windows10复现DEtection TRansformers(DETR)并实现自己的数据集
DEtection TRansformers(DETR)
DEtection TRansformer(DETR)是Facebook AI的研究者提出的Transformer的视觉版本,用于目标检测和全景分割。这是第一个将Transformer成功整合为检测pipeline中心构建块的目标检测框架。
1、代码地址Github:https://github.com/facebookresearch/detr
2、论文地址:End-to-End Object Detection with Transformers
第一步,先将代码下载下来,然后在pycharm中打开,运行terminal,输入
pip install -r requirements.txt
安装代码必要的库,

我在这路遇到了问题,在安装第二个库cocoapi时出现了安装失败,折腾了半天,终于解决了–>本地安装加换其它大神编译好的包,下载地址:https://github.com/philferriere/cocoapi
- 打开anconda的命令界面输入activate your_env_name (激活anaconda虚拟环境);
- 进入coco源码setup.py所在目录 cocoapi-master\PythonAPI;
- 运行python setup.py build_ext install即可安装完成。
解决了这个问题,安装其他的库就没得什么问题了,如果遇到vc++2015之类的问题建议在vs studio中把c++那一项也安装好。
第二步,将它的pth文件改一下,因为他是用的coco数据集,而我们只需要训练自己的数据集,就是下图这个文件
![]()
运行一下代码,就会生成一个你数据集所需要的物体数目的pth,记得改那个数字。
import torch
pretrained_weights = torch.load('detr-r50-e632da11.pth')
num_class = 3 #这里是你的物体数+1,因为背景也算一个
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1, 256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights, "detr-r50_%d.pth"%num_class
运行完后会生成下图的文件:
![]()
第三步,准备自己的训练集,首先你要用自己的数据标记一个VOC类型的数据集,这里就不多赘述了,可以自己百度下载labelimg来打标,然后将文件放入这几个文件夹,就可以了,然后就是转换成json格式的数据。

第四步,转换成json格式,生成的文件夹记得改为instances_train2017,json这种样子,如下图,

下面是voc转换为json的代码,自己更改文件路径
# coding:utf-8
# pip install lxml
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
path2 = "C:/Users/Desktop/VOC2007"
START_BOUNDING_BOX_ID = 1
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = 20190000001 + index
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
classes = ['bicycle', 'pottedplant', 'tvmonitor']
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
# pre_define_categories = {'a1': 1, 'a3': 2, 'a6': 3, 'a9': 4, "a10": 5}
only_care_pre_define_categories = True
# only_care_pre_define_categories = False
train_ratio = 0.9
save_json_train = 'instances_train2014.json'
save_json_val = 'instances_val2014.json'
xml_dir = "./tmp_xml"
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
np.random.seed(100)
np.random.shuffle(xml_list)
train_num = int(len(xml_list) * train_ratio)
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num:]
convert(xml_list_train, save_json_train)
convert(xml_list_val, save_json_val)
if os.path.exists(path2 + "/annotations"):
shutil.rmtree(path2 + "/annotations")
os.makedirs(path2 + "/annotations")
if os.path.exists(path2 + "/images/train2014"):
shutil.rmtree(path2 + "/images/train2014")
os.makedirs(path2 + "/images/train2014")
if os.path.exists(path2 + "/images/val2014"):
shutil.rmtree(path2 + "/images/val2014")
os.makedirs(path2 + "/images/val2014")
f1 = open("train.txt", "w")
for xml in xml_list_train:
img = xml[:-4] + ".jpg"
f1.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/images/train2014/" + os.path.basename(img))
f2 = open("test.txt", "w")
for xml in xml_list_val:
img = xml[:-4] + ".jpg"
f2.write(os.path.basename(xml)[:-4] + "\n")
shutil.copyfile(img, path2 + "/images/val2014/" + os.path.basename(img))
f1.close()
f2.close()
print("-------------------------------")
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
这下面是将xml中的图片从文件夹选出来,用得到的可以用。
#将图片根据xml中的文件名挑选出来
from PIL import Image
from PIL import ImageEnhance
import os
import cv2
import numpy as np
def convert(input_dir1, input_dir2,output_dir):
for filename in os.listdir(input_dir1):
for filename1 in os.listdir(input_dir2):
path = input_dir1 + "/" + filename#图片路径
path1=input_dir2+'/'+filename1#xml路径
#print("doing... ", path)
#print("doing... ", path1)
if path1[-10:-4]==path[-10:-4]:#只有图片代号和xml代号相等的时候才会保存
print(path[-10:-4])
image = Image.open(path)
image.save(output_dir + "/" + filename[:-4] + ".jpg")
if __name__ == '__main__':
input_dir1 = "C:/Users/Desktop/VOC2007_COCO/images"#输入图片路径
input_dir2= "C:/Users/Desktop/xml/xml_train"#输入标注路径
output_dir = "C:/Users/Desktop/xml/train1"#保存路径
convert(input_dir1,input_dir2,output_dir)
数据集做好后如下图所示

annotations文件夹中的文件如下图所示

train2017文件夹中的文件如下图所示

第五步,修改detr.py中305行的num_classes改成你的物体种类的数目

第六步,运行main.py进行训练
python main.py --dataset_file "coco" --coco_path data/coco --epochs 100 --lr=1e-4 --batch_size=2 --num_workers=4 --output_dir="outputs" --resume="detr-r50_3.pth"
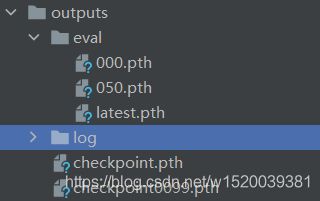
训练完后会在outputs生成下图的文件,log文件是记录每一个epoch的一些信息
到这里就完成了整个训练。
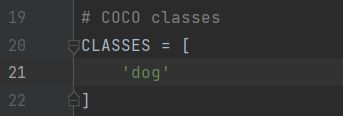
最后,就是拿自己的训练的模型进行测试,更改这里的图片路径为要测试的图片的路径,还有第19行的CLASSES=[],记得改成自己的类别!
整个流程就结束了,这个代码还提供了画图的功能,在util中的plot_utils.py文件
在这个py文件下加入这个代码,路径自己改哦!
if __name__ == '__main__':
files = list(Path('../outputs/eval').glob('*.pth'))
plot_precision_recall(files)
plt.show()
plot_logs(logs=Path('D:/detr/outputs/log/'),fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt')
plt.show()
出现这个错误:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
![]()
解决方法为
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
就可解决问题
if __name__ == '__main__':
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
files = list(Path('../outputs/eval').glob('*.pth'))
plot_precision_recall(files)
plt.show()
plot_logs(logs=Path('D:/BaiduNetdiskDownload/detr/outputs/log/'),fields=('class_error', 'loss_bbox_unscaled', 'mAP'), ewm_col=0, log_name='log.txt')
plt.show()
好了,到这里所有的步骤与我遇到的坑都告诉大家了,有什么问题可以留言!
好多同学要预测模型,点击自己去取吧
提取码:6ino