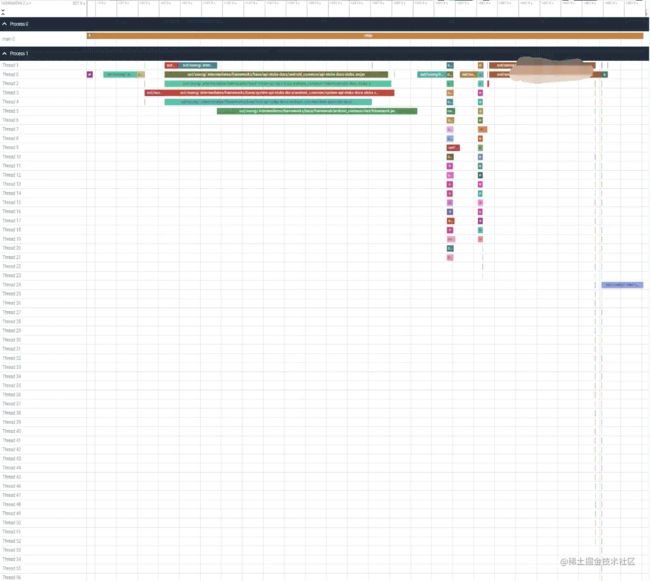
可以看到此时CPU利用率应该是可以明显上升的。但是耗时较大的阶段仅启用了几个线程,后面的阶段和最后的图形很细(时间占比很小)的阶段才用起来更多的线程。
其中,一些阶段(图中时间占比较长的几条记录)没能跑满资源的原因是这些编译目标本身不支持并行,且本次编译命令指定的目标已经全部“安排”了,不需要调动更多资源启动其他编译目标的工作。当编译整个系统时就能够跑满了。
最后一个阶段(图中最后的几列很细的记录)虽然跑满了所有线程资源,但是运行时间很短。这是因为本case进行编译分析的过程中,仅修改了一行代码来触发编译。因编译工作量很小,所以这几列很细。
小结:我们看到,Ninja编译启动比较快,这表明Ninja对.ninja文件的读取解析并不敏感。整个过程也没有看到显著的耗时点。且最后面编译量很小,表明Ninja能够确保增量编译、未更新不编译。
编译优化
本节完成点题——Android系统编译优化:使用Ninja加快编译。
根据前面分析的小结,可以总结性能瓶颈:
- Kati遍历、生成太慢,受限于IO速率
- Kati吞吐量太低,单线程
- 不论有无更新均重新解析Makefile
利用Ninja进行编译优化的思路是,大多数场景,可以舍弃Kati的工作,仅执行Ninja的工作,以节省掉60%以上的时间。其核心思路,也是制约条件,即在不影响编译正确性的前提下,舍弃不必要的Kati编译工作。
- 使用
Ninja直接基于.ninja文件进行编译来改善耗时:
结合前面的分析,容易想到,如果目标被构建前,能够确保mk文件没有更新也不需要重新生成一长串的最终编译目标(即.ninja),那么make命令带来的Soong bootstrap、Kati等工作完全是重复的冗余的——这个性质Soong和Kati自己识别不出来,它们会重复工作一次。
既重新生成.ninja是冗余的,那么直接命令编译系统根据指定的.ninja进行编译显然会节省大量的工作耗时。ninja命令is the key:
使用源码中自带的ninja:
./prebuilts/build-tools/linux-x86/bin/ninja --version 1.8.2.git
对比最上面列出的make命令的编译,这里用ninja编译同样的目标:
time ./prebuilts/build-tools/linux-x86/bin/ninja -j 57 -v -f out/combined-full_xxxxxx.ninja services framework
ninja自己识别出来CPU平台后,默认使用-j58。这里为了对比上面的m命令,使用-j57编译
-f参数指定.ninja文件。它是编译配置文件,在Android中由Kati生成。这里文件名用'x'替换修改
编译结果,对比上面的m,有三倍的提升:
real 7m57.835s
user 97m12.564s
sys 8m31.756s
编译耗时为8分半,仅make的三分之一。As we can see,当能够确保编译配置没有更新,变更仅存在于源码范围时,使用Ninja直接编译,跳过Kati可以取得很显著的提升。
直接使用ninja:
./prebuilts/build-tools/linux-x86/bin/ninja -j $MAKE_JOBS -v -f out/combined-*.ninja
对比汇总
这里找了一个其他项目的编译Demo,该Demo的特点是本身代码较简单,编译配置也较简单,整体编译工作较少,通过make编译的大部分耗时来自soong、make等工具自身的消耗,而真正执行编译的ninja耗时占比极其低。由于ninja本身跳过了soong,因此可以跳过这一无用的繁琐的耗时。可以看到下面,ninja编译iperf仅花费10秒。这个时间如果给soong来编译,预热都不够。
$ -> f_ninja_msf iperf Run ninja with out/combined-full_xxxxxx.ninja to build iperf. ====== ====== ====== Ninja: ./prebuilts/build-tools/linux-x86/bin/[email protected] Ninja: build with out/combined-full_xxxxxx.ninja Ninja: build targets iperf Ninja: j72 ====== ====== ====== time /usr/bin/time ./prebuilts/build-tools/linux-x86/bin/ninja -j 72 -f out/combined-full_xxxxxx.ninja iperf [24/24] Install: out/target/product/xxxxxx/system/bin/iperf 53.62user 11.09system 0:10.17elapsed 636%CPU (0avgtext+0avgdata 5696772maxresident) 4793472inputs+5992outputs (4713major+897026minor)pagefaults 0swaps real 0m10.174s user 0m53.624s sys 0m11.096s
下面给出soong编译的恐怖耗时:
$ -> rm out/target/product/xxxxxx/system/bin/iperf $ -> time m iperf -j72 ... [100% 993/993] Install: out/target/product/xxxxxx/system/bin/iperf #### build completed successfully (14:45 (mm:ss)) #### real 14m45.164s user 23m40.616s sys 11m46.248s
As we can see,m和ninja一个是10+ minutes,一个是10+ seconds,比例是88.5倍。
以上就是Android系统优化Ninja加快编译的详细内容,更多关于Android Ninja加快编译的资料请关注脚本之家其它相关文章!