看过来——用Python探索《红楼梦》的人物关系
数据准备
红楼梦 txt 电子书一份。
金陵十二钗 + 贾宝玉 人物名称列表。
宝玉 nr 黛玉 nr 宝钗 nr 湘云 nr 凤姐 nr 李纨 nr 元春 nr 迎春 nr 探春 nr 惜春 nr 妙玉 nr 巧姐 nr 秦氏 nr
该分列表是为了做分词时使用,后面的 nr 就是人名的意思。
人物出镜次数
首先读取小说;
with open("红楼梦.txt", encoding="gb18030") as f:
honglou = f.read()
接下来进行出场次数数据整理;
honglou = honglou.replace("\n", " ")
honglou_new = honglou.split(" ")
renwu_list = ['宝玉', '黛玉', '宝钗', '湘云', '凤姐', '李纨', '元春', '迎春', '探春', '惜春', '妙玉', '巧姐', '秦氏']
renwu = pd.DataFrame(data=renwu_list, columns=['姓名'])
renwu['出现次数'] = renwu.apply(lambda x: len([k for k in honglou_new if x[u'姓名'] in k]), axis=1)
renwu.to_csv('renwu.csv', index=False, sep=',')
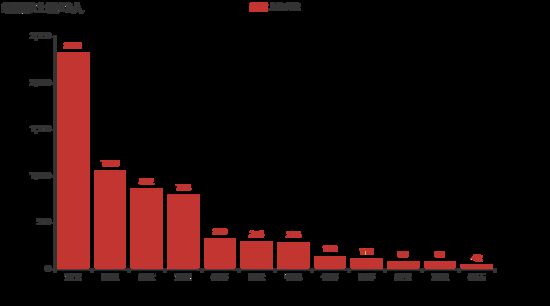
renwu.sort_values('出现次数', ascending=False, inplace=True)
attr = renwu['姓名'][0:12]
v1 = renwu['出现次数'][0:12]
这样我们就得到了 attr 和 v1 两个数据,内容如下:

下面就可以通过 pyecharts 来绘制柱状图了;
bar = (
Bar()
.add_xaxis(attr.tolist())
.add_yaxis("上镜次数", v1.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="红楼梦上镜13人"))
)
bar.render_notebook()
人物关系
数据处理
我们先将读取到内存中的小说内容进行 jieba 分词处理;
import jieba
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]
通过 load_userdict 将我们上面自定义的词典加载到了 jieba 库中;
接下来进行分词处理;
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("贾妃", "元春")
h.replace("李宫裁", "李纨")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1
因为文中"贾妃", "元春","李宫裁", "李纨" 等人物名字混用严重,所以这里做替换处理。
然后使用 jieba 库提供的 pseg 工具来做分词处理,会返回每个分词的词性。
之后做判断,只有符合要求且在我们提供的字典列表里的分词,才会保留。
一个人每出现一次,就会增加一,方便后面画关系图时,人物 node 大小的确定。
对于存在于我们自定义词典的人名,保存到一个临时变量当中 tmpNames。
下面处理每个段落中的人物关系:
for name in tmpNames:
for name1 in name:
for name2 in name:
if name1 == name2:
continue
if relationships[name1].get(name2) is None:
relationships[name1][name2] = 1
else:
relationships[name1][name2] += 1
对于出现在同一个段落中的人物,我们认为他们是关系紧密的,同时每出现一次,关系增加1。
最后可以把相关信息保存到文件当中。
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")
文件1:人物关系表,包含首先出现的人物、之后出现的人物和一同出现次数。
文件2:人物比重表,包含该人物总体出现次数,出现次数越多,认为所占比重越大。
数据分析
下面我们可以做一些简单的人物关系分析。
这里我们还是使用 pyecharts 绘制图表。
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "宝玉":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="红楼人物关系"))
)
return g
首先把两个文件通过 pandas 读取到内存当中。
对于“宝玉”,由于其占比过大,如果统一进行缩放,会导致其他人物的 node 过小,展示不美观,所以这里先做了一次缩放。
最后我们得到的人物关系图如下:
