JDBC增删改查(使用Java对数据库操作)
使用JDBC进行增删改查
前一天给大家分享了一些基本的JDBC知识,今天给大家做了一分最详尽的增删改查总结。Let’s go!
复习一下MySQL的语法
| 作用 | 关键字 | 举例 | 是否需要返回数据 |
|---|---|---|---|
| 添加(增) | INSERT | INSERT INTO customers(id)VALUES(9) | 显示受到影响,不返回值 |
| 删除(删) | DELETE | DELETE FROM customers WHERE id=9 | 同上 |
| 修改(改) | UPDATE | update customers set name = ‘周星驰’ where id = 9 | 同上 |
| 查询(查) | SELECT | SELECT * FROM customers | 有结果返回 |
对上述表进行分析,发现对表的添加、删除以及修改都是不需要返回值的,按照长期对于Java代码的理解,那么,我们就像代码中不需要返回值的一律为void方法,我们可以试着把它归为一类,而查询是需要由返回值的,我们就只能将其单独划分一类。
添加、删除以及修改
一、我们先来分析一下我们如果需要对一个数据库的表进行操作,需要那几步叭
- ①对数据库进行连接(昨天讲过了)
- ②写sql语句(因为这个肯定也是需要自己编写sql语句进行操作的)
- ③执行sql语句
- ④关闭资源
二、以添加为例子先看看
/**添加*/
/**因为涉及到关闭资源,这里就不采用throw来抛出异常,采用的是try……catch的形式*/
public void connection(){
PreparedStatement ps=null;
Connection conn =null;
//读取配置文件中的4个基本信息
try {
InputStream inputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(inputStream);
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
//加载区间
Class.forName(driverClass);
//获取连接
conn = DriverManager.getConnection(url,user,password);
//4预编译sql语句,返回PreparedStatement的实例
String sql = "insert into customers(name,email,birth)values(?,?,?)";
ps = conn.prepareStatement(sql);
//填充占位符
ps.setString(1,"小阿七");
ps.setString(2,"[email protected]");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
java.util.Date date = sdf.parse("1996-09-08");
ps.setDate(3,new Date(date.getTime()));
//执行操作
//execute()执行sql语句,返回的是一个布尔值
ps.execute();
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
//释放资源
try {
if(conn!=null && ps!=null) {
conn.close();
ps.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
结果展示
- 添加前的数据

- 添加后的数据

分析一下,上面的的代码,我们不管做哪一个操作,我们都需要的是连接,执行还有释放资源,仅仅只是语句和占位符不一样,这里我们完全可以把她的 代码单独用一个方法包装起来。下面我们试着取写一个通用的方法。
将代码升级到通用的情况
jdbc.properties文件
user=你的用户名
password=用户名对应的密码
url=连接数据库的地址
driverClass=com.mysql.jdbc.Driver
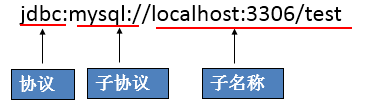
注:文件里面的配置文件尽量不要使用空格,否则会出现报错嫌疑!!!
user=root
password=123456
url=jdbc:mysql://localhost:3306/test
driverClass=com.mysql.jdbc.Driver
通用的工具类
看下面的代码想一想为什么本人会在设置连接时选择的是用throws关键字抛出异常,而在关闭资源时选择用try……catch来处理异常呢?
/**设置连接*/
public static Connection getConnection() throws Exception{
//读取配置文件中的4个基本信息
InputStream inputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("jdbc.properties");
Properties pros = new Properties();
pros.load(inputStream);
String user = pros.getProperty("user");
String password = pros.getProperty("password");
String url = pros.getProperty("url");
String driverClass = pros.getProperty("driverClass");
//加载区间
Class.forName(driverClass);
//获取连接
Connection conn = DriverManager.getConnection(url,user,password);
return conn;
}
/**关闭资源*/
public static void closeResoure (Connection conn,PreparedStatement ps){
try {
if(ps!=null) {
ps.close();
}
} catch (SQLException throwables) {
//
throwables.printStackTrace();
}
try {
if(conn!=null) {
conn.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
/**重载一下关闭流,方便查询操作时使用*/
public static void closeResoure (Connection conn,PreparedStatement ps,ResultSet rs) {
try {
if(ps!=null) {
ps.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if(conn!=null) {
conn.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
try {
if(rs!=null) {
rs.close();
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
原因:在连接时也可以使用try……catch抛出,但是为了便捷不使用,而在关闭资源时,是因为使用try-with-resource时,如果对外部资源的处理和对外部资源的关闭均遭遇了异常,“关闭异常”将被抑制,“处理异常”将被抛出,但“关闭异常”并没有丢失,而是存放在“处理异常”的被抑制的异常列表中。所以采用try……catch可以将关闭异常也抛出。
通用的增删改
因为通用,所以对应的SQL语句也会不同,所以我们需要传入不同的数据参数,所以需要利用一个字符串,将我们的SQL语句传入,因为我们采用的是PreparedStatement或者Statement来进行语句的编译,所以还需要填充占位符来进行传入。
/**通用的增删改操作*/
public void update(String sql,Object ...args) throws Exception {
Connection conn = null;
PreparedStatement ps = null;
try {
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
//填充占位符
for (int i = 0; i < args.length; i++) {
ps.setObject(i + 1,args[ i ]);
}
//执行
ps.execute();
} catch (Exception e) {
System.out.println(e.getMessage());
}
JDBCUtils.closeResoure(conn,ps);
}
测试一下
有人会发现我这串代码其实是有一点小瑕疵的吗?要是你发现了,请偷偷自己改正,不用说出来,留给大家自己想想瑕疵在何处哟。
@Test
/**修改*/
public void testUpdate() throws Exception{
Connection conn = JDBCUtils.getConnection();
String sql = "update customers set name = ? where id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
//填充占位符
ps.setObject(1,"莫扎特");
ps.setObject(2,18);
//大家觉得这里需要ps.execute();吗?
//其实可以要起,方便理解,但是你不要也问题不大,自己去探索这个小秘密呢
JDBCUtils.closeResoure(conn,ps);
}
这里就写修改了,因为修改执行忘记截图了,反正大家的数据库又不一样,需要使用的自行修改一下jdbc.properties文件路径,还有sql语句哟。
查询操作
一、同上我们一起来分析一下 查询操作又可以分为几步呢?
- ①对数据库进行连接(昨天讲过了)
- ②写sql语句(因为这个肯定也是需要自己编写sql语句进行操作的)
- ③执行sql语句并得到返回值这里需要使用这个executeQuery()方法,因为它具有返回结果集的作用
- ④对得到的结果集进行遍历输出处理
- ⑤关闭资源
二、这里就直接先上分析
因为我们返回的结果肯定是对 某一个表中的元素值进行返回,所以我们定义一个对象来进行保存我们结果值,顺便可以直接重写tostring方法来进行遍历打印!nice!干!
普通版查询
/**返回的一条记录*/
public <T> T getInstance(Class<T> tClass, String sql,Object...args){
Connection conn =null;
ResultSet rs =null;
PreparedStatement ps = null;
try{
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i+1,args[i]);
}
//执行获取结果集
rs = ps.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
//获取列数
int columnCount = rsmd.getColumnCount();
if(rs.next()){
T t = tClass.newInstance();
for (int i = 0; i < columnCount; i++) {
//获取列值
Object columnValue = rs.getObject(i + 1);
//获取列的列名,不推荐使用
//不采用列名时,不符合sql语句特点,因为有时候我们需要对数据取别名嘛
// String columnName = rsmd.getColumnName(i + 1);
//获取列的别名,推荐使用,因为当我们未采用别名时也会获取到本身得名字
String columnLable = rsmd.getColumnLabel(i + 1);
//利用反射为每一个对象进行赋值操作赋值
Field field = tClass.getDeclaredField(columnLable);
//不知道是否为私有变量
field.setAccessible(true);
field.set(t,columnValue);
}
return t;
}
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
try {
JDBCUtils.closeResoure(conn,ps,rs);
}catch (Exception e){
System.out.println(e.getMessage());
}
}
return null;
}
分析,因为这样子我们的结果只能一条语句一样的输出,于是想到了使用集合来保存每一条数据,但是集合类型不一致,所以得使用泛型定义。
升级改进版
/**返回多条记录*/
public List getInstanceList(Class tClass,String sql,Object...args){
Connection conn =null;
ResultSet rs =null;
PreparedStatement ps = null;
//创建集合对象
ArrayList list = new ArrayList<>();
try{
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
for (int i = 0; i < args.length; i++) {
ps.setObject(i+1,args[i]);
}
//执行获取结果集
rs = ps.executeQuery();
ResultSetMetaData rsmd = rs.getMetaData();
//获取列数
int columnCount = rsmd.getColumnCount();
while (rs.next()){
T t = tClass.newInstance();
for (int i = 0; i < columnCount; i++) {
//获取列值
Object columnValue = rs.getObject(i + 1);
//获取列的列名,不推荐使用
//String columnName = rsmd.getColumnName(i + 1);
//获取列的别名
String columnLable = rsmd.getColumnLabel(i + 1);
//利用反射为每一个对象进行赋值操作赋值
Field field = tClass.getDeclaredField(columnLable);
field.setAccessible(true);
field.set(t,columnValue);
}
list.add(t);
}
return list;
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
try {
JDBCUtils.closeResoure(conn,ps,rs);
}catch (Exception e){
System.out.println(e.getMessage());
}
}
return null;
}
测试一下升级版查询
@Test
public void testGetInstanceList(){
String sql = "select id,name from Customers where id < ?";
List<Customer> list = getInstanceList(Customer.class,sql,12);
list.forEach(System.out::println);
}
System.out::println是我偶然发现的,我的猜测来源如下:
List list = Arrays.asList("AA", "BB");
//第一种
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//第二种
for (String s : list) {
System.out.println(s);
}
//第三种 lambda 表达式
list.forEach(s-> System.out.println(s));
Blob数据类型
你以为结束了吗?不?难道你的数据库就保存一些简单得东西吗?就存储一些类似于记事本的东西吗?你乐意,我不行,毕竟我还得给自己的数据保存下来,云端太贵,自己加密,手机坏了咋办,上传数据库,嗯需要直接拷走!nice!
Blob类型
- MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据。
- 插入BLOB类型的数据必须使用PreparedStatement,因为BLOB类型的数据无法使用字符串拼接写的。
- MySQL的四种BLOB类型(除了在存储的最大信息量上不同外,他们是等同的)
| 类型 | 大小(单元:字节) |
|---|---|
| TinyBlob | 最大 255 |
| Blob | 最大 65K |
| MediumBlob | 最大 16M |
| LongBlob | 最大 4G |
- 实际使用中根据需要存入的数据大小定义不同的BLOB类型。
- 需要注意的是:如果存储的文件过大,数据库的性能会下降。
- 如果在指定了相关的Blob类型以后,还报错:xxx too large,那么在mysql的安装目录下,找my.ini文件加上如下的配置参数: max_allowed_packet=16M。同时注意:修改了my.ini文件之后,需要重新启动mysql服务。
Blob操作
因为删除数据我们基本上就可以直接用正常的数据删除就可以了,因为删除时肯定一整条数据就没了呀,所以我们主要是涉及到数据的上传、修改和删除操作。下面的代码没有去写通用的操作,如果有需要的可以自行去理解,可以验证你上面的代码是否了。没有结果展示,不是没结果,而是博主觉得没有必要放这样子没有意义的结果。因为看结果反正也是在数据库里面去查看的。下面对于数据流有不懂的小伙伴可以看我io流的博客,有详解。
- 添加
/**添加*/
@Test
public void test1(){
Connection conn =null;
PreparedStatement ps =null;
try {
conn = JDBCUtils.getConnection();
String sql = "insert into customers(name,email,birth,photo)values(?,?,?,?)";
ps = conn.prepareStatement(sql);
//name
ps.setString(1, "pier");
//email
ps.setString(2, "[email protected]");
//日期
ps.setDate(3, new Date(new java.util.Date().getTime()));
//使用数据流的方式对数据上传
FileInputStream stream = new FileInputStream(new File("src/com/File/359e19687b3ad3aa908919095148cf8d.gif"));
ps.setBlob(4,stream);
//没有数据返回所以还是使用execute()方法
ps.execute();
stream.close();
} catch (Exception e) {
e.printStackTrace();
}finally {
try{
JDBCUtils.closeResoure(conn,ps);
}catch (Exception e){
System.out.println(e.getMessage());
}
}
}
- 修改
/**修改*/
@Test
public void test2(){
Connection conn =null;
PreparedStatement ps =null;
try {
conn = JDBCUtils.getConnection();
String sql = "update customers set photo = ? where id = ?";
ps = conn.prepareStatement(sql);
// 填充占位符
// 操作Blob类型的变量
FileInputStream fis = new FileInputStream("src/com/File/微信图片扭头.jpg");
ps.setBlob(1, fis);
ps.setInt(2, 6);
ps.execute();
fis.close();
}catch (Exception e){
System.out.println(e.getMessage());
}finally {
try {
JDBCUtils.closeResoure(conn,ps);
}catch (Exception e){
System.out.println(e.getMessage());
}
}
}
- 查看
/**读取Blob文件采用流的方式读取下载**/
@Test
public void aVoid() {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
String sql = "SELECT id, name, email, birth, photo FROM customers WHERE id = ?";
conn = JDBCUtils.getConnection();
ps = conn.prepareStatement(sql);
ps.setInt(1,6);
//这里有返回值,所以使用executeQuery方法,获取结果
rs = ps.executeQuery();
if ( rs.next() ) {
int id = rs.getInt("id");
String email = rs.getString("email");
String name = rs.getString("name");
Date birth = rs.getDate("birth");
Customer cust = new Customer(id,name,email,birth);
System.out.println(cust);
//读取Blob类型的字段保存在本地
Blob photo = rs.getBlob("photo");
InputStream is = photo.getBinaryStream();
OutputStream os = new FileOutputStream("copy.jpg");
byte[] buffer = new byte[ 1024 ];
int len = 0;
while ((len = is.read(buffer)) != -1) {
os.write(buffer,0,len);
}
JDBCUtils.closeResoure(conn,ps,rs);
if ( is != null ) {
is.close();
}
if ( os != null ) {
os.close();
}
}
}catch (Exception e){
System.out.println(e.getMessage());
}
}
批量插入
有人说,博主!博主!我学会了基本的增删改了,可以下课了嘛?

我问一个问题,假如说我要是一下子需要插入两万条数据怎么办呢?
啊!这。
是不是懵圈了,继续叭!接下来我们一起看看批量插入。
博主博主,那待会是不是还有批量删除批量修改呀?
你!嗯!真是个大聪明。 批量操作Update、delete本身就具有批量操作的效果insert此时批量操作就主要指的是批量插入。
嗯,那我们应该有两种思路叭,Statement和PrepareStatement,但是你之前提过PrepareStatement效率更高,应该是采用它来写叭。
既然你都提了,我们就先来看看Statement的代码,看看为什么叭?
- 批量执行SQL语句
当需要成批插入或者更新记录时,可以采用Java的批量更新机制,这一机制允许多条语句一次性提交给数据库批量处理。通常情况下比单独提交处理更有效率
JDBC的批量处理语句包括下面三个方法:
- addBatch(String):添加需要批量处理的SQL语句或是参数;
- executeBatch():执行批量处理语句;
- clearBatch():清空缓存的数据
通常我们会遇到两种批量执行SQL语句的情况:
-
多条SQL语句的批量处理;
-
一个SQL语句的批量传参;
-
Statement
* 方式一:Statement**/
@Test
public void InsertTest1() throws Exception{
long start = System.currentTimeMillis();
//使用statement
Connection conn = null;
conn = JDBCUtils.getConnection();
Statement st = conn.createStatement();
for (int i = 0; i < 20000; i++) {
String sql = "insert into goods(name)values('name_"+"')";
st.execute(sql);
}
conn.close();
st.close();
long end = System.currentTimeMillis();
//结束时间
//两次测试耗时时间
//①27297ms
//②29062ms
System.out.println(end-start+"ms");
}
- PrepareStatement
@Test
public void testInsert1() throws Exception{
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for (int i = 0; i < 20000; i++) {
ps.setObject(1,"name_"+i);
ps.execute();
}
conn.close();
ps.close();
long end = System.currentTimeMillis();
//结束时间
//两次测试耗时时间
//①28991ms
//②27088ms
System.out.println(end-start+"ms");
}
这个代码的比较可能看不出来差距,但是这里面的差距,还算是有的
PreparedStatement 能最大可能提高性能:
- DBServer会对预编译语句提供性能优化。因为预编译语句有可能被重复调用,所以语句在被DBServer的编译器编译后的执行代码被缓存下来,那么下次调用时只要是相同的预编译语句就不需要编译,只要将参数直接传入编译过的语句执行代码中就会得到执行。
- 在statement语句中,即使是相同操作但因为数据内容不一样,所以整个语句本身不能匹配,没有缓存语句的意义.事实是没有数据库会对普通语句编译后的执行代码缓存。这样每执行一次都要对传入的语句编译一次。
- (语法检查,语义检查,翻译成二进制命令,缓存)
将其升级
/*
* 修改1: 使用 addBatch() / executeBatch() / clearBatch()
* 修改2:mysql服务器默认是关闭批处理的,我们需要通过一个参数,让mysql开启批处理的支持。
* ?rewriteBatchedStatements=true 写在配置文件的url后面
* 修改3:使用更新的mysql 驱动:mysql-connector-java-5.1.37-bin.jar
*
*/
@Test
public void testInsert1() throws Exception{
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 1000000;i++){
ps.setString(1, "name_" + i);
//1.“攒”sql
ps.addBatch();
if(i % 500 == 0){
//2.执行
ps.executeBatch();
//3.清空
ps.clearBatch();
}
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));//20000条:625 //1000000条:14733
JDBCUtils.closeResource(conn, ps);
}
最终理解版
/*
* 层次四:在层次三的基础上操作
* 使用Connection 的 setAutoCommit(false) / commit()
*/
@Test
public void testInsert2() throws Exception{
long start = System.currentTimeMillis();
Connection conn = JDBCUtils.getConnection();
//1.设置为不自动提交数据
conn.setAutoCommit(false);
String sql = "insert into goods(name)values(?)";
PreparedStatement ps = conn.prepareStatement(sql);
for(int i = 1;i <= 1000000;i++){
ps.setString(1, "name_" + i);
//1.“攒”sql
ps.addBatch();
if(i % 500 == 0){
//2.执行
ps.executeBatch();
//3.清空
ps.clearBatch();
}
}
//2.提交数据
conn.commit();
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));//1000000条:4978
JDBCUtils.closeResource(conn, ps);
}
终于搞定利用Java对数据进行完整的增删改查了,接下来,开始干它!毕竟我们还知道数据库可不仅仅是增删改查,但是基本的数据我们不会有问题了叭!
下课
