【强化学习】基于DQN的《只狼:影逝二度》自学习算法研究
前言
写在前面
- 作为强化学习的入门练手项目之一,得益于《只狼》的特殊游戏机制,这个看似复杂的课题实际上难度不高且相当有趣(特别鸣谢两位b站up提供的宝贵思路)。
- 《只狼》作为一款3D动作游戏,一是战斗目标可锁定且视角可固定,这意味着图像区域可以被有效剪裁,很好地缩小了需要采集的样本数据大小;二是角色移动输入依赖不高,在采集键盘数据时能针对方向键对样本数据进行大幅度压缩;三是战斗模式相对单一,游戏中的战斗技巧相当纯粹,采集数据时仅需攻击、跳跃、识破、防御四个动作作为键位输入即可。
- 值得一提的是,我在整个项目的基础上,借鉴前辈们的思路,做了一些模块化、工具化的尝试,以图面对不同的游戏实验平台时,仅需按部就班地修改部分参数即可完成适配。
系统环境
本文选择的深度学习框架为TensorFlow。
本文训练和测试模型所使用的机器配置如下:
- 处理器:AMD Ryzen 5 3600
- GPU:NVIDIA RTX 2060
- 内存:16GB
- 操作系统:Windows 10。
- Tensorflow版本:2.4.1
- CUDA版本:11.3
- cuDNN版本:8.1.1
强化学习理论
一般认为,强化学习的四大基本要素分别是:状态(state)、动作(action)、策略(policy)、奖励(reward)。
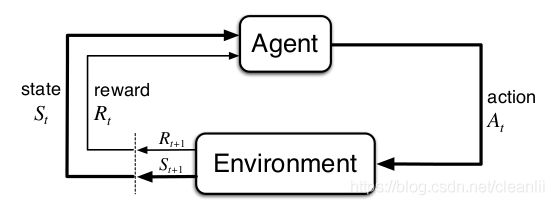
如图所示,强化学习研究的是智能体与环境的交互。智能体通过对环境的观察,得到与环境相关的状态信息,然后根据该信息判断下一步应该进行何种决策,并做出与之相应的动作,环境在接收到智能体的动作信息之后给予一定反馈作为奖励,这里的奖励可以是正面的,也可以是负面的,旨在反映该动作的好坏程度。
与此同时,来自智能体的该动作也会对环境造成一定影响,从而使上一个状态信息发生变化,转而再次进行判断,由此往复。最终,智能体生成了一系列的状态-动作序列。而智能体的目标就是根据这一组组序列,使其得到在这段时间内的最大奖励累计,生成一组组最优行为策略。
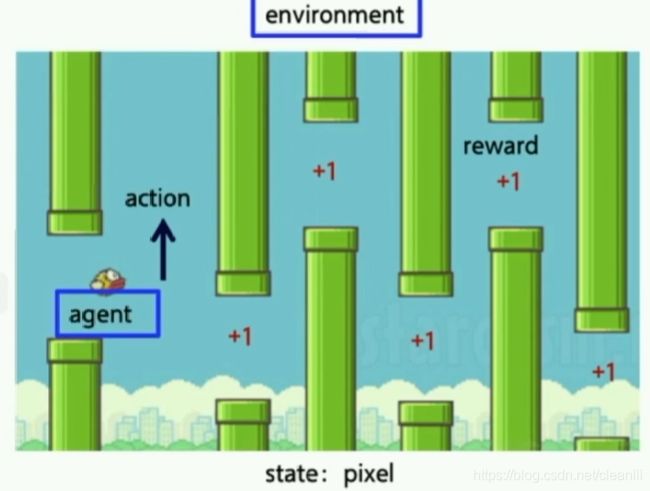
这里以机制简单的2D像素游戏《疯狂小鸟(Flappy Bird)》为例,对应到前面提到的强化学习四要素:智能体agent指的是这只小鸟,小鸟周围的天空背景、管道分布即environment,游戏中小鸟的目标是越飞越远,所以reward可以简单描述成飞得越远奖励分数就越高,action是小鸟每一次飞翔的操作,state则是每一帧画面的像素值分布。一个面向游戏的强化学习系统的目标即训练智能体可以控制这只鸟尽可能取得高分。
这个例子可以很好地解释大部分游戏AI的基础思路。
深度强化学习理论
近年,神经网络在图像识别领域取得了显著的成果,得益于其强大的特征提取能力。卷积神经网络可以从原始复杂的高维数据中提取特征,这也是本文能用实时画面捕获的方式实现游戏AI的原因。
深度强化学习(Deep Reinforcement Learning,DRL)将深度学习较强的感知能力和强化学习较强的决策能力相结合,可以直接根据输入的图像进行控制,是一种更接近人类思维方式的人工智能方法。

如图所示,传统的强化学习算法是Q-Learning,引申了一个不断更新的Q表格(保存当前状态的基本元素)去逼近奖励函数,从而得到最优策略。但这样的方法无法处理复杂的电子游戏,因为每一帧游戏画面都是不同的state,对于表格更新来说计算量过于庞大。于是深度强化学习算法应运而生。研究者将状态值state与动作值action的集合输入神经网络,训练得到每个动作值对应的值函数value,代表了该动作的好坏程度。而在测试模型时只输入状态值state,预测多个动作值和其值函数,从而进行最优决策。这与人类通过五官向大脑传递信息学习各类健身操的经历类似。
深度Q网络(Deep Q-Learning Network,DQN)是深度强化学习的代表算法。DQN的核心思路在于用神经网络取代Q表格更新的方法去进行拟合,即使用神经网络逼近奖励函数,以激励智能体进行最优动作。

如图可见DQN的基本算法流程图,DQN开创性地将深度神经网络和Q学习(Q-Learning)相结合,仅将电子游戏的实时画面作为数据输入,同时进行随机采样以打破数据之间的联系,有效地解决了神经网络模型本身的不稳定和发散性问题,极大提高了强化学习的适用性,令其在很多方面的应用成为了可能。
模块介绍
读取游戏画面
为了确保每次采集数据都是有效且可靠的,本系统需要严格对游戏窗口进行一些约束,并需要消除窗口边框对采集的影响。为了方便坐标运算,需要将窗口固定在屏幕左上角起点位置。
这里构造了一组用于捕捉兴趣区域(Region of Interest,ROI)的函数,通过鼠标左键点击四次获取屏幕内任意矩形的顶点坐标(基于实时分辨率),实现对当前游戏窗口的坐标裁定。
# 抠图
def ROI(img, x, x_w, y, y_h):
return img[y:y_h, x:x_w]
完成坐标裁定之后,再进行简单的相减运算,消除边框影响,可以较为精准地计算出游戏画面的四个顶点坐标,并修改该类下相应的参数。
GAME_WIDTH = 800 # 游戏窗口宽度
GAME_HEIGHT = 450 # 游戏窗口高度
GAME_BORDER = 31 # 游戏边框
FULL_WIDTH = 1920 # 全屏宽度
FULL_HEIGHT = 1080 # 全屏高度
由此,今后在面对任何一款PC电子游戏时,只需要将其窗口化、并按部就班地获取以上参数即可。这也是本算法面向工具化的核心内容。
捕获键盘数据
本算法构造了基于win32api的键盘输入输出命令集。鉴于《只狼》不存在“连招”、“蓄力”一类的游戏机制,故对按键时序、时长不作严格要求。
首先是模拟键盘输入部分,PressKey方法模拟按键按压,ReleaseKey方法则模拟了按键释放。完成一次完整的按键点击,需要先执行PressKey,然后再执行ReleaseKey,相当于按下去再松开。由于智能体的学习途径是自行探索,本系统需要在中途适当添加sleep方法制造延迟,以模拟真实游戏中的效果。
def PressKey(hexKeyCode) # 压键
def ReleaseKey(hexKeyCode) # 松键
然后是相对复杂的检测键盘输出部分,本系统需要根据游戏里设置的按键来定义执行相应动作的函数。例如本算法针对《只狼》的键位设置为:攻击键J,防御键K,识破(闪避、垫步)键L,跳跃键M。如前文所述,得益于该游戏的特殊机制,上下左右的位移数据极易造成数据冗杂且对游戏获胜帮助不大,故在此去掉了移动键位输出。
# 攻击
def attack():
PressKey(dk['J'])
time.sleep(delay)
ReleaseKey(dk['J'])
# 防御
def deflect():
PressKey(dk['K'])
time.sleep(delay)
ReleaseKey(dk['K'])
# 闪避、识破、垫步
def dodge():
PressKey(dk['L'])
time.sleep(delay)
ReleaseKey(dk['L'])
# 跳跃
def jump():
PressKey(dk['M'])
time.sleep(delay)
ReleaseKey(dk['M'])
经数十次测试,按键延迟为0.1秒时人物行动正常,不会出现因延迟过低或过高出现的“角色抽搐”现象。
量化角色状态
在《只狼》中,观察环境状态、计算奖励的核心点是人物状态的变化,例如目标生命值减少、自身架势值增加等。由于缺少底层API,从实时画面中分析这些信息是必要的。
本算法需要量化获取的四个状态分别为:自身生命值、自身架势值、敌方生命值、敌方架势值,分别如图中绿框所示。
本算法采用了边缘检测的方法量化人物状态。正如前文所述,本方法解决了常规的“二值化取像素值”方法中无法获取架势的问题,这是因为架势条会随着其大小出现渐变色,影响像素值的判断。架势条未显示时,则默认录入值为0。
如图所示,这里需要再次使用捕获兴趣区域的函数组,由于各个人物状态信息栏位置和形式固定,可以很方便地采集到坐标信息并使用图像处理方法将“血条”、“架势条”量化。

以获取自身生命值为例,裁定兴趣区域之后对该区域进行常规的Canny算子边缘检测并转化成十进制数字作为返回值。
# 识别自身血量
def get_self_HP(img):
img = ROI(img, x=48, x_w=307, y=406, y_h=410)
canny = cv2.Canny(cv2.GaussianBlur(img,(3,3),0), 0, 100)
value = canny.argmax(axis=-1)
return np.median(value)
最后将四类状态信息进行封装,以便统一调用。
def get_game_status(img):
return get_self_HP(img), get_self_posture(img), get_boss_HP(img), get_boss_posture(img)
构造网络模型
本算法模型主要使用的是 DQN 算法,即在迭代过程中不断更新Q表格。根据肖智清在《强化学习原理与Python实现》中提供的DQN网络模型源码,本系统将其封装,在应用到训练不同游戏前根据需要修改网络结构,增加卷积层和池化层,以达到工具适配的效果。而如何恰当地对结构进行调整,也是整个系统的最大难点。

在构造网络模型的过程中,本算法使用经验回放池的方法来解决样本数据的强相关性问题。经验回放池中放入了很多次战斗中采集到的交互数据,而使用经验回放池后训练的批数据就能随机从池中抽取,这样保证了数据均来自不同的战斗,大幅度降低了数据间的相关性。
这样的DQN 算法属于Off-Policy算法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历,所以在学习过程中随机的加入之前的经验会让神经网络更有效率。经验池解决了相关性及非静态分布问题。他通过在每个timestep下agent与环境交互得到的转移样本储存到回放记忆网络,要训练时就随机拿出一些(minibatch)来训练因此打乱其中的相关性。
如若研究者希望看见智能体探索出风格多样的战斗风格,由此采样的利用率亦会大幅提高,这对基于值函数近似的深度强化学习算法而言是非常有益的。
设置奖励系统
针对3.4中最后封装整合的状态获取,其返回的是一个包含四种量化状态的元组,因此可以分别用下一状态的人物信息减去当前状态的人物信息,就能得到对应状态值的变化量。
"""
next_status - cur_status
等于 (自身生命变化值,自身架势变化值,目标生命变化值,目标架势变化值)
"""
s1 = next_status[0] - cur_status[0] # 自身生命变化值
s2 = next_status[1] - cur_status[1] # 自身架势变化值
s3 = next_status[2] - cur_status[2] # 目标生命变化值
s4 = next_status[3] - cur_status[3] # 目标架势变化值
而根据游戏内容,研究者可以判断出这四个变化量对于游戏过程的影响,例如自身生命值下降带来的是负面影响,因此呈负相关;而目标生命值下降带来的是正面反馈,因此呈正相关。
s1 *= 1 # 正相关
s2 *= -1 # 负相关
s3 *= -1 # 负相关
s4 *= 1 # 正相关
这里的奖励规则完全可以自行设定,而且经测试发现,不同程度的正负参数设定,会显著影响整个智能体的奖励曲线。这意味着可以通过设定更复杂的奖励参数来“引导”或者说“要求”智能体发现各种风格迥异的战斗方式。
例如,通过拔高生命值方面的奖励幅度,来让智能体探索战斗时更为激进。甚至可以根据《只狼》游戏本身的特殊机制——完美防御,即自身生命值不减的同时,敌方架势值上升,这种情况设定给予双倍奖励,旨在训练智能体更倾向于“无伤”战斗,这也是顶尖人类玩家的一般玩法。
if(s1 == 0 and s3 == 0 and s4 > 0):
s5 = s4*2
当然,越复杂的奖励系统设计,收敛效率越难得以保证,对网络模型结构要求也越高,需要更多新的技术来完善训练过程。
参数设置
最后,在正式进入训练之前,还需要明确一些模块化的参数设置。
这里定义了一个Agent类,用于保存必要的参数以及后续多模型训练测试的管理,这也是前文提到的本系统工具化的一部分。
class Agent:
def __init__(
self,
save_memory_path=None,
load_memory_path=None,
save_weights_path=None,
load_weights_path=None
):
在画面截取方面,已经捕获了800*450的游戏画面,但是将整个画面的像素值全部作为数据输入的话仍存在较多的干扰,这里需要对核心战斗区域再做一次兴趣区域裁剪。如图所示,在《只狼》中锁定敌人之后,实际上需要捕获的仅为画面中央的小部分区域。

因此,以《只狼》为例,在800450分辨率情况下取200200的核心区域。区域坐标分别为x,x_w,y,y_h。
# 800 x 450 window mode
x = 800 // 2 - 200 # 左 不小于0,小于 x_w
x_w = 800 // 2 + 200 # 右 不大于图像宽度,大于 x
y = 450 // 2 - 200 # 上 不小于0,小于 y_h
y_h = 450 // 2 + 200 # 下 不大于图像高度,大于 y
在网络模型方面,in_depth参数代表卷积核,若为二维卷积则置1;in_height和in_width分别代表输入模型时对图像的缩放比;in_channels代表颜色通道数量;outputs代表输入动作数量,即智能体能够执行几种动作;lr则代表学习率,默认为0.001,如果要修改的话,前期可以设置大点,快速收敛,后期设置小一点,提升学习效果。
in_depth = 1
in_height = 5
in_width = 5
in_channels = 1
outputs = 4
lr = 0.001
在强化学习方面,gamma参数代表奖励衰减,即未来对现在的重要程度,设置1代表同等重要,模型更有远瞻性,gamma值设置得越小说明越重视当前的决策;replay_memory_size和replay_start_size代表记忆容量和开始经验回放时的储存记忆量,即前文提到的回放经验池,到达最终探索率后才开始;batch_size代表样本抽取数量;update_freq代表训练评估网络的频率;target_netword_update_freq则代表更新目标网络的频率。
in_depth = 1
in_height = 5
in_width = 5
in_channels = 1
outputs = 4
lr = 0.001
模型训练
为了管理方便,本系统选出了《只狼》中颇具代表性的四位常规人形BOSS,并为他们创建了保存对应模型的相应目录:苇名弦一郎、巴流弦一郎、剑圣一心以及宫内破戒僧。
target = 'Genichiro_Ashina' # 苇名弦一郎
# target = 'Genichiro_Way_of_Tomoe' # 巴流 苇名弦一郎
# target = 'True_Monk' # 宫内破戒僧
# target = 'Isshin_the_Sword_Saint' # 剑圣一心
# 保存路径
SAVE_PATH = 'Boss/' + target + '/' + target
调用Agent类,设定好训练目标和记忆池相关参数,等待CUDA加载完毕,加载完毕后训练程序自动处于暂停状态。
train = Agent(
save_memory_path = SAVE_PATH + '_memory.json', # 保存记忆
load_memory_path = SAVE_PATH + '_memory.json', # 加载记忆
save_weights_path = SAVE_PATH + '_w.h5', # 保存模型权重
load_weights_path = SAVE_PATH + '_w.h5' # 加载模型权重
)
train.run()
如图,进入游戏窗口,按下按键T,即可开始训练。按T可再次暂停,按P则中止训练。
若观测到控制台每帧输出无误,则训练进程正常。
训练结束后,打印出单次训练的reward奖励曲线图。

模型测试
根据完成训练的模型对应路径修改target值,调用Agent类,进行测试。
test = Agent(
load_weights_path = target + '_w.h5'
)
test.run()
步骤同训练,若观测到控制台每帧输出无误,则测试进程正常。
参考教程
- Sentdex大神的GTA5自动驾驶教程 【B站搬运】【Github】
- B站up蓝魔digital的强化学习&机器学习打只狼教程 【B站】【Github】
- B站up遇上雨也笑笑的深度强化学习只狼AI教程 【B站】【Github】
- 肖智清《强化学习原理与Python实现》 【Github】
- 莫烦《强化学习入门教程》【Github】