DETR训练实践以及自动预标注脚本、测试可视化脚本
目录
自动预标注脚本
测试可视化脚本
DETR训练自己的数据集
自动预标注脚本
总所周知,标注是一个体力活,而我又是一个懒人,所以我就自己写了个脚本。。。并不要求高精度,只是想体验用DETR训练自己的数据集又不想标注的人可以借鉴或使用。
输入方式可以调用摄像头或者读取视频、图片三种方式来获取输入,我加了print提示,可以直接运行查看哈。输入0,1,2来选择

功能分为3种,查看原图,检测可视化,图像标注,由于这次我是用我的人脸做了一个数据集,所以取名face detection。

如果选择image label,接下来是选择数据集类型,输入对应的字符例如test就可以开始了。其他的功能可以读者自己慢慢摸索一下。有需要的或者意见的也可以直接在评论区提出来,我看见了也会及时回复。这里就不说太多了。
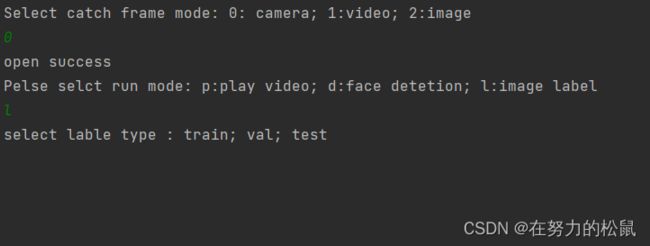
输出结果:


测试可视化脚本
因为论文源代码里是没有test脚本的,所以我就直接写了一个test脚本包括了可视化结果
其实和源码是同样的架构,搭建模型后load训练好的参数,构建测试数据集,获取测试输出后用后处理获得高得分的目标然后可视化出来,有需要的也可以评论需要哈。这里我就只把主要函数贴上来了
def main(dataset_type):
device = torch.device('cuda')
model= build_model()
model.to(device)
#dataset
dataset_test = build_dataset(dataset_type)
sampler_test = torch.utils.data.SequentialSampler(dataset_test)
data_loader_test = DataLoader(dataset_test, 1, sampler=sampler_test,
drop_last=False, collate_fn=utils.collate_fn, num_workers=0)
base_ds = get_coco_api_from_dataset(dataset_test)
#load model params
load_path = 'D:\\fgy\\Desktop\\DETR\\detr\\pthsave\\pthsave_facedetect\\checkpoint.pth'
checkpoint = torch.load(load_path, map_location='cpu')
model.load_state_dict(checkpoint["model"],False)
model.eval()
#postprocess
postprocessors = {'bbox': detr.PostProcess()}
iou_types = tuple(k for k in ('segm', 'bbox') if k in postprocessors.keys())
coco_evaluator = coco_eval.CocoEvaluator(base_ds, iou_types)
image_path = 'D:\\fgy\\Desktop\\DETR\\dataroot\\{}'.format(dataset_type)
#get result and visual
for img_data, target in data_loader_test:
img_data = img_data.to(device)
target = [{k: v.to(device) for k, v in t.items()} for t in target]
output = model(img_data)
# print(output)
orig_target_sizes = torch.stack([t["orig_size"] for t in target], dim=0)
result = postprocessors['bbox'](output, orig_target_sizes)
res = {target['image_id'].item(): output for target, output in zip(target, result)}
if coco_evaluator is not None:
coco_evaluator.update(res)
# print(res)
res_index = []
score=[]
min_score = 0.995
res_lable=[]
res_bbox=[]
res = res[target[0]['image_id'].item()]
for i in range(0,100):
res_tmp = res['scores']
if float(res_tmp[i]) > min_score:
score.append(float(res_tmp[i]))
res_index.append(i)
res_lable.append(int(res['labels'][res_index].cpu().numpy()))
res_bbox.append(res['boxes'][res_index].cpu().numpy().tolist())
print("processing "+str(target[0]['image_id'].item()))
print("result: ",score, res_lable, res_bbox)
img =cv.imread(os.path.join(image_path,str(target[0]['image_id'].item())+".jpg"))
for bbox in res_bbox:
bbox = bbox[0]
cv.rectangle(img, (int(bbox[0]), int(bbox[1])), (int(bbox[2]), int(bbox[3])), (255, 0, 0), 1)
cv.imshow("Faceimglabel", img)
cv.waitKey(0)
if coco_evaluator is not None:
coco_evaluator.synchronize_between_processes()
coco_evaluator.accumulate()
coco_evaluator.summarize()
print(coco_evaluator)DETR训练自己的数据集
开始之前,对DETR或源码不了解的建议先看一下DETR源码笔记(一)_在努力的松鼠的博客-CSDN博客_detr源码
DETR源码笔记(二)_在努力的松鼠的博客-CSDN博客
一、首先是搭建自己的数据集,标注完成后,查看数据集的类别数N,其中不包括背景类。
二、可以初始化参数训练,也可以下载预训练模型,建议下载一个预训练模型,提高训练速度。
下载地址可以在https://gitee.com/fgy120/DETR的ReadMe里的Modelzoo查找自己想要训练的网络结构的预训练模型下载地址。
三、没有下载预训练模型跳过这一步,下载好预训练模型后,我们需要把模型的head输出数改为我们自己的数据集类别数N,可以用这个脚本,注意里面需要修改的class不包含背景类。https://gitee.com/fgy120/DETR/blob/master/util/change_pth_numclass.py
四、预训练模型准备好后,就是配置我们的agrs——运行配置和训练的超参等,在main.py的get_args_parser()函数里,关于parser的使用,可以看一下argparse解析器_在努力的松鼠的博客-CSDN博客

因为我喜欢pycharm直接运行, 所以我直接给很多的arg都加上了default默认值,懒人实锤了。。。
值得注意要修改的几个arg:
-
batch_size:如果太高了显卡带不动会显示爆显存的错,就需要降低我们的batch_size了,我3060显,460*680的图像设了4,感觉刚刚好,大家量力而行。
- epochs: 训练的轮次,所有图片训练一次是一轮。
-
backbone:backbone的网络结构选择,我选择了'resnet50'
-
coco_path:是你存放数据集ann、train、test、val文件夹的文件夹路径
-
output_dir:是你训练以及验证模型保存的文件夹路径
-
world_size:一般别超过1,是分布式训练需要用到的设置
-
resume:预处理模型以及断点训练的load模型的地址,下面可以参考
# parser.add_argument('--resume', default='D:\\fgy\\Desktop\\DETR\\detr\\pthsave\\pthsave_facedetect\\checkpoint.pth', help='resume from checkpoint')
parser.add_argument('--resume', default='D:\\fgy\\Desktop\\DETR\\savepth\\detr_r50init_1.pth', help='resume from checkpoint')五、接下来是在代码里修改我们的数据集类别数,在detr.py的build()函数,为了方便我都修改成了我的类别数,数据集也懒得弄了,就弄了一个类别。。
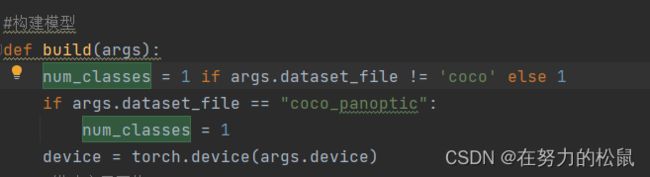
六、上面的都弄好后,运行main.py就可以了。
上面提到的代码和脚本都可以在https://gitee.com/fgy120/DETR找到,有问题或有建议的也可以评论区交流