动手学深度学习之物体检测算法R-CNN,SSD,YOLO
区域卷积神经网络R-CNN
R-CNN
- 首先是使用启发式搜索算法来选择锚框,选出很多锚框之后,对于每一个锚框当作一张图片,使用一个预训练好的模型来对他进行特征抽取,然后训练一个SVM来对类别进行分类。使用一个线性回归模型来预测边缘框的偏移。

兴趣区域(Rol)池化层
- 上面我们得到不同的锚框,我们怎么将其变为一个batch?
- 使用RoI Pooling:给定一个锚框,我们将它均匀的切成 n × m n\times m n×m块,然后输出每一块中的最大值。这样不管锚框多大,总是输出nm个值。这样我们就可以将不同的锚框变为一个batch了。

Fast RCNN
- 在RCNN上做块,首先对整张图片用CNN抽取特征,抽完之后,再用Selective serch搜索锚框,搜到锚框之后,我们将他映射到CNN的输出上,我们将刚刚选择的锚框在CNN的输出上面按照比例找出来,然后使用RoI池化对锚框抽取特征。下图黄色框中的会将图片变为锚框数乘以特征的矩阵,这样就不需要SVM了可以一次性的进去。
- 这个之所以快的原因是因为,在CNN这里不是对每个锚框进行特征的抽取,而是对整张图片进行特征抽取。

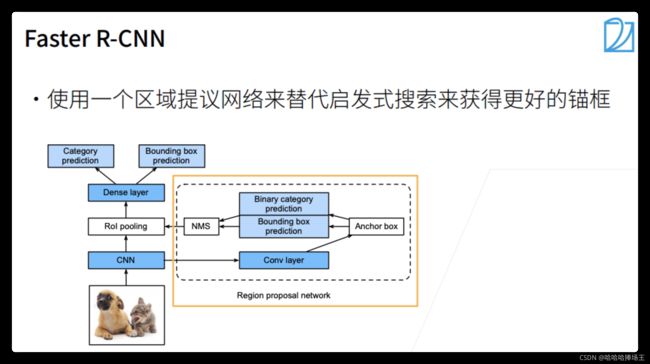
Faster RCNN
- 使用一个神经网络来替代启发式搜索算法。首先将图片放到CNN中,然后将结果给RPN,RPN的输出就是一堆高质量的锚框。RPN其实就是在做一个模糊一点的目标检测。RPN拿到了CNN的输出后再做一次卷积,然后又弄出一堆锚框,然后做一个二分类问题,这个锚框是不是质量还不错。根据预测值使用NMS(将类似的锚框去重),然后将预测好的锚框进入一个RoI的池化,再做一个对每个类的预测。
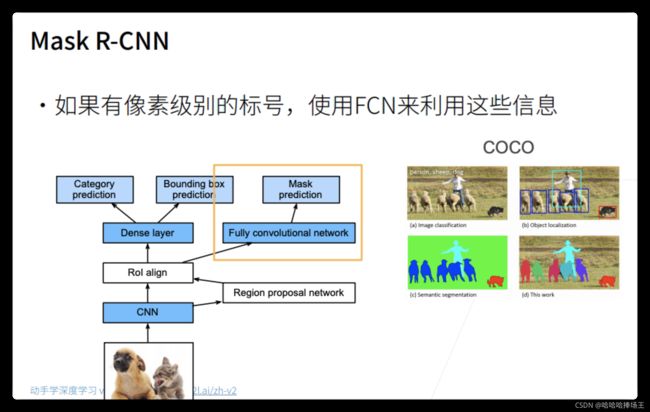
Mask R-CNN
- 和Fater RCNN比起来只是加了一个新的东西,假设我们有每一个像素的编号,我们可以对每个像素进行预测,在RoI出来的东西中,会进入一个FCN再加上Mask prediction的loss就可以提升原来的精度。对RoI Pooling做了一个改进,RoI align的意思就是说:直接在中间切开,后面拿到的值只拿到像素的一部分。
总结

单发多框检测(SSD)
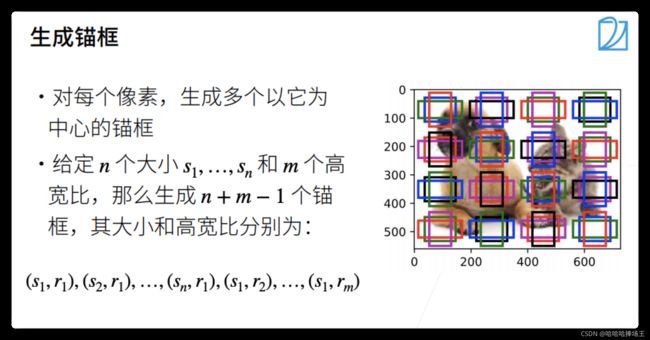
生成锚框
- 对每个像素,生成多个以它为中心的锚框。如果有n个大小和m个高宽比的话,会生成n+m-1个锚框。
SSD模型
- 当一个图片过来,先抽特征,抽完特征之后,对每个像素里面的每一个像素,按照刚刚的方法去生成锚框,然后我们可以认为,在底层我们会检测一个小的锚框,在顶部看大物体。他的一个想法就是在多个分辨率下进行预测,SSD在一个张图片上生成很多锚框。

总结

YOLO(you only look one)
- 只有一个单身节网络来做预测,需要有锚框,在前面SSD中我们对每个像素生成锚框,这样的话每个锚框之间的重叠率是非常高的。YOLO的思想就是尽量让每个锚框不重叠。它将一个张图片均匀分开,每一块就是一个锚框,这样锚框就不会重叠。接下来每一个锚框会预测b个边缘框。
多尺度目标检测
%matplotlib inline
import torch
from d2l import torch as d2l
img = d2l.plt.imread('/Users/tiger/Desktop/study/机器学习/李沐深度学习/d2l-zh/pytorch/img/catdog.jpg')
h, w = img.shape[:2]
h, w
(561, 728)
在特征图(fmap)上生成锚框(anchors),每个单位(像素)作为锚框的中心
# 这里的特征图就是某一个卷积层的输出。
def display_anchors(fmap_w, fmap_h, s):
d2l.set_figsize()
fmap = torch.zeros((1, 10, fmap_h, fmap_w)) # 这里我们生成一个假的feature map
anchors = d2l.multibox_prior(fmap, sizes=s, ratios=[1, 2, 0.5]) # 生成一堆以每个像素为中心的锚框
bbox_scale = torch.tensor((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img).axes, anchors[0] * bbox_scale) # 还原出真实图片中的高和宽。
探测小目标
display_anchors(fmap_w=4, fmap_h=4, s=[-0.15])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aeyqgiCk-1630209459567)(output_6_0.svg)]
将特征图的高度和宽度减小一半,然后使用较大的锚框来检测较大的目标
display_anchors(fmap_w=2, fmap_h=2, s=[-0.4])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-plYWHRyP-1630209459568)(output_8_0.svg)]
将特征图的高度和宽度减小一半,然后将锚框的尺度增加到0.8
display_anchors(fmap_w=1, fmap_h=1, s=[0.8])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6J8YCpiN-1630209459569)(output_10_0.svg)]
单发多框检测(SSD)
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 类别预测层,预测一个锚框的类别
def cls_predictor(num_inputs, num_anchors, num_classes): # 输入通道数,多少个锚框,多少类
return nn.Conv2d(num_inputs, num_anchors * (num_classes + 1),
kernel_size=3, padding=1) # 输入的通道数,输出的通道数=锚框的通道数*(类别数+1),这里加1的原因是有一个背景类,
# 边界框预测:用来预测每个锚框到真实锚框的偏移
def bbox_predictor(num_inputs, num_anchors):
# 这里的意思就是对于每一个bounding box的每一个预测值是4,输出通道数就是以每个像素为中心的锚框大小*4,这里kernel_size=3,padding=1使得我们的输入大小和输出大小是一样的。
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)
# 连接多尺度的预测,给一个block(network中的一些块)
def forward(x, block):
return block(x)
Y1 = forward(torch.zeros((2, 8, 20, 20)), cls_predictor(8, 5, 10))
Y2 = forward(torch.zeros((2, 16, 10, 10)), cls_predictor(16, 3, 10))
Y1.shape, Y2.shape
(torch.Size([2, 55, 20, 20]), torch.Size([2, 33, 10, 10]))
# 首先Flatten,将4D变为2D,将通道数放到最后,再将其拉成一个2D的矩阵,高就是批量大小,宽是所有,之所以把通道数放在最后是因为,这样做每个像素的预测都是一个连续的,不然的话像素会拉的比较开
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
# 在宽上面concat
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)
concat_preds([Y1, Y2]).shape
torch.Size([2, 25300])
# 高和宽减半块,这里是一个简单的CNN网络
# 主要做的事情就是将高宽减半
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2): # 这里就是一个卷积+一个BN+一个ReLU,重复两次
blk.append(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2)) #加一个最大池化,将高宽减半
return nn.Sequential(*blk)
forward(torch.zeros((2, 3, 20, 20)), down_sample_blk(3, 10)).shape
/Users/tiger/opt/anaconda3/envs/d2l-zh/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
torch.Size([2, 10, 10, 10])
# 基本的网络块,从原始图片抽特征一直到第一次对它的featuremap做锚框,中间的那一截我们将它称为basenet
def base_net():
blk = []
num_filters = [3, 16, 32, 64] # channels数
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i + 1]))
return nn.Sequential(*blk) # 高宽从原始图片减少8倍
forward(torch.zeros((2, 3, 256, 256)), base_net()).shape
torch.Size([2, 64, 32, 32])
# 完整的单发多框检测模型由五个模块组成
def get_blk(i):
if i == 0:
blk = base_net() # 将图片变为通道数为64,图片大小减8倍
elif i == 1:
blk = down_sample_blk(64, 128) # 通道数变为125
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1, 1)) # 全局的池化,将featuremap压到1*1
else:
blk = down_sample_blk(128, 128) # 通道数不变
return blk
# 对每个块定义前向计算
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor): # 输入,网络块,锚框的大小、ratio。。。
Y = blk(X) # 算一个featuremap出来
anchors = d2l.multibox_prior(Y, sizes=size, ratios=ratio) #告诉我们在这个尺度下面我们的超参数事什么样子的,生成锚框
cls_preds = cls_predictor(Y) # 每一个锚框的类别的预测
bbox_preds = bbox_predictor(Y) # 锚框到真实的边缘框的offset
return (Y, anchors, cls_preds, bbox_preds)
# 超参数
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1 # 每一个像素为中心生成4个锚框
# 定义完整的网络
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128] # 每个Stage的输出
for i in range(5): # 做五次预测
setattr(self, f'blk_{i}', get_blk(i))
setattr(
self, f'cls_{i}',
cls_predictor(idx_to_in_channels[i], num_anchors,
num_classes))
setattr(self, f'bbox_{i}',
bbox_predictor(idx_to_in_channels[i], num_anchors))
# 完整forward函数
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(cls_preds.shape[0], -1,
self.num_classes + 1) # reshape成一个3D的东西,做Softmax方便
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds # 返回:每个锚框,类别的预测,offset的预测
# 创建一个模型实例,然后使用它执行前向计算
net = TinySSD(num_classes=1)
X = torch.zeros((32, 3, 256, 256))
anchors, cls_preds, bbox_preds = net(X)
print('output anchors:', anchors.shape)
print('output class preds:', cls_preds.shape)
print('output bbox preds:', bbox_preds.shape)
output anchors: torch.Size([1, 5444, 4])
output class preds: torch.Size([32, 5444, 2])
output bbox preds: torch.Size([32, 21776])
# 读取香蕉检测数据集
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)
read 1000 training examples
read 100 validation examples
# 初始化其参数并定义优化算法
device, net = d2l.try_gpu(), TinySSD(num_classes=1)
trainer = torch.optim.SGD(net.parameters(), lr=0.2, weight_decay=5e-4)
# 定义损失函数和评价函数
cls_loss = nn.CrossEntropyLoss(reduction='none') # reduction的意思就是不将每个loss加起来
bbox_loss = nn.L1Loss(reduction='none') # L1Loss
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = cls_loss(cls_preds.reshape(-1, num_classes), # -1的意思就是将批量大小维和锚框个数维放在一个
cls_labels.reshape(-1)).reshape(batch_size, -1).mean(dim=1) # 对锚框分类的loss
bbox = bbox_loss(bbox_preds * bbox_masks,
bbox_labels * bbox_masks).mean(dim=1) # 预测和真实的乘了一个mask
return cls + bbox
#
def cls_eval(cls_preds, cls_labels):
return float(
(cls_preds.argmax(dim=-1).type(cls_labels.dtype) == cls_labels).sum())
#
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())
# 模型训练
num_epochs, timer = 20, d2l.Timer()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
timer.start()
trainer.zero_grad()
X, Y = features.to(device), target.to(device)
anchors, cls_preds, bbox_preds = net(X)
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y) # 这个函数作用就是把锚框和Y输入进去之后输出预测
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks) # 计算损失
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')
print(f'{len(train_iter.dataset) / timer.stop():.1f} examples/sec on '
f'{str(device)}')
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
in
15 l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
16 bbox_masks)
---> 17 l.mean().backward()
18 trainer.step()
19 metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
~/opt/anaconda3/envs/d2l-zh/lib/python3.8/site-packages/torch/_tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
253 create_graph=create_graph,
254 inputs=inputs)
--> 255 torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
256
257 def register_hook(self, hook):
~/opt/anaconda3/envs/d2l-zh/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables, inputs)
145 retain_graph = create_graph
146
--> 147 Variable._execution_engine.run_backward(
148 tensors, grad_tensors_, retain_graph, create_graph, inputs,
149 allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
# 预测模型
X = torchvision.io.read_image('../img/banana.jpg').unsqueeze(0).float()
img = X.squeeze(0).permute(1, 2, 0).long()
def predict(X):
net.eval() # 预测模式
anchors, cls_preds, bbox_preds = net(X.to(device))
cls_probs = F.softmax(cls_preds, dim=2).permute(0, 2, 1)
output = d2l.multibox_detection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0] != -1]
return output[0, idx]
output = predict(X)
# 筛选所有置信度不低于 0.9 的边界框,做为最终输出
def display(img, output, threshold):
d2l.set_figsize((5, 5))
fig = d2l.plt.imshow(img)
for row in output:
score = float(row[1])
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * torch.tensor((w, h, w, h), device=row.device)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output.cpu(), threshold=0.9)