【Mysql】九、Mysql高级篇 --- 索引
MYSQL索引
-
-
- 一、什么是索引?
- 二、索引数据结构
-
- 1、mysql数据库的四种索引
- 2、BTREE结构
- 三、索引分类、创建索引、查看索引
-
- 1、单值索引
- 2、复合索引
- 3、函数索引
- 4、删除索引
- 5、查看索引
- 四、什么情况需要建立索引?
- 五、EXPLAIN 字段属性
-
- 1、EXPLAIN -- id(表的读取顺序):
- 2、EXPLAIN -- select_type(数据读取操作):
- 3、EXPLAIN -- type(如何读取数据):
- 4、EXPLAIN -- possible_keys(显示可能用到的索引):
- 5、EXPLAIN -- key(查询实际用到的索引):
- 6、EXPLAIN -- key_len(索引显示的字节数):
- 7、EXPLAIN -- ref(显示索引的使用列):
- 8、EXPLAIN -- row(查询的行数):
- 9、EXPLAIN -- filtered(读取行数占比):
- 10、EXPLAIN -- extra(扩展):
- 六、索引优化原则
-
查看本表的索引:
mysql:SHOW INDEX FROM 表名
oracle:SELECT * FROM USER_IND_COLUMNS WHERE TABLE_NAME = '表名'
一、什么是索引?

索引优势:
- 相当于书的目录,提高数据库
查询效率,降低数据库io操作成本。 - 通过索引对数据库进行排序,降低
排序成本,减轻cpu负荷
索引劣势: - 建立索引相当于存储了另一张表记录了索引的模型,该表保存主键与索引字段,所以索引列也需要占用内存空间。
- 索引虽然提高了查询效率,但是同时也降低了增删改的效率。因为每次新增修改删除,都需要更新索引列字段的B+树,降低增删改的时间。
二、索引数据结构
1、mysql数据库的四种索引
- BTREE:最广泛的索引类型,大部分索引都是支持该类型
- HASH:只有memory引擎支持,用途相对较少
- R-tree(空间索引):MYISAM引擎,用途少,不介绍
- Full-text(全文索引):MYISAM引擎,InnoDB丛mysql5.6版本之后支持该索引
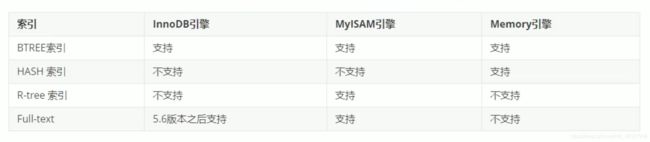
创建索引没有特殊指定时,默认创建的都是BTREE索引
2、BTREE结构
btree叫做多路平衡搜索树,一颗m叉的btree树有如下特性:
- 树中每个节点最多包含m个孩子
- 除去根节点和叶子节点外,每个节点最多有m/2(向上取整 5/2=2.5 取 3)个孩子
- 如根节点不是叶子节点,则至少有两个孩子
- 所有叶子节点都在同一层
- 每个非叶子节点都有n个key和n+1个指针组成
三、索引分类、创建索引、查看索引
个人主推方式二进行所有创建修改等操作
1、单值索引
方式1: CREATE INDEX index_name ON table_name(column)
方式2: ALTER TABLE table_name ADD INDEX index_name(column)
2、复合索引
方式1: CREATE INDEX composite_index_name ON table_name(col1, col2)
方式2: ALTER TABLE table_name ADD INDEX composite_index_name(col1, col2)
3、函数索引
函数索引是MySql8.0支持的,之前版本不支持该函数索引
-- 创建函数索引
ALTER TABLE books ADD KEY idx_fun_data((DATE(created_time))) -- 注意函数需要用()包住,否则报错
ALTER TABLE books ADD KEY idx_fun_data((DATE(created_time)))
-- 查看当前索引
mysql> SHOW INDEX FROM books;
+-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------------------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------------------------+
| books | 0 | PRIMARY | 1 | id | A | 2 | NULL | NULL | | BTREE | | | YES | NULL |
| books | 1 | idx_fun_data | 1 | NULL | A | 1 | NULL | NULL | YES | BTREE | | | YES | cast(`created_time` as date) |
| books | 1 | idx_fun_contact | 1 | NULL | A | 3 | NULL | NULL | YES | BTREE | | | YES | concat(`name`,`writer`) |
+-------+------------+---------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------------------------+
explain查看是否使用索引
-- key = idx_fun_data 使用函数索引
mysql> EXPLAIN SELECT * FROM books WHERE DATE(created_time)='2000-1-1';
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | books | NULL | ref | idx_fun_data | idx_fun_data | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+--------------+---------+-------+------+----------+-------+
-- key = idx_fun_contact 使用函数索引
mysql> EXPLAIN SELECT CONCAT(name, writer) FROM books WHERE CONCAT(name, writer) = 'sssssss';
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | books | NULL | ref | idx_fun_contact | idx_fun_contact | 123 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------+
4、删除索引
方式一DROP INDEX index_name ON table_name
方式二:ALTER TABLE table_name DROP INDEX index_name
5、查看索引
- mysql:
SHOW INDEX FROM '表名'

- oracle:
SELECT * FROM USER_IND_COLUMNS WHERE TABLE_NAME = '表名'
四、什么情况需要建立索引?
适合创建索引
- 主键索引
- 频繁查询的字段需要创建索引(例如:微信号或者商品编号)
- 与其他表关联的外键需要
- 查询中分组的字段
- 查询中排序的字段 order by
- 字段列值重复度较底的情况下
不适合创建索引
- 频繁更新的字段
不适合建立索引 - where语句用不到的需要建索引
- 表记录太少不要建立索引
- 某个字段包含许多重复的内容,不要建立索引(例如:性别字段只保存男/女)
五、EXPLAIN 字段属性
explain是模拟mysql查询优化器执行sql,可以看出mysql是如何优化执行你的sql语句。
explain有什么用?
- 读取表的顺序
- 数据读取操作的操作累心
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表多少行被查询优化器查询
1、EXPLAIN – id(表的读取顺序):
- id相同:执行顺序是由上而下
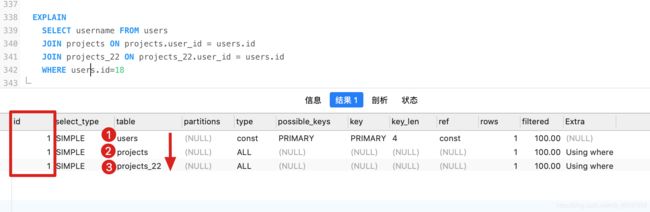
- id不同: ID值越大越先执行
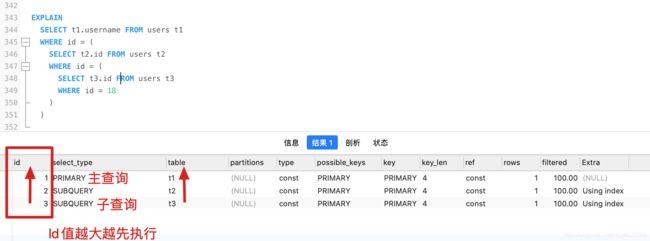
- id相同和不同,同时存在: ID越大优先级越高,ID相同顺序执行

2、EXPLAIN – select_type(数据读取操作):
| select_type属性 | 含义 |
|---|---|
| SIMPLE | 简单的select查询,不包含子查询和UNION |
| PRIMARY | 查询中包含任何复杂的子查询部分,最外层标记为PRIMARY,最后执行 |
| SUBQUERY | select或者where子句包含子查询 |
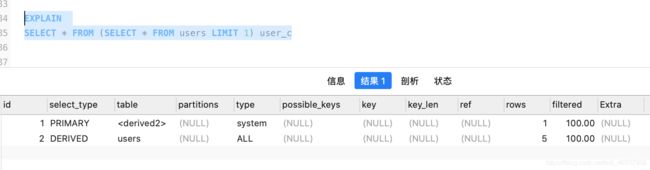
| DERIVED | from列表中包含子查询(表连接)mysql会递归这些子查询,将子查询结果放在临时表中 |
| UNION | 第二个select出现在union之后,标记为UNION(union包含在from子句中,外层select标记为DERIV-DR) |
| UNION RESULT | 连接两个select语句的UNION |
图例为UNION RESULT
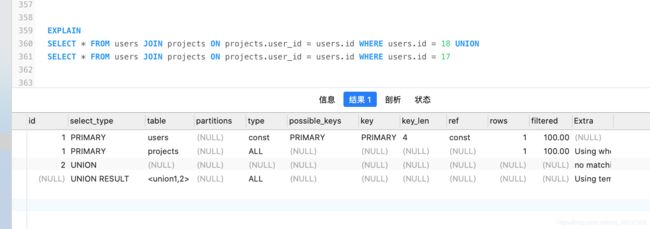
3、EXPLAIN – type(如何读取数据):

效率从好到差依次为:system > const > eq_ref > ref > range > index > ALL
查询中至少达到range,最好可以达到ref
| type属性 | 含义 |
|---|---|
| ALL | 全表扫描 |
| INDEX | 读取索引,与ALL都是全表扫描,ALL读硬盘,INDEX读索引,降低了IO操作 |
| RANGE | 只检索指定的行,where语句中的IN、between、<、>等范围查询 |
| REF | 非唯一扫描,主表的关联约束可以匹配子表多行,一对多的情况 |
| EQ_REF | 读取主表中和关联表,表中的每行组合成的一行 |
| CONST | 通过索引一次找到,常见与主键约束(PRIMARY KEY) / 唯一约束(UNIQUE),很快的将主键置于where列表中,mysql可以将该查询转化成一个常量 |
| SYSTEM | 表记录只有一行(是const的特例) |
ALL:

INDEX:

RANGE:

REF:
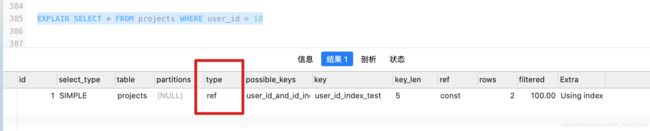
EQ_REF:

CONST:

SYSTEM:

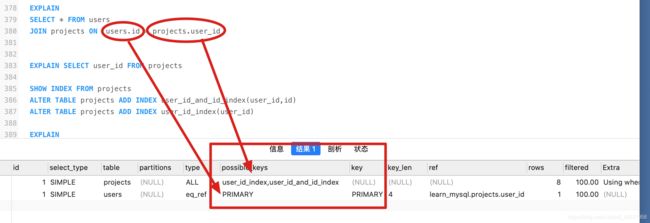
4、EXPLAIN – possible_keys(显示可能用到的索引):
查询字段存在多个索引,将会被列出,但不一定会使用
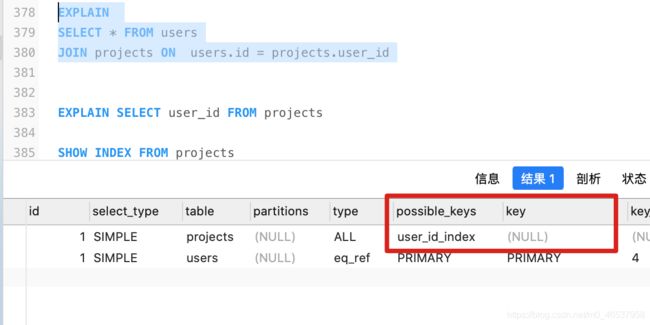
5、EXPLAIN – key(查询实际用到的索引):
-
实际使用到的索引,NULL表示没有用到索引,不为NULL则是实际使用到的索引
-
查询中若使用了覆盖索引,则改索引仅出现在key列表中
覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据
如下所示,user_id、id建立了联合索引,所以查询结果会直接从索引中读取结果,而不需要全表扫描
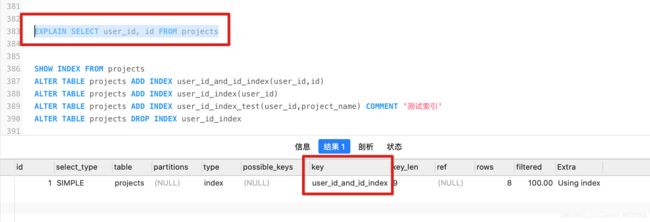
6、EXPLAIN – key_len(索引显示的字节数):
显示的是最大可能长度,并非实际使用长度。
不损失精度的情况下,越小越好,速度越快
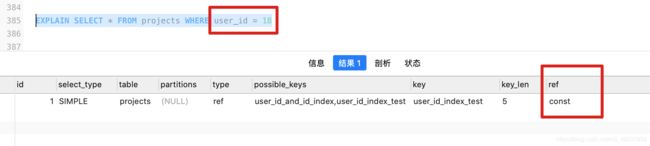
7、EXPLAIN – ref(显示索引的使用列):
如果索引固定查询一个值的话显示的是const,表示一个常量
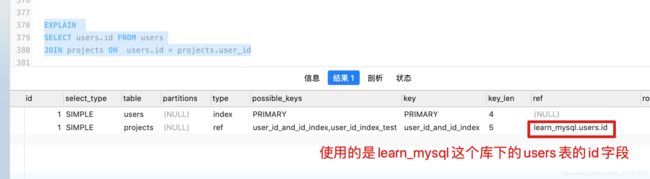
如果使用了某个字段去匹配则显示,users.id表示被使用的字段,,null表示没有使用到索引去匹配行。
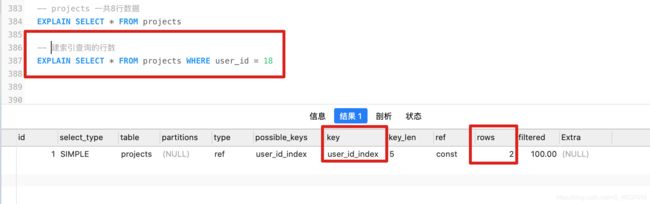
8、EXPLAIN – row(查询的行数):
- 未建索引查询的行数:

- 建索引查询的行数:
9、EXPLAIN – filtered(读取行数占比):
filtered表示的是:返回结果的行数占需读取行数的百分比
案例模拟隐试类型转化的索引搜索:
直接索引搜索
-- 走索引只查了一行,结果也是一行,所以filtered=100%
mysql> explain select * from testt where name = '2000';
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | testt | NULL | ref | name_index | name_index | 33 | const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
类型转化走where再走索引
-- 走索引查了两行,结果是一行,所以filtered=50%
mysql> explain select * from testt where name = 2000;
+----+-------------+-------+------------+-------+---------------+------------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | testt | NULL | index | name_index | name_index | 33 | NULL | 2 | 50.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+------------+---------+------+------+----------+--------------------------+
10、EXPLAIN – extra(扩展):
- Using filesort 文件排序
使用外部的索引排序,而不是按照表内的索引顺序读取。无法利用索引直接排序操作叫做‘文件排序’ - Using temporary
使用零时表保存中间结果,查询排序结果时使用临时表,常见order by 和 group by,效率低下 - Using index
使用了索引,表示效率不错。
如果同时出现Using where,表示索引被用来执行索引键值的查找。
如果没有出现Using where,表示索引用来读取数据而非查找 - Using where
使用了where过滤条件 - Using Join Buffer
使用了连接缓存 - Impossible WHERE
where的值得总是false,不可获取元素,例如where 1 = 2 - Using index condition
会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行

六、索引优化原则

- 全值匹配
如果是联合索引,按照最左匹配原则,查询要从最左列开始,并且不跳过索引中的列
-- 索引按照 user_id,project_name,id 顺序建立
ALTER TABLE projects ADD INDEX user_id_index_test(user_id,project_name,id) COMMENT '测试索引'
-- 查询也按照 user_id,project_name,id 顺序查询
SELECT * FROM projects WHERE user_id = 18 AND project_name = 'zhangsan' AND id = 1
-- 最左匹配原则,不用 user_id 开头,用不上索引
SELECT * FROM projects WHERE project_name = 'zhangsan' AND id = 1
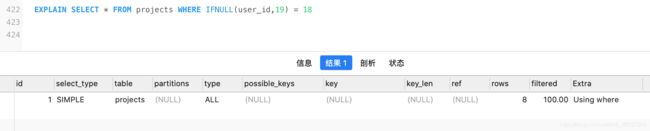
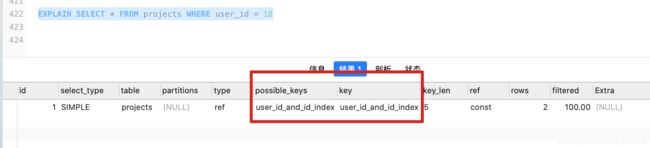
- 不要再索引列上做任何操作
计算、函数、自动or手动类型转化,否则索引失效,全表扫描
使用函数:
不使用函数:
- 联合索引中,使用范围查询后右边的列索引失效
-- 使用范围后的列索引失效
SELECT * FROM projects WHERE user_id > 18 AND project_name = 'zhangsan' AND id = 1
-- 如上 user_id 使用range查找后,project_name、id无法使用全职匹配查找,,,此时联合索引只用上了user_id的范围查找。
-
少用
select *(只访问索引列,索引列和查询列一致)
要什么取什么,不要使用*取出所有的值 -
<>、!=无法使用索引 -
is null、is not null无法使用索引 -
like开头的 ‘%admin’ 索引失效
解决办法:使用覆盖索引
-- select字段必须是索引字段
select name from projects where name like '%hhhh%'
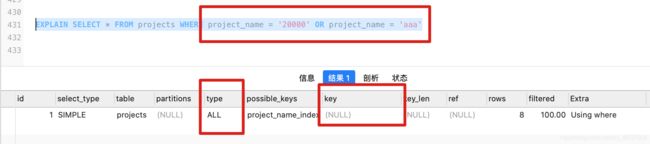
- 隐试类型转换不走索引
-- project_name是字符串类型,使用20000会隐试转化类型为字符串
EXPLAIN SELECT * FROM projects WHERE project_name = 20000
类型不一致,隐试转换的情况,不走索引
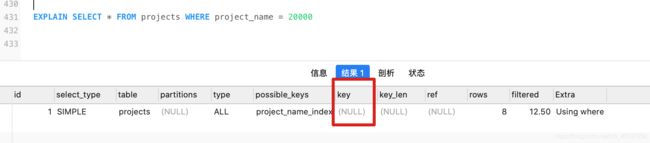
按照字段原类型查询,走索引

- 少用
or,不走索引