什么是JSOUP
JSOUP 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 官网
jsoup实现了WHATWG HTML5规范,并将 HTML 解析为与现代浏览器相同的 DOM。
- 从 URL、文件或字符串中抓取和解析HTML
- 使用 DOM 遍历或 CSS 选择器查找和提取数据
- 操作HTML 元素、属性和文本
- 根据安全列表清理用户提交的内容,以防止XSS攻击
- 输出整洁的 HTML
什么是OkHttp
一般在java平台上,我们会使用apache httpclient作为http客户端,用于发送 http 请求,并对响应进行处理。比如可以使用http客户端与第三方服务(如sso服务)进行集成,当然还可以爬取网上的数据等。okhttp与httpclient类似,也是一个http客户端,提供了对 http/2 和 spdy 的支持,并提供了连接池,gzip 压缩和 http 响应缓存功能;
okhttp是目前非常火的网络库,它有以下特性:
1.支持http/2,允许所有同一个主机地址的请求共享同一个socket连接
2.连接池减少请求延时
3.透明的gzip压缩减少响应数据的大小
4.缓存响应内容,避免一些完全重复的请求
OkHttp教程
爬虫需要掌握的技术
- JSOUP
- OKHTTP
- 前端知识
- http和https
- 数据存储(Json、XML ,txt、html, CSV ,Excel , ES ,mysql,redis…)
- 数据分析
- JavaScript语言
- 抓包工具fiddler,Wireshark
- 数据清洗
- 正则表达式
- 文件读写
- 多线程
根据情况可能还不止上面这些,但是会了上面这些技术那么可以说爬虫算是入门
需要的依赖
org.jsoup
jsoup
1.11.3
com.squareup.okhttp3
okhttp
3.10.0
JSON入门Demo
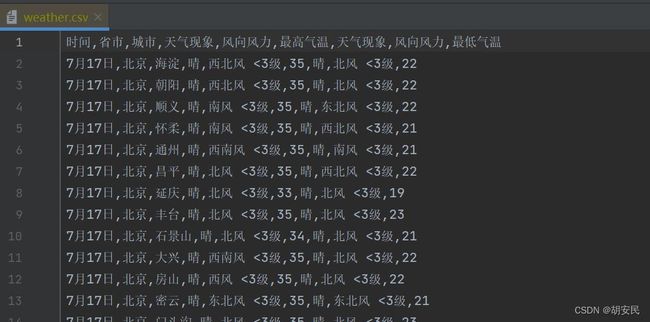
爬取华北地区,所有省市,一个星期全部的天气

按下f12,就就能查看html的结构进行分析具体该怎么爬,然后找到对应的标签,之后根据标签的位置写出css选择器
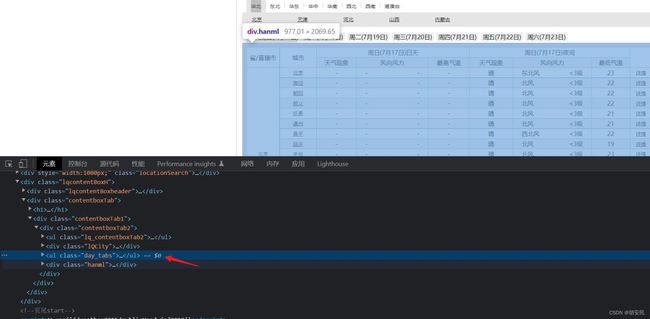
具体详情代码如下:
//拿到网页的xml
String doc = OkHttpUtils.builder()
.url("http://www.weather.com.cn/textFC/hb.shtml")
.get()
.sync();
//时间,省市,城市,天气现象
StringBuilder stringBuilder0=new StringBuilder();
//标题
StringBuilder stringBuilder = new StringBuilder("时间,省市,城市,天气现象,风向风力,最高气温,天气现象,风向风力,最低气温");
stringBuilder0.append(stringBuilder).append("\n");
Document document = Jsoup.parse(doc);//将页面转换为Document
//使用css 选择器
Elements selecttop = document.select(".day_tabs li");
//拿到数据列表
Elements select = document.select(".conMidtab");
for (int i1 = 0; i1 < selecttop.size(); i1++) {
Element element = selecttop.get(i1);
String text = element.text();
//进行数据清洗,取出时间
String time = PatternCommon.cutPatternStr(text, "[\\u4e00-\\u9fa5]*\\((\\S*)\\)", 1).get(1);
//取和实际对应的列表
Element element1 = select.get(i1);
Elements midtab = element1.select(".conMidtab2");
for (int i = 0; i < midtab.size(); i++) {
StringBuilder stringBuilder1 = new StringBuilder();
//时间
stringBuilder1.append(time).append(",");
Element element2 = midtab.get(i);
//拿到所有的行
Elements trs = element2.select("table tr");
//拿到省市
Elements select2 = trs.select(".rowspan");
stringBuilder1.append(select2.text()).append(",");
//跳过前3行从第4行开始读取
for (int i2 = 3; i2 < trs.size()-1; i2++) {
StringBuilder stringBuilder2 = new StringBuilder();
Element element3 = trs.get(i2);
//拿到行下所有列 城市,天气现象,风向风力,最高气温,天气现象,风向风力,最低气温
Elements td = element3.select("td");
for (int i3 = 0; i3 < td.size(); i3++) {
Element element4 = td.get(i3);
if(i3 == td.size()-2){
//最后一个不需要逗号
stringBuilder2.append(element4.text());
break;
}
stringBuilder2.append(element4.text()).append(",");
}
StringBuilder stringBuilder3 = new StringBuilder();
stringBuilder3.append(stringBuilder1).append(stringBuilder2);
stringBuilder0.append(stringBuilder3).append("\n");
}
}
}
//将内容按行写入到csv文件中
String absoluteFilePathAndCreate = ResourceFileUtil.getAbsoluteFileOrDirPathAndCreate("/weather.csv");
ReadWriteFileUtils.writeStrCover(new File(absoluteFilePathAndCreate),stringBuilder0.toString());

JSOUP常用方法
注意: 下面的参数名称query和cssQuery 就是css选择器
Jsoup:
- Document Jsoup.parse(str); 将字符串HTML转换为Document
- Connection connect(String url) 创建到URL的新连接。用于获取和解析HTML页面
- Document parse(File in, “UTF-8”) 将文件内容解析为HTML。
- Document parse(InputStream in, “UTF-8”, “”) 读取输入流,并将其解析为HTML。
Document :
- Elements select(css) 使用css选择器从document中查询指定元素 ,返回Elements类型
- String title() 获取文档标题元素的字符串内容。
- Element head() 文档头元素的访问者
- Element body() 文档主体元素的访问者。
Elements:
- Elements select(String query) 在此元素列表中查找匹配的元素。
- Element get(int index) 返回此列表中指定位置的元素
- String text() 获取元素的value
- boolean hasText() 判断是否有内容
- List
eachText() 获取每个匹配元素的文本内容 - String html() 获取所有匹配元素的组合内部HTML
- boolean is(String query) 测试是否有匹配的元素如果有则为true。
- Elements next() 获取此列表中每个元素的下一个同级元素
- Elements next(String query) 获取此列表中每个元素的下一个同级元素,并通过查询进行筛选。
- Elements nextAll() 获取此列表中每个元素的以下所有元素同级。
- Elements nextAll(String query) 获取此列表中每个元素的以下所有元素同级,并通过查询进行筛选。
- Elements prev() 获取此列表中每个元素的前一个元素同级。
- Elements prev(String query) 获取此列表中每个元素的前一个元素同级,并通过查询进行筛选。
- Elements prevAll() 获取此列表中每个元素之前的所有同级元素。
- Elements prevAll(String query) 获取此列表中每个元素之前的所有同级元素,并通过查询进行筛选。
- Elements parents() 获取匹配元素的所有父元素和祖先元素。
- Element first() 获取第一个匹配的元素。
- Element last() 获取最后匹配的元素
- List
forms() 从所选元素(如果有)中获取FormElement表单 - Elements filter(NodeFilter nodeFilter) 对每个选定元素执行深度优先过滤 (可以控制具体怎么遍历)
- Elements traverse(NodeVisitor nodeVisitor) 对每个选定元素执行深度优先遍历 (一直遍历到结束)
Element:
- Elements parents() 获取此元素的父元素和祖先元素,直到文档根。
- Element parent() 获取父元素
- String tagName() 获取此元素的标记名称
- boolean isBlock() 测试此元素是否为块级元素
- String id() 获取此元素的id属性。
- Attributes attributes() 获取元素上所有属性
- Element child(int index) 通过该元素的基于0的索引号获取该元素的子元素。
- Elements children() 获取此元素的子元素列表
- List
textNodes() 获取此元素的子文本节点 - Elements select(String cssQuery) 查找与选择器CSS查询匹配的元素
- Element selectFirst(String cssQuery) 查找与选择器CSS查询匹配的第一个元素
- boolean is(String cssQuery) 检查此元素是否与给定的选择器CSS查询匹配。
- Element nextElementSibling() 获取此元素的下一个同级元素
- Elements siblingElements() 获取兄弟元素。如果元素没有同级元素 则返回空列表
- String cssSelector() 获取将唯一选择此元素的CSS选择器。(可用于检索选择器中元素的CSS路径)
- Element previousElementSibling() 获取此元素的上一个同级元素
- Element firstElementSibling() 获取此元素的第一个同级元素
- int elementSiblingIndex() 在其元素同级列表中获取此元素的列表索引。 如果这是第一个同级元素,则返回0。
- Element lastElementSibling() 获取此元素的最后一个同级元素
- Elements getElementsByTag(String tagName) 查找具有指定标签名的元素,包括此元素下的元素并递归查找。
- Element getElementById(String id) 按ID查找元素,包括或在此元素下
- Elements getElementsByClass(String className) 查找具有此类的元素,包括或在该元素下。不区分大小写
- Elements getElementsByAttribute(String key) 查找具有命名属性集的元素。不区分大小写。
- Elements getElementsByAttributeStarting(String keyPrefix) 查找属性名称以提供的前缀开头的元素。
- Elements getElementsByAttributeValue(String key, String value) 查找具有具有特定值的属性的元素。不区分大小写。
- Elements getElementsByAttributeValueNot(String key, String value) 查找没有此属性=值的元素。不区分大小写。
- Elements getElementsByAttributeValueStarting(String key, String valuePrefix) 查找属性以值前缀开头的元素。不区分大小写。
- Elements getElementsByAttributeValueEnding(String key, String valueSuffix) 查找属性以值后缀结尾的元素。不区分大小写。
- Elements getElementsByAttributeValueContaining(String key, String match) 查找具有其值包含匹配字符串的属性的元素。不区分大小写。
- Elements getElementsByAttributeValueMatching(String key, Pattern pattern) 查找具有值与提供的正则表达式匹配的属性的元素。
- Elements getElementsByAttributeValueMatching(String key, String regex) 查找具有值与提供的正则表达式匹配的属性的元素。
- Elements getElementsByIndexLessThan(int index) 查找同级索引小于提供的索引的元素。
- Elements getElementsByIndexGreaterThan(int index) 查找同级索引大于提供的索引的元素。
- Elements getElementsByIndexEquals(int index) 查找同级索引等于提供的索引的元素
- Elements getElementsContainingText(String searchText) 查找包含指定字符串的元素。文本可以直接出现在元素中,也可以出现在其任何子元素中。(在元素的文本中查找)
- Elements getElementsContainingOwnText(String searchText) 查找直接包含指定字符串的元素。搜索不区分大小写。文本必须直接出现在元素中,而不是其任何子体中 (在元素自己的文本中查找)
- Elements getElementsMatchingText(Pattern pattern) 查找其文本与提供的正则表达式匹配的元素
- Elements getElementsMatchingText(String regex) 查找其文本与提供的正则表达式匹配的元素
- Elements getElementsMatchingOwnText(Pattern pattern) 查找其自身文本与提供的正则表达式匹配的元素。
- Elements getElementsMatchingOwnText(String regex) 查找其自身文本与提供的正则表达式匹配的元素。
- Elements getAllElements() 查找此元素下的所有元素(包括self和children的子元素)
- String text() 获取此元素及其所有子元素的组合文本。空白被规范化和修剪。
- String wholeText() 获取该元素所有子元素的(未编码)文本,包括原始元素中存在的任何换行符和空格。
- String ownText() 获取仅由该元素拥有的文本;无法获取所有子级的组合文本。
- boolean hasText() 测试这个元素是否有任何文本内容(不仅仅是空白)。 如果元素具有非空白文本内容,则为true。
- String data() 获取此元素的组合数据。例如,数据是脚本标记的内部。请注意,数据不是元素的文本。使用text()获取用户可见的文本,使用data()获取脚本、注释、CSS样式等的内容。
- String className() 获取此元素的“class”属性的文字值,该属性可能包括多个类名,用空格分隔。
- Set
classNames() 获取所有元素的类名 - boolean hasClass(String className) 测试此元素是否具有类。不区分大小写
- String val() 获取表单元素的值(input、textarea等)。
使用JSOUP 方式连接
高并发爬取使用OkHttp,因为内部做了很多的优化,在爬取的频率很快和多的时候效率是非常好的, JSOUP内部提供了请求方式但效率没有OkHttp高,下面是封装好的直接就可以用,但是只支持返回xml/html页面否则报错,所以尽量使用OkHttp比较灵活,效率还好
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocketFactory;
import javax.net.ssl.TrustManager;
import javax.net.ssl.X509TrustManager;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.security.SecureRandom;
import java.security.cert.X509Certificate;
/**
* 简要描述
* @Author: huanmin
* @Date: 2022/7/17 18:47
* @Version: 1.0
* @Description: 文件作用详细描述....
* Document execute = JsoupConnect.build("http://www.weather.com.cn/textFC/hb.shtml").getExecute();
*/
public class JsoupConnect {
private final Connection connect;
public static JsoupConnect build(String url) {
return new JsoupConnect(url);
}
public Document getExecute() {
Document document = null;
try {
document = connect.get();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}
public Document postExecute() {
Document document = null;
try {
document = connect.get();
} catch (IOException e) {
e.printStackTrace();
}
return document;
}
public JsoupConnect(String url) {
Connection connect1 = Jsoup.connect(url);
TrustManager[] trustManagers = buildTrustManagers();
connect1.timeout(30000);//超时时间 30秒
connect1.sslSocketFactory(createSSLSocketFactory(trustManagers));
connect1.userAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36");
this.connect =connect1;
}
//设置代理
// Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 8080));
public JsoupConnect proxy(Proxy.Type type,String ip,int port) {
Proxy proxy = new Proxy(type, new InetSocketAddress(ip, port));
this.connect.proxy(proxy);
return this;
}
public JsoupConnect cookie(String name, String value){
connect.cookie(name,value);
return this;
}
public JsoupConnect header(String name, String value){
connect.header(name,value);
return this;
}
//get 和 post
public JsoupConnect addParameter(String key, String value){
connect.data(key,value);
return this;
}
/**
* 生成安全套接字工厂,用于https请求的证书跳过
*
* @return
*/
private SSLSocketFactory createSSLSocketFactory(TrustManager[] trustAllCerts) {
SSLSocketFactory ssfFactory = null;
try {
SSLContext sc = SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, new SecureRandom());
ssfFactory = sc.getSocketFactory();
} catch (Exception e) {
e.printStackTrace();
}
return ssfFactory;
}
private TrustManager[] buildTrustManagers() {
return new TrustManager[]{
new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] chain, String authType) {
}
@Override
public void checkServerTrusted(X509Certificate[] chain, String authType) {
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return new X509Certificate[]{};
}
}
};
}
}
User-Agent(随机)
User-Agent是Http协议中的一部分,属于头域的组成部分,User Agent也简称UA。用较为普通的一点来说,是一种向访问网站提供你所使用的浏览器类型、操作系统及版本、CPU 类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息的标识。UA字符串在每次浏览器 HTTP 请求时发送到服务器! ,所以大批量爬虫的时候不要一直使用同一个User-Agent, 要多切换切换,不然就会识别到你了给你拉黑
可以利用随机的方式来获取下面的内容
Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50 Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50 Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0) Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0) Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0) Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0) Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1 Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1 Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11 Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36 Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0) Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE) Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5 Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1 MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1 Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10 UCWEB7.0.2.37/28/999 Openwave/ UCWEB7.0.2.37/28/999 Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999
import com.google.common.base.Charsets;
import com.google.common.io.Files;
import com.google.common.io.Resources;
import java.io.File;
import java.net.URL;
import java.util.Collections;
import java.util.List;
/**
* 简要描述
*
* @Author: huanmin
* @Date: 2022/7/17 19:51
* @Version: 1.0
* @Description: 文件作用详细描述....
*/
public class UserAgent {
private static final String DEFAULT_USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36";
private static List userAgents = null;
static {
URL url = Resources.getResource("userAgents");
if(url != null) {
File file = new File(url.getPath());
try {
userAgents = Files.readLines(file, Charsets.UTF_8);
} catch(Exception ex) {}
}
}
public static String getUserAgent() {
if(userAgents == null || userAgents.size() == 0) {
return DEFAULT_USER_AGENT;
}
Collections.shuffle(userAgents);
return userAgents.get(0);
}
}
后台爬虫的三大问题
后台爬虫在大行其道的时候,也有着些许棘手的、到目前也没有什么好的解决方案问题,而归根结底,这些问题的根本原因是由于后台爬虫的先天不足导致,在正式讨论之前,我们先思考一个问题,“爬虫和浏览器有什么异同?”
相同点: 本质上都是通过http/https协议请求互联网数据
不同点:
- 爬虫一般为自动化程序,无需用用户交互,而浏览器不是
- 运行场景不同 ,浏览器运行在客户端,而爬虫一般都跑在服务端
- 能力不同, 浏览器包含渲染引擎、javascript ,而爬虫一般都不具备这两者。
了解了这些,我们再来看看后台面临的问题
问题一:交互问题
有些网页往往需要和用户进行一些交互,进而才能走到下一步,比如输入一个验证码,拖动一个滑块,选几个汉字。网站之所以这么做,很多时候都是为了验证访问者到底是人还是机器。
而爬虫程序遇到这种情况很难处理,传统的简单图片验证码可以通过图形处理算法读出内容,但是随着各种各样,花样百出,人神共愤的、变态的验证码越来越多(尤其是买火车票时,分分钟都想爆粗口),这个问题就越来越严重。
问题二:Javascript 解析问题
如前文所述,javascript可以动态生成dom。目前大多数网页属于动态网页**(内容由javascript动态填充),尤其是在移动端,SPA/PWA应用越来越流行,网页中大多数有用的数据都是通过ajax/fetch动态获**取后然后再由js填充到网页dom树中,单纯的html静态页面中有用的数据很少。
目前主要应对的方案就是对于js ajax/fetch请求直接请求ajax/fetch的url ,但是还有一些ajax的请求参数会依赖一段javascript动态生成,比如一个请求签名,再比如用户登陆时对密码的加密等等。
如果一昧的去用后台脚本去干javascript本来做的事,这就要清楚的理解原网页代码逻辑,而这不仅非常麻烦,而且会使你的爬取代码异常庞大臃肿,但是,更致命的是,有些javascript可以做的事爬虫程序是很难甚至是不能模仿的,比如有些网站使用拖动滑块到某个位置的验证码机制,这就很难再爬虫中去模仿。
其实,总结一些,这些弊端归根结底,是因为爬虫程序并非是浏览器,没有javascript解析引擎所致。针对这个问题,目前主要的应对策略就是在爬虫中引入Javascript 引擎,如PhantomJS,但是又有着明显的弊端,如服务器同时有多个爬取任务时,资源占用太大。
还有就是,这些 无窗口的javascript引擎很多时候使用起来并不能像在浏览器环境中一样,页面内部发生跳转时,会导致流程很难控制。
问题三:IP限制
这是目前对后台爬虫中最致命的。网站的防火墙会对某个固定ip在某段时间内请求的次数做限制,如果没有超过上线则正常返回数据,超过了,则拒绝请求,如qq 邮箱。
值得说明的是,ip限制有时并非是专门为了针对爬虫的,而大多数时候是出于网站安全原因针对DOS攻击的防御措施。后台爬取时机器和ip有限,很容易达到上线而导致请求被拒绝。目前主要的应对方案是使用代理,这样一来ip的数量就会多一些,但代理ip需要花钱
selenium+phantomjs(维护中…内容重新整理)

selenium+phantomjs组合进行爬取,因为selenium封装了phantomjs,能够让我们更方便,更好的使用,节约时间和成本。
PhantomJs下载地址: https://phantomjs.org/download.html
org.seleniumhq.selenium selenium-java 3.141.59 com.codeborne phantomjsdriver 1.4.4
DesiredCapabilities desiredCapabilities = new DesiredCapabilities();
//ssl证书支持
desiredCapabilities.setCapability("acceptSslCerts", true);
//截屏支持,这里不需要
desiredCapabilities.setCapability("takesScreenshot", false);
//css搜索支持
desiredCapabilities.setCapability("cssSelectorsEnabled", true);
//js支持
desiredCapabilities.setJavascriptEnabled(true);
//驱动支持
desiredCapabilities.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"G:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(desiredCapabilities);
//这里注意,把窗口的大小调整为最大,如果不设置可能会出现元素不可用的问题
driver.manage().window().maximize();
上述是对爬虫实例对象设置请求头信息,由于我们爬取的网站采用JS+AJAX进行渲染页面,所以需要js支持,必须设置setJavascriptEnabled(true),否则无法运行js代码,无法正常拿到渲染后的页面。
//用于设置phantomjs运行器的位置 desiredCapabilities.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,"G:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
现在,我们有了实例对象了,可以进行网页爬取了,以CSDN为例,给大家简单说一下工具的使用。
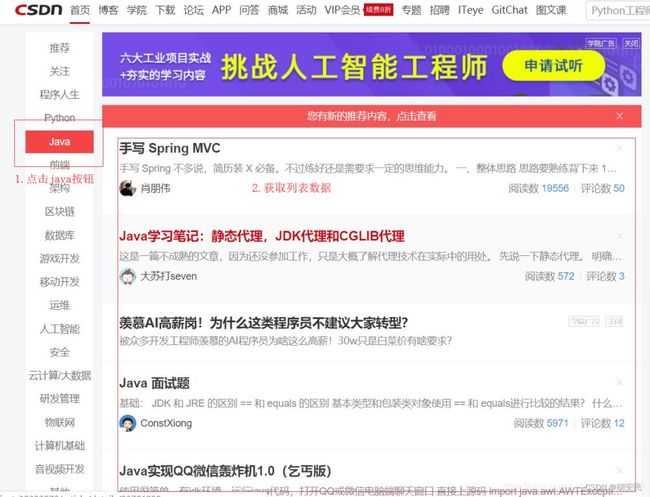
假设我们现在需要获取JAVA模块的文章(标题+链接),我们来看看应该怎么做。
String href = "https://www.csdn.net";
PhantomJSDriver driver = create();
//获取csdn主页
driver.get(href);
//定位到Java按钮
WebElement java = driver.findElementByLinkText("Java");
//执行点击
java.click();
//用于定位到Java模块列表
WebElement feedlist_id = driver.findElementById("feedlist_id");
List liList = feedlist_id.findElements(By.className("clearfix"));
//循环遍历li
for (WebElement li : liList) {
WebElement title = li.findElement(By.className("title"));
WebElement a = title.findElement(By.tagName("a"));
System.out.println("标题:" + a.getText() + " 链接:" + a.getAttribute("href"));
}
常用的如下:
//通过id的方式获取元素 public WebElement findElementById(String using) //通过链接文本方式获取单个元素 public WebElement findElementByLinkText(String using) //通过标签名方式获取单个元素 public WebElement findElementByTagName(String using) //通过标签名方式获取多个元素 public ListfindElementsByTagName(String using) //通过name属性方式获取单个元素 public WebElement findElementByName(String using) //通过name属性方式获取多个元素 public List findElementsByName(String using) //通过类名方式获取单个元素 public WebElement findElementByClassName(String using) //通过类名方式获取多个元素 public List findElementsByClassName(String using) //通过css选择器方式获取单个元素 public WebElement findElementByCssSelector(String using) //通过css选择器方式获取多个元素 public List findElementsByCssSelector(String using) //通过xpath方式获取单个元素 public WebElement findElementByXPath(String using) //通过xpath方式获取多个元素 public List findElementsByXPath(String using) void click(); //触发点击事件 String getAttribute(String name) //获取属性值 String getText() //标签文本 element.getAttribute("value") //输入框value值 clear()用于清空元素的内容 sendKeys(CharSequence... keysToSend)用于给输入框赋值
选择下拉框元素
Select select = new Select(driver.findElementById("select"));
//通过索引选择
select.selectByIndex(1);
//通过value值获取
select.selectByValue("zhangsan")
//通过文本值获取
select.selectByVisibleText("张三");
单选和复选
driver.findElementById("radio"); radio.click(); //单选按钮
复选框其实和单选按钮一样,都是定位元素,点击元素,在选择元素之前,我们可以通过isSelected()来判断元素是否被选择,isEnabled()来判断元素是否被禁用。
表单提交
WebElement form = driver.findElementById("form");
//只能用于表单提交
form.submit();
在某些时候,有些网站在执行的时候可能会打开另外一个窗口,这个时候,如果我们想要回到原先的窗口,应该怎么办呢?
//获取窗口的句柄 String windowHandle = driver.getWindowHandle(); //另外一个窗口执行... //另外一个窗口执行结束后,我们可以通过switchTo()去返回到原先窗口 driver.switchTo().window(windowHandle);
在某些AJAX请求进行渲染的页面,可能我们不能立即获取到渲染后的页面,那么我们就需要进行等待,这里支持两种类型的等待方式:
隐形等待
//针对全局设置,所有命令的超时时间都是10s,如果超过等待时间,则抛出异常。 driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
显示等待
WebDriverWait webDriverWait = new WebDriverWait(driver, 10); webDriverWait.until(new ExpectedCondition() { @Override public WebElement apply(WebDriver webDriver) { return webDriver.findElement(By.id("toolber-keyword")); } });
等待某个元素,最大等待10s,默认0.5s为搜索间隔,搜索到元素则停止等待。在使用获取数据的网站中,使用该方式十分方便,若10s都没有结果,那么则认定系统出现故障。
某些时候,我们可能通过getText()的方式获取标签的文本值并不会生效 ,phantomjs能够执行js语句,这可是一个好方式,我们可以通过写js语句来解决大部分问题。 执行js语句Object executeScript(String script, Object... args); 该方法可以供我们执行js语句,script代表我们的js语句,args代表散列值,接受参数使用arguments[0]依次来接受。示例如下:
假设我们想要获取某个标签的文本值
第一种方式:driver.executeScript("document.getElementById('blogClick').innerText")
第二种方式:
WebElement blogClick = driver.findElementById("blogClick");
driver.executeScript("arguments[0].innerText",blogClick);
采用爬虫处理业务,如果是静态网页还比较好处理,如果是AJAX+JS渲染的动态页面,在爬取的过程中,会遇到各种各样的坑,就需要耐心研究了,到底怎么才能获取到
到此这篇关于详解Java中的OkHttp JSONP爬虫的文章就介绍到这了,更多相关java OkHttp JSONP内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!