Python爬虫入门教程31:爬取猫咪交易网站数据并作数据分析
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
前文内容
Python爬虫入门教程01:豆瓣Top电影爬取
Python爬虫入门教程02:小说爬取
Python爬虫入门教程03:二手房数据爬取
Python爬虫入门教程04:招聘信息爬取
Python爬虫入门教程05:B站视频弹幕的爬取
Python爬虫入门教程06:爬取数据后的词云图制作
Python爬虫入门教程07:腾讯视频弹幕爬取
Python爬虫入门教程08:爬取csdn文章保存成PDF
Python爬虫入门教程09:多线程爬取表情包图片
Python爬虫入门教程10:彼岸壁纸爬取
Python爬虫入门教程11:新版王者荣耀皮肤图片的爬取
Python爬虫入门教程12:英雄联盟皮肤图片的爬取
Python爬虫入门教程13:高质量电脑桌面壁纸爬取
Python爬虫入门教程14:有声书音频爬取
Python爬虫入门教程15:音乐网站数据的爬取
Python爬虫入门教程17:音乐歌曲的爬取
Python爬虫入门教程18:好看视频的爬取
Python爬取入门教程19:YY短视频的爬取
Python爬虫入门教程20:IP代理的爬取使用
Python爬虫入门教程21:付费文档的爬取
Python爬虫入门教程22:百度翻译JS解密
Python爬虫入门教程23:A站视频的爬取,解密m3u8视频格式
Python爬虫入门教程24:下载某网站付费文档保存PDF
Python爬虫入门教程25:绕过JS加密参数,实现批量下载抖某音无水印视频内容
Python爬虫入门教程26:快手视频网站数据内容下载
Python爬虫入门教程27:爬取某电商平台数据内容并做数据可视化
Python爬虫入门教程28:爬取微博热搜榜并做动态数据展示
Python爬虫入门教程29:爬取某团烤肉店铺数据内容并做可视化展示
ython爬虫入门教程30:爬取拉勾网招聘数据信息
PS:如有需要 Python学习资料 以及 解答 的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本开发环境
- Python 3.8
- Pycharm
相关模块的使用
import requests
import parsel
import csv
安装Python并添加到环境变量,pip安装需要的相关模块即可。
需求数据来源分析
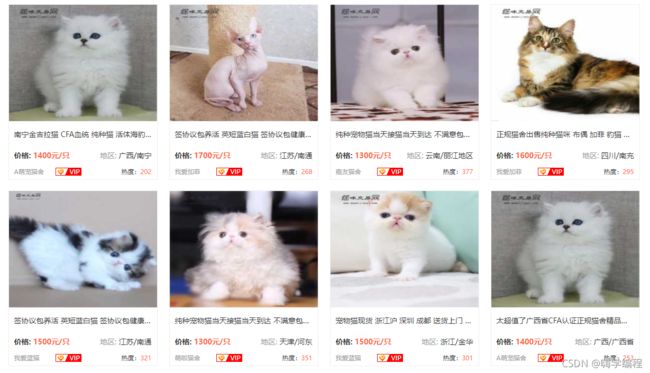
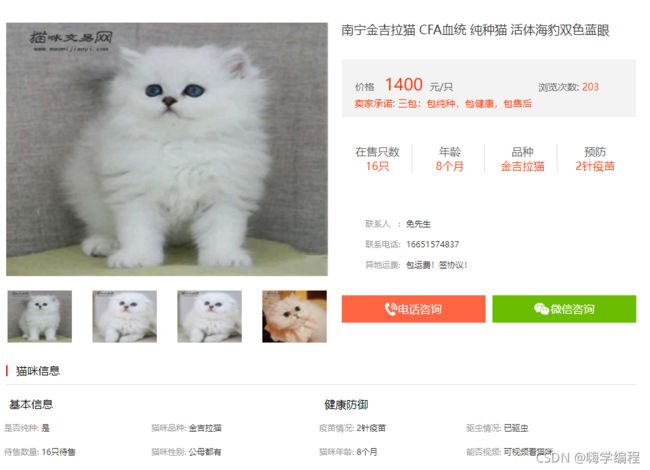
'地区', '店名', '标题', '价格', '浏览次数', '卖家承诺', '在售只数',
'年龄', '品种', '预防', '联系人', '联系方式', '异地运费', '是否纯种',
'猫咪性别', '驱虫情况', '能否视频', '详情页'
这些数据, 都是要获取下来的, 虽然说需要的数据比较多, 但是这个网站相对而言还是很简单的, 因为没有什么反爬的措施.
代码实现
获取数据
url = 'http://www.maomijiaoyi.com/index.php?/chanpinliebiao_c_2.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
href = selector.css('div.content:nth-child(1) a::attr(href)').getall()
areas = selector.css('div.content:nth-child(1) a .area span.color_333::text').getall()
areas = [i.strip() for i in areas]
zip_data = zip(href, areas)
for index in zip_data:
# http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_546549.html
index_url = 'http://www.maomijiaoyi.com' + index[0]
response_1 = requests.get(url=index_url, headers=headers)
selector_1 = parsel.Selector(response_1.text)
area = index[1] # 地区
shop = selector_1.css('.dinming::text').get().strip() # 店名
title = selector_1.css('.detail_text .title::text').get().strip() # 标题
price = selector_1.css('span.red.size_24::text').get() # 价格
views = selector_1.css('.info1 span:nth-child(4)::text').get() # 浏览次数
promise = selector_1.css('.info1 div:nth-child(2) span::text').get().replace('卖家承诺: ', '') # 卖家承诺
sale = selector_1.css('.info2 div:nth-child(1) div.red::text').get() # 在售
age = selector_1.css('.info2 div:nth-child(2) div.red::text').get() # 年龄
breed = selector_1.css('.info2 div:nth-child(3) div.red::text').get() # 品种
safe = selector_1.css('.info2 div:nth-child(4) div.red::text').get() # 预防
people = selector_1.css('div.detail_text .user_info div:nth-child(1) .c333::text').get() # 联系人
phone = selector_1.css('div.detail_text .user_info div:nth-child(2) .c333::text').get() # 联系方式
fare = selector_1.css('div.detail_text .user_info div:nth-child(3) .c333::text').get().strip() # 异地运费
purebred = selector_1.css(
'.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(1) .c333::text').get().strip() # 是否纯种
sex = selector_1.css(
'.xinxi_neirong div:nth-child(1) .item_neirong div:nth-child(4) .c333::text').get().strip() # 猫咪性别
worming = selector_1.css(
'.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(2) .c333::text').get().strip() # 驱虫情况
video = selector_1.css(
'.xinxi_neirong div:nth-child(2) .item_neirong div:nth-child(4) .c333::text').get().strip() # 能否视频
dit = {
'地区': area,
'店名': shop,
'标题': title,
'价格': price,
'浏览次数': views,
'卖家承诺': promise,
'在售只数': sale,
'年龄': age,
'品种': breed,
'预防': safe,
'联系人': people,
'联系方式': phone,
'异地运费': fare,
'是否纯种': purebred,
'猫咪性别': sex,
'驱虫情况': worming,
'能否视频': video,
'详情页': index_url,
}
print(area, shop, title, price, views, promise, sale, age, breed,
safe, people, phone, fare, purebred, sex, worming, video, index_url, sep=' | ')
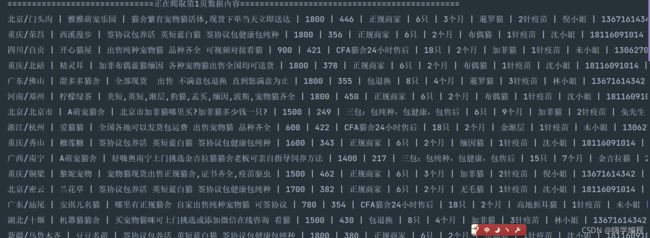
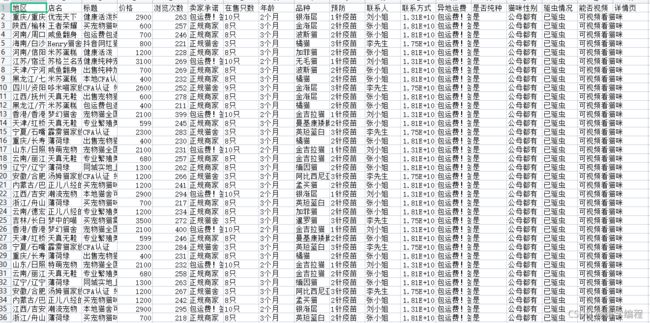
爬取数据展示
部分数据分析展示
品种类目词云

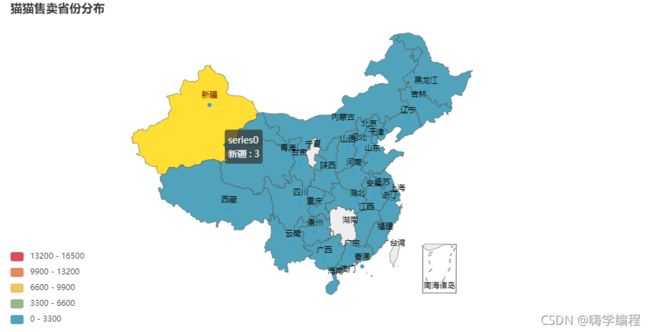
猫猫售卖省份分布
交易品种占比树状图

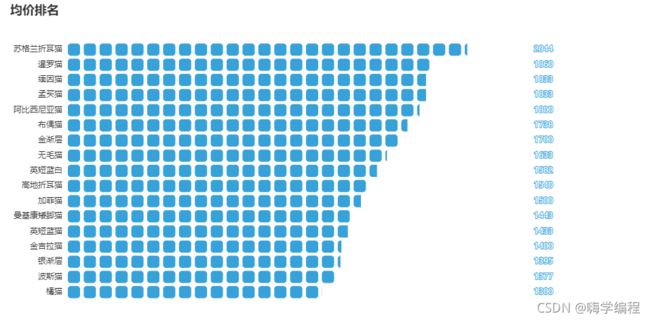
均价排名
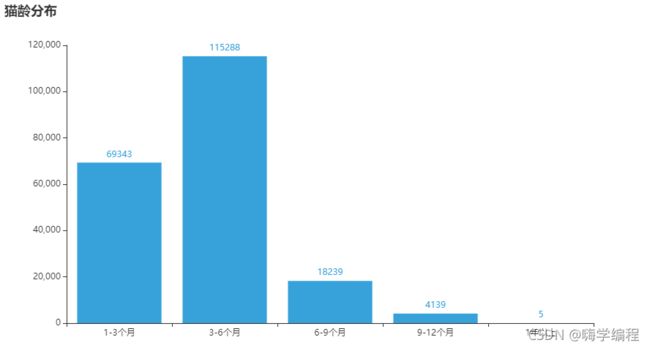
猫龄分布
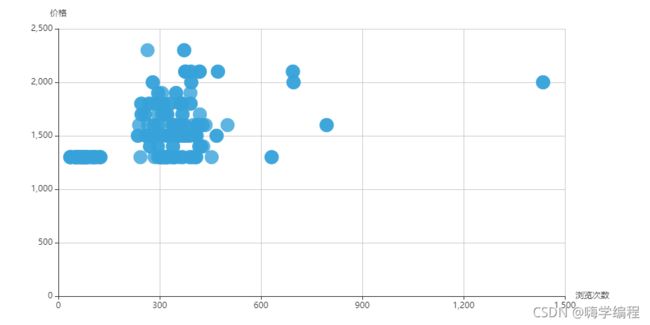
浏览次数是否跟价格成正比,散点图
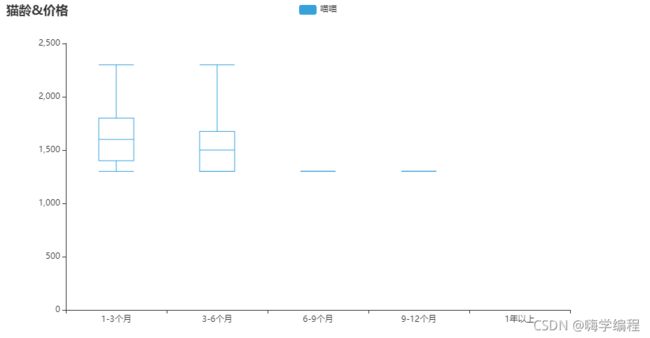
猫龄&价格箱形图
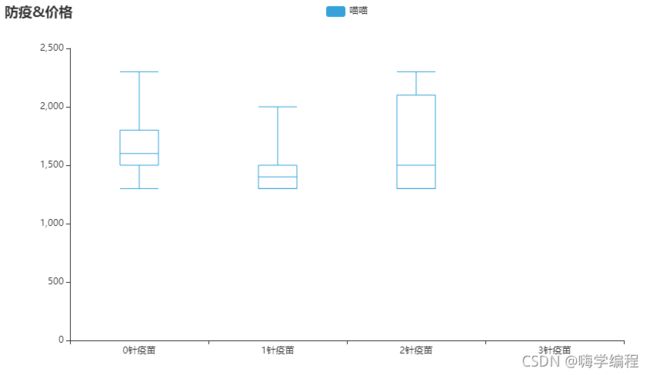
打疫苗&价格箱形图
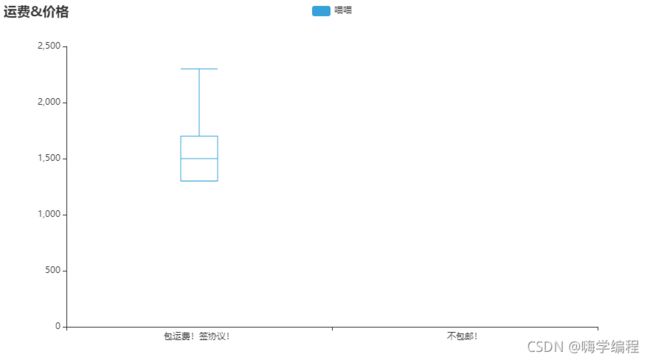
包邮&价格箱形图
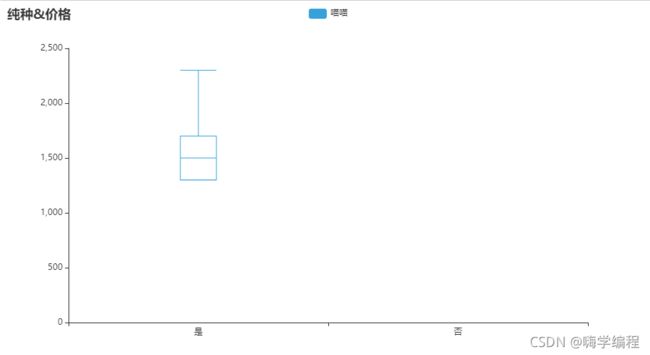
纯种&价格箱形图
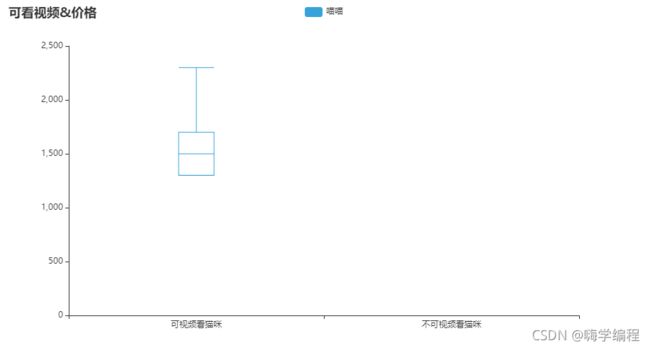
可看视频&价格箱形图
数据分析代码点击即可领取