解析Caffe框架的prototxt模型文件
文档目录
-
- 前言
- 1. 解析示例
- 2. 层解析
- 3. 完整文件
- 4. caffe模型权重转pytorch模型权重
前言
Caffe全称为Convolutional Architecture for Fast Feature Embedding,是一个应用广泛的开源深度学习框架,在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目,由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。核心编程语言为C++,同时提供了python和matlab接口。
本篇博客主要介绍Caffe的模型定义文件.prototxt及如何将Caffe的模型权重文件.caffemodel转为PyTorch的.pth。
1. 解析示例
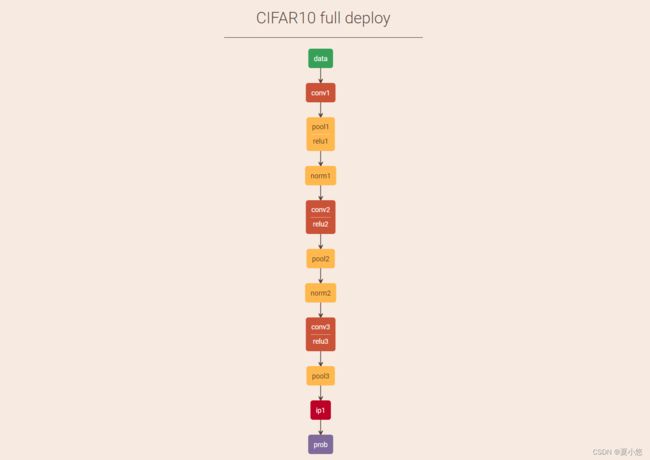
2. 层解析
# this is model name
# cifar10_full.prototxt
name: "CIFAR10_full_deploy"
# N.B. input image must be in CIFAR-10 format
# as described at http://www.cs.toronto.edu/~kriz/cifar.html
# 输入层
layer {
name: "data" # 表示该层的名字为 data
type: "Input" # 表示该层的类型为 Input
top: "data" # 表示输出结果保存到 data 层中, 也就是本层
input_param { # 表示输入参数
shape: { # 表示输入 shape 为 (1,3,32,32)
dim: 1
dim: 3
dim: 32
dim: 32
}
}
}
# 卷积层
layer {
name: "conv1" # 表示该层的名字为 data
type: "Convolution" # 表示该层的类型为 Convolution
bottom: "data" # 表示输入来自 data 层
top: "conv1" # 表示输出保存到 conv1 层
param {
lr_mult: 1 # 表示本层参数的学习率需要乘上的一个系数
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32 # 表示本层输出 dim 为 32
pad: 2 # 表示卷积核的 padding 为 2, kernel-size 为 5, stride 为 1
kernel_size: 5
stride: 1
}
}
# 池化层
layer {
name: "pool1" # 表示该层的名字为 pool1
type: "Pooling" # 表示该层的类型为 Pooling
bottom: "conv1" # 表示输入来自 conv1 层
top: "pool1" # 表示输出保存到 pool1 层
pooling_param {
pool: MAX # 表示最大池化
kernel_size: 3 # 表示 kernel-size 为 3, stride 为 2
stride: 2
}
}
# 激活层
layer {
name: "relu1" # 表示该层的名字为 relu1
type: "ReLU" # 表示该层的类型为 ReLU
bottom: "pool1" # 表示输入来自 pool1 层
top: "pool1" # 表示输出保存到 pool1 层
}
# 归一层
layer {
name: "norm1" # 表示该层的名字为 norm1
type: "LRN" # 表示该层的类型为 LRN
bottom: "pool1" # 表示输入来自 pool1 层
top: "norm1" # 表示输出保存到 norm1 层
lrn_param {
local_size: 3
alpha: 5e-05
beta: 0.75
norm_region: WITHIN_CHANNEL
}
}
...
layer {
name: "ip1" # 表示该层的名字为 ip1
type: "InnerProduct" # 表示该层的类型为 InnerProduct
bottom: "pool3" # 表示输入来自 pool3 层
top: "ip1" # 表示输出保存到 ip1 层
param {
lr_mult: 1
decay_mult: 250
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 10
}
}
layer {
name: "prob" # 表示该层的名字为 prob
type: "Softmax" # 表示该层的类型为 Softmax
bottom: "ip1" # 表示输入来自 ip1 层
top: "prob" # 表示输出保存到 prob 层
}
3. 完整文件
# cifar10_full.prototxt
name: "CIFAR10_full_deploy"
# N.B. input image must be in CIFAR-10 format
# as described at http://www.cs.toronto.edu/~kriz/cifar.html
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 32 dim: 32 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 3
alpha: 5e-05
beta: 0.75
norm_region: WITHIN_CHANNEL
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "norm1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "norm2"
type: "LRN"
bottom: "pool2"
top: "norm2"
lrn_param {
local_size: 3
alpha: 5e-05
beta: 0.75
norm_region: WITHIN_CHANNEL
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "norm2"
top: "conv3"
convolution_param {
num_output: 64
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: AVE
kernel_size: 3
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool3"
top: "ip1"
param {
lr_mult: 1
decay_mult: 250
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 10
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "ip1"
top: "prob"
}
该文件可以在ethereon网站上进行可视化。
4. caffe模型权重转pytorch模型权重
具体支持的模型可参考链接:caffemodel2pytorch。
# 运行指令
python -m caffemodel2pytorch resnet50-float.caffemodel -o resnet50.pt
# caffemodel2pytorch.py
import os
import sys
import time
import argparse
import tempfile
import subprocess
import collections
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import reduce
try:
from urllib.request import urlopen
except:
from urllib2 import urlopen # Python 2 support.
import google.protobuf.descriptor
import google.protobuf.descriptor_pool
import google.protobuf.symbol_database
import google.protobuf.text_format
from google.protobuf.descriptor import FieldDescriptor as FD
TRAIN = 0
TEST = 1
caffe_pb2 = None
def initialize(caffe_proto = 'https://raw.githubusercontent.com/BVLC/caffe/master/src/caffe/proto/caffe.proto', codegen_dir = tempfile.mkdtemp(), shadow_caffe = True):
global caffe_pb2
if caffe_pb2 is None:
local_caffe_proto = os.path.join(codegen_dir, os.path.basename(caffe_proto))
with open(local_caffe_proto, 'w') as f:
mybytes = urlopen(caffe_proto).read()
mystr = mybytes.decode('ascii', 'ignore')
f.write(mystr)
#f.write((urlopen if 'http' in caffe_proto else open)(caffe_proto).read())
subprocess.check_call(['protoc', '--proto_path', os.path.dirname(local_caffe_proto), '--python_out', codegen_dir, local_caffe_proto])
sys.path.insert(0, codegen_dir)
old_pool = google.protobuf.descriptor._message.default_pool
old_symdb = google.protobuf.symbol_database._DEFAULT
google.protobuf.descriptor._message.default_pool = google.protobuf.descriptor_pool.DescriptorPool()
google.protobuf.symbol_database._DEFAULT = google.protobuf.symbol_database.SymbolDatabase(pool = google.protobuf.descriptor._message.default_pool)
import caffe_pb2 as caffe_pb2
google.protobuf.descriptor._message.default_pool = old_pool
google.protobuf.symbol_database._DEFAULT = old_symdb
sys.modules[__name__ + '.proto'] = sys.modules[__name__]
if shadow_caffe:
sys.modules['caffe'] = sys.modules[__name__]
sys.modules['caffe.proto'] = sys.modules[__name__]
return caffe_pb2
def set_mode_gpu():
global convert_to_gpu_if_enabled
convert_to_gpu_if_enabled = lambda obj: obj.cuda()
def set_device(gpu_id):
torch.cuda.set_device(gpu_id)
class Net(nn.Module):
def __init__(self, prototxt, *args, **kwargs):
super(Net, self).__init__()
# to account for both constructors, see https://github.com/BVLC/caffe/blob/master/python/caffe/test/test_net.py#L145-L147
caffe_proto = kwargs.pop('caffe_proto', None)
weights = kwargs.pop('weights', None)
phase = kwargs.pop('phase', None)
weights = weights or (args + (None, None))[0]
phase = phase or (args + (None, None))[1]
self.net_param = initialize(caffe_proto).NetParameter()
google.protobuf.text_format.Parse(open(prototxt).read(), self.net_param)
for layer in list(self.net_param.layer) + list(self.net_param.layers):
layer_type = layer.type if layer.type != 'Python' else layer.python_param.layer
if isinstance(layer_type, int):
layer_type = layer.LayerType.Name(layer_type)
module_constructor = ([v for k, v in modules.items() if k.replace('_', '').upper() in [layer_type.replace('_', '').upper(), layer.name.replace('_', '').upper()]] + [None])[0]
if module_constructor is not None:
param = to_dict(([v for f, v in layer.ListFields() if f.name.endswith('_param')] + [None])[0])
caffe_input_variable_names = list(layer.bottom)
caffe_output_variable_names = list(layer.top)
caffe_loss_weight = (list(layer.loss_weight) or [1.0 if layer_type.upper().endswith('LOSS') else 0.0]) * len(layer.top)
caffe_propagate_down = list(getattr(layer, 'propagate_down', [])) or [True] * len(caffe_input_variable_names)
caffe_optimization_params = to_dict(layer.param)
param['inplace'] = len(caffe_input_variable_names) == 1 and caffe_input_variable_names == caffe_output_variable_names
module = module_constructor(param)
self.add_module(layer.name, module if isinstance(module, nn.Module) else CaffePythonLayerModule(module, caffe_input_variable_names, caffe_output_variable_names, param.get('param_str', '')) if type(module).__name__.endswith('Layer') else FunctionModule(module))
module = getattr(self, layer.name)
module.caffe_layer_name = layer.name
module.caffe_layer_type = layer_type
module.caffe_input_variable_names = caffe_input_variable_names
module.caffe_output_variable_names = caffe_output_variable_names
module.caffe_loss_weight = caffe_loss_weight
module.caffe_propagate_down = caffe_propagate_down
module.caffe_optimization_params = caffe_optimization_params
for optim_param, p in zip(caffe_optimization_params, module.parameters()):
p.requires_grad = optim_param.get('lr_mult', 1) != 0
else:
print('Skipping layer [{}, {}, {}]: not found in caffemodel2pytorch.modules dict'.format(layer.name, layer_type, layer.type))
if weights is not None:
self.copy_from(weights)
self.blobs = collections.defaultdict(Blob)
self.blob_loss_weights = {name : loss_weight for module in self.children() for name, loss_weight in zip(module.caffe_output_variable_names, module.caffe_loss_weight)}
self.train(phase != TEST)
convert_to_gpu_if_enabled(self)
def forward(self, data = None, **variables):
if data is not None:
variables['data'] = data
numpy = not all(map(torch.is_tensor, variables.values()))
variables = {k : convert_to_gpu_if_enabled(torch.from_numpy(v.copy()) if numpy else v) for k, v in variables.items()}
for module in [module for module in self.children() if not all(name in variables for name in module.caffe_output_variable_names)]:
for name in module.caffe_input_variable_names:
assert name in variables, 'Variable [{}] does not exist. Pass it as a keyword argument or provide a layer which produces it.'.format(name)
inputs = [variables[name] if propagate_down else variables[name].detach() for name, propagate_down in zip(module.caffe_input_variable_names, module.caffe_propagate_down)]
outputs = module(*inputs)
if not isinstance(outputs, tuple):
outputs = (outputs, )
variables.update(dict(zip(module.caffe_output_variable_names, outputs)))
self.blobs.update({k : Blob(data = v, numpy = numpy) for k, v in variables.items()})
caffe_output_variable_names = set([name for module in self.children() for name in module.caffe_output_variable_names]) - set([name for module in self.children() for name in module.caffe_input_variable_names if name not in module.caffe_output_variable_names])
return {k : v.detach().cpu().numpy() if numpy else v for k, v in variables.items() if k in caffe_output_variable_names}
def copy_from(self, weights):
try:
import h5py, numpy
state_dict = self.state_dict()
for k, v in h5py.File(weights, 'r').items():
if k in state_dict:
state_dict[k].resize_(v.shape).copy_(torch.from_numpy(numpy.array(v)))
print('caffemodel2pytorch: loaded model from [{}] in HDF5 format'.format(weights))
except Exception as e:
print('caffemodel2pytorch: loading model from [{}] in HDF5 format failed [{}], falling back to caffemodel format'.format(weights, e))
bytes_weights = open(weights, 'rb').read()
bytes_parsed = self.net_param.ParseFromString(bytes_weights)
if bytes_parsed != len(bytes_weights):
print('caffemodel2pytorch: loading model from [{}] in caffemodel format, WARNING: file length [{}] is not equal to number of parsed bytes [{}]'.format(weights, len(bytes_weights), bytes_parsed))
for layer in list(self.net_param.layer) + list(self.net_param.layers):
module = getattr(self, layer.name, None)
if module is None:
continue
parameters = {name : convert_to_gpu_if_enabled(torch.FloatTensor(blob.data)).view(list(blob.shape.dim) if len(blob.shape.dim) > 0 else [blob.num, blob.channels, blob.height, blob.width]) for name, blob in zip(['weight', 'bias'], layer.blobs)}
if len(parameters) > 0:
module.set_parameters(**parameters)
print('caffemodel2pytorch: loaded model from [{}] in caffemodel format'.format(weights))
def save(self, weights):
import h5py
with h5py.File(weights, 'w') as h:
for k, v in self.state_dict().items():
h[k] = v.cpu().numpy()
print('caffemodel2pytorch: saved model to [{}] in HDF5 format'.format(weights))
@property
def layers(self):
return list(self.children())
class Blob(object):
AssignmentAdapter = type('', (object, ), dict(shape = property(lambda self: self.contents.shape), __setitem__ = lambda self, indices, values: setattr(self, 'contents', values)))
def __init__(self, data = None, diff = None, numpy = False):
self.data_ = data if data is not None else Blob.AssignmentAdapter()
self.diff_ = diff if diff is not None else Blob.AssignmentAdapter()
self.shape_ = None
self.numpy = numpy
def reshape(self, *args):
self.shape_ = args
def count(self, *axis):
return reduce(lambda x, y: x * y, self.shape_[slice(*(axis + [-1])[:2])])
@property
def data(self):
if self.numpy and torch.is_tensor(self.data_):
self.data_ = self.data_.detach().cpu().numpy()
return self.data_
@property
def diff(self):
if self.numpy and torch.is_tensor(self.diff_):
self.diff_ = self.diff_.detach().cpu().numpy()
return self.diff_
@property
def shape(self):
return self.shape_ if self.shape_ is not None else self.data_.shape
@property
def num(self):
return self.shape[0]
@property
def channels(self):
return self.shape[1]
@property
def height(self):
return self.shape[2]
@property
def width(self):
return self.shape[3]
class Layer(torch.autograd.Function):
def __init__(self, caffe_python_layer = None, caffe_input_variable_names = None, caffe_output_variable_names = None, caffe_propagate_down = None):
self.caffe_python_layer = caffe_python_layer
self.caffe_input_variable_names = caffe_input_variable_names
self.caffe_output_variable_names = caffe_output_variable_names
self.caffe_propagate_down = caffe_propagate_down
def forward(self, *inputs):
bottom = [Blob(data = v.cpu().numpy()) for v in inputs]
top = [Blob() for name in self.caffe_output_variable_names]
#self.caffe_python_layer.reshape()
self.caffe_python_layer.setup(bottom, top)
self.caffe_python_layer.setup = lambda *args: None
self.caffe_python_layer.forward(bottom, top)
outputs = tuple(convert_to_gpu_if_enabled(torch.from_numpy(v.data.contents.reshape(*v.shape))) for v in top)
self.save_for_backward(*(inputs + outputs))
return outputs
def backward(self, grad_outputs):
inputs, outputs = self.saved_tensors[:len(self.caffe_input_variable_names)], self.saved_tensors[len(self.caffe_input_variable_names):]
bottom = [Blob(data = v.cpu().numpy()) for v in inputs]
top = [Blob(data = output.cpu().numpy(), diff = grad_output.cpu().numpy()) for grad_output, output in zip(grad_outputs, outputs)]
self.caffe_python_layer.backward(top, self.caffe_propagate_down, bottom)
return tuple(convert_to_gpu_if_enabled(torch.from_numpy(blob.diff.contents.reshape(*v.reshape))) if propagate_down else None for v, propagate_down in zip(bottom, self.caffe_propagate_down))
class SGDSolver(object):
def __init__(self, solver_prototxt):
solver_param = initialize().SolverParameter()
google.protobuf.text_format.Parse(open(solver_prototxt).read(), solver_param)
solver_param = to_dict(solver_param)
self.net = Net(solver_param.get('train_net') or solver_param.get('net'), phase = TRAIN)
self.iter = 1
self.iter_size = solver_param.get('iter_size', 1)
self.optimizer_params = dict(lr = solver_param.get('base_lr') / self.iter_size, momentum = solver_param.get('momentum', 0), weight_decay = solver_param.get('weight_decay', 0))
self.lr_scheduler_params = dict(policy = solver_param.get('lr_policy'), step_size = solver_param.get('stepsize'), gamma = solver_param.get('gamma'))
self.optimizer, self.scheduler = None, None
def init_optimizer_scheduler(self):
self.optimizer = torch.optim.SGD([dict(params = [param], lr = self.optimizer_params['lr'] * mult.get('lr_mult', 1), weight_decay = self.optimizer_params['weight_decay'] * mult.get('decay_mult', 1), momentum = self.optimizer_params['momentum']) for module in self.net.children() for param, mult in zip(module.parameters(), module.caffe_optimization_params + [{}, {}]) if param.requires_grad])
self.scheduler = torch.optim.lr_scheduler.StepLR(self.optimizer, step_size = self.lr_scheduler_params['step_size'], gamma = self.lr_scheduler_params['gamma']) if self.lr_scheduler_params.get('policy') == 'step' else type('', (object, ), dict(step = lambda self: None))()
def step(self, iterations = 1, **inputs):
loss_total = 0.0
for i in range(iterations):
tic = time.time()
if self.optimizer is not None:
self.optimizer.zero_grad()
loss_batch = 0
losses_batch = collections.defaultdict(float)
for j in range(self.iter_size):
outputs = [kv for kv in self.net(**inputs).items() if self.net.blob_loss_weights[kv[0]] != 0]
loss = sum([self.net.blob_loss_weights[k] * v.sum() for k, v in outputs])
loss_batch += float(loss) / self.iter_size
for k, v in outputs:
losses_batch[k] += float(v.sum()) / self.iter_size
if self.optimizer is None:
self.init_optimizer_scheduler()
self.optimizer.zero_grad()
loss.backward()
loss_total += loss_batch
self.optimizer.step()
self.scheduler.step()
self.iter += 1
log_prefix = self.__module__ + '.' + type(self).__name__
print('{}] Iteration {}, loss: {}'.format(log_prefix, self.iter, loss_batch))
for i, (name, loss) in enumerate(sorted(losses_batch.items())):
print('{}] Train net output #{}: {} = {} (* {} = {} loss)'.format(log_prefix, i, name, loss, self.net.blob_loss_weights[name], self.net.blob_loss_weights[name] * loss))
print('{}] Iteration {}, lr = {}, time = {}'.format(log_prefix, self.iter, self.optimizer_params['lr'], time.time() - tic))
return loss_total
modules = dict(
Convolution = lambda param: Convolution(param),
InnerProduct = lambda param: InnerProduct(param),
Pooling = lambda param: [nn.MaxPool2d, nn.AvgPool2d][param['pool']](kernel_size = first_or(param, 'kernel_size', 1), stride = first_or(param, 'stride', 1), padding = first_or(param, 'pad', 0)),
Softmax = lambda param: nn.Softmax(dim = param.get('axis', -1)),
ReLU = lambda param: nn.ReLU(),
Dropout = lambda param: nn.Dropout(p = param['dropout_ratio']),
Eltwise = lambda param: [torch.mul, torch.add, torch.max][param.get('operation', 1)],
LRN = lambda param: nn.LocalResponseNorm(size = param['local_size'], alpha = param['alpha'], beta = param['beta'])
)
class FunctionModule(nn.Module):
def __init__(self, forward):
super(FunctionModule, self).__init__()
self.forward_func = forward
def forward(self, *inputs):
return self.forward_func(*inputs)
class CaffePythonLayerModule(nn.Module):
def __init__(self, caffe_python_layer, caffe_input_variable_names, caffe_output_variable_names, param_str):
super(CaffePythonLayerModule, self).__init__()
caffe_python_layer.param_str = param_str
self.caffe_python_layer = caffe_python_layer
self.caffe_input_variable_names = caffe_input_variable_names
self.caffe_output_variable_names = caffe_output_variable_names
def forward(self, *inputs):
return Layer(self.caffe_python_layer, self.caffe_input_variable_names, self.caffe_output_variable_names)(*inputs)
def __getattr__(self, name):
return nn.Module.__getattr__(self, name) if name in dir(self) else getattr(self.caffe_python_layer, name)
class Convolution(nn.Conv2d):
def __init__(self, param):
super(Convolution, self).__init__(first_or(param,'group',1), param['num_output'], kernel_size = first_or(param, 'kernel_size', 1), stride = first_or(param, 'stride', 1), padding = first_or(param, 'pad', 0), dilation = first_or(param, 'dilation', 1), groups = first_or(param, 'group', 1))
self.weight, self.bias = nn.Parameter(), nn.Parameter()
self.weight_init, self.bias_init = param.get('weight_filler', {}), param.get('bias_filler', {})
def forward(self, x):
if self.weight.numel() == 0 and self.bias.numel() == 0:
requires_grad = [self.weight.requires_grad, self.bias.requires_grad]
super(Convolution, self).__init__(x.size(1), self.out_channels, kernel_size = self.kernel_size, stride = self.stride, padding = self.padding, dilation = self.dilation)
convert_to_gpu_if_enabled(self)
init_weight_bias(self, requires_grad = requires_grad)
return super(Convolution, self).forward(x)
def set_parameters(self, weight = None, bias = None):
init_weight_bias(self, weight = weight, bias = bias.view(-1) if bias is not None else bias)
self.in_channels = self.weight.size(1)
class InnerProduct(nn.Linear):
def __init__(self, param):
super(InnerProduct, self).__init__(1, param['num_output'])
self.weight, self.bias = nn.Parameter(), nn.Parameter()
self.weight_init, self.bias_init = param.get('weight_filler', {}), param.get('bias_filler', {})
def forward(self, x):
if self.weight.numel() == 0 and self.bias.numel() == 0:
requires_grad = [self.weight.requires_grad, self.bias.requires_grad]
super(InnerProduct, self).__init__(x.size(1), self.out_features)
convert_to_gpu_if_enabled(self)
init_weight_bias(self, requires_grad = requires_grad)
return super(InnerProduct, self).forward(x if x.size(-1) == self.in_features else x.view(len(x), -1))
def set_parameters(self, weight = None, bias = None):
init_weight_bias(self, weight = weight.view(weight.size(-2), weight.size(-1)) if weight is not None else None, bias = bias.view(-1) if bias is not None else None)
self.in_features = self.weight.size(1)
def init_weight_bias(self, weight = None, bias = None, requires_grad = []):
if weight is not None:
self.weight = nn.Parameter(weight.type_as(self.weight), requires_grad = self.weight.requires_grad)
if bias is not None:
self.bias = nn.Parameter(bias.type_as(self.bias), requires_grad = self.bias.requires_grad)
for name, requires_grad in zip(['weight', 'bias'], requires_grad):
param, init = getattr(self, name), getattr(self, name + '_init')
if init.get('type') == 'gaussian':
nn.init.normal_(param, std = init['std'])
elif init.get('type') == 'constant':
nn.init.constant_(param, val = init['value'])
param.requires_grad = requires_grad
def convert_to_gpu_if_enabled(obj):
return obj
def first_or(param, key, default):
return param[key] if isinstance(param.get(key), int) else (param.get(key, []) + [default])[0]
def to_dict(obj):
return list(map(to_dict, obj)) if isinstance(obj, collections.Iterable) else {} if obj is None else {f.name : converter(v) if f.label != FD.LABEL_REPEATED else list(map(converter, v)) for f, v in obj.ListFields() for converter in [{FD.TYPE_DOUBLE: float, FD.TYPE_SFIXED32: float, FD.TYPE_SFIXED64: float, FD.TYPE_SINT32: int, FD.TYPE_SINT64: int, FD.TYPE_FLOAT: float, FD.TYPE_ENUM: int, FD.TYPE_UINT32: int, FD.TYPE_INT64: int, FD.TYPE_UINT64: int, FD.TYPE_INT32: int, FD.TYPE_FIXED64: float, FD.TYPE_FIXED32: float, FD.TYPE_BOOL: bool, FD.TYPE_STRING: str, FD.TYPE_BYTES: lambda x: x.encode('string_escape'), FD.TYPE_MESSAGE: to_dict}[f.type]]}
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(metavar = 'model.caffemodel', dest = 'model_caffemodel', help = 'Path to model.caffemodel')
parser.add_argument('-o', dest = 'output_path', help = 'Path to converted model, supported file extensions are: h5, npy, npz, json, pt')
parser.add_argument('--caffe.proto', metavar = '--caffe.proto', dest = 'caffe_proto', help = 'Path to caffe.proto (typically located at CAFFE_ROOT/src/caffe/proto/caffe.proto)', default = 'https://raw.githubusercontent.com/BVLC/caffe/master/src/caffe/proto/caffe.proto')
args = parser.parse_args()
args.output_path = args.output_path or args.model_caffemodel + '.pt'
net_param = initialize(args.caffe_proto).NetParameter()
net_param.ParseFromString(open(args.model_caffemodel, 'rb').read())
blobs = {layer.name + '.' + name : dict(data = blob.data, shape = list(blob.shape.dim) if len(blob.shape.dim) > 0 else [blob.num, blob.channels, blob.height, blob.width]) for layer in list(net_param.layer) + list(net_param.layers) for name, blob in zip(['weight', 'bias'], layer.blobs)}
if args.output_path.endswith('.json'):
import json
with open(args.output_path, 'w') as f:
json.dump(blobs, f)
elif args.output_path.endswith('.h5'):
import h5py, numpy
with h5py.File(args.output_path, 'w') as h:
h.update(**{k : numpy.array(blob['data'], dtype = numpy.float32).reshape(*blob['shape']) for k, blob in blobs.items()})
elif args.output_path.endswith('.npy') or args.output_path.endswith('.npz'):
import numpy
(numpy.savez if args.output_path[-1] == 'z' else numpy.save)(args.output_path, **{k : numpy.array(blob['data'], dtype = numpy.float32).reshape(*blob['shape']) for k, blob in blobs.items()})
elif args.output_path.endswith('.pt'):
torch.save({k : torch.FloatTensor(blob['data']).view(*blob['shape']) for k, blob in blobs.items()}, args.output_path)